
阅读量:0
一. 原始模型整体概述
U-Net网络是Ronneberger等人在2015年发表于计算机医学影像顶刊 MICCAI上的一篇论文,该论文首次提出了一种U型结构来进行图像的语义分割,论文的下载链接如下:U-Net: Convolutional Networks for Biomedical Image Segmentation
该网络赢得了2015年ISBI细胞跟踪挑战赛,一经提出便获得了巨大的关注,在计算机视觉领域的影响堪比凯明大神的ResNet网络,也正巧是同一年提出的,2015年真是一个AI的爆发之年,再后来便就是2017年的transformer网络提出了。
闲话少说,我们先来看一下U-Net网络的整体架构图,如下图所示:
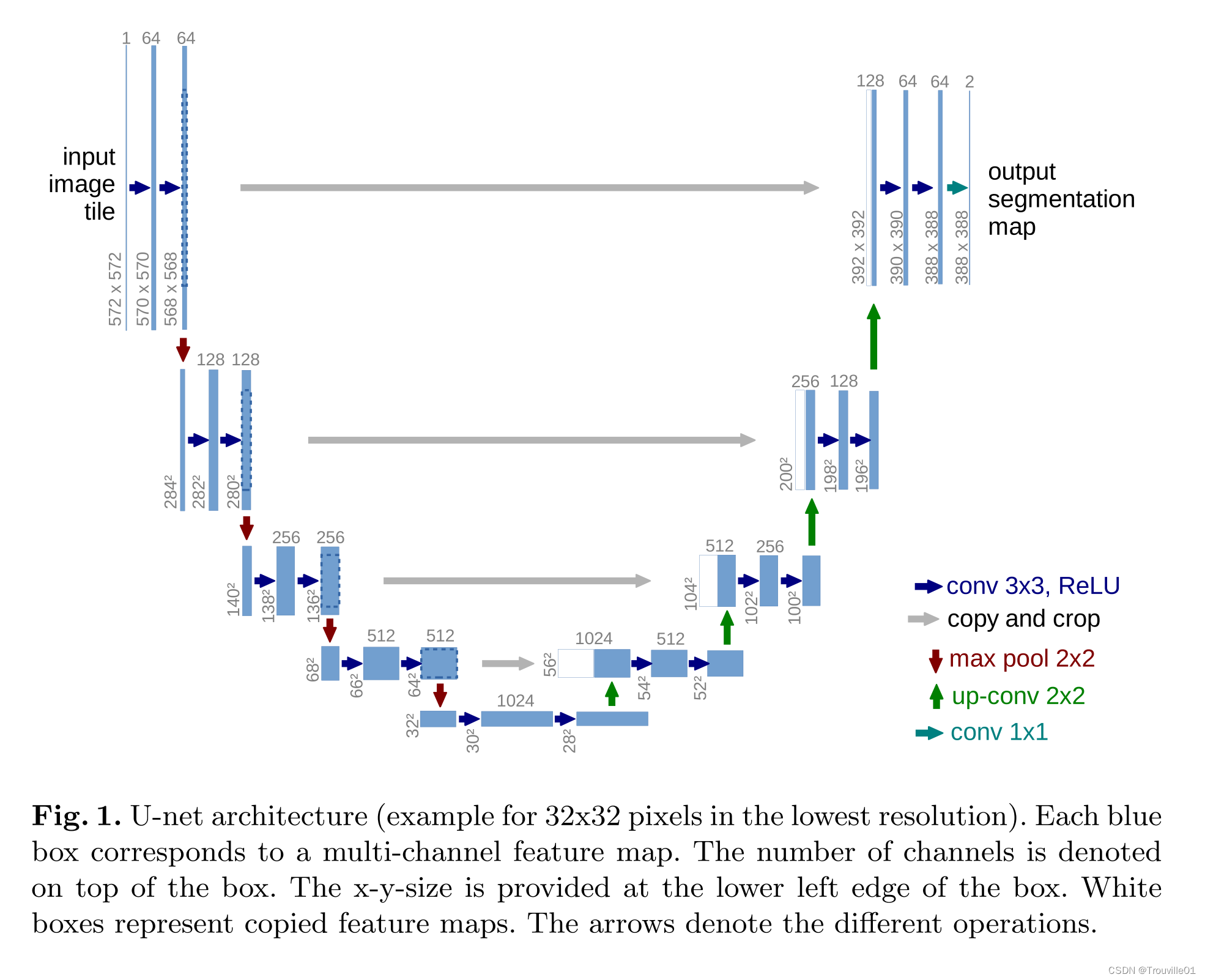
该模型主要由两个部分组成,左边是编码器(文章里称作收缩路径,contracting path),右边是解码器( 文章里称作膨胀路径,expansive path)。这种U型结构和跳跃连接可以更好地获取上下文信息和位置信息。
其中编码器的每一行遵守常规卷积神经网络的典型架构,由两个3x3的卷积(无padding操作)构成。每个卷积层的后面跟随一个整流线性单元ReLU和一个2x2的最大池化操作,步幅为2,用于下采样,在每个下采样的过程中将特征通道数翻倍。
解码器的每一步都包含特征图的上采样,然后是一个将特征通道数量减半的2x2卷积(“上卷积”),与收缩路径中相应裁剪的特征map进行连接,以及两个3x3卷积,每个卷积后面都有一个ReLU。由于在每次卷积中边界像素的损失,所以需要裁剪(crop)。在最后一层,使用1x1卷积将每个64个分量的特征向量map到所需的类数。这个网络总共有23个卷积层。
U-Net网络的优点及为什么在医学影像中表现优异:
1.通过跳跃连接,补充了语义信息的丢失。深层卷积得到的特征图有着更大的感受野,关注更多抽象的粗粒度的信息;而浅层卷积则关注纹理,颜色,边缘特征等中高级语义信息,所以深层浅层特征都是有意义的;另外一点是通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现特征信息的找回。由于医学影像中的所有特征都很重要,所以跳跃连接起到了关键作用。
2.U-Net模型的结构比较简单,在模型参数较少的情况下获得了更多的语义信息,所以在数据规模较小的医学影像数据集上表现出更好的效果。
二. U-Net模型的改进
通过上述模型架构设计,我们很容易发现这个架构图有一些不便之处,我们可以将模型改成以下结构来方便模型构建并改善模型性能。这也是当前最流行的U-Net构造方法。
1.将卷积层的padding设置为1。由于编码器和解码器中使用的卷积层都没有进行padding操作,卷积层核大小为3x3,stride为1,padding=0,这就是一个很普通的卷积层,卷积之后,特征图的高和宽会各减少2。具体计算步骤:N=(W-F+2P)/S+1,其中N为输出特征图的大小,W为输入特征图大小,F为卷积核大小,P为padding的像素个数,S为stride的大小。则N = (572-3+0)/1 +1= 570。
我们如果将padding设置为1,则卷积操作后特征图的高和宽都不会发生变化,这样的话就免去了拼接时由于尺寸不一致而产生额外的裁剪操作,改进之后可以直接concat,而不用crop操作。此外,这种做法可以保证输入的图像大小核输出的图像大小完全一致,避免了边缘缺失导致的误差。
2.在每个卷积层和ReLu之间加上Batch normalization,这个做可以加速网络训练并提升网络精度。关于BN层的原理和作用,请参见另外一篇优质博文:BN层的原理和作用
三.改进U-Net模型的完整代码
from typing import Dict import torch import torch.nn as nn import torch.nn.functional as F # 定义双卷积类 class DoubleConv(nn.Sequential): def __init__(self, in_channels, out_channels, mid_channels=None): if mid_channels is None: mid_channels = out_channels super(DoubleConv, self).__init__( # 定义padding为1,保持卷积后特征图的宽度和高度不变,具体计算N= (W-F+2P)/S+1 nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False), # 加入BN层,提升训练速度,并提高模型效果 nn.BatchNorm2d(mid_channels), nn.ReLU(inplace=True), # 第二个卷积层,同第一个 nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False), # BN层 nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) # 调用上面定义的双卷积类,定义下采样类 class Down(nn.Sequential): def __init__(self, in_channels, out_channels): super(Down, self).__init__( # 最大池化,步长为2,池化核大小为2,计算公式同卷积,则 N = (W-F+2P)/S+1, N= (W-2+0)/4 + 1 nn.MaxPool2d(2, stride=2), DoubleConv(in_channels, out_channels) ) class Up(nn.Module): def __init__(self, in_channels, out_channels): super(Up, self).__init__() # 调用转置卷积的方法进行上采样,使特征图的高和宽翻倍,out =(W−1)×S−2×P+F,通道数减半 self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) # 调用双层卷积类,通道数是否减半要看out_channels接收的值 self.conv = DoubleConv(in_channels, out_channels) def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor: x1 = self.up(x1) # X的shape为[N, C, H, W],下面三行代码主要是为了保证x1和x2在维度为2和3的地方保持一致,方便cat操作不出错。 diff_y = x2.size()[2] - x1.size()[2] diff_x = x2.size()[3] - x1.size()[3] # 增加padding操作,padding_left, padding_right, padding_top, padding_bottom x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2, diff_y // 2, diff_y - diff_y // 2]) x = torch.cat([x2, x1], dim=1) x = self.conv(x) return x # 定义输出卷积类 class OutConv(nn.Sequential): def __init__(self, in_channels, num_classes): super(OutConv, self).__init__( nn.Conv2d(in_channels, num_classes, kernel_size=1) ) class UNet(nn.Module): def __init__(self, in_channels: int = 1, # 默认输入图像的通道数为1,这里一般黑白图像为1,而彩色图像为3 num_classes: int = 2, # 默认输出的分类类别数为2 # 默认基础通道为64,这里也可以改成大于2的任意2的次幂,不过越大模型的复杂度越高,参数越大,模型的拟合能力也就越强 base_c: int = 64): super(UNet, self).__init__() self.in_channels = in_channels self.num_classes = num_classes # 编码器的第1个双卷积层,不包含下采样过程,输入通道为1,输出通道数为base_c,这个值可以为64或者32 self.in_conv = DoubleConv(in_channels, base_c) # 编码器的第2个双卷积层,先进行下采样最大池化使得特征图高和宽减半,然后通道数翻倍 self.down1 = Down(base_c, base_c * 2) # 编码器的第3个双卷积层,先进行下采样最大池化使得特征图高和宽减半,然后通道数翻倍 self.down2 = Down(base_c * 2, base_c * 4) # 编码器的第4个双卷积层,先进行下采样最大池化使得特征图高和宽减半,然后通道数翻倍 self.down3 = Down(base_c * 4, base_c * 8) # 编码器的第5个双卷积层,先进行下采样最大池化使得特征图高和宽减半,然后通道数翻倍 self.down4 = Down(base_c * 8, base_c * 16) # 解码器的第1个上采样模块,首先进行一个转置卷积,使特征图的高和宽翻倍,通道数减半; # 对x1(x1可以到总的forward函数中可以知道它代指什么)进行padding,使其与x2的尺寸一致,然后在第1维通道维度进行concat,通道数翻倍。 # 最后再进行一个双卷积层,通道数减半,高和宽不变。 self.up1 = Up(base_c * 16, base_c * 8) # 解码器的第2个上采样模块,操作同上 self.up2 = Up(base_c * 8, base_c * 4) # 解码器的第3个上采样模块,操作同上 self.up3 = Up(base_c * 4, base_c * 2) # 解码器的第4个上采样模块,操作同上 self.up4 = Up(base_c * 2, base_c) # 解码器的输出卷积模块,改变输出的通道数为分类的类别数 self.out_conv = OutConv(base_c, num_classes) def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]: # 假设输入的特征图尺寸为[N, C, H, W],[4, 3, 480, 480],依次代表BatchSize, 通道数量,高,宽; 则输出为[4, 64, 480,480] x1 = self.in_conv(x) # 输入的特征图尺寸为[4, 64, 480, 480]; 输出为[4, 128, 240,240] x2 = self.down1(x1) # 输入的特征图尺寸为[4, 128, 240,240]; 输出为[4, 256, 120,120] x3 = self.down2(x2) # 输入的特征图尺寸为[4, 256, 120,120]; 输出为[4, 512, 60,60] x4 = self.down3(x3) # 输入的特征图尺寸为[4, 512, 60,60]; 输出为[4, 1024, 30,30] x5 = self.down4(x4) # 输入的特征图尺寸为[4, 1024, 30,30]; 输出为[4, 512, 60, 60] x = self.up1(x5, x4) # 输入的特征图尺寸为[4, 512, 60,60]; 输出为[4, 256, 120, 120] x = self.up2(x, x3) # 输入的特征图尺寸为[4, 256, 120,120]; 输出为[4, 128, 240, 240] x = self.up3(x, x2) # 输入的特征图尺寸为[4, 128, 240,240]; 输出为[4, 64, 480, 480] x = self.up4(x, x1) # 输入的特征图尺寸为[4, 64, 480,480]; 输出为[4, 2, 480, 480] logits = self.out_conv(x) return {"out": logits} 模型代码解读:
1.模型更改:上面是一个完整的U-Net网络的结构,该代码相对于原文的实现主要更改了卷积层的padding和添加了BN层。改善了边缘信息丢失并且由于BN层的添加使模型效率更高;
2.代码主要由两部分组成,一个编码器,一个解码器。编码器由1个初始双卷积层和4个下采样层构成;解码器由4个上采样层和1个输出卷积层构成,其中上采样层由一个转置卷积,对x1进行padding操作,cat操作和1个双卷积层构成。这里解释一下为什么还要padding,如果你在训练数据和测试数据输入时严格按照480*480进行输入,则不需要padding,x1和x2的也会保持相同的形状。而大部分情况下,测试数据不会做裁剪再输入,所以很难保证输入时由于分辨率为奇数时,由于池化和转置卷积的宽和高的减半和翻倍原因导致尺寸有出入而不匹配。如果嫌麻烦,可以删掉padding部分的代码,然后将测试集的图像大小严格resize;
3.模型的执行过程按照UNet类的forward中的顺序执行。
四.模型的关键代码展示
1. transform.py 一些关于数据增强的功能函数类,其实这些类在torchvision中也有实现。
import numpy as np import random import torch from torchvision import transforms as T from torchvision.transforms import functional as F def pad_if_smaller(img, size, fill=0): # 如果图像最小边长小于给定size,则用数值fill进行padding min_size = min(img.size) if min_size < size: ow, oh = img.size padh = size - oh if oh < size else 0 padw = size - ow if ow < size else 0 img = F.pad(img, (0, 0, padw, padh), fill=fill) return img class Compose(object): def __init__(self, transforms): self.transforms = transforms def __call__(self, image, target): for t in self.transforms: image, target = t(image, target) return image, target class RandomResize(object): def __init__(self, min_size, max_size=None): self.min_size = min_size if max_size is None: max_size = min_size self.max_size = max_size def __call__(self, image, target): size = random.randint(self.min_size, self.max_size) # 这里size传入的是int类型,所以是将图像的最小边长缩放到size大小 image = F.resize(image, size) # 这里的interpolation注意下,在torchvision(0.9.0)以后才有InterpolationMode.NEAREST # 如果是之前的版本需要使用PIL.Image.NEAREST target = F.resize(target, size, interpolation=T.InterpolationMode.NEAREST) return image, target class RandomHorizontalFlip(object): def __init__(self, flip_prob): self.flip_prob = flip_prob def __call__(self, image, target): if random.random() < self.flip_prob: image = F.hflip(image) target = F.hflip(target) return image, target class RandomVerticalFlip(object): def __init__(self, flip_prob): self.flip_prob = flip_prob def __call__(self, image, target): if random.random() < self.flip_prob: image = F.vflip(image) target = F.vflip(target) return image, target class RandomCrop(object): def __init__(self, size): self.size = size def __call__(self, image, target): image = pad_if_smaller(image, self.size) target = pad_if_smaller(target, self.size, fill=255) crop_params = T.RandomCrop.get_params(image, (self.size, self.size)) image = F.crop(image, *crop_params) target = F.crop(target, *crop_params) return image, target class CenterCrop(object): def __init__(self, size): self.size = size def __call__(self, image, target): image = F.center_crop(image, self.size) target = F.center_crop(target, self.size) return image, target class ToTensor(object): def __call__(self, image, target): image = F.to_tensor(image) target = torch.as_tensor(np.array(target), dtype=torch.int64) return image, target class Normalize(object): def __init__(self, mean, std): self.mean = mean self.std = std def __call__(self, image, target): image = F.normalize(image, mean=self.mean, std=self.std) return image, target 2. my_dataset.py ,用于数据集的提取和格式化
import os from PIL import Image import numpy as np from torch.utils.data import Dataset class DriveDataset(Dataset): # 继承Dataset类 def __init__(self, root: str, train: bool, transforms=None): super(DriveDataset, self).__init__() self.flag = "training" if train else "test" # 根据train这个布尔类型确定需要处理的是训练集还是测试集 data_root = os.path.join(root, "DRIVE", self.flag) # 得到数据集根目录 assert os.path.exists(data_root), f"path '{data_root}' does not exists." # 判断路径是否存在 self.transforms = transforms # 初始化图像变换操作 img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")] # 遍历图像文件夹获取每个图像的文件名 self.img_list = [os.path.join(data_root, "images", i) for i in img_names] # 获取图像路径 self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif") # 获取手动标签的路径 for i in img_names] # 检查手动标签文件是否存在 for i in self.manual: if os.path.exists(i) is False: raise FileNotFoundError(f"file {i} does not exists.") # 获取分割的ROI区域掩码 self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif") for i in img_names] # check files for i in self.roi_mask: if os.path.exists(i) is False: raise FileNotFoundError(f"file {i} does not exists.") def __getitem__(self, idx): img = Image.open(self.img_list[idx]).convert('RGB') # 加载图像,并转换为RGB模式 manual = Image.open(self.manual[idx]).convert('L') # 加载手动标注图像,并转换为灰度模式 manual = np.array(manual) / 255 # 进行归一化操作 roi_mask = Image.open(self.roi_mask[idx]).convert('L') # 加载ROI图像,并转换为灰度模式 roi_mask = 255 - np.array(roi_mask) # 对图像数组取反,使用这个方法将背景和前景颜色反转,白色是255,黑色是0,反转后ROI变成了内黑外白 mask = np.clip(manual + roi_mask, a_min=0, a_max=255) # 将手动标注图像和反转后的ROI图像相加,使用np.clip()将像素值控制在0-255范围, # 这里转回PIL的原因是,transforms中是对PIL数据进行处理 mask = Image.fromarray(mask) if self.transforms is not None: img, mask = self.transforms(img, mask) return img, mask # 获取图像数据集长度 def __len__(self): return len(self.img_list) # 用于将批量的图像和标签数据合并为一个批张量。 @staticmethod def collate_fn(batch): images, targets = list(zip(*batch)) # 将批量数据拆分为图像和标签两个列表 batched_imgs = cat_list(images, fill_value=0) # 使用 cat_list() 函数将图像和标签列表合并成张量。用于将列表中的 PIL 图像数据堆叠成张量, batched_targets = cat_list(targets, fill_value=255) return batched_imgs, batched_targets def cat_list(images, fill_value=0): max_size = tuple(max(s) for s in zip(*[img.shape for img in images])) # 找到图像中最大的形状,以元组形式返回给max_size batch_shape = (len(images),) + max_size # 计算出堆叠后的张量形状,包括批量大小和图像大小两个维度 batched_imgs = images[0].new(*batch_shape).fill_(fill_value) # 创建一个新的空白张量 batched_imgs,其形状与 batch_shape 相同,并将其填充为指定的填充值 fill_value for img, pad_img in zip(images, batched_imgs): # 使用 zip() 函数将输入列表中的每个图像与其对应的空白张量进行拼接,以得到一个完整的张量。 pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img) # 将每个图像按照其实际大小插入到空白张量的左上角,以保持图像的相对位置不变。 return batched_imgs 3. train.py, 模型训练的代码
import os import time import datetime import torch from src import UNet from train_utils import train_one_epoch, evaluate, create_lr_scheduler from my_dataset import DriveDataset import transforms as T # 定义训练集图像的预处理方式 class SegmentationPresetTrain: def __init__(self, base_size, crop_size, hflip_prob=0.5, vflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)): min_size = int(0.5 * base_size) max_size = int(1.2 * base_size) trans = [T.RandomResize(min_size, max_size)] # 对图像的短边(长和宽中最短的)进行随机缩放以适应不同图像输入尺寸,缩放范围为【min_size, max_size】 if hflip_prob > 0: trans.append(T.RandomHorizontalFlip(hflip_prob)) # 加入水平翻转 if vflip_prob > 0: trans.append(T.RandomVerticalFlip(vflip_prob)) # 加入垂直翻转 trans.extend([ T.RandomCrop(crop_size), # 对图像进行随机裁剪 T.ToTensor(), # 将数组矩阵转换为tensor类型,规范化到【0,1】范围 T.Normalize(mean=mean, std=std), # 加入图像归一化,并定义均值和标准差,RGB三通道的 ]) # trans是一个列表类型,包含各种了变换,将这些变换组成一个compose变换,注意transforms.Compose()函数需要接收一个列表类型 self.transforms = T.Compose(trans) # 使用__call__()函数来调用transforms变换 def __call__(self, img, target): return self.transforms(img, target) # target是指标签图像,img是指待分割图像 # 定义验证集的图像预处理组合类,比较简单,只有张量化和规范化两个操作,这里规范化使用的是ImageNet推荐的参数,注意这种做法是针对彩色图像 class SegmentationPresetEval: def __init__(self, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)): self.transforms = T.Compose([ T.ToTensor(), T.Normalize(mean=mean, std=std), ]) def __call__(self, img, target): return self.transforms(img, target) # 定义一个函数根据数据集的类型来调用对应的数据集处理类 def get_transform(train, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)): base_size = 565 crop_size = 480 # 检查train是否为True if train: return SegmentationPresetTrain(base_size, crop_size, mean=mean, std=std) else: return SegmentationPresetEval(mean=mean, std=std) # 定义模型创建函数,实例化UNet类创建模型,传入通道数,分割类别数, def create_model(num_classes): model = UNet(in_channels=3, num_classes=num_classes, base_c=64) # 输入通道数为3,分类类别数为2, # model = MobileV3Unet(num_classes=num_classes, pretrain_backbone=True) # model = VGG16UNet(num_classes=num_classes, pretrain_backbone=True) return model def main(args): device = torch.device(args.device if torch.cuda.is_available() else "cpu") batch_size = args.batch_size # using compute_mean_std.py mean = (0.709, 0.381, 0.224) std = (0.127, 0.079, 0.043) # 用来保存训练以及验证过程中信息 results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S")) train_dataset = DriveDataset(args.data_path, train=True, transforms=get_transform(train=True, mean=mean, std=std)) val_dataset = DriveDataset(args.data_path, train=False, transforms=get_transform(train=False, mean=mean, std=std)) num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # 如果batch_size>1, 线程数num_workers取min(cpu核数,batch_size) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=True, collate_fn=train_dataset.collate_fn) val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=1, num_workers=num_workers, pin_memory=True, collate_fn=val_dataset.collate_fn) model = create_model(num_classes=args.num_classes) model.to(device) params_to_optimize = [p for p in model.parameters() if p.requires_grad] optimizer = torch.optim.SGD( params_to_optimize, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay ) scaler = torch.cuda.amp.GradScaler() if args.amp else None # 创建学习率更新策略,这里是每个step更新一次(不是每个epoch) lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True) if args.resume: checkpoint = torch.load(args.resume, map_location='cpu') model.load_state_dict(checkpoint['model']) optimizer.load_state_dict(checkpoint['optimizer']) lr_scheduler.load_state_dict(checkpoint['lr_scheduler']) args.start_epoch = checkpoint['epoch'] + 1 if args.amp: scaler.load_state_dict(checkpoint["scaler"]) best_dice = 0. start_time = time.time() for epoch in range(args.start_epoch, args.epochs): mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch, args.num_classes, lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler) confmat, dice = evaluate(model, val_loader, device=device, num_classes=args.num_classes) val_info = str(confmat) print(val_info) print(f"dice coefficient: {dice:.3f}") # write into txt with open(results_file, "a") as f: # 记录每个epoch对应的train_loss、lr以及验证集各指标 train_info = f"[epoch: {epoch}]\n" \ f"train_loss: {mean_loss:.4f}\n" \ f"lr: {lr:.6f}\n" \ f"dice coefficient: {dice:.3f}\n" f.write(train_info + val_info + "\n\n") if args.save_best is True: if best_dice < dice: best_dice = dice else: continue save_file = {"model": model.state_dict(), "optimizer": optimizer.state_dict(), "lr_scheduler": lr_scheduler.state_dict(), "epoch": epoch, "args": args} if args.amp: save_file["scaler"] = scaler.state_dict() if args.save_best is True: torch.save(save_file, "save_weights/best_model_mobilenet_unet.pth") else: torch.save(save_file, "./save_weights/model_amp_{}.pth".format(epoch)) total_time = time.time() - start_time total_time_str = str(datetime.timedelta(seconds=int(total_time))) print("training time {}".format(total_time_str)) def parse_args(): import argparse parser = argparse.ArgumentParser(description="pytorch unet training") parser.add_argument("--data-path", default="./", help="DRIVE root") # exclude background parser.add_argument("--num-classes", default=2, type=int) parser.add_argument("--device", default="cuda", help="training device") parser.add_argument("-b", "--batch-size", default=4, type=int) parser.add_argument("--epochs", default=100, type=int, metavar="N", help="number of total epochs to train") parser.add_argument('--lr', default=0.01, type=float, help='initial learning rate') parser.add_argument('--momentum', default=0.9, type=float, metavar='M', help='momentum') parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float, metavar='W', help='weight decay (default: 1e-4)', dest='weight_decay') parser.add_argument('--print-freq', default=1, type=int, help='print frequency') # 从上次训练停止的地方重新开始训练 parser.add_argument('--resume', default='', help='resume from checkpoint') parser.add_argument('--start-epoch', default=0, type=int, metavar='N', help='start epoch') # 保存最佳模型 parser.add_argument('--save-best', default=True, type=bool, help='only save best dice weights') # 混合精度训练参数,用于加快模型训练 parser.add_argument("--amp", default=True, type=bool, help="Use torch.cuda.amp for mixed precision training") # 解析命令行参数,并将解析结果保存在args对象中 args = parser.parse_args() # 返回解析结果 return args if __name__ == '__main__': args = parse_args() if not os.path.exists("./save_weights"): os.mkdir("./save_weights") main(args) 五.模型的完整代码和数据集下载,请参考GitHub链接:Useful-DL-Projects-for-Exercise/U-Net at main · yangyunfeng-cyber/Useful-DL-Projects-for-Exercise · GitHub
备注:此代码基于B站大佬:霹雳吧啦Wz,个人对这些代码进行了理解和注释说明得到。
