
阅读量:0
CUDA简介
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种通用并行计算架构。CUDA允许程序员利用NVIDIA GPU的并行计算能力,加速各种计算密集型应用程序。
CUDA技术基于GPU的并行计算原理。传统的CPU处理器拥有少量的核心,可以同时执行少量的线程。但是,现代GPU拥有数百甚至上千个核心,可以同时执行大量的线程,实现高度并行计算。CUDA技术通过将CUDA代码编译成针对GPU的指令,利用GPU的并行处理能力,加快程序执行速度。
CUDA提供了一个基于C语言的编程模型和一组库,使程序员能够轻松地编写并行计算代码。CUDA代码可以在主机CPU和GPU之间进行协作,实现数据传输和计算划分。CUDA还提供了一些高级功能,例如共享内存、纹理内存和图像处理,以及支持异步和流处理等技术,可最大化地利用GPU处理器的性能。
CUDA技术在各种应用程序中广泛应用,包括科学计算、大数据分析、机器学习和图形处理等领域。CUDA在科学计算中已经取得了很大的成功,如在天文学、生物学、物理学等领域基础研究中的应用。同时,CUDA还在深度学习、计算机视觉和自然语言处理等人工智能领域获得了越来越多的应用。

异构计算架构
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,CPU会对GPU进行任务下达和指令部署,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。
在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)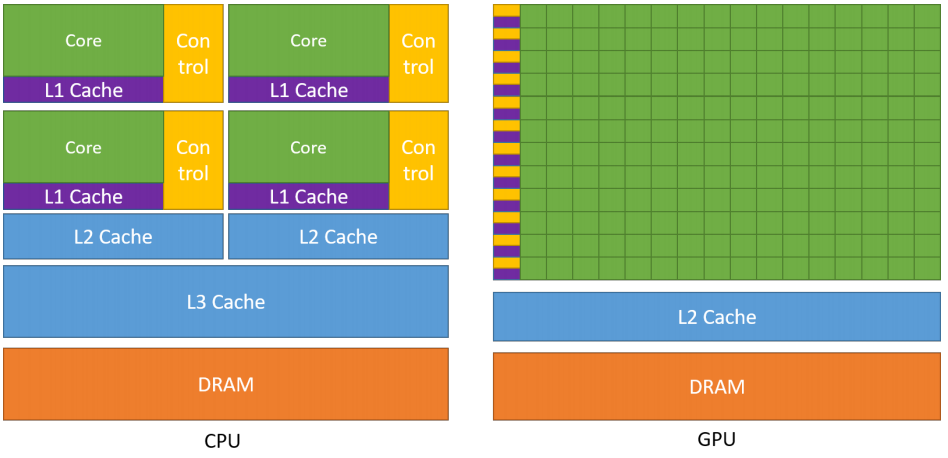
| 特点 | CPU | GPU |
|---|---|---|
| 运算核心 | 运算核心少,但可以实现复杂的逻辑运算,适合控制密集型任务 | 运算核心数多,适合数据并行的计算密集型任务,如大型矩阵运算 |
| 线程 | 线程是重量级的,上下文切换开销大 | 多核心,因此线程是轻量级的 |
CUDA下载
Windows下配置和测试运行
前言
在Windows下做CUDA编程最好使用Vistual Studio(使用命令行运行会出现一些配置上的问题)而在Vistual Studio中不会出现这些问题,Vistual Studio可以直接创建一个CUDA的项目
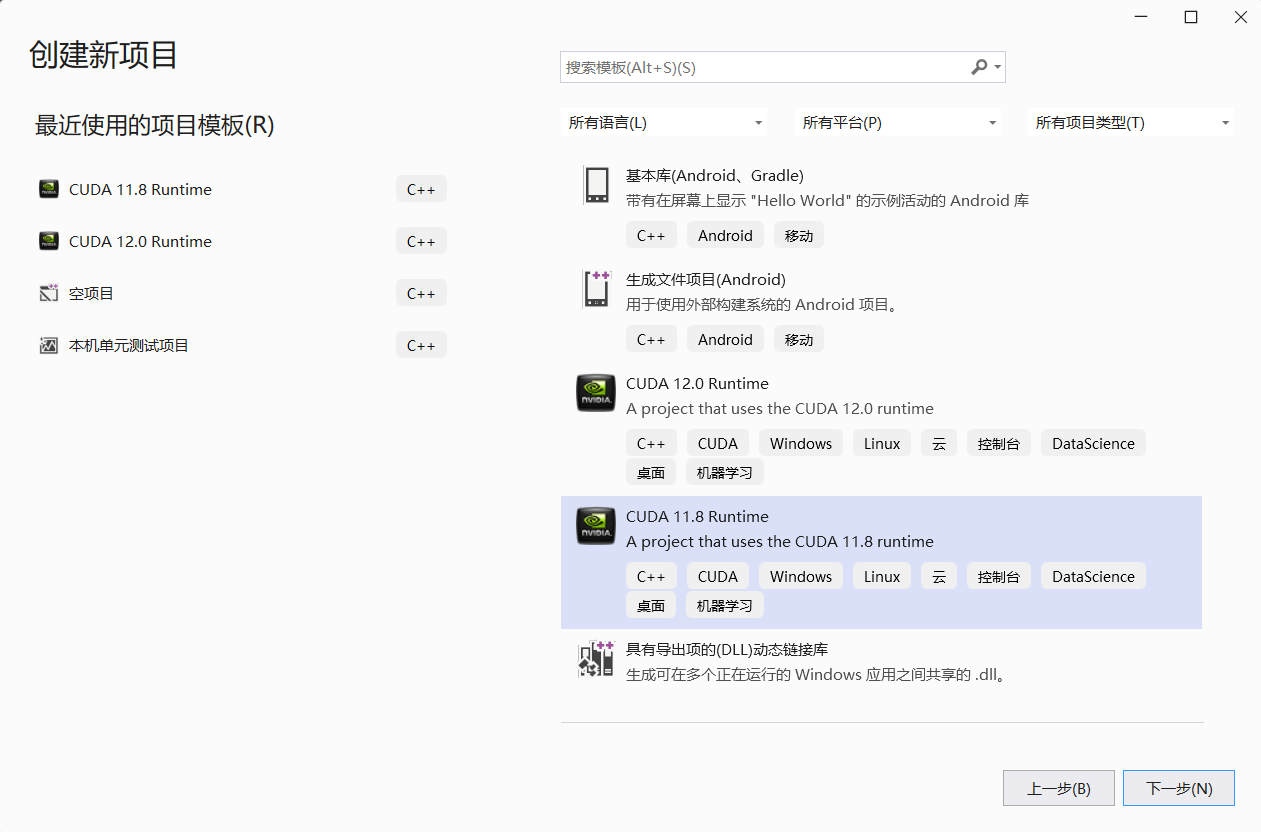
当然,这样便需要提前下载好Vistual Studio,网络上有很多教程,比较基础,我这里就不在演示了(要提前下好VS!)因为有些版本CUDA在安装过程中可以会让你选择是否Visual Studio Integration(下方图片是CUDA10.1版),这个选项的作用:是否在VS里出现创建CUDA项目的选项)
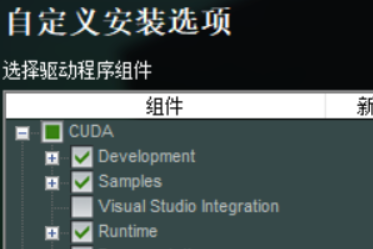
开始安装
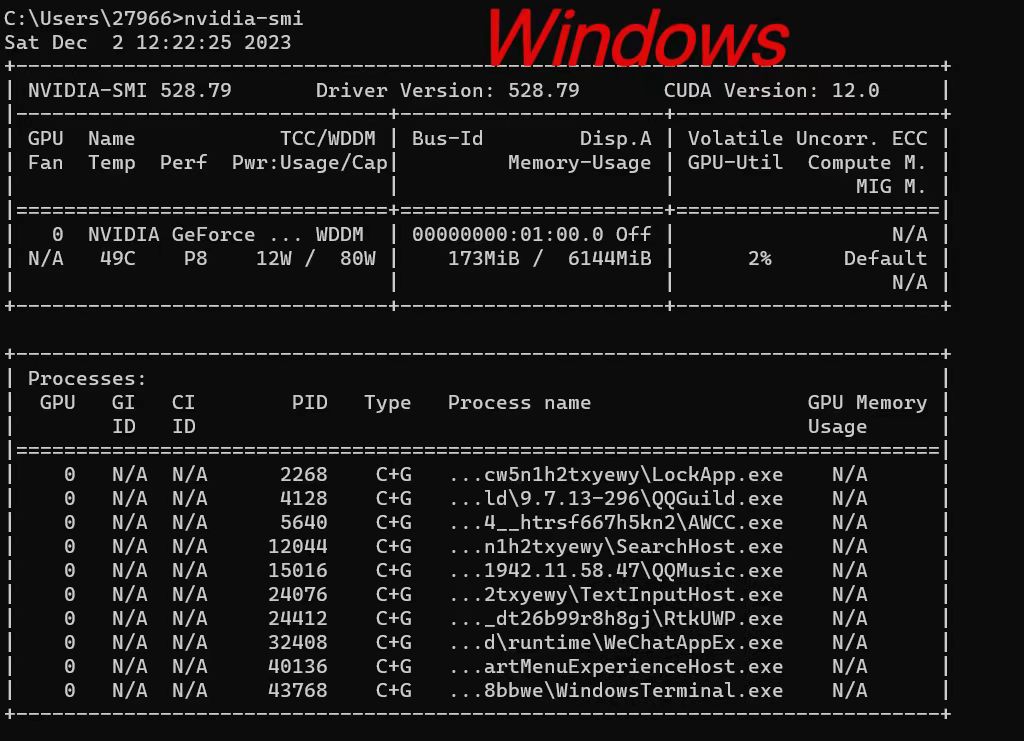
CUDA对于电脑支持的最高版本有很大的限制(受到显卡架构调整要求),首先要知道自己电脑支持的最高CUDA版本,打开命令行,输入
nvidia -smi 会出现以下界面(如果你的电脑没装NVIDIA的显卡,那么恭喜你,后面的内容就都和你没关系了,CUDA是基于NVIDIA开发的,没有NVIDIA显卡自然就做不了CUDA编程)
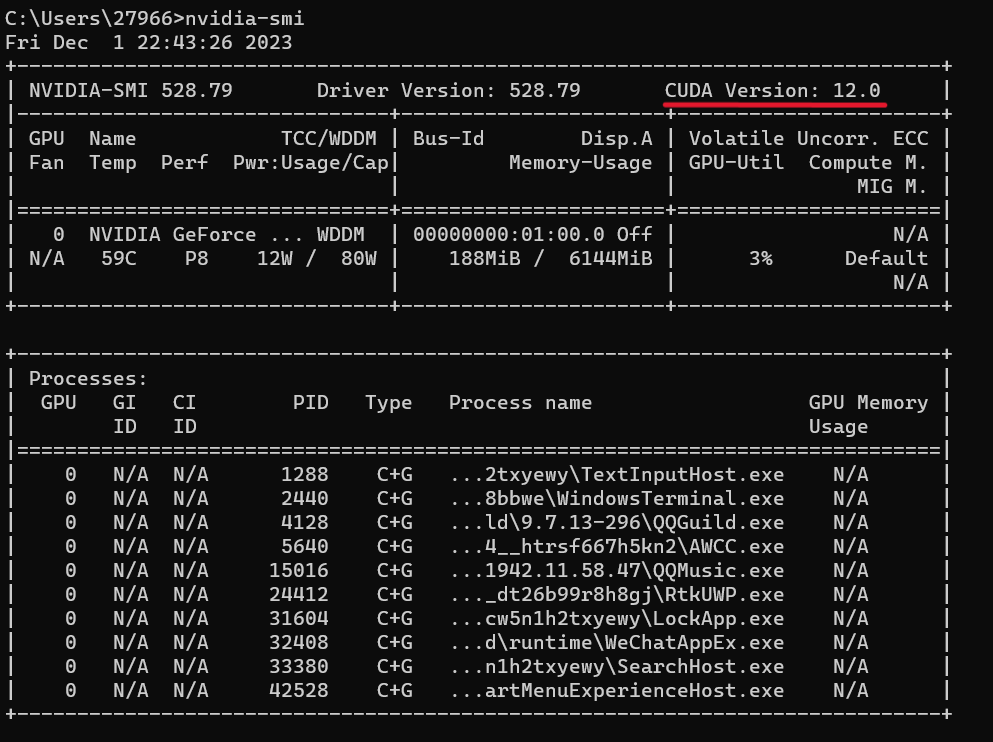
标红的部分便是CUDA支持的最高版本号,可以看见我的电脑支持的最高版本是12.0,所以我可以下载12.0及以下的版本使用,切记,不能高于最高版本号,可能出现结果输出异常等情况(亲测)接下来我们进入下载界面,这是CUDA官网各个版本号的地址:https://developer.nvidia.com/cuda-toolkit-archive,进入后的界面如下:
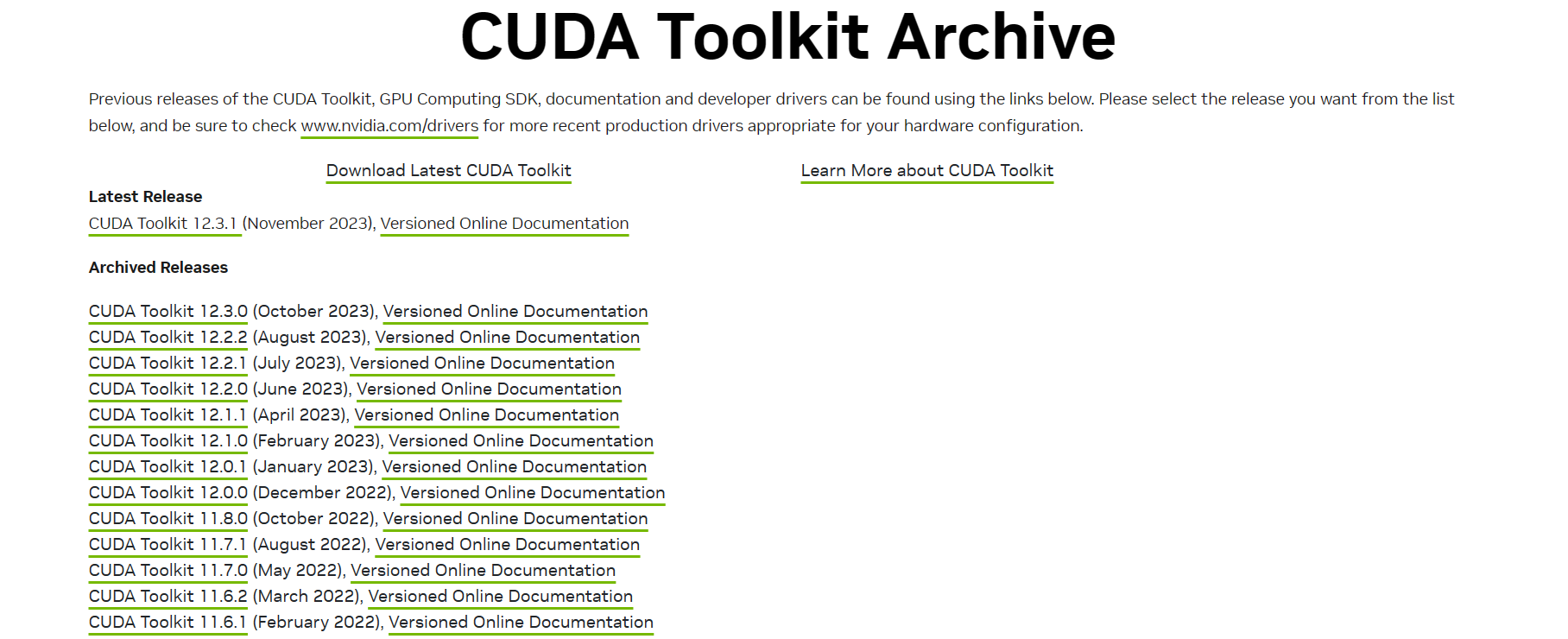
这里我选择11.8.0版本下载,点击 CUDA Toolkit 11.8.0, 进入下面界面:
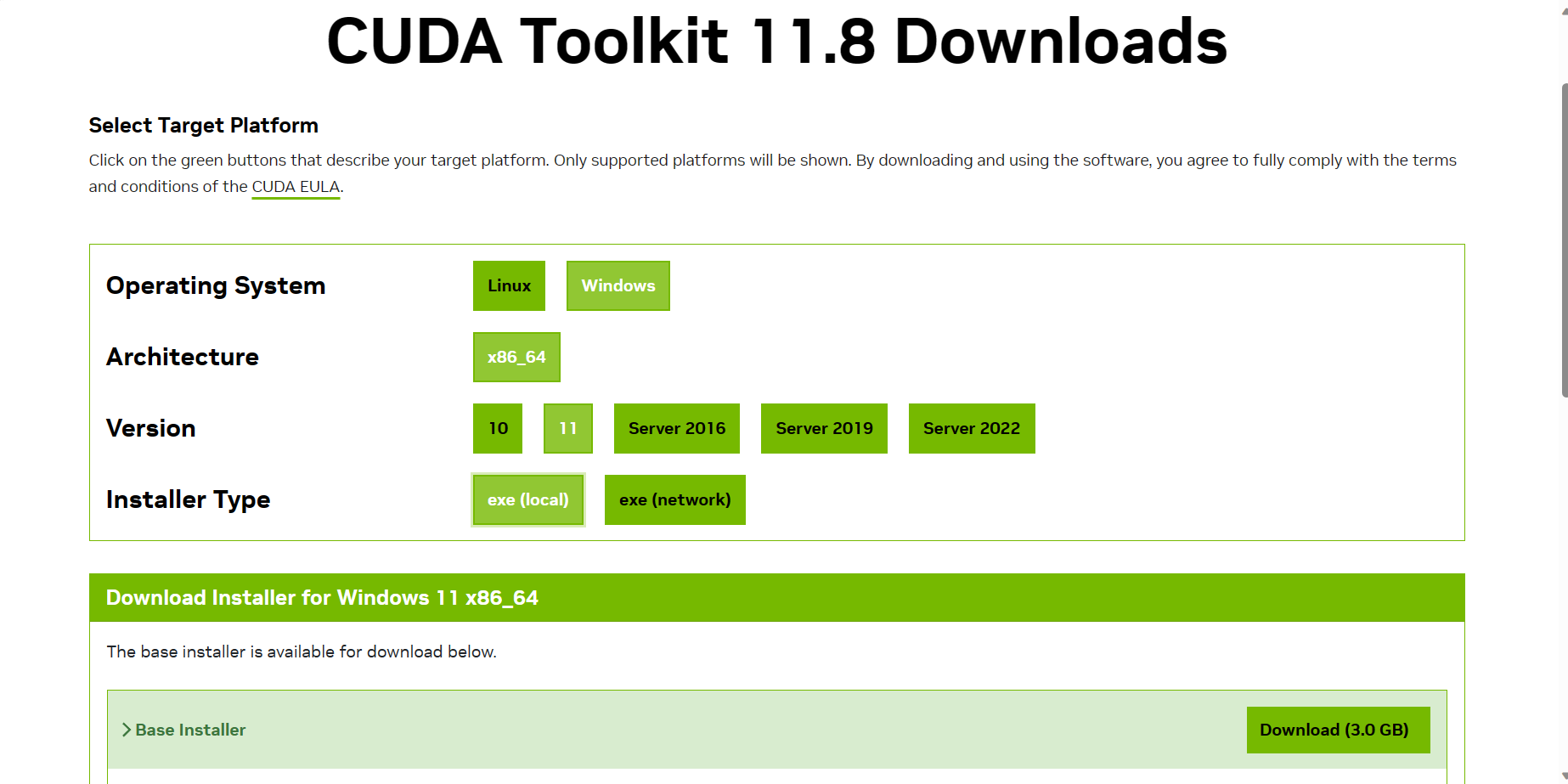
Version如果你用win10选择10,win11选择11,Installer Type选择local即可,点击DownLoad,可以用迅雷接管下载,速度比较快,下载好后会得到一个exe的安装程序,点击即可安装
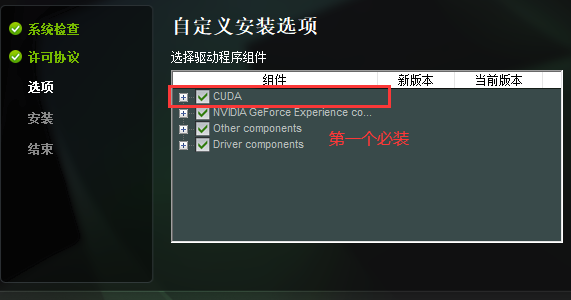
<必装CUDA,其他情况自己选择,如果是第一次安装建议全选,尤其是VS选项,后面可以在VS中生成CUDA项目>
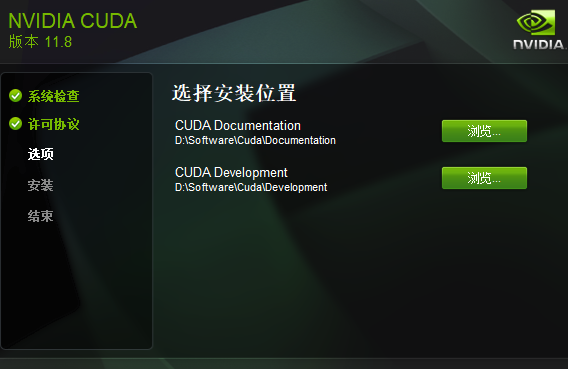
<自定义路径 Document与Development路径>
<等待安装完成即可>
安装完成后,会自动在环境变量中添加两个配置,可自行查看

在path中还会自动添加(一般会出现三个和NVIDIA相关的环境变量,如果一个没有则自己手动添加)

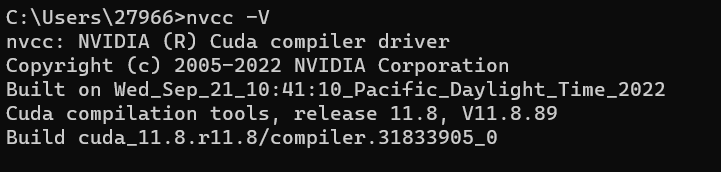
测试是否安装成功,打开终端输出:
nvcc -V 出现如下则说明安装成功
测试运行
接下来便在Windows下可以运行第一个CUDA程序(Vistual Studio):
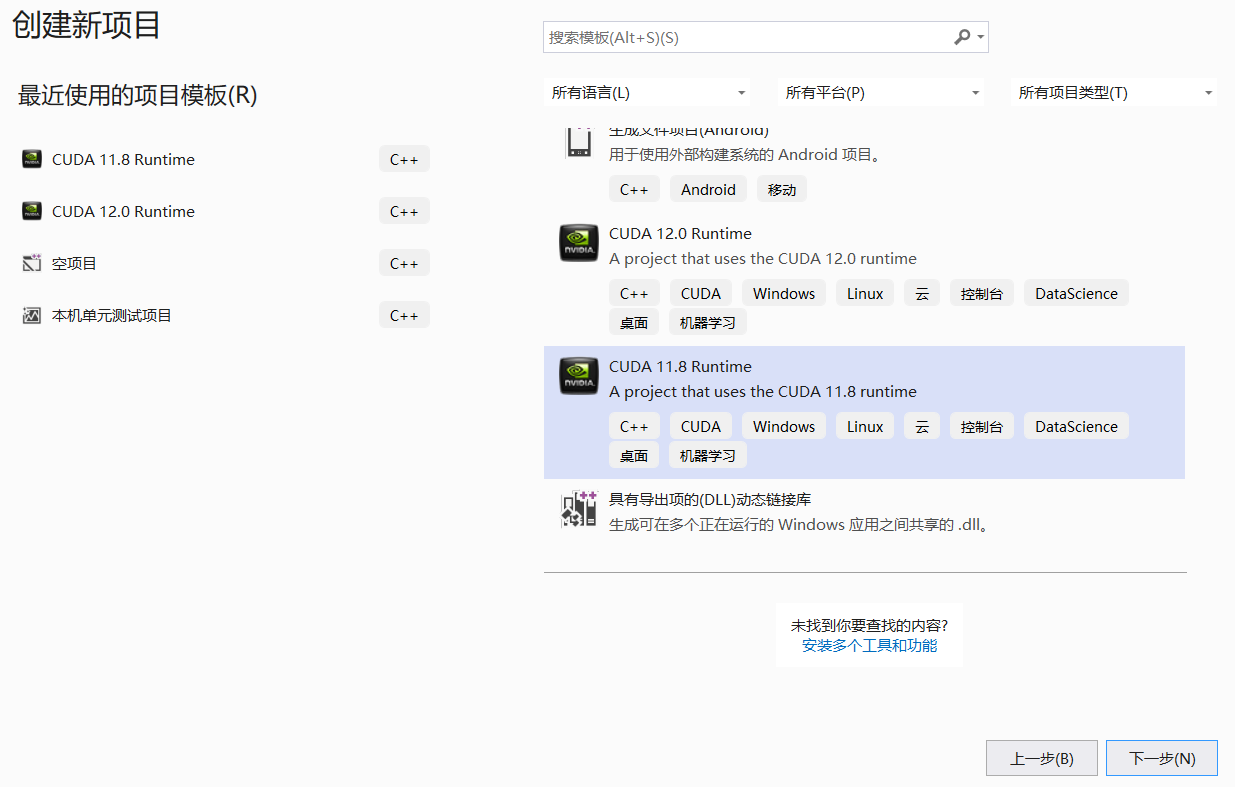
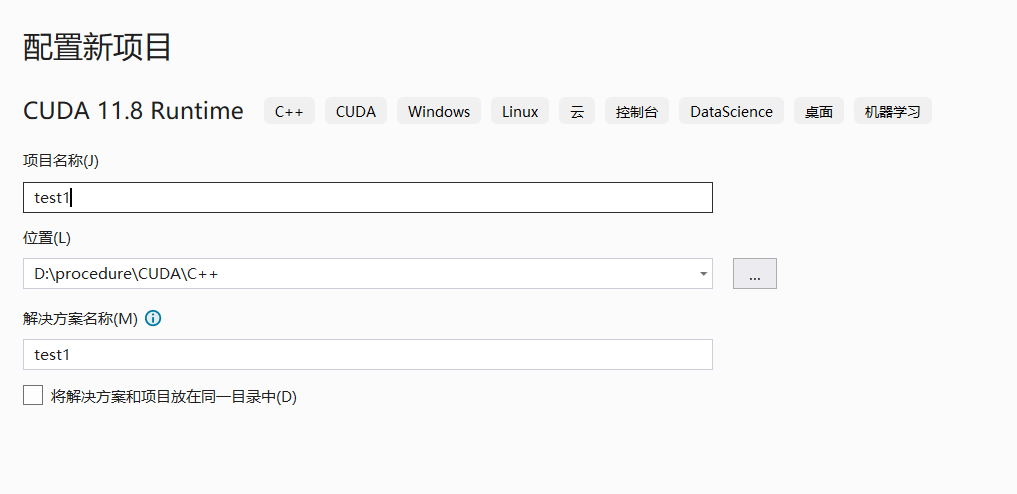
打开VS,新建一个CUDA项目
然后VS会给你一段测试代码(会出现一个报错,但实际上没错,猜测应该是VS的一个bug):
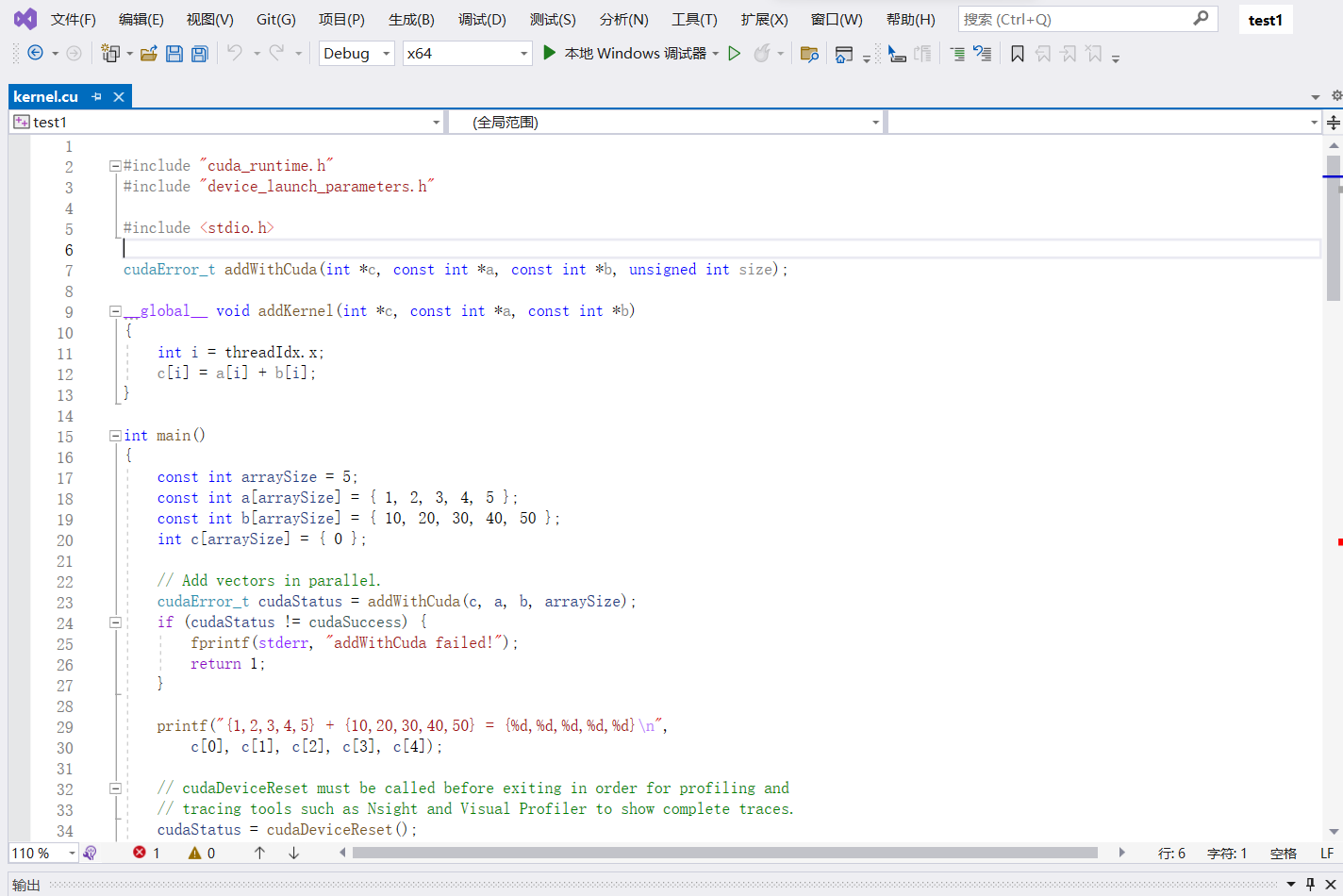
直接运行这个代码,就会得到如下结果: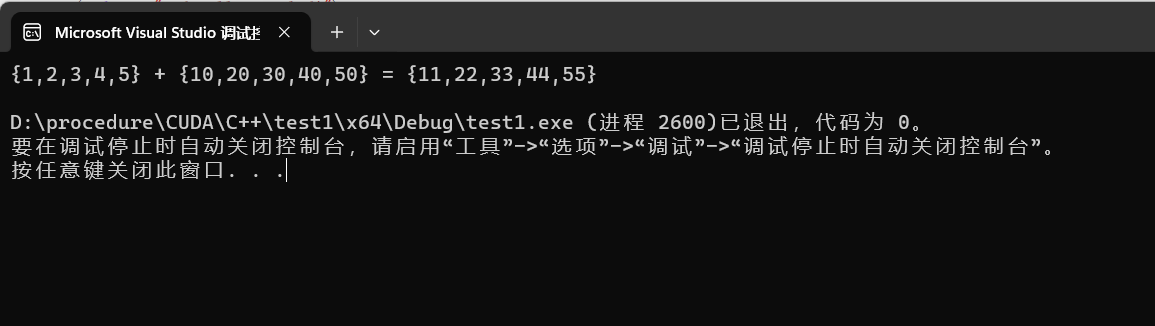
这便是Windows系统下通过CUDA调用GPU做的一个运算!至此,Windows下的配置CUDA基础环境便介绍完毕,博客上还有很多教程顺便介绍了怎么配置cuDNN(CUDA下的一个深度神经网络库)这里我先不做介绍,由于我后面会用到它和CUDA的其他一些库,到那个时候我再统一介绍怎么安装和使用这些库。
Linux下配置和测试运行
前言
我个人比较建议在学习阶段的话尽量在Linux下做CUDA编程,因为在Windows下只能通过VS配置项目的方式才能用CUDA(目前我只找到这一种方法),比较不方便,在Linux下可以用命令行的方式对CUDA程序进行编译,比较方便也能更好的体会到CUDA的工作原理。
如果第一次或者对Linux用的不熟的情况下,我推荐使用Ubuntu(建议使用18.04版)(基于Linux内核的一个发行版)怎么使用呢,我提供两种思路,一是使用双系统,二是使用WSL(Windows下的一个子系统)不要使用虚拟机,因为虚拟机无法调用显卡(技术很难以实现)
选择双系统或WSL使用,下面是二者各自的优点:
双系统:完全独立的操作系统,具备完整的系统性能,最大的兼容性
WSL:无需重启系统,简化的开发环境,良好的集成性
要是有朋友没有接触过两个技术的话可以选择其中一种到网上找教程安装(由于安装难度不大,我便不再演示)如果是初学CUDA,我建议选用WSL即可,比较方便,下面我将演示WSL环境下Ubuntu系统的CUAD安装(双系统的配置过程完全一致,只需按照自己需求选择不同的版本即可)
开始安装
我采用的是WSL2下的Ubuntu18.04版(推荐),打开WSL,由于是Windows的子系统,所以直接输入nvidia-smi 如果Windows系统能正常显示界面的话,WSL也能显示如下界面:
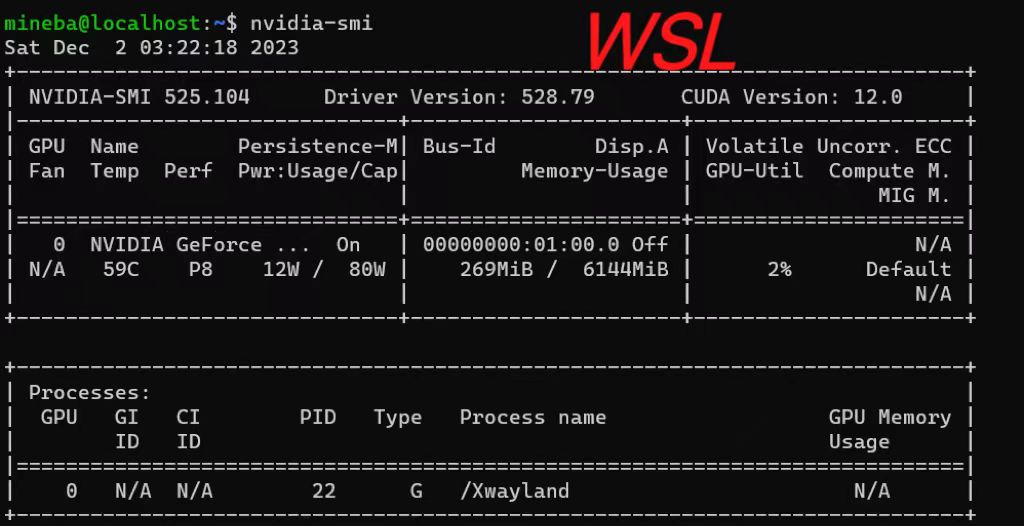
支持CUDA的最高版本依旧是12.0,这次我们尝试下载12.0版,进入CUDA Toolkit 12.0.0,与Windows不同,这次版本选择Linux:
Distribution选择WSL-Ubuntu,Installer选择local,(runfile() 和 deb() 都是命令行工具,runfile(local) 是 NVIDIA 针对自己的显卡发布的一个安装脚本。相比于 runfile(local) 命令,deb(local) 命令使用更加方便。deb(local) 命令是针对基于 Debian Linux 的系统设计的,在这些系统上可以使用 apt 命令安装软件包,推荐使用 deb(local))
选择好配置后会出下如下命令(Windows是一个exe的下载链接,也体现出了Linux使用命令行下载的方便)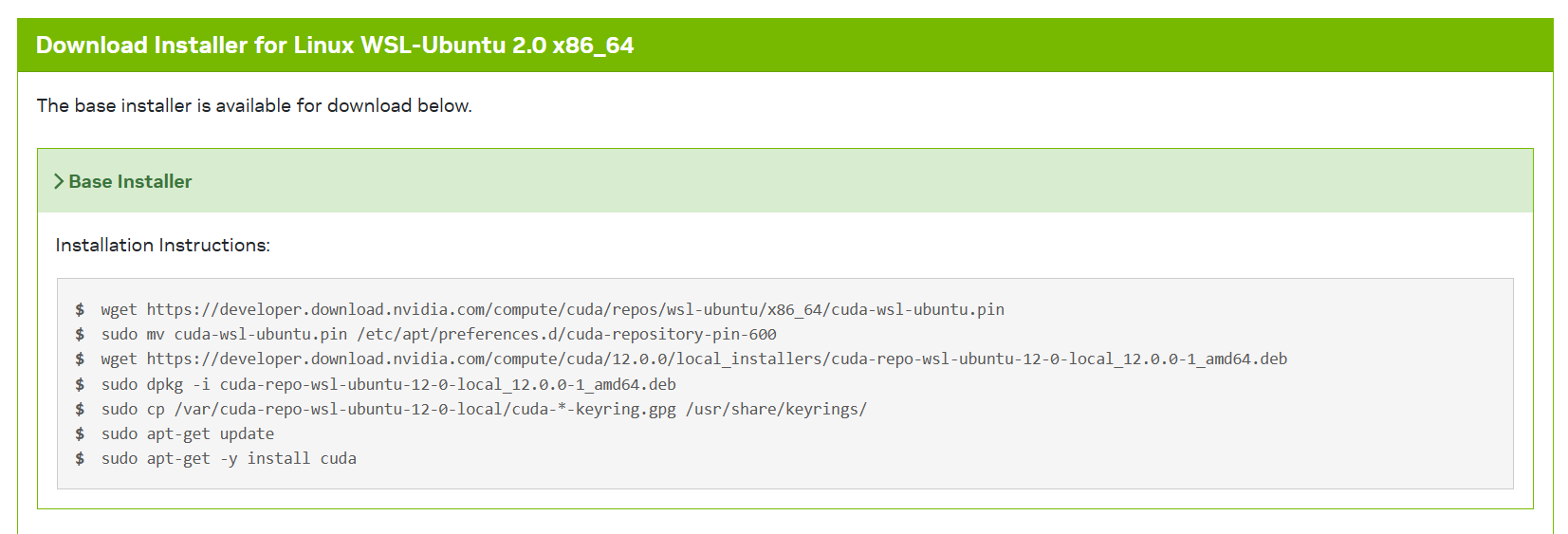
打开WSL终端,依次复制指令输入即可。
下载完毕后需要配置环境变量(Windows会自动配置,Linux需要手动输入路径到配置配置环境)
查看下载后的版本号(文件名):

记住这个标红的文件夹名!
配置环境,在终端中输入:
sudo nano ~/.bashrc 便会用nano打开.bashrc文件(nano是Linux中的一个轻量级的命令行文本编辑器,不习惯命令行的朋友可以使用gedit,一款图形化文本编辑器)
打开.bashrc后其他的配置千万不要更改!查看版本号后在文件最后加入如下配置(更改版本号为自己下载的的版本!)
添加配置:
#config cuda export LD_LABRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.0/lib64 export PATH=$PATH:/usr/local/cuda-12.0/bin export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.0 export PATH=/usr/local/cuda/bin:$PATH 保存退出即可,然后输入如下指令使刚才的配置生效:
source ~/.bashrc 同样输入nvcc -V查看是否配置成功
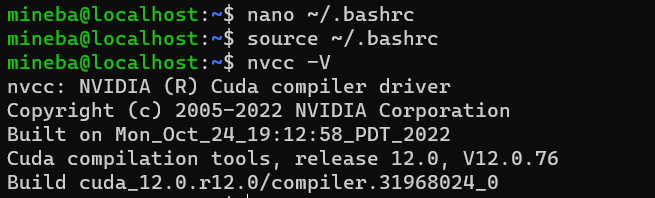
出现如上则说明配置成功
测试运行:
下面在WSL下测试和运行第一个CUDA程序(终端):
创建一个文件命名为 “test.cu”,写入代码:
# include <stdio.h> __global__ void hello_from_GPU() { printf("hello from GPU \n"); } int main(void){ hello_from_GPU<<<4, 4>>>(); cudaDeviceSynchronize(); return 0; } 这段代码的意思大概是定义了一个核函数,作用是输出"hello from GPU" , 然后在main函数里调用这个函数,<<<4, 4>>>意思是使用4个线程块,每个线程块打开4个线程,即输出16次 “hello from GPU” 这便是一个最简单的CUDA的helloworld程序。
写入代码后用如下指令编译:
nvcc -o test test.cu 这段编译指令和gcc的一模一样(只有编译器名字不同),编译结果便是得到一个名为 “test”(自己设定的名字)的二级制执行文件,直接执行这个文件即可 ./test,注意:前面要加相对路径./ 否则找不到文件。
编译和执行结果的全过程如下:
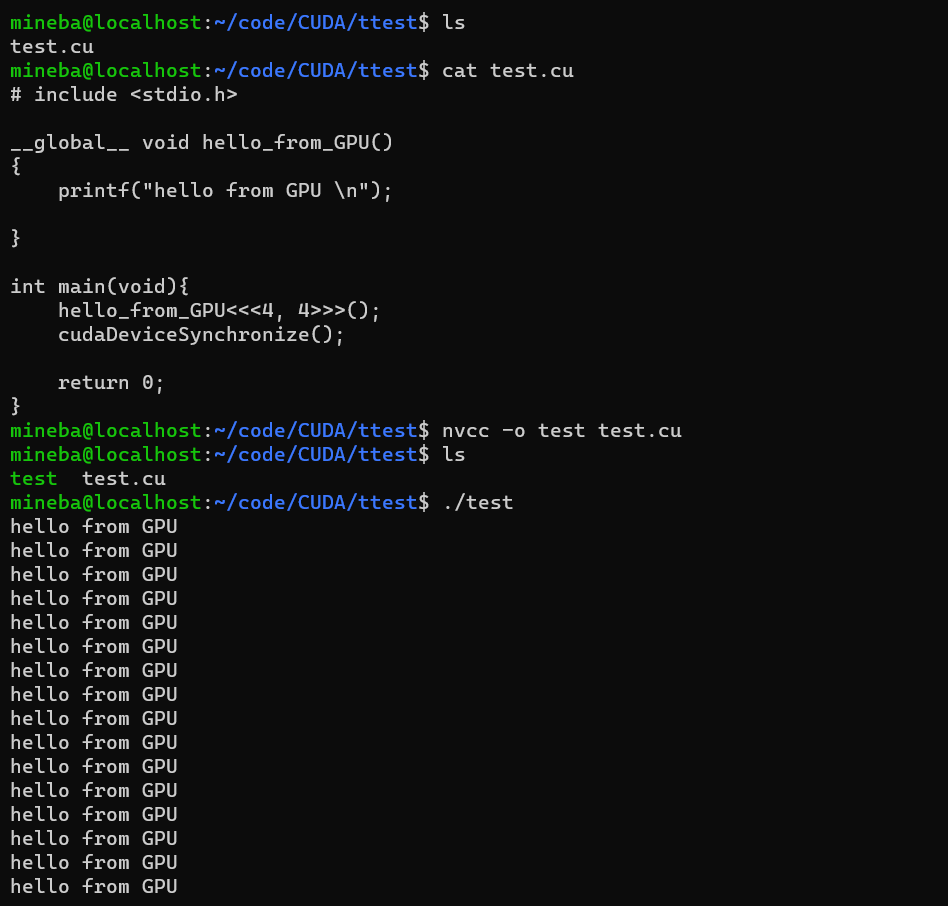
这样便完成了在WSL下的CUDA配置和第一个helloworld程序的运行。当然如果主系统中有vscode的话也可以用vscode打开test.cu(不必再WSL子系统中单独下载vscode)
code ./test.cu
打开后界面如下:
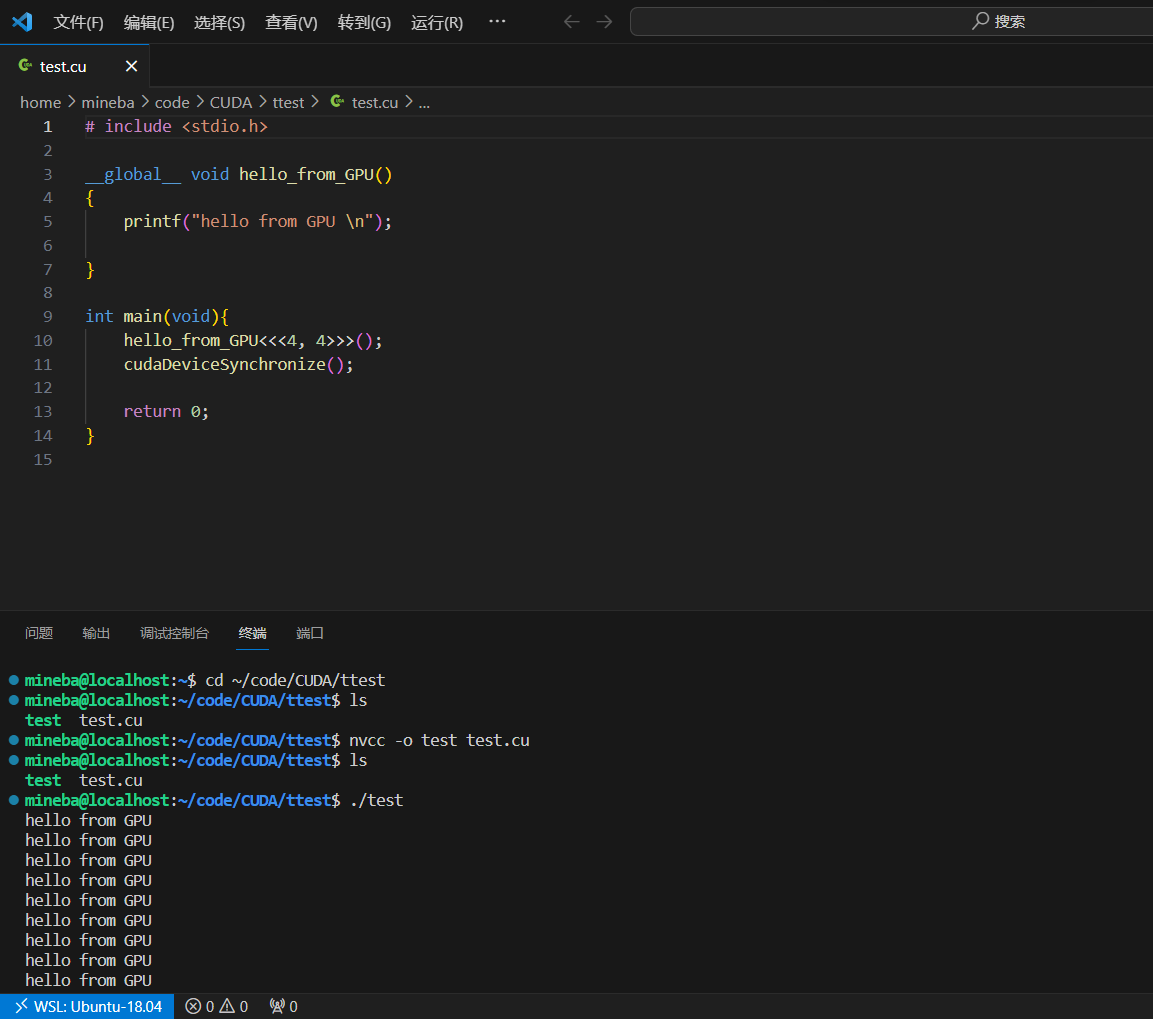
左下角蓝色部分表示用主系统的vscode连接上了WSL,这样即可以使用WSL的Linux的终端窗口,又可以高效的利用vscode良好的生态来管理代码和文件,调试代码非常方便,十分推荐!
关于CUDA的简介,以及在Windows和Linux下的配置过程,和在不同系统下分别测试运行第一个CUDA程序就到此结束,后面将会介绍CUDA的编程学习(用WSL为主)
