
阅读量:0
一、前言
FastAPI 的高级用法可以为开发人员带来许多好处。它能帮助实现更复杂的路由逻辑和参数处理,使应用程序能够处理各种不同的请求场景,提高应用程序的灵活性和可扩展性。
在数据验证和转换方面,高级用法提供了更精细和准确的控制,确保输入数据的质量和安全性。它还能更高效地处理异步操作,提升应用程序的性能和响应速度,特别是在处理大量并发请求时优势明显。
此外,高级用法还有助于更好地整合数据库操作、实现数据的持久化和查询优化,以及实现更严格的认证和授权机制,保护应用程序的敏感数据和功能。总之,掌握 FastAPI 的高级用法可以帮助开发人员构建出功能更强大、性能更卓越、安全可靠的 Web 应用程序。
本篇学习FastAPI的生命周期事件,示例均在开源模型应用落地-FastAPI-助力模型交互-WebSocket篇(二)基础上进行扩展,建议有需要的老铁们,先去学习。
二、术语
2.1. Lifespan Events(生命周期事件)
通过生命周期事件,可以更好地管理应用的整个生命周期中的资源和操作,确保资源的正确初始化和释放,提高应用的性能、可靠性和可维护性。
Lifespan Events主要有以下作用:
- 资源初始化与释放:可以在应用启动时执行一些初始化操作,例如创建数据库连接池、加载共享的机器学习模型等需要在整个应用中使用且可在请求间共享的资源。在应用关闭时,执行清理和释放资源的操作,例如关闭数据库连接、释放内存或其他相关资源。
- 避免不必要的操作:如果某些资源的初始化成本较高(如加载大型模型),使用 Lifespan Events 可以避免在每次请求时都进行初始化,仅在应用启动后且接收请求之前执行一次。同时,也可以防止在一些不需要处理实际请求的情况下(如运行简单的自动化测试)进行不必要的资源加载,从而提高性能和效率。
- 分离启动和关闭逻辑:将与应用启动和关闭相关的逻辑集中在一个地方进行管理,使代码更加清晰和可维护。
三、前置条件
3.1. 创建虚拟环境&安装依赖
conda create -n fastapi_test python=3.10 conda activate fastapi_test pip install fastapi websockets uvicorn transformers==4.32.0 accelerate tiktoken einops transformers_stream_generator==0.0.4 scipy3.2. 下载Qwen-1_8B-Chat模型
huggingface:
https://huggingface.co/Qwen/Qwen-1_8B-Chat![]() https://huggingface.co/Qwen/Qwen-1_8B-Chat
https://huggingface.co/Qwen/Qwen-1_8B-Chat
魔搭:
魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。![]() https://modelscope.cn/models/qwen/Qwen-1_8B-Chat
https://modelscope.cn/models/qwen/Qwen-1_8B-Chat
四、技术实现
4.1. startup & shutdown event
# -*- coding: utf-8 -*- import traceback from transformers import AutoTokenizer, AutoModelForCausalLM from transformers import GenerationConfig import torch import uvicorn from typing import Annotated from fastapi import ( Depends, FastAPI, WebSocket, WebSocketException, WebSocketDisconnect, status, ) model_path = "E:/model/qwen-1_8b-chat" class ConnectionManager: def __init__(self): self.active_connections: list[WebSocket] = [] async def connect(self, websocket: WebSocket): await websocket.accept() self.active_connections.append(websocket) def disconnect(self, websocket: WebSocket): self.active_connections.remove(websocket) async def send_personal_message(self, message: str, websocket: WebSocket): await websocket.send_text(message) async def broadcast(self, message: str): for connection in self.active_connections: await connection.send_text(message) manager = ConnectionManager() app = FastAPI() async def authenticate( websocket: WebSocket, userid: str, secret: str, ): if userid is None or secret is None: raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION) print(f'userid: {userid},secret: {secret}') if '12345' == userid and 'xxxxxxxxxxxxxxxxxxxxxxxxxx' == secret: return 'pass' else: return 'fail' async def chat(query): position = 0 try: for response in model.chat_stream(tokenizer, query, history = None): result = response[position:] position = len(response) yield result except Exception: traceback.print_exc() @app.websocket("/ws") async def websocket_endpoint(*,websocket: WebSocket,userid: str,permission: Annotated[str, Depends(authenticate)],): await manager.connect(websocket) try: while True: text = await websocket.receive_text() if 'fail' == permission: await manager.send_personal_message( f"authentication failed", websocket ) else: if text is not None and len(text) > 0: async for msg in chat(text): await manager.send_personal_message(msg, websocket) except WebSocketDisconnect: manager.disconnect(websocket) print(f"Client #{userid} left the chat") await manager.broadcast(f"Client #{userid} left the chat") def loadTokenizer(): tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) return tokenizer def loadModel(config): model = AutoModelForCausalLM.from_pretrained(model_path, device_map="cpu", trust_remote_code=True).eval() model.generation_config = config return model @app.on_event("startup") async def startup_event(): global model,tokenizer config = GenerationConfig.from_pretrained(model_path, trust_remote_code=True, top_p=0.9, temperature=0.45,repetition_penalty=1.1, do_sample=True, max_new_tokens=8192) tokenizer = loadTokenizer() model = loadModel(config) @app.on_event("shutdown") def shutdown_event(): torch.cuda.empty_cache() if __name__ == '__main__': uvicorn.run(app, host='0.0.0.0',port=7777) 调用结果:
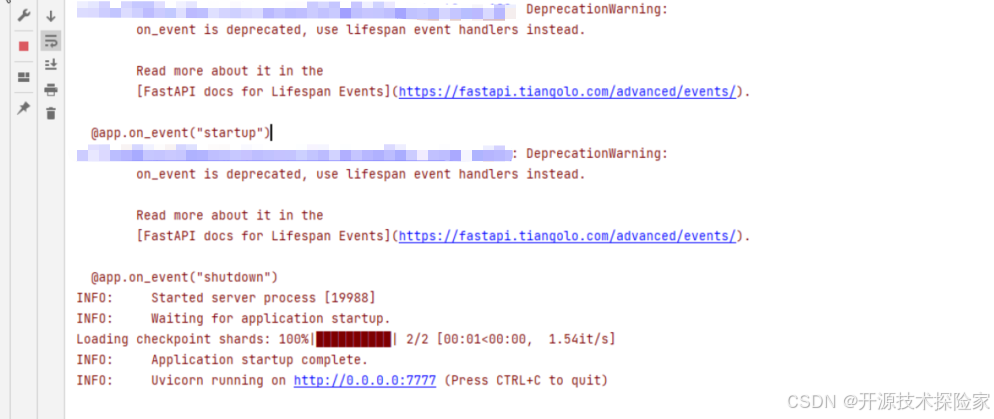
用户输入:你好
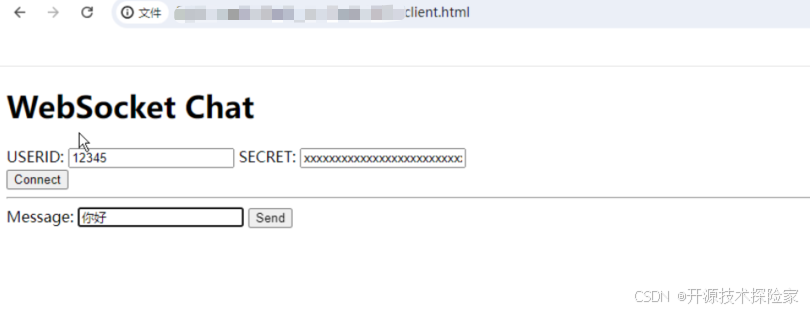
模型输出:你好!有什么我能帮助你的吗?
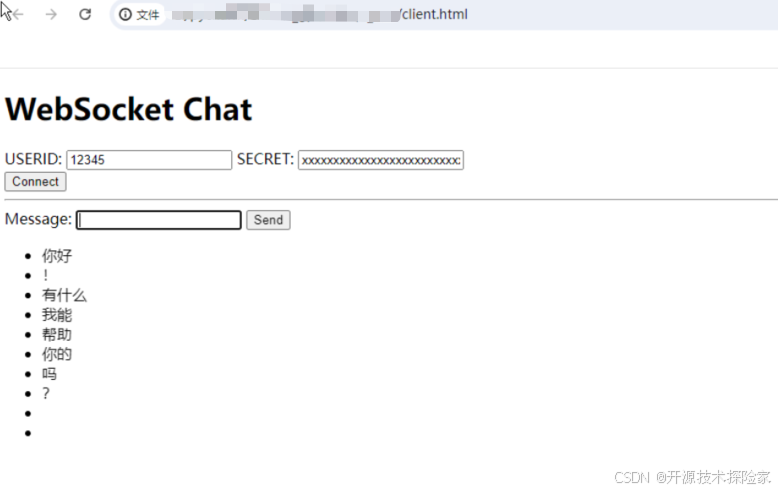
说明:
- 在startup事件函数中加载模型资源
- 在shutdown时间函数中释放资源
- startup & shutdown event已过期,后面可能会被移除,建议使用lifespan event代替
4.2. lifespan event
import traceback from contextlib import asynccontextmanager from transformers import AutoTokenizer, AutoModelForCausalLM from transformers import GenerationConfig import torch import uvicorn from typing import Annotated from fastapi import ( Depends, FastAPI, WebSocket, WebSocketException, WebSocketDisconnect, status, ) model_path = "E:/model/qwen-1_8b-chat" class ConnectionManager: def __init__(self): self.active_connections: list[WebSocket] = [] async def connect(self, websocket: WebSocket): await websocket.accept() self.active_connections.append(websocket) def disconnect(self, websocket: WebSocket): self.active_connections.remove(websocket) async def send_personal_message(self, message: str, websocket: WebSocket): await websocket.send_text(message) async def broadcast(self, message: str): for connection in self.active_connections: await connection.send_text(message) manager = ConnectionManager() def loadTokenizer(): tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) return tokenizer def loadModel(config): model = AutoModelForCausalLM.from_pretrained(model_path, device_map="cpu", trust_remote_code=True).eval() model.generation_config = config return model @asynccontextmanager async def lifespan(app: FastAPI): # 加载模型 global model, tokenizer config = GenerationConfig.from_pretrained(model_path, trust_remote_code=True, top_p=0.9, temperature=0.45, repetition_penalty=1.1, do_sample=True, max_new_tokens=8192) tokenizer = loadTokenizer() model = loadModel(config) yield # 释放资源 torch.cuda.empty_cache() app = FastAPI(lifespan=lifespan) async def authenticate( websocket: WebSocket, userid: str, secret: str, ): if userid is None or secret is None: raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION) print(f'userid: {userid},secret: {secret}') if '12345' == userid and 'xxxxxxxxxxxxxxxxxxxxxxxxxx' == secret: return 'pass' else: return 'fail' async def chat(query): position = 0 try: for response in model.chat_stream(tokenizer, query, history = None): result = response[position:] position = len(response) yield result except Exception: traceback.print_exc() @app.websocket("/ws") async def websocket_endpoint(*,websocket: WebSocket,userid: str,permission: Annotated[str, Depends(authenticate)],): await manager.connect(websocket) try: while True: text = await websocket.receive_text() if 'fail' == permission: await manager.send_personal_message( f"authentication failed", websocket ) else: if text is not None and len(text) > 0: async for msg in chat(text): await manager.send_personal_message(msg, websocket) except WebSocketDisconnect: manager.disconnect(websocket) print(f"Client #{userid} left the chat") await manager.broadcast(f"Client #{userid} left the chat") if __name__ == '__main__': uvicorn.run(app, host='0.0.0.0',port=7777) 调用结果:
没有输出警告信息

用户输入:你好,广州有什么好玩的地方推荐?
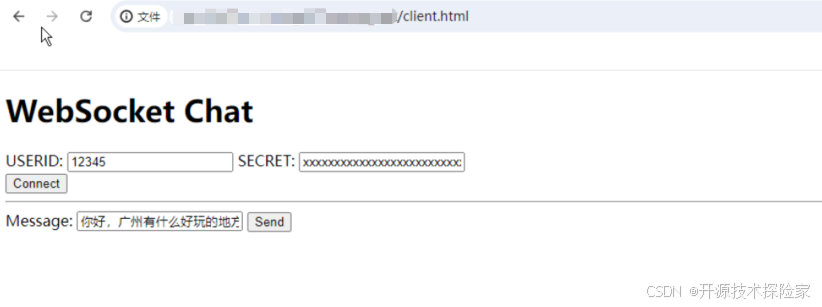
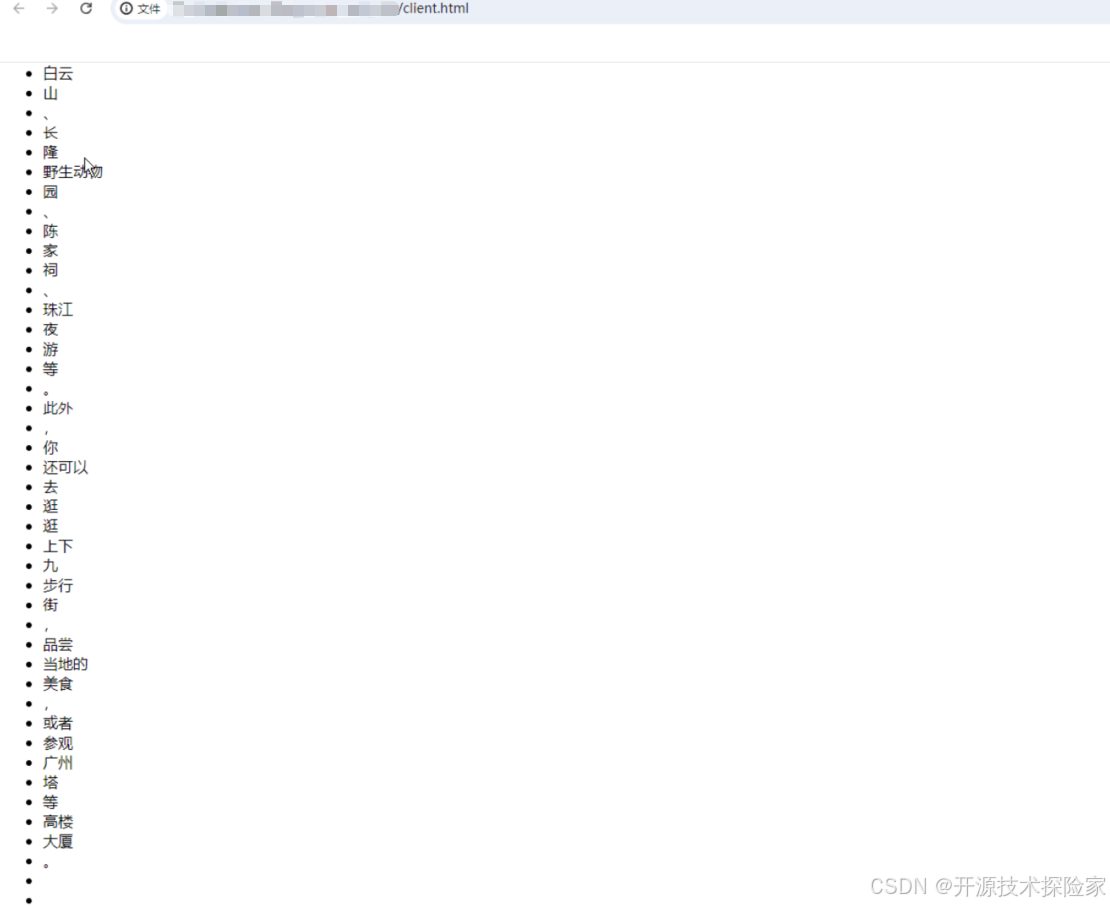
模型输出:广州有很多值得一去的景点,比如白云山、长隆野生动物园、陈家祠、珠江夜游等。此外,你还可以去逛逛上下九步行街,品尝当地的美食,或者参观广州塔等高楼大厦。
五、附带说明
5.1. 测试界面
<!DOCTYPE html> <html> <head> <title>Chat</title> </head> <body> <h1>WebSocket Chat</h1> <form action="" onsubmit="sendMessage(event)"> <label>USERID: <input type="text" id="userid" autocomplete="off" value="12345"/></label> <label>SECRET: <input type="text" id="secret" autocomplete="off" value="xxxxxxxxxxxxxxxxxxxxxxxxxx"/></label> <br/> <button onclick="connect(event)">Connect</button> <hr> <label>Message: <input type="text" id="messageText" autocomplete="off"/></label> <button>Send</button> </form> <ul id='messages'> </ul> <script> var ws = null; function connect(event) { var userid = document.getElementById("userid") var secret = document.getElementById("secret") ws = new WebSocket("ws://localhost:7777/ws?userid="+userid.value+"&secret=" + secret.value); ws.onmessage = function(event) { var messages = document.getElementById('messages') var message = document.createElement('li') var content = document.createTextNode(event.data) message.appendChild(content) messages.appendChild(message) }; event.preventDefault() } function sendMessage(event) { var input = document.getElementById("messageText") ws.send(input.value) input.value = '' event.preventDefault() } </script> </body> </html>