
阅读量:0
在上一篇文章Docker下拉取zookeeper镜像中我们已经成功地拉取了3.5.9版本的zookeeper官方镜像以及bitnami镜像,下面将通过使用bitnami的Kafka镜像搭配使用bitnami的zookeeper镜像来体验Kafka的使用。
Kafka是一个分布式流处理平台和消息队列系统,旨在实现高吞吐量、持久性的日志型消息传输,并广泛应用于构建实时数据管道和大规模事件驱动型应用程序。作为一个高效的分布式发布-订阅消息系统,Kafka具有可水平扩展、容错性强、并支持多订阅者的特点,适用于构建实时数据流的处理和存储,以及日志聚合、监控等场景。
拉取Kafka镜像

docker pull bitnami/kafka:3.2.1注意这里拉取的是3.2.1版本的bitnami发行的Kafka镜像。
查看镜像安装情况

创建容器
下面我们使用Docker Compose来创建Docker Kafka的容器。
Docker Compose是一个用于定义和运行多容器Docker应用程序的工具,通过一个简单的YAML文件来配置应用的服务、网络和卷等,使得开发人员能够轻松地搭建和管理复杂的多容器应用环境,并实现一键启动整个应用栈的便利。
version: "2" services: # Zookeeper 服务配置 zookeeper: image: bitnami/zookeeper:3.5.9 ports: - "2181:2181" # 将容器内的Zookeeper端口映射到主机的2181端口 environment: - ALLOW_ANONYMOUS_LOGIN=yes # 设置允许匿名登陆 networks: - mynetwork # Kafka节点1配置 kafka1: image: bitnami/kafka:3.2.1 ports: - "9091:9091" # 将容器内的Kafka端口映射到主机的9091端口 environment: - ALLOW_PLAINTEXT_LISTENER=yes # 允许Kafka监听器使用明文传输 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 # 指定Kafka连接的Zookeeper实例 - KAFKA_BROKER_ID=1 # 设置Kafka Broker ID为1 - KAFKA_CFG_LISTENERS=INSIDE://:9092,OUTSIDE://0.0.0.0:9091 # 定义Kafka监听器,允许内部和外部访问 - KAFKA_CFG_ADVERTISED_LISTENERS=INSIDE://kafka1:9092,OUTSIDE://<你的IP>:9091 # 广告发布的监听器,用于外部客户端访问 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT # 定义内部和外部监听器的安全协议 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INSIDE # 定义节点间通信的监听器名称 depends_on: - zookeeper # kafka1依赖于zookeeper服务,确保在启动kafka1之前先启动zookeeper networks: - mynetwork # Kafka节点2配置 kafka2: image: bitnami/kafka:3.2.1 ports: - "9093:9093" # 将容器内的Kafka端口映射到主机的9093端口 environment: - ALLOW_PLAINTEXT_LISTENER=yes # 允许Kafka监听器使用明文传输 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 # 指定Kafka连接的Zookeeper实例 - KAFKA_BROKER_ID=2 # 设置Kafka Broker ID为2 - KAFKA_CFG_LISTENERS=INSIDE://:9092,OUTSIDE://0.0.0.0:9093 # 定义Kafka监听器,允许内部和外部访问 - KAFKA_CFG_ADVERTISED_LISTENERS=INSIDE://kafka2:9092,OUTSIDE://<你的IP>:9093 # 广告发布的监听器,用于外部客户端访问 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT # 定义内部和外部监听器的安全协议 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INSIDE # 定义节点间通信的监听器名称 depends_on: - zookeeper # kafka2依赖于zookeeper服务,确保在启动kafka2之前先启动zookeeper networks: - mynetwork # Kafka节点3配置 kafka3: image: bitnami/kafka:3.2.1 ports: - "9094:9094" # 将容器内的Kafka端口映射到主机的9094端口 environment: - ALLOW_PLAINTEXT_LISTENER=yes # 允许Kafka监听器使用明文传输 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 # 指定Kafka连接的Zookeeper实例 - KAFKA_BROKER_ID=3 # 设置Kafka Broker ID为3 - KAFKA_CFG_LISTENERS=INSIDE://:9092,OUTSIDE://0.0.0.0:9094 # 定义Kafka监听器,允许内部和外部访问 - KAFKA_CFG_ADVERTISED_LISTENERS=INSIDE://kafka3:9092,OUTSIDE://<你的IP>:9094 # 广告发布的监听器,用于外部客户端访问 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT # 定义内部和外部监听器的安全协议 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INSIDE # 定义节点间通信的监听器名称 depends_on: - zookeeper # kafka3依赖于zookeeper服务,确保在启动kafka3之前先启动zookeeper networks: - mynetwork networks: mynetwork: driver: bridge注意将文件的名称命名为docker-compose.yml,同时正确填入<你的IP>
将控制台的路径调整到docker-compose.yml文件的位置。

![]()
docker-compose up查看容器
如果使用的是Docker Desktop的话可以直接看到容器的情况。
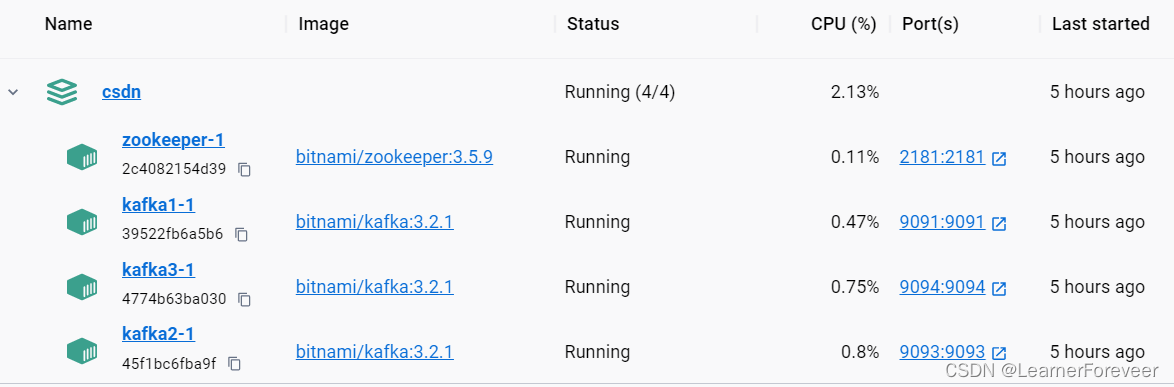
如果不是的话可以通过命令查看容器创建的情况。
docker ps -a
创建topic
Kafka主题(topic)是消息的逻辑分类单元,用于对消息进行分组和管理,生产者发布消息到特定主题,而消费者订阅感兴趣的主题来接收消息,实现了解耦、并行处理和灵活的数据管理。Kafka主题在构建可靠、高吞吐量的消息处理系统中扮演着重要角色。
下面我们在容器中创建一个名为“csdn”的topic
首先进入到其中一个Kafka节点中:
docker exec -it <你的节点名称> bin/bash之后需要创建一个topic并设置相关配置:
kafka-topics.sh --create --topic <topic的名称> --bootstrap-server localhost:9092 --partitions 3 --replication-factor 3这个命令是使用kafka-topics.sh工具在本地的Kafka集群上创建一个新的主题。该主题被命名为<topic的名称>,并且设置了3个分区和每个分区有3个副本。这意味着每个分区中的消息将被复制到3个不同的副本以提高容错性和可用性。Bootstrap服务器配置为本地主机的9092端口,这是Kafka集群的启动服务器地址和端口号。通过执行这个命令,我们可以在Kafka中创建一个可用于发布和订阅消息的新主题。
最后查看topic:
kafka-topics.sh --bootstrap-server localhost:9092 --topic <需要查看的topic> --describe
可以看到此时topic被成功创建完成了。
创建Maven项目
Kafka的核心功能包括消息传递、存储和处理,能够实现可靠的数据传输、实时流处理和数据管道构建,同时支持发布-订阅模式和批处理。
下面我们将通过使用一个Maven项目向Kafka队列中发布消息,同时进行订阅。项目的引用的依赖如下:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>3.2.1</version> </dependency>创建一个包(package)用来存放生产者(producer)的代码,创建一个包用存放消费者(consumer)的代码:

生产者
在Kafka中,生产者是将消息发送到Kafka集群的组件。生产者的主要作用是将消息以可持久化的方式发布到一个或多个主题(topics)。
以下是生产者在Kafka中的作用:
发送消息:生产者负责将消息发送到Kafka集群。生产者可以将消息发送到一个或多个主题,并且可以指定消息的键(key),以便对消息进行分区和排序。
持久化:生产者将消息以持久化的方式写入Kafka的日志文件中。这样一来,即使消费者暂时不消费消息,消息也会被保存在磁盘上,并且在后续可以被消费者消费。
分区和负载均衡:生产者可以根据配置的分区策略将消息发送到不同的分区中。这样可以实现负载均衡,同时也可以确保相关的消息被发送到同一个分区中。
异步发送:生产者可以以异步的方式发送消息,这意味着生产者可以在消息发送后继续处理其他任务,而不需要等待Kafka的响应。这种异步发送方式可以提高生产者的吞吐量。
生产者是将消息发送到Kafka集群,并确保消息被持久化的重要组件。它使得应用程序可以将消息发送到Kafka主题,并且可以方便地实现可靠的消息传递和数据处理。
下面我们来创建一个随机生成整型数字的生产者:
package producer; import org.apache.kafka.clients.producer.*; import java.util.Properties; import java.util.Random; public class RandomProducer { public static Random rd = new Random(); // 创建一个随机数生成器 public static void main(String[] args) throws InterruptedException { String TOPIC = "<你的队列topic>"; // 指定要发送消息的主题名称 Properties props = new Properties(); // 创建用于配置生产者的属性对象 // 设置连接到Kafka集群所需的属性 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9091,localhost:9093,localhost:9094"); // 指定Kafka集群地址 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器 props.put(ProducerConfig.ACKS_CONFIG, "0"); // 设置消息确认级别为0(不等待任何确认) KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props); // 创建Kafka生产者 for (int i = 0; i < 999; i++) { double d = 0.1 + (3 - 0.1) * rd.nextDouble(); // 生成0.1到3之间的浮点数用来表示间隔时间 String message = String.format("sleep time:%.2f s", d); // 格式化消息内容 ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC, message); // 创建要发送的消息记录 kafkaProducer.send(producerRecord); // 发送消息到主题 System.out.printf("发送消息“%s”\n", message); // 打印发送的消息内容 Thread.sleep((long) Math.floor(d * 1000)); // 根据生成的间隔时间进行等待 } // 关闭消息生产者对象 kafkaProducer.close(); } }注意将上面代码中的TOPIC变量改成实际你创建的队列主题。

在kafka节点命令行中监视队列来模拟消费者:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic <topic的名称>
此时进入监视状态,当生产者发布消息进入队列时,就将在这里打印出来。
运行生产者同时观察消费者情况:
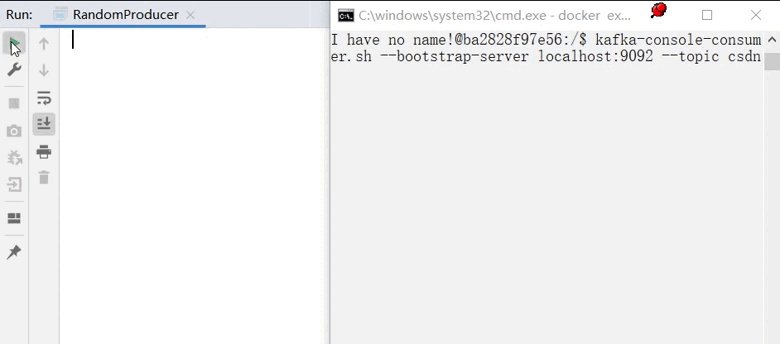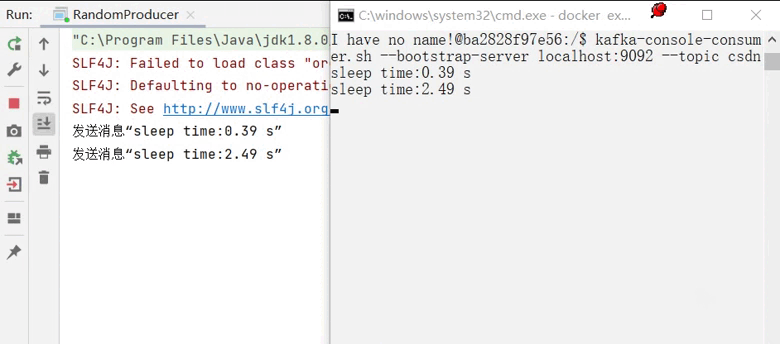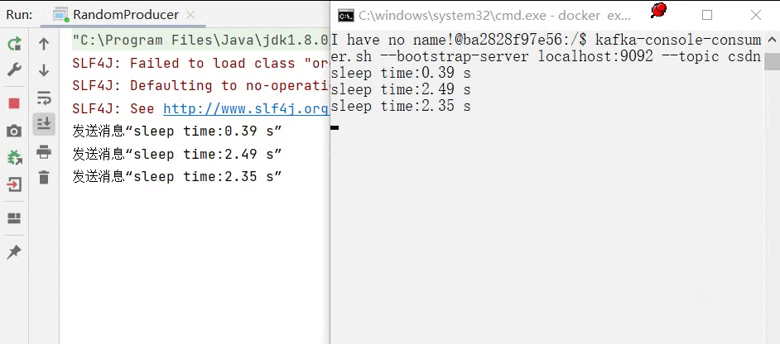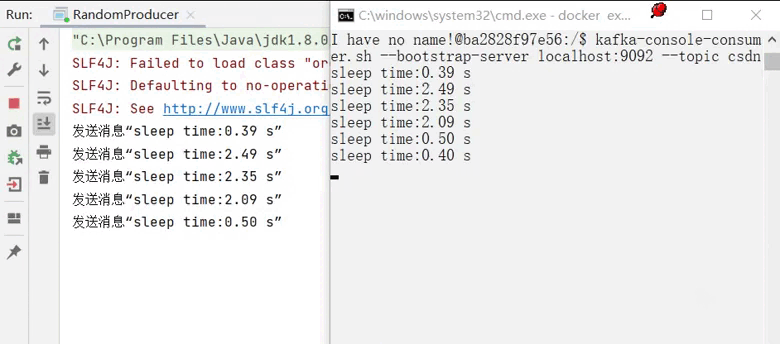
到此我们就成功完成了生产者的部分。
消费者
在上一节中我们通过Kafka自带的kafka-console-consumer.sh脚本完成完成了消费者的模拟,在这一节中将介绍怎样在Maven项目中创建一个自定义的消费者以满足项目的需求。
下面来写一个接收队列中内容并求和打印的消费者:
package consumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Collections; import java.util.Properties; public class RandomConsumer { public static void main(String[] args) { String TOPIC = "<你的队列topic>"; Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9091,localhost:9093,localhost:9094"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");// 取消自动提交 防止消息丢失 props.put(ConsumerConfig.GROUP_ID_CONFIG, "<你需要的分组id>");//指定分组的名称 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props); kafkaConsumer.subscribe(Collections.singletonList(TOPIC)); double sum_num = 0; while (true) { ConsumerRecords<String, String> consumerRecord = kafkaConsumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> cr : consumerRecord) { double num = Double.parseDouble(cr.value()); sum_num += num; System.out.printf("当前偏移量为:%d,num:%.3f,sum num:%.3f\n", cr.offset(), num, sum_num); kafkaConsumer.commitSync(); } } } } 注意将上面代码中的TOPIC变量和分组id改成实际你创建的队列主题。
之后再控制台中打开一个生产者来对消费者进行测试:
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic <你的topic> 运行消费者,并在生产者输入中输入消息,观察消费者打印的情况: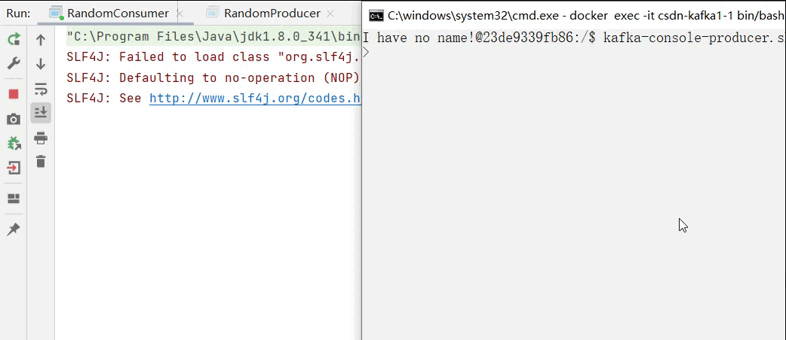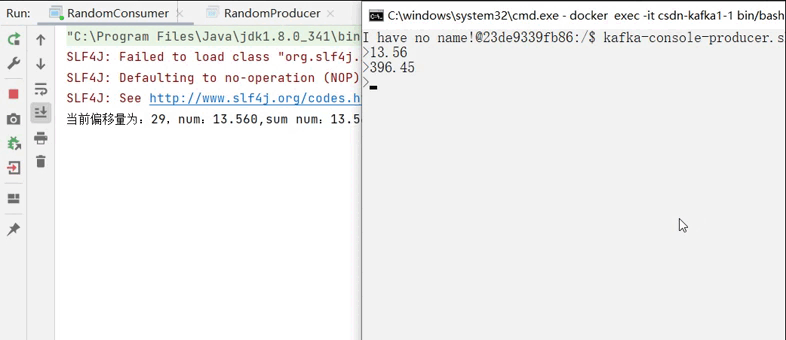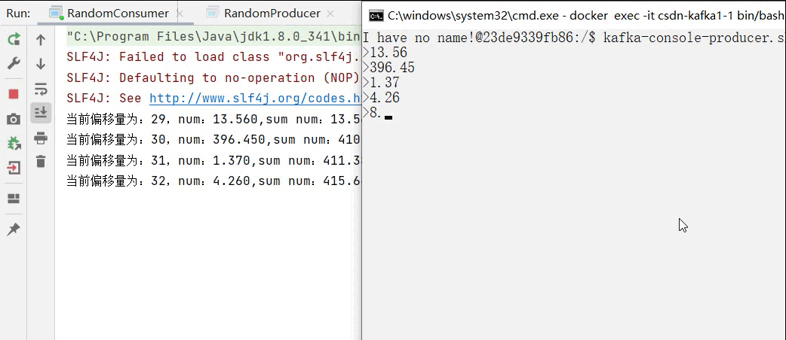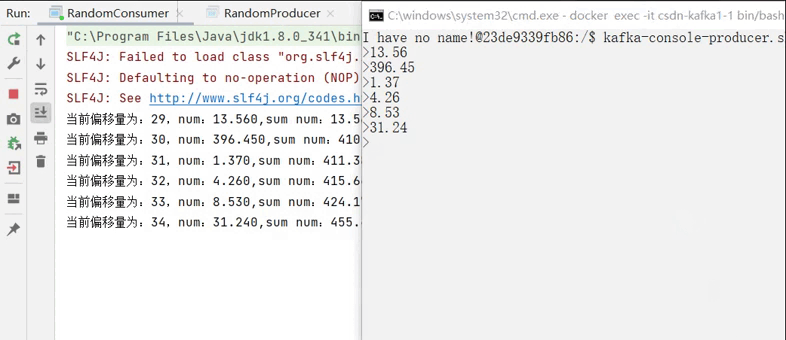
至此,基于docker的kafka集群的搭建和使用就全部完成了。
下一篇:Docker下的Storm
