
阅读量:0
概述
gn是generate ninja的缩写,它是一个元编译系统(meta-build system),是ninja的前端,gn和ninja结合起来,完成OpenHarmony操作系统的编译任务。
gn简介
- 目前采用gn的大型软件系统有:Chromium,Fuchsia和OpenHarmony。
- gn语法自设计之初就自带局限性,比如不能求list的长度,不支持通配符等。这些局限性源于其 有所为有所不为 的设计哲学。 所以在使用gn的过程中,如果发现某件事情用gn实现起来很复杂,请先停下来思考这件事情是否真的需要做。
- 关于gn的更多详情见gn官方文档。
本文的目标读者和覆盖范围
目标读者为OpenHarmony的开发者。本文主要讨论gn的编码风格和使用gn过程中容易出现的问题,不讨论gn的语法,如需了解gn基础知识,见gn reference文档。
总体原则
在保证功能可用的前提下,脚本需要满足易于阅读,便于维护,良好的扩展性和性能等要求。
代码风格
命名
总体上遵循Linux kernel的命名风格,即小写字母+下划线的命名风格。
局部变量
我们这里对局部变量的定义为:在某作用域内,且不向下传递的变量。
为了更好的区别于全局变量,局部变量统一采用下划线开头。
# 例1 action("some_action") { ... # _output是个局部变量,所以使用下划线开头 _output = "${target_out_dir}/${target_name}.out" outputs = [ _output ] args = [ ... "--output", rebase_path(_output, root_build_dir), ... ] ... }全局变量
全局变量使用小写字母开头。
如果变量值可以被gn args修改,则需要使用declare_args来声明,否则不要使用declare_args。
# 例2 declare_args() { # 可以通过gn args来修改some_feature的值 some_feature = false }目标命名
目标命名采用小写字母+下划线的命名方式。
模板中的子目标命名方式采用"${target_name}+双下划线+后缀"的命名方式。这样做有两点好处:
加入"${target_name}"可以防止子目标重名。
加入双下划线可以很方便地区分出子目标属于哪一个模块,方便在出现问题时快速定位。
# 例3 template("ohos_shared_library") { # "{target_name}"(主目标名)+"__"(双下划线)+"notice"(后缀) _notice_target = "${target_name}__notice" collect_notice(_notice_target) { ... } shared_library(target_name) { ... } }
自定义模板的命名
推荐采用动宾短语的形式来命名。
# 例4 # Good template("compile_resources") { ... }格式化
gn脚本在提交之前需要执行格式化。格式化可以保证代码对齐,换行等风格的统一。使用gn自带的format工具即可。命令如下:
$ gn format path-to-BUILD.gngn format会按照字母序对import文件做排序,如果想保证import的顺序,可以添加空注释行。
假设原来的import顺序为:
# 例5 import("//b.gni") import("//a.gni")经过format之后变为:
import("//a.gni") import("//b.gni")如果想保证原有的import顺序,可以添加空注释行。
import("//b.gni") # Comment to keep import order import("//a.gni")编码实践
实践原则
编译脚本实质上完成了两件工作:
描述模块之间依赖关系(deps)
实践过程中,最常出现的问题是依赖关系缺失。
描述模块编译的规则(rule)
实践过程中,容易出现的问题是输入和输出不明确。
依赖缺失会导致两个问题:
概率性编译错误
# 例6 # 依赖关系缺失,导致概率性编译出错 shared_library("a") { ... } shared_library("b") { ... ldflags = [ "-la" ] deps = [] ... } group("images") { deps = [ ":b" ] }上面的例子中,libb.so在链接的时候会链接liba.so,实质上构成b依赖a,但是b的依赖列表(deps)却没有声明对a的依赖。由于编译是并发执行的,如果libb.so在链接的时候liba.so还没有编译出来,就会出现编译错误。
由于liba.so也有可能在libb.so之前编译出来,所以依赖缺失导致的编译错误是概率性的。
依赖关系缺失导致模块没有参与编译
还是上面的例子,如果我们指定ninja编译目标为images,由于images仅仅依赖b,所以a不会参与编译。由于b实质上依赖a, 这时b在链接时会出现必现错误。
有一种不太常见的问题是过多的依赖。过多的依赖会降低并发,导致编译变慢。见下面的例子:
_compile_js_target不需要依赖 _compile_resource_target,增加这层依赖,会导致 _compile_js_target在 _compile_resource_target编译完成之后才能开始编译。
# 例7 # 过多的依赖导致编译变慢 template("too_much_deps") { ... _gen_resource_target = "${target_name}__res" action(_gen_resource_target) { ... } _compile_resource_target = "${target_name}__compile_res" action(_compile_resource_target) { deps = [":$_gen_resource_target"] ... } _compile_js_target = "${target_name}__js" action(_compile_js_target) { # 这个deps不需要 deps = [":$_compile_resource_target"] } }输入不明确会导致:
- 代码修改了,但增量编译时却没有参与编译。
- 当使用缓存时,代码发生变化,但是缓存仍然命中。
下面的例子中,foo.py引用了bar.py中的函数。bar.py实质上是foo.py的输入,需要将bar.py添加到implict_input_action的input或者depfile中去。否则,修改bar.py,模块implict_input_action将不会重新编译。
# 例8 action("implict_input_action") { script = "//path-to-foo.py" ... }#!/usr/bin/env # Contents of foo.py import bar ... bar.some_function() ...输出不明确会导致:
- 隐式的输出
- 当使用缓存时,隐式输出无法从缓存中获得
下面的例子中,foo.py会生成两个文件,a.out和b.out,但是implict_output_action的输出只声明了a.out。这种情况下,b.out实质上就是一个隐式输出。缓存中只会存储a.out,不会存储b.out,当缓存命中时,b.out就编译不出来了。
# 例9 action("implict_output_action") { outputs = ["${target_out_dir}/a.out"] script = "//path-to-foo.py" ... }#!/usr/bin/env # Contents of foo.py ... write_file("b.out") write_file("a.out") ...模板
不要使用gn的原生模板,使用编译子系统提供的模板
所谓gn原生模板,是指source_set,shared_library, static_library, action, executable,group这六个模板。
不推荐使用原生模板的原因有二:
原生模板是最小功能模板,无法提供external_deps的解析,notice收集,安装信息生成等的额外功能,这些额外功能最好是随着模块编译时同时生成,所以必须对原生模板做额外的扩展才能满足实际的需求。
当输入文件依赖的文件发生变化时,gn原生的action模板不能自动感知不到这种编译,无法重新编译。见例8
原生模板和编译子系统提供的模板之间的对应关系:
| 编译子系统提供的模板 | 原生模板 |
|---|---|
| ohos_shared_library | shared_library |
| ohos_source_set | source_set |
| ohos_executable | executable |
| ohos_static_library | static_library |
| action_with_pydeps | action |
| ohos_group | group |
使用python脚本
action中的script推荐使用python脚本,不推荐使用shell脚本。相比于shell脚本,python脚本:
- python语法友好,不会因为少写一个空格就导致奇怪的错误。
- python脚本有很强的可读性。
- 可维护性强,可调试。
- OpenHarmony对python任务做了缓存,可以加快编译速度。
rebase_path
仅在向action的参数列表中(args)调用rebase_path。
# 例10 template("foo") { action(target_name) { ... args = [ # 仅在args中调用rebase_path "--bar=" + rebase_path(invoker.bar, root_build_dir), ... ] ... } } foo("good") { bar = something ... }同一变量做两次rebase_path会出现意想不到的结果。
# 例11 template("foo") { action(target_name) { ... args = [ # bar被执行了两次rebase_path, 传递的bar的值已经不对了 "--bar=" + rebase_path(invoker.bar, root_build_dir), ... ] ... } } foo("bad") { # 不要在这里调用rebase_path bar = rebase_path(some_value,root_build_dir) ... }
模块间数据分享
模块间数据分享是很常见的事情,比如A模块想要知道B模块的输出和deps。
同一BUILD.gn之间数据分享
同一BUILD.gn之间数据可以通过定义全局变量的方式来共享。
下面的例子中,模块a的输出是模块b的输入,可以通过定义全局变量的方式来共享给b
# 例12 _output_a = get_label_info(":a", "out_dir") + "/a.out" action("a") { outputs = _output_a ... } action("b") { inputs = [_output_a] ... }不同BUILD.gn之间数据分享
不同BUILD.gn之间传递数据,最好的办法是将需要共享的数据保存成文件,然后不同模块之间通过文件来传递和共享数据。这种场景比较复杂,读者可以参照OpenHarmony的hap编译过程的write_meta_data。
forward_variable_from
自定义模板需要首先将testonly传递(forward)进来。因为该模板的target有可能被testonly的目标依赖。
# 例13 # 自定义模板首先要传递testonly template("foo") { forward_variable_from(invoker, ["testonly"]) ... }不推荐使用*来forward变量,需要的变量应该显式地,一个一个地被forward进来。
# 例14 # Bad,使用*forward变量 template("foo") { forward_variable_from(invoker, "*") ... } # Good, 显式地,一个一个地forward变量 template("bar") { # forward_variable_from(invoker, [ "testonly", "deps", ... ]) ... }
target_name
target_name会随着作用域变化而变化,使用时需要注意。
# 例15 # target_name会随着作用域变化而变化 template("foo") { # 此时打印出来的target_name为"${target_name}" print(target_name) _code_gen_target = "${target_name}__gen" code_gen(_code_gen_target) { # 此时打印出来的target_name为"${target_name}__gen" print(target_name) ... } _compile_gen_target = "${target_name}__compile" compile(_compile_gen_target) { # 此时打印出来的target_name为"${target_name}__compile" print(target_name) ... } ... }public_configs
如果模块需要向外export头文件,请使用public_configs。
# 例16 # b依赖a,会同时继承a的headers config("headers") { include_dirs = ["//path-to-headers"] ... } shared_library("a") { public_configs = [":headers"] ... } executable("b") { deps = [":a"] ... }template
自定义模板中必须有一个子目标的名字是target_name。该子目标会作为template的主目标。其他子目标都应该被主目标依赖,否则子目标不会被编译。
# 例17 # 自定义模板中必须有一个子目标的名字是target_name template("foo") { _code_gen_target = "${target_name}__gen" code_gen(_code_gen_target) { ... } _compile_gen_target = "${target_name}__compile" compile(_compile_gen_target) { # 此时打印出来的target_name为"${target_name}__compile" print(target_name) ... } ... group(target_name) { deps = [ # 由于_compile_gen_target依赖了_code_gen_target,所以主目标只需要依赖_compile_gen_target即可。 ":$_compile_gen_target" ] } }set_source_assignment_filter
set_source_assignment_filter除了可以过滤sources,还可以用来过滤其他变量。过滤完成后记得将过滤器和sources置空。
# 例18 # 使用set_source_assignment_filter过滤依赖, 挑选label符合*:*_res的添加到依赖列表中 _deps = [] foreach(_possible_dep, invoker.deps) { set_source_assignment_filter(["*:*_res"]) _label = get_label_info(_possible_dep, "label_no_toolchain") sources = [] sources = [ _label ] if (sources = []) { _deps += _sources } } sources = [] set_source_assignment_filter([])最新版本上set_source_assignment_filter被filter_include和filter_exclude取代。
部件内依赖采用deps,跨部件依赖采用external_deps
部件在OpenHarmony上指能提供某个能力的一组模块。
在模块定义的时候可以声明part_name,用来表明当前模块属于哪个部件。
每个部件会声明其inner_kits,供其他部件调用。部件inner_kits的声明见源码中的bundle.json。
部件间依赖只能依赖inner_kits,不能依赖非inner_kits的模块。
如果a模块和b模块的part_name相同,那么a、b模块属于同一个部件,a,b模块之间的依赖关系可以用deps来声明。
如果a、b模块的part_name不同,那么a、b模块不属于同一个部件,a、b模块之间的依赖关系需要通过external_deps来声明,依赖方式为"部件名:模块名"的方式。见例19。
# 例19 shared_library("a") { ... external_deps = ["part_name_of_b:b"] ... }
最后
有很多小伙伴不知道学习哪些鸿蒙开发技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?而且学习时频繁踩坑,最终浪费大量时间。所以有一份实用的鸿蒙(HarmonyOS NEXT)资料用来跟着学习是非常有必要的。
这份鸿蒙(HarmonyOS NEXT)资料包含了鸿蒙开发必掌握的核心知识要点,内容包含了(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、Harmony南向开发、鸿蒙项目实战等等)鸿蒙(HarmonyOS NEXT)技术知识点。
希望这一份鸿蒙学习资料能够给大家带来帮助,有需要的小伙伴自行领取,限时开源,先到先得~无套路领取!!
如果你是一名有经验的资深Android移动开发、Java开发、前端开发、对鸿蒙感兴趣以及转行人员,可以直接领取这份资料
获取这份完整版高清学习路线,请点击→纯血版全套鸿蒙HarmonyOS学习资料
鸿蒙(HarmonyOS NEXT)最新学习路线

HarmonOS基础技能

- HarmonOS就业必备技能

- HarmonOS多媒体技术

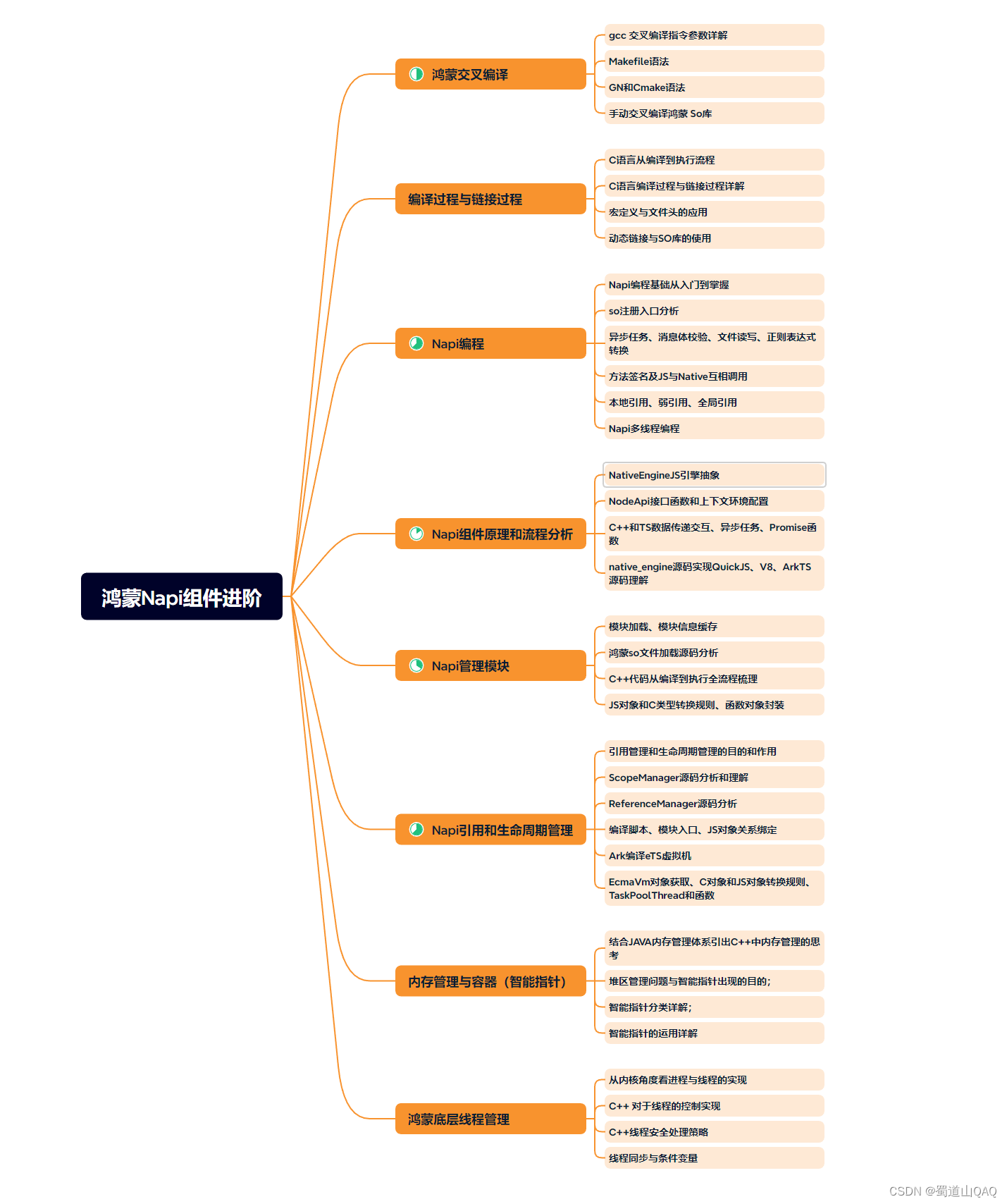
- 鸿蒙NaPi组件进阶
- HarmonOS高级技能

- 初识HarmonOS内核
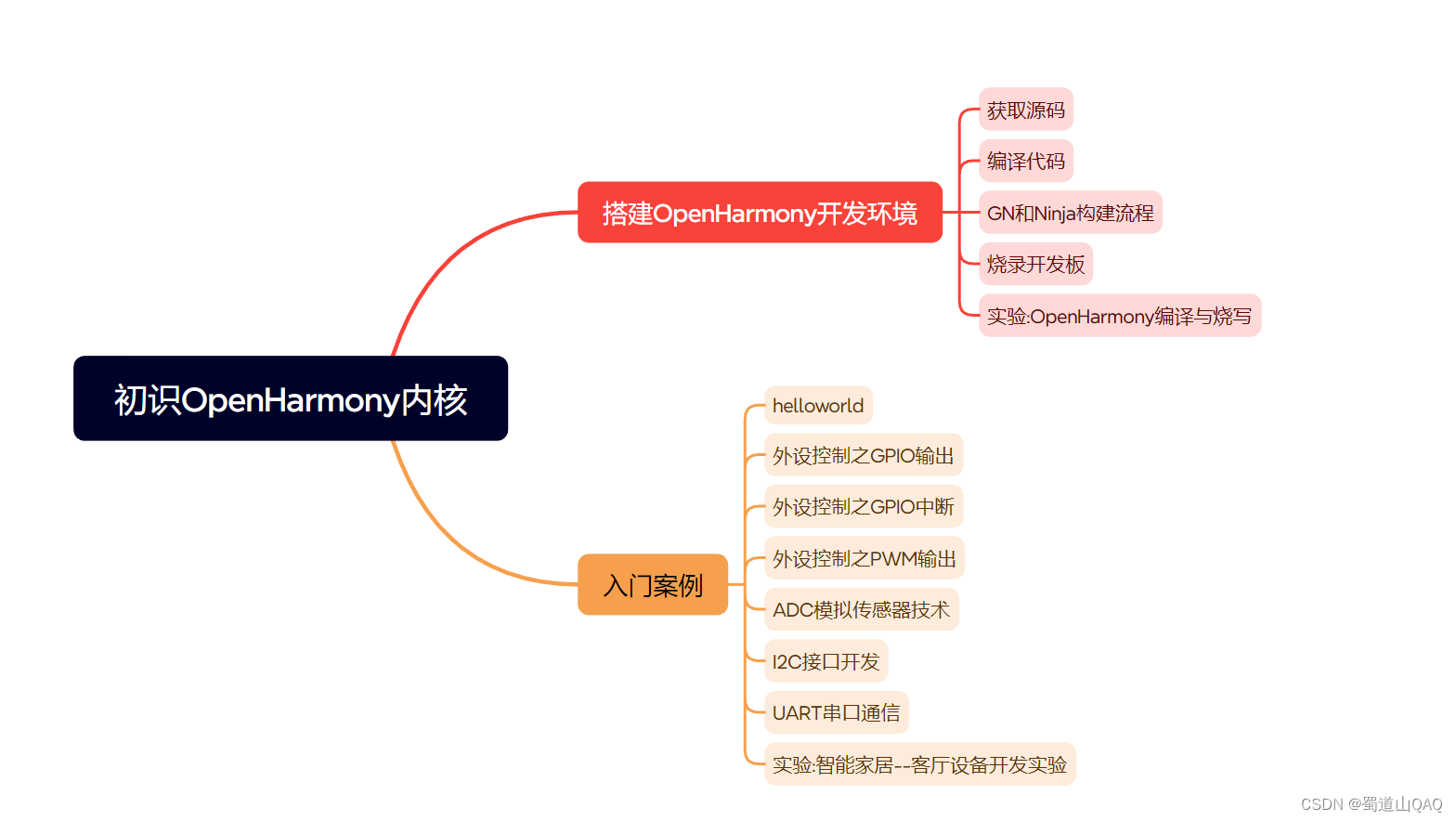
- 实战就业级设备开发

有了路线图,怎么能没有学习资料呢,小编也准备了一份联合鸿蒙官方发布笔记整理收纳的一套系统性的鸿蒙(OpenHarmony )学习手册(共计1236页)与鸿蒙(OpenHarmony )开发入门教学视频,内容包含:ArkTS、ArkUI、Web开发、应用模型、资源分类…等知识点。
获取以上完整版高清学习路线,请点击→纯血版全套鸿蒙HarmonyOS学习资料
《鸿蒙 (OpenHarmony)开发入门教学视频》

《鸿蒙生态应用开发V2.0白皮书》

《鸿蒙 (OpenHarmony)开发基础到实战手册》
OpenHarmony北向、南向开发环境搭建
《鸿蒙开发基础》
- ArkTS语言
- 安装DevEco Studio
- 运用你的第一个ArkTS应用
- ArkUI声明式UI开发
- .……
《鸿蒙开发进阶》
- Stage模型入门
- 网络管理
- 数据管理
- 电话服务
- 分布式应用开发
- 通知与窗口管理
- 多媒体技术
- 安全技能
- 任务管理
- WebGL
- 国际化开发
- 应用测试
- DFX面向未来设计
- 鸿蒙系统移植和裁剪定制
- ……

《鸿蒙进阶实战》
- ArkTS实践
- UIAbility应用
- 网络案例
- ……

获取以上完整鸿蒙HarmonyOS学习资料,请点击→纯血版全套鸿蒙HarmonyOS学习资料
总结
总的来说,华为鸿蒙不再兼容安卓,对中年程序员来说是一个挑战,也是一个机会。只有积极应对变化,不断学习和提升自己,他们才能在这个变革的时代中立于不败之地。

