
阅读量:0
问题复现:
Spring服务在启动的时候经常发现会在一个地方停顿很久,通过日志看到Spring 在初始化 Druid 数据的时候进行了阻塞操作,导致耗时接近2s
 耗时对服务本身未造成太大影响,主要在启动的时候浪费了太久的时间
耗时对服务本身未造成太大影响,主要在启动的时候浪费了太久的时间
问题排查:
通过日志发现,在执行完 com.alibaba.druid.pool.DruidDataSource#init 该方法后就进行了卡顿,于是猜想是和数据库相关,开启debug验证猜想。
由于代码中引入了 sharding 的配置,所以默认当前的数据库初始化是由 Sharding 调起
Sharding默认初始化Datasource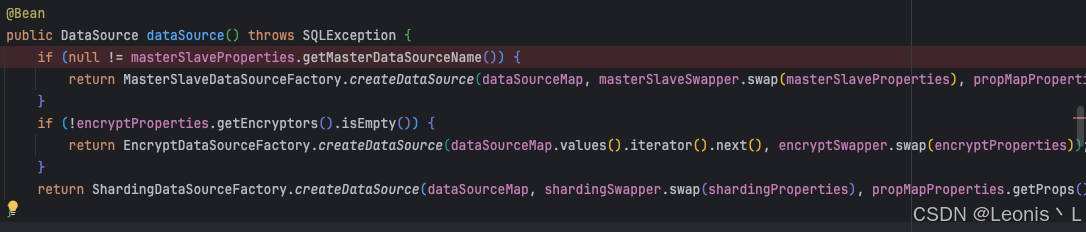
Sharding在初始化 druidDataSource 时会进行一系列初始化操作,随后扫描当前配置下的所有表结构数据load到 metaData 中,Sharding 的 metaData 里面存储了所有需要路由的表结构
Sharding初始化所有表结构数据
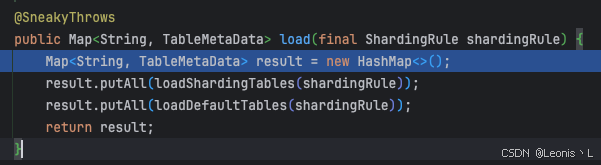
Sharding根据dataSourceName获取表数据
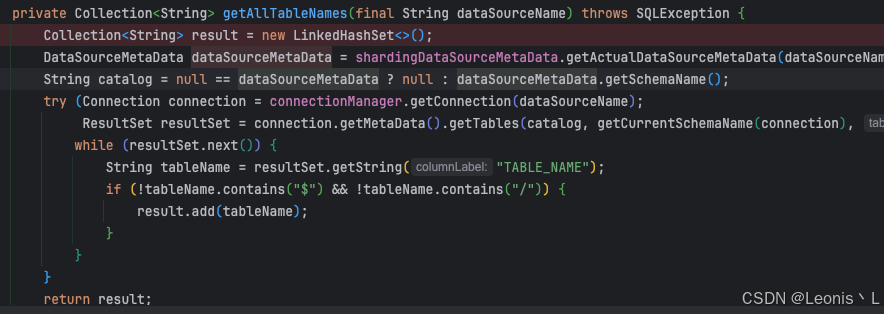
debug发现Sharding在初始化的时候需要扫描 50429 张表,一般的业务不会有这么多张表的,因此肯定是有其他问题导致
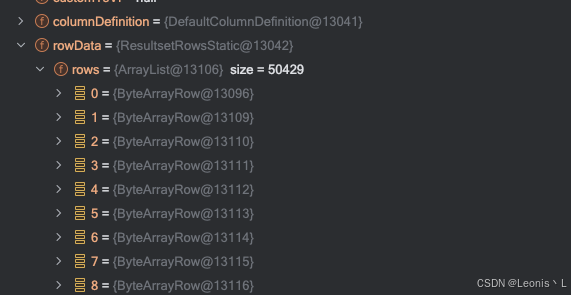
debug继续跟进发现,很多表都不是自己对应的业务表,查看数据库得知,该表是在其他库中的其他表,而我们扫描的这个库应该只有3张表,所以问题在于Sharding扫描的表出了问题
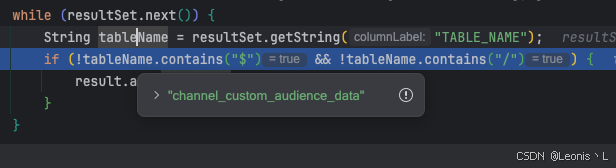
Sharding 获取的链接是正确的,但是在获取对应的 数据库 名字时发生了 Null,找不到对应的库导致了扫描该链接下的所有表结构,而Sharding会在此循环添加datameta数据,因此需要循环5万多次,导致了Spring的启动慢
问题解决:
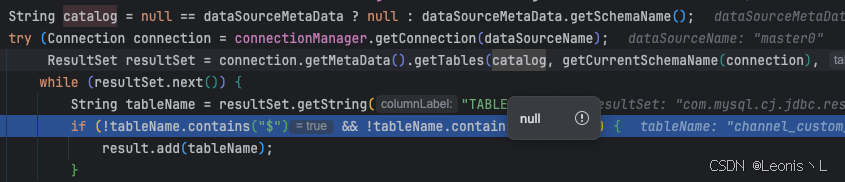
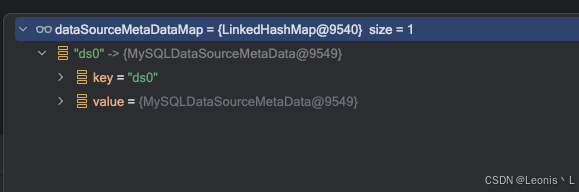
Sharding 读取的库是从 dataSourceMetaDataMap 中获取的,而该 dataSourceMetaDataMap 的数据是由 org.apache.shardingsphere.core.metadata.datasource.ShardingDataSourceMetaData#ShardingDataSourceMetaData 该方法初始化进去的,因此默认就是我们的自己配置
Sharding默认的读取库为 master0
 而初始化到Sharing dataSourceMetaDataMap 中的是 ds0,因此找不到对应的key,导致Sharding扫描了全表数据
而初始化到Sharing dataSourceMetaDataMap 中的是 ds0,因此找不到对应的key,导致Sharding扫描了全表数据
问题原因:
Sharding一般用于分库分表,在测试环境下,未进行分库分表操作,只有单库,开发同学直接将生产的分库分表配置拷贝过来,导致Sharding 默认还是走了分库分表策略,但是对应的分库和主库名称一样,导致Sharding无法区分
在单库的情况下,sharding默认提供了 default-datasource-name 的配置
配置如下:
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name= master0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names =master0 spring.shardingsphere.sharding.tables.test_table.actual-data-nodes=ds$->{0}.snapshot_$->{2021..2024}-$->{01..12}-$->{01..31} 修改后的配置:
spring.shardingsphere.sharding.default-datasource-name = master0 spring.shardingsphere.sharding.tables.test_table.actual-data-nodes = mater$->{0}.test_table_$->{2021..2024}-$->{01..12}-$->{01..31}修改后的启动时长:

