
阅读量:0
文章目录
Elasticsearch 的聚合(Aggregations)功能允许用户对数据集进行聚合分析,从而获得数据的摘要信息。
聚合应用于搜索结果,帮助用户理解数据的分布、统计和模式。
一,基本概念
聚合提供了从数据中分组和提取数据的能力。聚合类似于 SQL GROUPBY 和 SQL 聚合函数。
- 桶(Buckets):桶是聚合的基础,用于将数据分组。每个桶代表一个分组,可以基于不同的标准,如日期范围、数值范围、术语等。
- 度量(Metrics):度量聚合用于计算数值字段的统计数据,如总和、平均值、最小值、最大值、计数等。
- 管道聚合(Pipeline Aggregations):管道聚合是对其他聚合结果进行二次处理的聚合,如计算移动平均值、百分比变化等。
- 子聚合(Sub-Aggregations):子聚合允许在桶内部进一步细分数据,可以嵌套使用。
主要聚合类型
- terms:基于字段的术语进行分组,并为每个术语提供度量(如计数)。
- histogram:基于数值字段创建数值区间(桶),并计算每个区间内的文档数量。
- date_histogram:类似于histogram,但是专门用于日期字段,可以按照年、月、日等时间单位分组。
- range:基于指定的范围表达式对数值或日期字段进行分组。
- significant_terms:找出在特定数据集中出现的显著术语,与常规terms聚合不同,它基于统计测试来确定哪些术语是显著的。
- cardinality:提供一个字段中唯一值的近似计数,这个聚合类型对于大数据集很有用,因为它比普通的unique计数更高效。
- avg、sum、min、max:这些聚合类型分别计算数值字段的平均值、总和、最小值和最大值。
- stats 和 extended_stats:提供数值字段的多种统计信息,包括平均值、总和、最小值、最大值、标准差等。
二,实战
以下Demo都是基于对索引bank的搜索。
1,搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search { "query": { "match": { "address": "mill" } }, "aggs": { "group_by_state": { "terms": { "field": "age" } }, "avg_age": { "avg": { "field": "age" } } }, "size": 0 } query:定义了搜索的具体条件。match:这是一个全文搜索查询,用于搜索address字段中包含"mill"的文档。
aggs:定义了聚合操作,用于对搜索结果进行分组和统计分析。group_by_state:这是一个terms聚合,命名为group_by_state(注意,则个名称是自定义的,不是标准字段),它将结果基于age字段的术语进行分组,并为每个年龄提供计数。terms:指定使用age字段进行分组并统计文档数量。
avg_age:这是一个度量聚合,命名为avg_age(也是自定义名称),用于计算所有匹配文档的age字段的平均值。avg:指定聚合类型为平均值。
size:指定返回的文档数量。在这里设置为0,表示不返回任何匹配的文档,只返回聚合结果。
查询解释:
- 这个查询将返回所有
address字段包含"mill"的文档,但不会返回这些文档本身,只返回基于这些文档的聚合分析结果。
聚合解释:
group_by_state聚合将为每个不同的年龄值创建一个桶,并计算每个年龄组中有多少文档。例如,如果有多个文档的age字段是30,它们将被归为一个桶,并且这个桶的计数将是这些文档的数量。avg_age聚合将计算所有匹配文档的age字段的平均值,提供一个单一数值,表示所有这些文档年龄的平均。
查询结果:
聚合结果包含在响应体中的aggregations对象中,这个对象中有我们命名的两个属性avg_age和group_by_state,属性值包含聚合结果。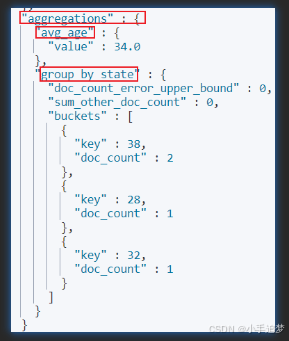
2,按照年龄聚合,并且请求每个年龄的平均薪资
这是一个桶聚合,先按照年龄分桶,统计每个年龄的人数,然后统计每个桶内的人的平均薪资。
注意下面的写法,最外层聚合是按照年龄分桶,嵌套子聚合是外层聚合的基础上统计桶内人的平均薪资。
GET bank/_search { "query": { "match_all": {} }, "aggs": { "group_by_age": { "terms": { "field": "age" }, "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } }, "size": 0 } query:定义了搜索的具体条件。match_all:这是一个查询,它匹配所有文档。这意味着搜索结果将包括bank索引中的所有文档。
aggs:定义了聚合操作,用于对搜索结果进行分组和统计分析。group_by_age:这是一个terms聚合,它将结果基于age字段的值进行分组。terms:指定使用age字段进行分组,这将创建一个桶为每个不同的年龄值。aggs:在这个terms聚合内部,定义了一个子聚合avg_balance。avg_balance:这是一个度量聚合,用于计算每个年龄组的账户余额(balance字段)的平均值。avg:指定聚合类型为平均值,计算每个年龄桶中balance字段的平均数。
size:指定返回的文档数量。在这里设置为0,表示不返回任何匹配的文档,只返回聚合结果。
聚合解释:
group_by_age聚合将为每个不同的年龄值创建一个桶,并计算每个年龄组中的文档数量。- 在每个年龄桶内,
avg_balance子聚合将计算该年龄组内所有文档的balance字段的平均值。
这个DSL的用例是分析银行索引中不同年龄段的平均账户余额。结果将展示每个年龄组的账户平均余额,这可以用于了解不同年龄段的财务状况或进行市场分析。
