
阅读量:0
【Hadoop】Windows下安装Hadoop(手把手包成功安装)
- Hadoop简介
- 一、环境准备
- 二、下载Hadoop的相关文件
- 三、解压Hadoop安装包
- 四、替换bin文件夹
- 五、配置Hadoop环境变量
- 六、检查环境变量是否配置成功
- 七、配置Hadoop的配置文件
- 八、启动Hadoop服务
- 九、Hadoop问题处理和注意事项
Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
起源
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一 [2]。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法 。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已成为Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司。
优点
- Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
- Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
- Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
- Hadoop 还是可伸缩的,能够处理 PB 级数据。
- 此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
- Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
- 1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
- Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++ 。
- Hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
核心架构
- Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
- HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的(参见图 1),这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 1.x版本的一个缺点(单点失败)。在Hadoop 2.x版本可以存在两个NameNode,解决了单节点故障问题 。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(1.x版本默认为 64MB,2.x版本默认为128MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。 - NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上 。
实际的 I/O事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode [4]。
NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是 EditLog)将存储在 NameNode 的本地文件系统上。FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失 。
NameNode本身不可避免地具有SPOF(Single Point Of Failure)单点失效的风险,主备模式并不能解决这个问题,通过Hadoop Non-stop namenode才能实现100% uptime可用时间 。 - DataNode
DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度 。
DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。 - 文件操作
可见,HDFS 并不是一个万能的文件系统。它的主要目的是支持以流的形式访问写入的大型文件 。
如果客户机想将文件写到 HDFS 上,首先需要将该文件缓存到本地的临时存储。如果缓存的数据大于所需的 HDFS 块大小,创建文件的请求将发送给 NameNode。NameNode 将以 DataNode 标识和目标块响应客户机。
同时也通知将要保存文件块副本的 DataNode。当客户机开始将临时文件发送给第一个 DataNode 时,将立即通过管道方式将块内容转发给副本 DataNode。客户机也负责创建保存在相同 HDFS名称空间中的校验和(checksum)文件。
在最后的文件块发送之后,NameNode 将文件创建提交到它的持久化元数据存储(在 EditLog 和 FsImage 文件)
一、环境准备
1.1、查看是否安装了java环境
java -version,这里要安装java1.8版本,注意java安装的目录不要有空格
安装包链接:https://pan.baidu.com/s/1UU9rDSxro7ifUv1USsV-6g?pwd=yyds

二、下载Hadoop的相关文件
- Hadoop3.1.0版本的安装包:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz
- Windows环境安装所需的bin文件包(我们这里选择3.1.0):
- 1、可以打开地址:https://gitee.com/nkuhyx/winutils ,里面选 3.1.0。
- 2、或者直接下载:https://gitee.com/tttzzzqqq/apache-hadoop-3.1.0-winutils
三、解压Hadoop安装包
四、替换bin文件夹
替换到Hadoop安装目录下
可以发现apache-hadoop-3.1.0-winutils-master这个文件夹解压后里面只有bin这一个文件夹,我们将这个bin文件夹复制到hadoop-3.1.0文件夹中替换原有的bin文件夹
五、配置Hadoop环境变量
HADOOP_HOME
D:\hadoop-3.1.0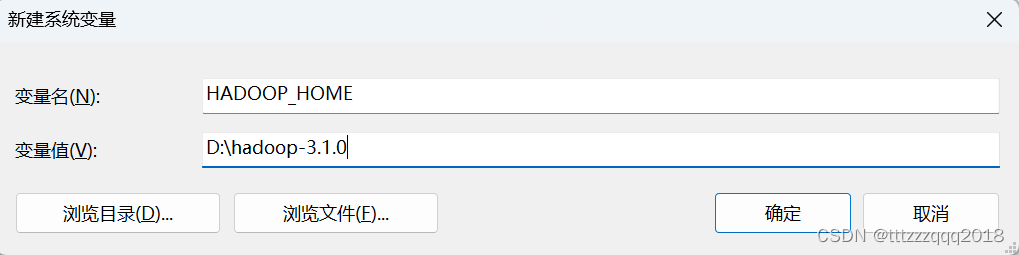
path里面加上 %HADOOP_HOME%\bin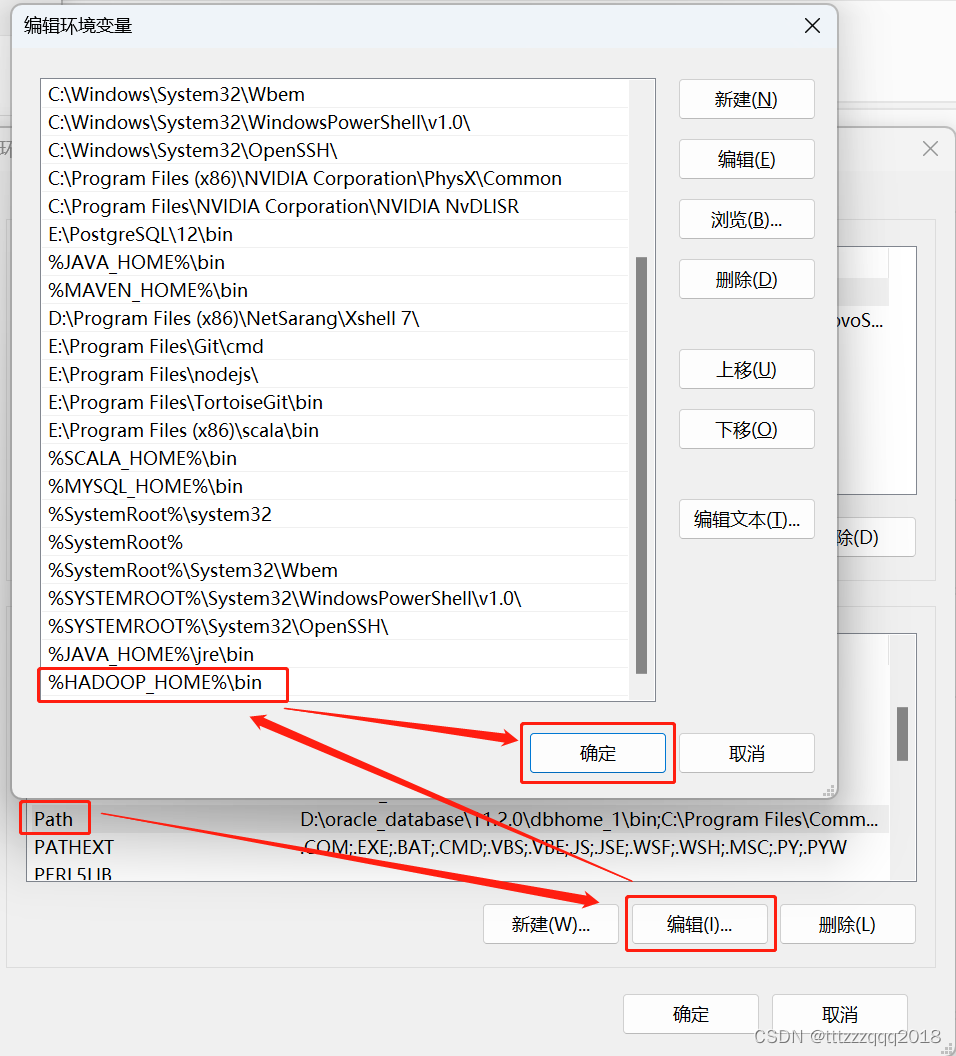
六、检查环境变量是否配置成功
hadoop version
七、配置Hadoop的配置文件
7.1、配置 core-site.xml 文件
先在 D:/hadoop-3.1.0/data/ 目录下建 tmp 文件夹
配置 core-site.xml 文件,文件路径:\hadoop-3.1.0\etc\hadoop\core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/D:/hadoop-3.1.0/data/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> 7.2、配置 mapred-site.xml 文件
文件路径:\hadoop-3.1.0\etc\hadoop\mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>hdfs://localhost:9001</value> </property> </configuration> 7.3、配置 yarn-site.xml 文件
文件路径:\hadoop-3.1.0\etc\hadoop\yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hahoop.mapred.ShuffleHandler</value> </property> </configuration> 7.4、新建namenode文件夹和datanode文件夹还有tmp文件夹
7.4.1、在D:\hadoop-3.1.0创建data文件夹(这个也可以是别的名字,但后面配置要对应修改)
7.4.2、在data文件夹中(D:\hadoop-3.1.0\data)创建datanode和namenode文件夹还有tmp文件夹
7.5、配置 hdfs-site.xml 文件
文件路径:\hadoop-3.1.0\etc\hadoop\hdfs-site.xml
<configuration> <!-- 这个参数设置为1,因为是单机版hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/D:/hadoop-3.1.0/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/hadoop-3.1.0/data/datanode</value> </property> </configuration> 7.6、配置 hadoop-env.sh 文件
文件路径:\hadoop-3.1.0\etc\hadoop\hadoop-env.sh
使用查找功能(ctrl+f)查找export JAVA_HOME,找到相应的位置:
JAVA_HOME的具体路径在环境变量中查找到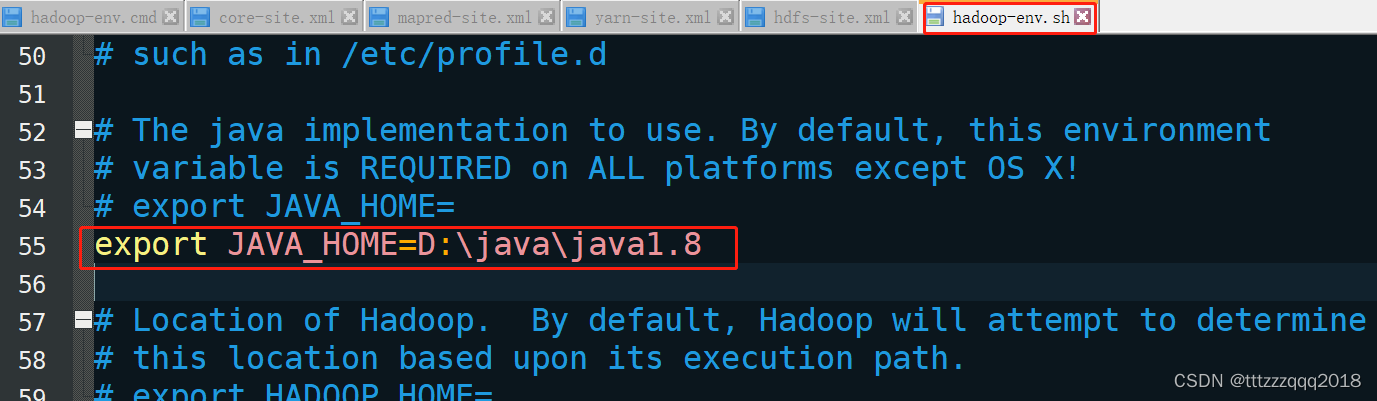
7.7、配置 hadoop-env.cmd 文件
文件路径:\hadoop-3.1.0\etc\hadoop\hadoop-env.cmd
打开后使用查找功能(ctrl+f),输入@rem The java implementation to use查找到对应行
在set JAVA_HOME那一行将自己的JAVA_HOME路径配置上去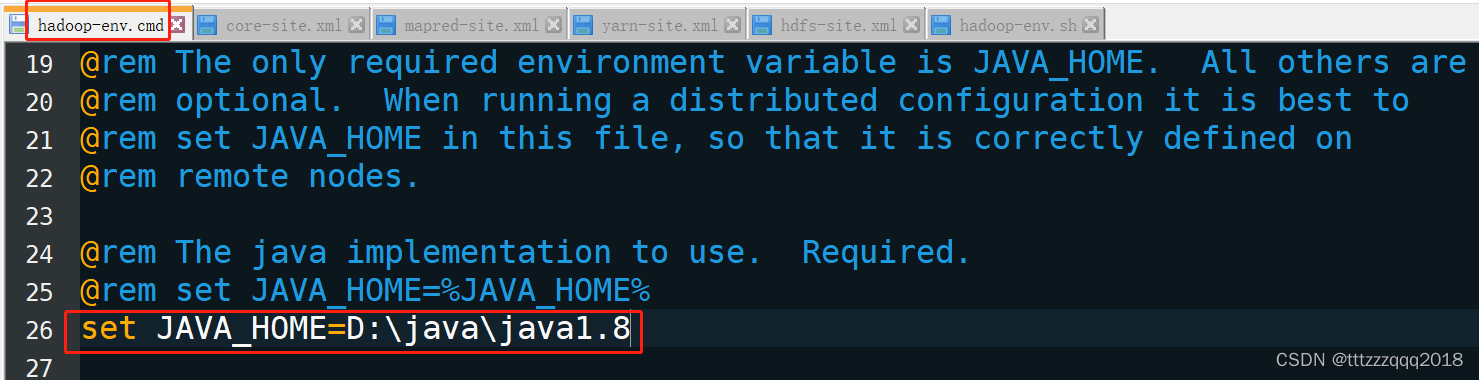
八、启动Hadoop服务
8.1、namenode格式化:hdfs namenode -format
以管理员模式打开命令窗口
在cmd中进入到D:\hadoop-3.1.0\bin路径
或者直接在对应的文件夹里面输入cmd进入
输入命令:
hdfs namenode -format 如果没报错的话,证明配置文件没出问题!
出现类似下图说明成功。如果出错,可能原因有如:环境变量配置错误如路径出现空格,或者winutils版本不对或hadoop版本过高等,或hadoop的etc下文件配置有误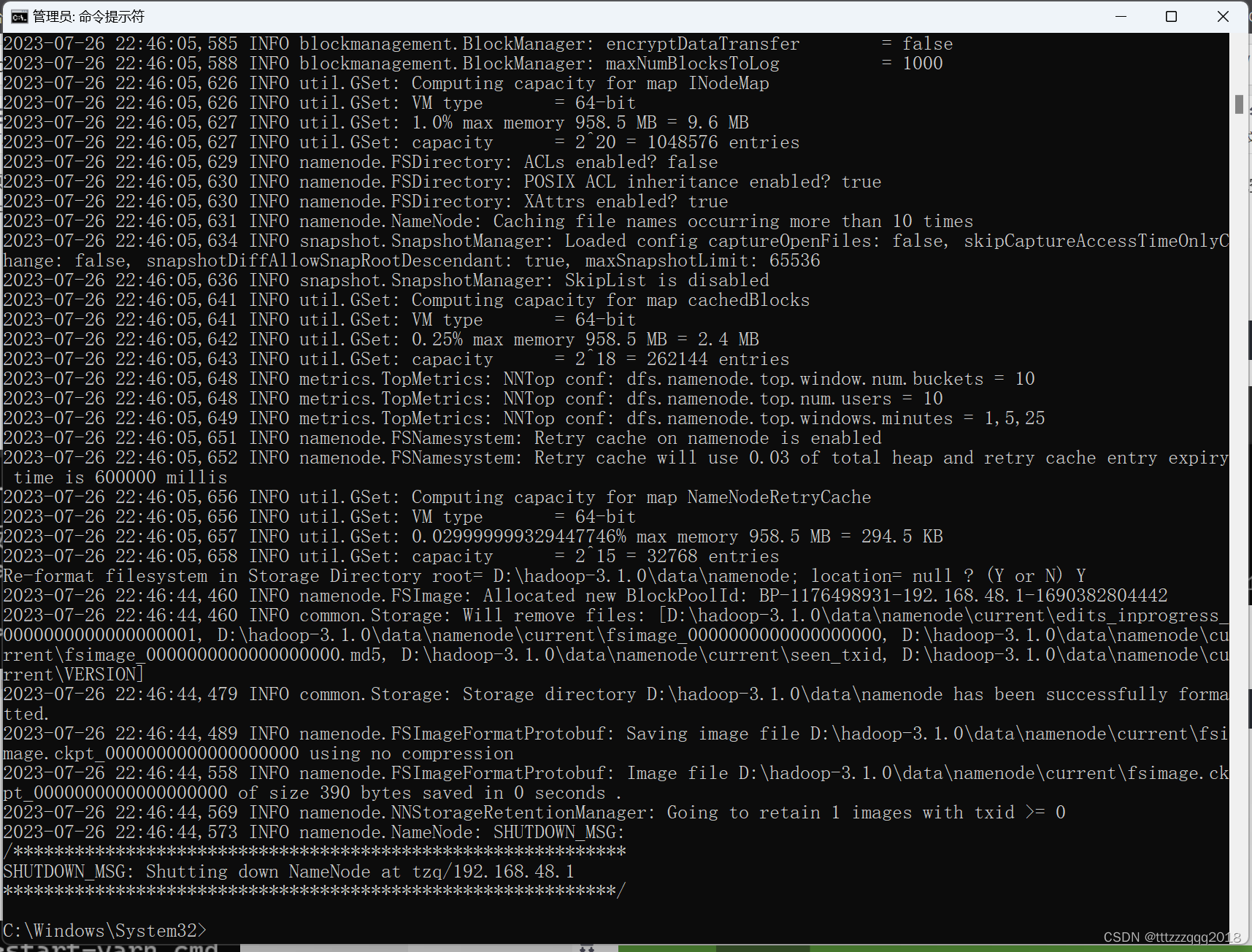
8.2、开启hdfs:start-dfs.cmd
然后再进入到D:\hadoop-3.1.0\sbin路径
输入命令:
start-dfs.cmd 
会跳出两个窗口,不要关闭!
8.3、开启yarn:start-yarn.cmd
再输入命令:
start-yarn.cmd 会跳出两个窗口,也不要关闭!
8.4、或者直接开启所有服务:start-all.cmd
也可以直接执行下面命令:(以管理员模式打开命令窗口)
start-all.cmd 然后回车,此时会弹出4个cmd窗口,分别是NameNode、ResourceManager、NodeManager、DataNode。检查4个窗口有没有报错。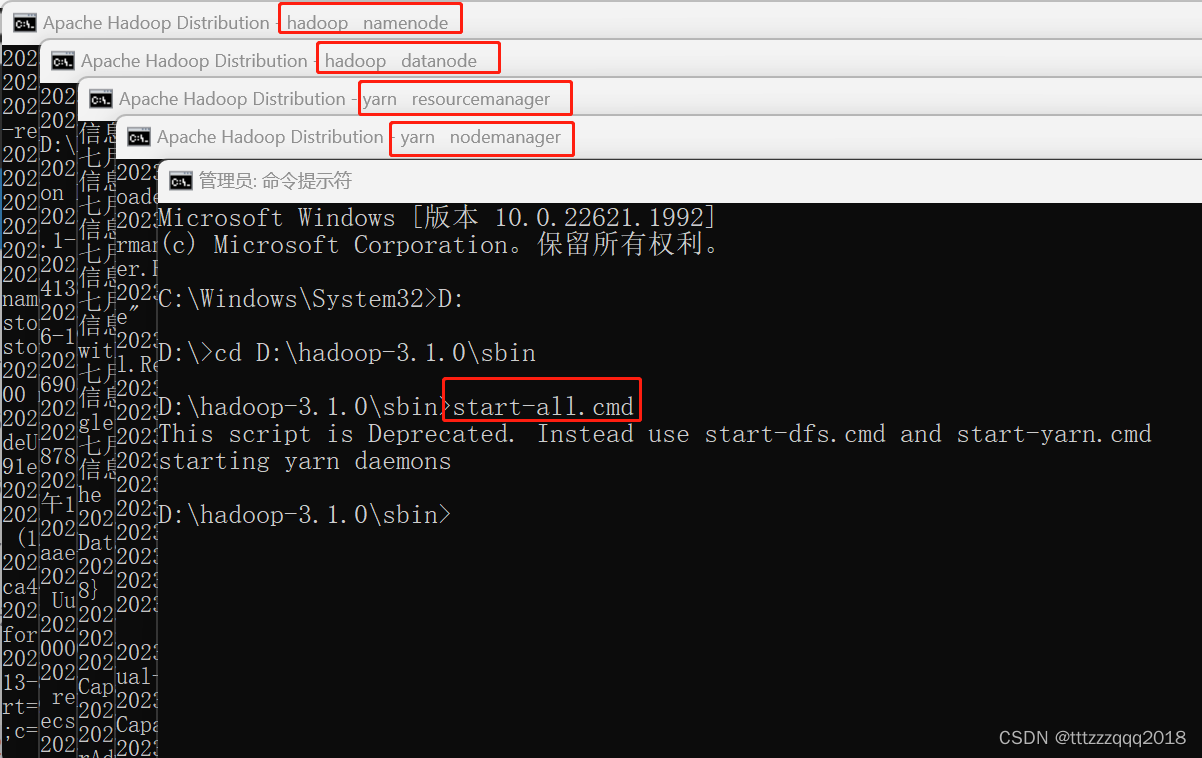
8.5、查看Hadoop运行的进程:jps
在CMD执行jps看到这4个进程,启动成功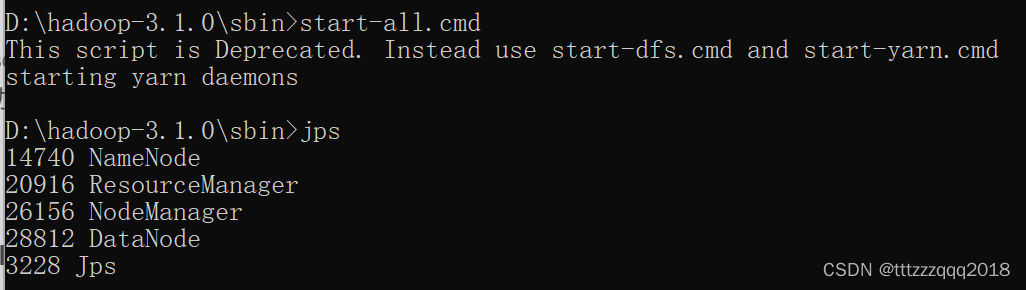
8.6、访问namenode和HDFS的页面以及resourcemanager的页面来观察集群是否正常
可以通过访问namenode和HDFS的Web UI界面(http://localhost:9870)
注意:
Hadoop版本是3.xx的是 http://localhost:9870/
Hadoop版本是2.xx的是 http://localhost:50070/
本文演示的hadoop版本是3.1.0,所以是前者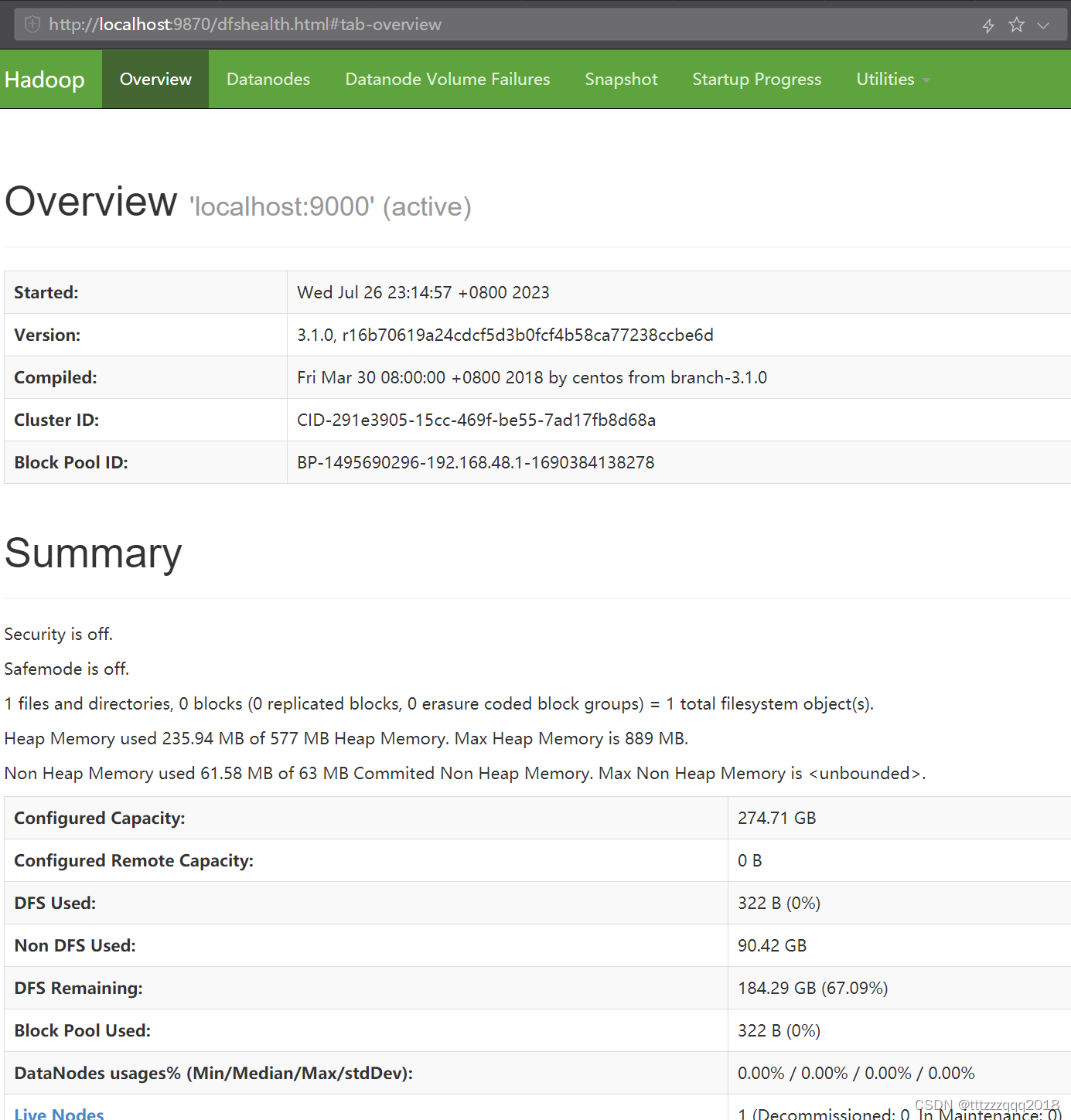
以及resourcemanager的页面(http://localhost:8088)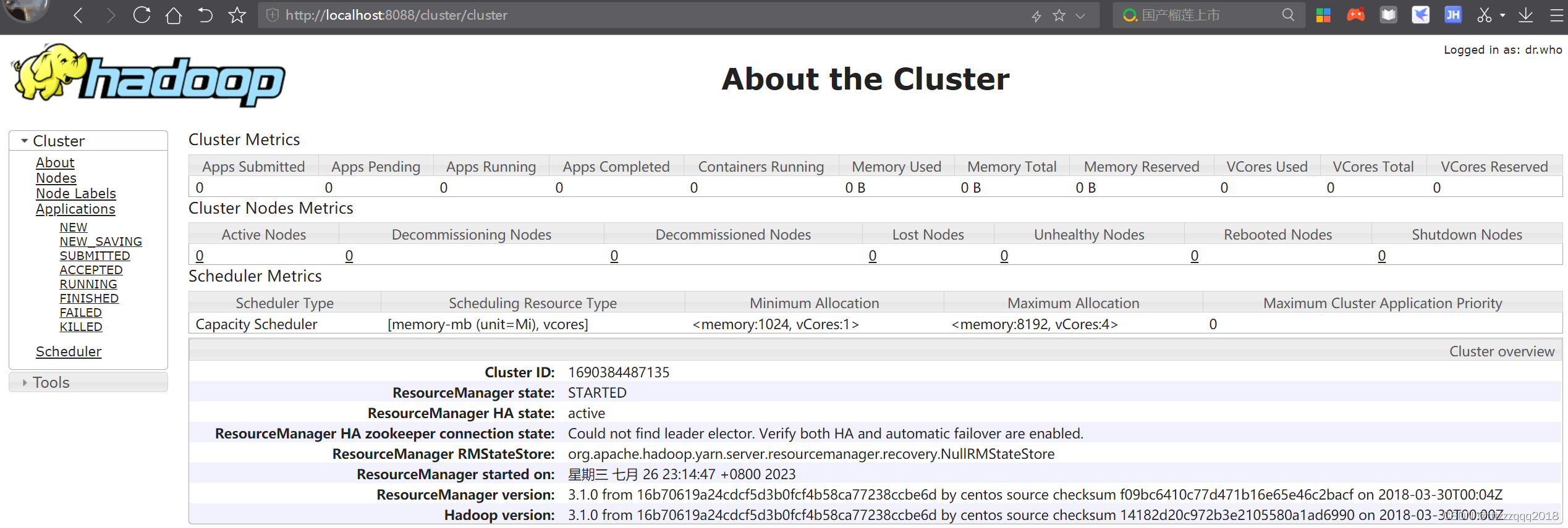
如果成功出现上面两个界面则代表Hadoop安装和配置完成。
8.7、关闭Hadoop集群:stop-all.cmd
以管理员模式打开命令窗口
进入到hadoop的目录:D:\hadoop-3.1.0\sbin
执行命令:stop-all.cmd
D:\hadoop-3.1.0\sbin>stop-all.cmd 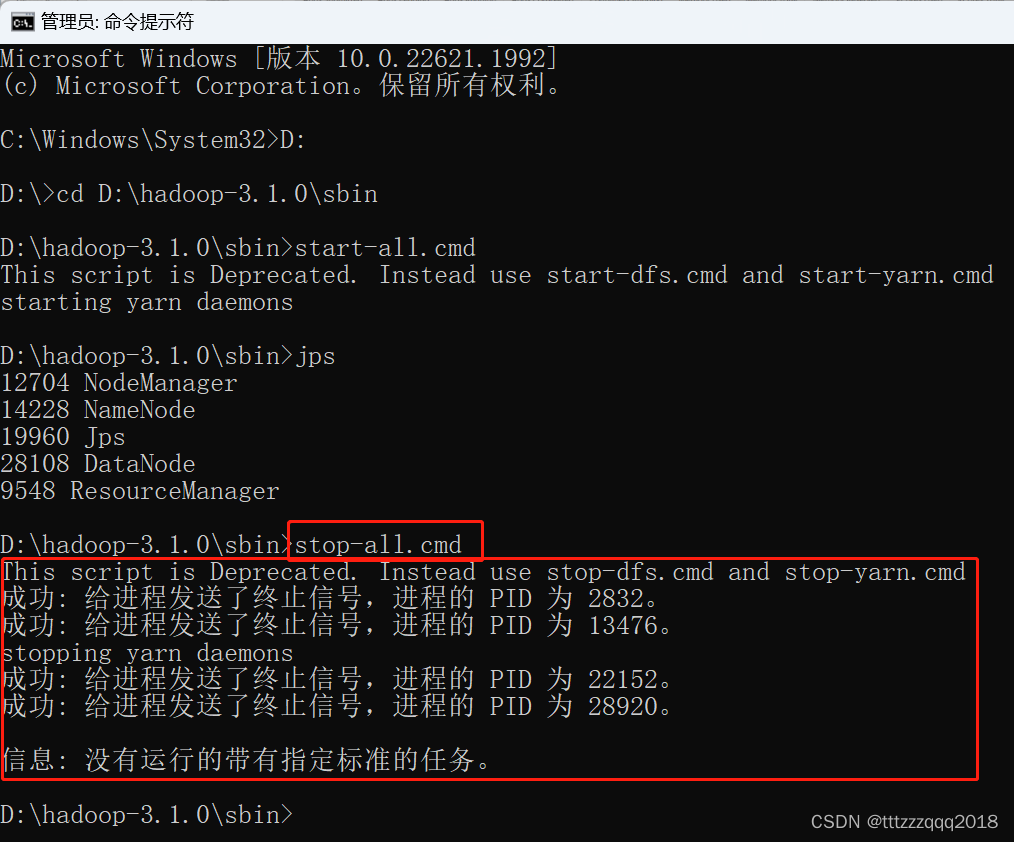
九、Hadoop问题处理和注意事项
9.1、hadoop启动报错“ org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager”处理办法
如果:hadoop启动报错“ org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager”,
主要是缺少timelineCollectorManager的jar包。
解决方案:
将hadoop3.1.0 版本将share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-3.1.0.jar放到share\hadoop\yarn\lib 下就可以。
9.2、namenode重新格式化注意事项
需要将 D:\hadoop-3.1.0\data 的
namenode、datanode、tmp这三个目录下的所有文件删除干净
9.3、Address already in use: bind
Problem binding to [0.0.0.0:8030] java.net.BindException: Address already in use: bind;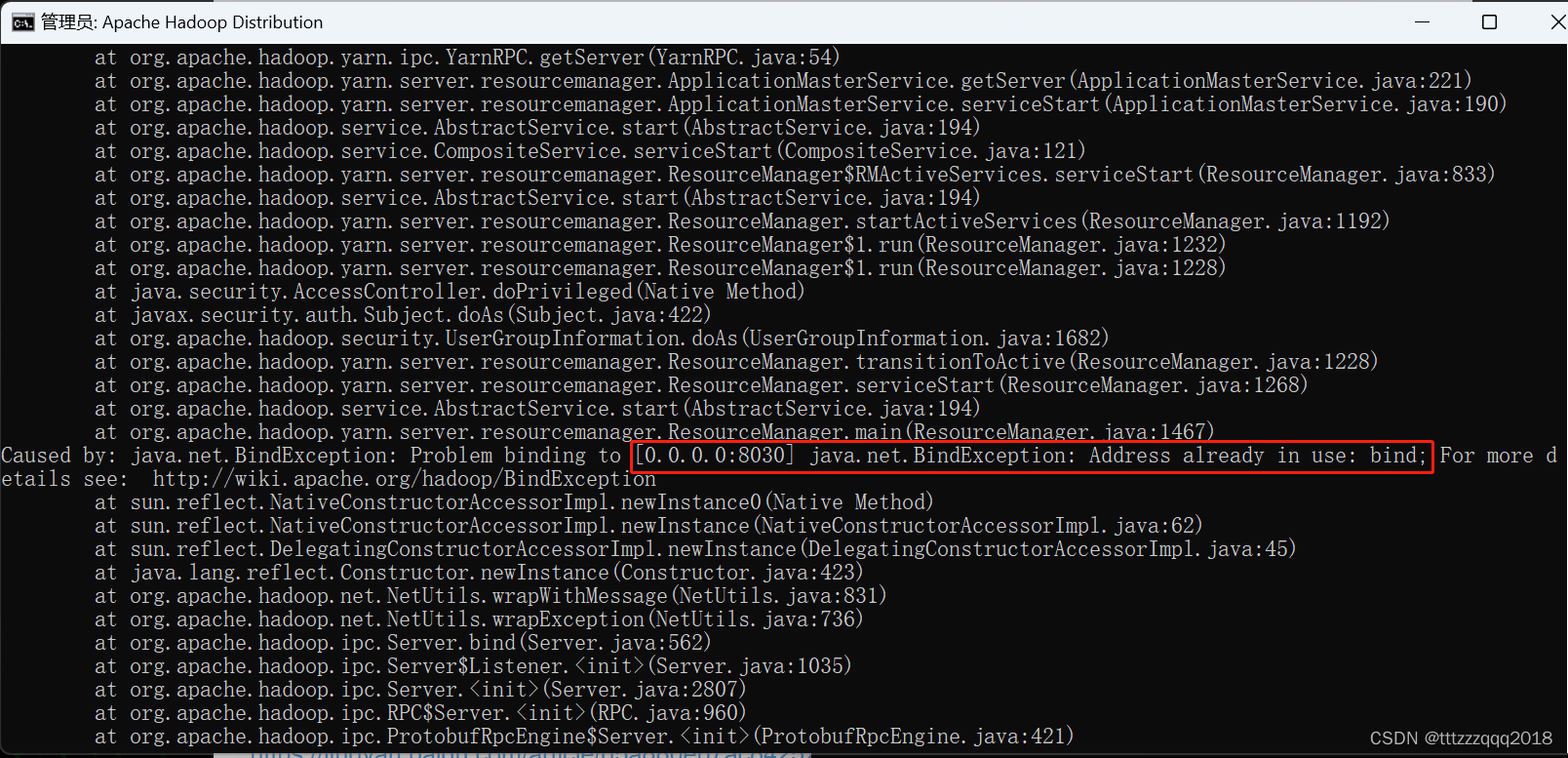
9.3.1、查看占用该端口的PID,注意端口号要加上双引号
netstat -ano|findstr "8030" 
9.3.2、使用tasklist查看 PID 对应的进程名
tasklist|findstr "13336" 
9.3.3、结束进程
如果我们想结束该进程,可以在任务管理器内找到该进程,然后直接右键结束。
也可通过 taskkill 命令的方式结束进程:
#强制
taskkill /pid 13336 -t -f 