
阅读量:0
最近需要做基于卫星和无人机的农业大棚的旋转目标检测,基于YOLO V8 OBB的原因是因为尝试的第二个模型就是YOLO V8,后面会基于YOLO V9模型做农业大棚的旋转目标检测。YOLO V9目前还不能进行旋转目标的检测,需要修改代码
PS:欢迎大家分享农业大棚数据集,数据制作太花时间了......下面是我制作的农业大棚图像

一、下载代码配置环境
GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
下载解压缩源码之后,激活环境进入根目录配置环境(我已经换源):
pip install pyproject.dependencies我的换源方法是到用户文件夹(C:\Users\Administrator)下创建一个pip文件夹,然后在pip文件夹里创建一个txt文件,在txt文件里面写入下面的内容,然后把txt文件后缀改成ini

[global] index-url = http://pypi.mirrors.ustc.edu.cn/simple [install] use-mirrors =true mirrors =http://pypi.mirrors.ustc.edu.cn/simple/ trusted-host =pypi.mirrors.ustc.edu.cn

二、数据集准备
流程:数据集标注——>XML——>DOTA_XML——>DOTA_TXT——>划分数据集(train和val)——>YOLO格式TXT
(1)LabelImg2标注数据集生成XML标注文件
在LabelImg2上标注好数据,LabelImg2标注是五点式,即旋转框的中心x,y坐标、旋转框的长度和宽度、旋转角度

(2)XML标注文件转DOTA格式标签文件(TXT)
下面将五点式XML文件转换为八点式XML文件,再将八点式XML文件转换为YOLO可训练的TXT格式
提示:DOTA数据集的TXT格式
x1,y1,x2,y2,x3,<y3,x4,y4,class_index,difficult # 示例 307 308 330 299 422 541 398 550 dog 0OBB检测方法里面旋转框的表示方法有好几种,YOLO V8 OBB使用的是(通过坐标在 0 和 1 之间归一化的四个角点来指定边界框):
class_index, x1, y1, x2, y2, x3, y3, x4, y4(需要做归一化) # 示例 0 0.332813 0.164062 0.403125 0.15 0.45 0.373437 0.379688 0.389062注意事项:
【1】运行代码之前将cls_list = ['dog'] # 修改为自己的标签,不修改也不会报错,只是转换后的TXT中将没有任何数据
【2】查看ultralytics/data/converter.py脚本中的代码,图片数据格式是png还是jpg。如果你的图像格式与代码中要求的图像格式不符就无法生成TXT标签(PS:我是将jpg转png再运行代码的)
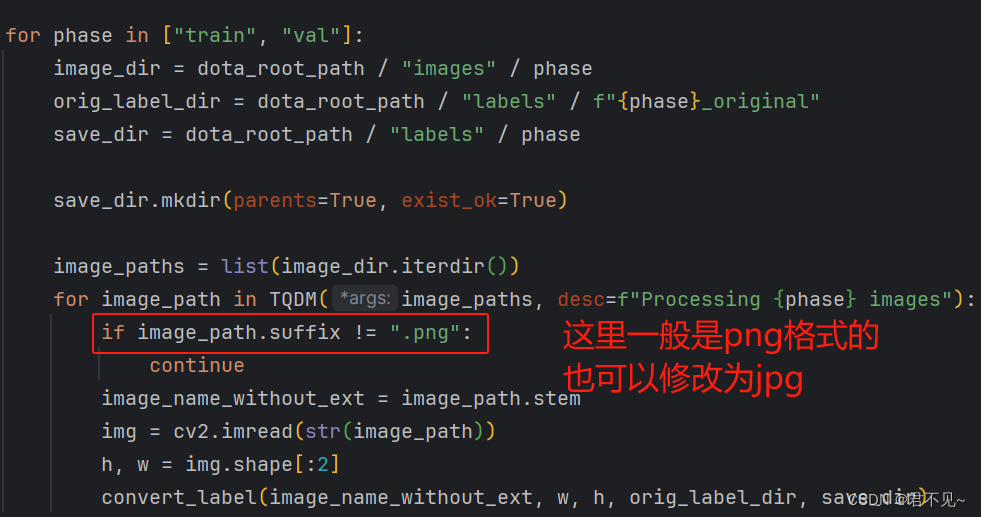
(2024.05.22更新)当然也可以直接修改ultralytics/data/converter.py脚本中的代码,将
if image_path.suffix != ".png":修改为
if image_path.suffix != [".png", ".jpg", ".jpeg"]:修改之后就不用担心图像格式了,png、jpg、jpeg中的任何一种都可以
# 文件名称 :roxml_to_dota.py # 功能描述 :把rolabelimg标注的xml文件转换成dota能识别的xml文件, # 再转换成dota格式的txt文件 # 把旋转框 cx,cy,w,h,angle,或者矩形框cx,cy,w,h,转换成四点坐标x1,y1,x2,y2,x3,y3,x4,y4 import os import xml.etree.ElementTree as ET import math cls_list = ['dog'] # 修改为自己的标签 def edit_xml(xml_file, dotaxml_file): """ 修改xml文件 :param xml_file:xml文件的路径 :return: """ # dxml_file = open(xml_file,encoding='gbk') # tree = ET.parse(dxml_file).getroot() tree = ET.parse(xml_file) objs = tree.findall('object') for ix, obj in enumerate(objs): x0 = ET.Element("x0") # 创建节点 y0 = ET.Element("y0") x1 = ET.Element("x1") y1 = ET.Element("y1") x2 = ET.Element("x2") y2 = ET.Element("y2") x3 = ET.Element("x3") y3 = ET.Element("y3") # obj_type = obj.find('bndbox') # type = obj_type.text # print(xml_file) if (obj.find('robndbox') == None): obj_bnd = obj.find('bndbox') obj_xmin = obj_bnd.find('xmin') obj_ymin = obj_bnd.find('ymin') obj_xmax = obj_bnd.find('xmax') obj_ymax = obj_bnd.find('ymax') # 以防有负值坐标 xmin = max(float(obj_xmin.text), 0) ymin = max(float(obj_ymin.text), 0) xmax = max(float(obj_xmax.text), 0) ymax = max(float(obj_ymax.text), 0) obj_bnd.remove(obj_xmin) # 删除节点 obj_bnd.remove(obj_ymin) obj_bnd.remove(obj_xmax) obj_bnd.remove(obj_ymax) x0.text = str(xmin) y0.text = str(ymax) x1.text = str(xmax) y1.text = str(ymax) x2.text = str(xmax) y2.text = str(ymin) x3.text = str(xmin) y3.text = str(ymin) else: obj_bnd = obj.find('robndbox') obj_bnd.tag = 'bndbox' # 修改节点名 obj_cx = obj_bnd.find('cx') obj_cy = obj_bnd.find('cy') obj_w = obj_bnd.find('w') obj_h = obj_bnd.find('h') obj_angle = obj_bnd.find('angle') cx = float(obj_cx.text) cy = float(obj_cy.text) w = float(obj_w.text) h = float(obj_h.text) angle = float(obj_angle.text) obj_bnd.remove(obj_cx) # 删除节点 obj_bnd.remove(obj_cy) obj_bnd.remove(obj_w) obj_bnd.remove(obj_h) obj_bnd.remove(obj_angle) x0.text, y0.text = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle) x1.text, y1.text = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle) x2.text, y2.text = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle) x3.text, y3.text = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle) # obj.remove(obj_type) # 删除节点 obj_bnd.append(x0) # 新增节点 obj_bnd.append(y0) obj_bnd.append(x1) obj_bnd.append(y1) obj_bnd.append(x2) obj_bnd.append(y2) obj_bnd.append(x3) obj_bnd.append(y3) tree.write(dotaxml_file, method='xml', encoding='utf-8') # 更新xml文件 # 转换成四点坐标 def rotatePoint(xc, yc, xp, yp, theta): xoff = xp - xc; yoff = yp - yc; cosTheta = math.cos(theta) sinTheta = math.sin(theta) pResx = cosTheta * xoff + sinTheta * yoff pResy = - sinTheta * xoff + cosTheta * yoff return str(int(xc + pResx)), str(int(yc + pResy)) def totxt(xml_path, out_path): # 想要生成的txt文件保存的路径,这里可以自己修改 files = os.listdir(xml_path) i = 0 for file in files: tree = ET.parse(xml_path + os.sep + file) root = tree.getroot() name = file.split('.')[0] output = out_path + '\\' + name + '.txt' file = open(output, 'w') i = i + 1 objs = tree.findall('object') for obj in objs: cls = obj.find('name').text box = obj.find('bndbox') x0 = int(float(box.find('x0').text)) y0 = int(float(box.find('y0').text)) x1 = int(float(box.find('x1').text)) y1 = int(float(box.find('y1').text)) x2 = int(float(box.find('x2').text)) y2 = int(float(box.find('y2').text)) x3 = int(float(box.find('x3').text)) y3 = int(float(box.find('y3').text)) if x0 < 0: x0 = 0 if x1 < 0: x1 = 0 if x2 < 0: x2 = 0 if x3 < 0: x3 = 0 if y0 < 0: y0 = 0 if y1 < 0: y1 = 0 if y2 < 0: y2 = 0 if y3 < 0: y3 = 0 for cls_index, cls_name in enumerate(cls_list): if cls == cls_name: file.write("{} {} {} {} {} {} {} {} {} {}\n".format(x0, y0, x1, y1, x2, y2, x3, y3, cls, cls_index)) file.close() # print(output) print(i) if __name__ == '__main__': # -----**** 第一步:把xml文件统一转换成旋转框的xml文件 ****----- roxml_path = r'D:\data\yolov8_obb\origin_xml' # labelimg2标注生成的原始xml文件路径 dotaxml_path = r'D:\data\yolov8_obb\dota_xml' # 转换后dota能识别的xml文件路径,路径需存在,不然报错 out_path = r'D:\data\yolov8_obb\dota_txt' # 转换后dota格式的txt文件路径,路径需存在,不然报错 filelist = os.listdir(roxml_path) for file in filelist: edit_xml(os.path.join(roxml_path, file), os.path.join(dotaxml_path, file)) # -----**** 第二步:把旋转框xml文件转换成txt格式 ****----- totxt(dotaxml_path, out_path) 转换后的TXT格式的标签文件(此时的标签还不是OBB数据集的格式,还需要再转换):

(3)划分数据集
接下来划分数据集:使用下面的代码划分数据集
import os import random import shutil random.seed(42) """ 该脚本用于将给定的数据集分割成训练集和测试集。 数据集应包含图像和对应的标注文件。 脚本会按照90%训练集和10%测试集的比例进行分割,并将图像和标注文件分别复制到相应的文件夹中。 """ # 设置数据集文件夹路径和输出文件夹路径 data_folder = 'data_mouse_ro' img_folder = 'data_mouse_ro/dataset/images' label_folder = 'data_mouse_ro/dataset/labels' # 计算每个子集的大小 # 总文件数乘以0.9得到训练集大小,其余为测试集大小 total_files = len(os.listdir(os.path.join(data_folder, 'img'))) train_size = int(total_files * 0.9) test_size = int(total_files - train_size) # 获取所有图像文件的文件名列表,并进行随机打乱 image_files = os.listdir(os.path.join(data_folder, 'img')) random.shuffle(image_files) # 复制图像和标注文件到相应的子集文件夹中 # 枚举每个图像文件,根据索引决定复制到训练集还是测试集文件夹 for i, image_file in enumerate(image_files): base_file_name = os.path.splitext(image_file)[0] # 获取文件名(不包括扩展名) image_path = os.path.join(data_folder, 'img', image_file) label_path = os.path.join(data_folder, 'dotatxt', base_file_name + '.txt') # 根据索引判断文件应复制到训练集还是测试集 if i < train_size: shutil.copy(image_path, os.path.join(img_folder, 'train')) # 复制图像到训练集 shutil.copy(label_path, os.path.join(label_folder, 'train_original')) # 复制标注到训练集 else: shutil.copy(image_path, os.path.join(img_folder, 'val')) # 复制图像到测试集 shutil.copy(label_path, os.path.join(label_folder, 'val_original')) # 复制标注到测试集运行代码前文件夹结构如下(所有图像放在img文件夹下,所有txt放在dotatxt文件夹下)

运行代码后dataset中的train和val文件夹就已经有了划分好的图像,labels中的train_original和val_original有对应的train和val标签

(4)DOTA格式标签文件转换为YOLO V8训练所需的YOLO格式
【1】在项目代码根目录下面创建下面的文件夹结构,然后将划分好的图像和标签文件放到相应的文件夹中


【2】由于官方源码转换代码用的是VOC数据集,所以这里我们需要修改ultralytics/data/converter.py中的类别名,改成自己的数据集类别名。修改ultralytics/data/converter.py中的代码

【3】运行下面的代码,将DOTA格式的标签文件转换为OBB数据集格式,其中的参数根据自己的情况设置
import sys sys.path.append('F:\object_detection\yolov8_obb_version2\yolov8') from ultralytics.data.converter import convert_dota_to_yolo_obb convert_dota_to_yolo_obb('F:\object_detection\yolov8_obb_version2\yolov8\data')运行提示:

转换后的OBB数据集格式的标签会保存在labels\train和labels\val中(训练需要使用的就是这两个文件夹,train_original和val_original用不到)
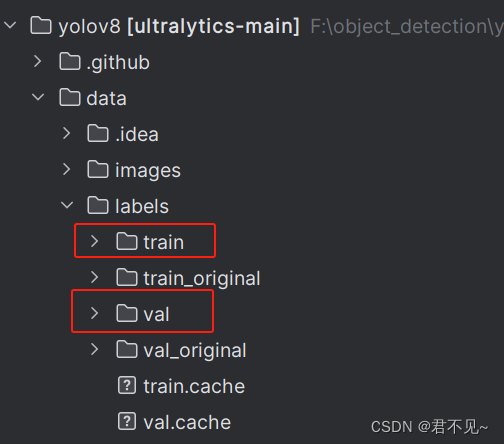
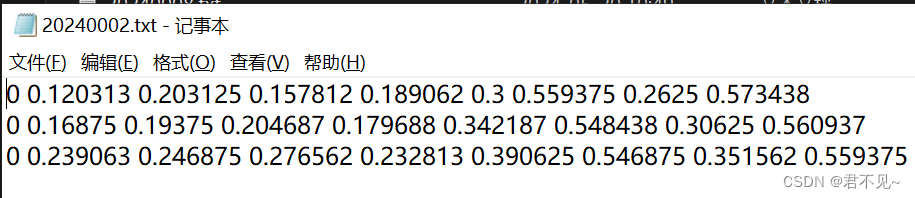
转换后的OBB数据集格式的标签文件中的内容
others tips(2024.07.10更新):
之前我是在裁剪、挑选图像之后才做标注的,挑选图像和标注图像花的时间多,消耗精力大。其实也可以对整幅影像进行标注,标注完了再使用代码裁剪图像,标注也会根据裁剪得到的图像进行更新,这样更省时省力。但是整幅标注再裁剪的方法会将标注的目标物体切割为几部分,在训练中我发现这样似乎不利于涨点,但是也没有明显丢点。自己裁剪挑选图像的话可以尽可能挑选目标物体整体位于图像内的图像,方便标注也有利于模型学习整体特征(个人主观认为)。
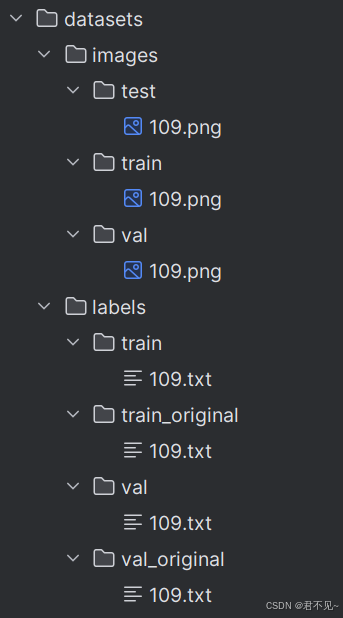
datasets和DOTAv1.0-split文件夹结构

下面是将整幅影影及其标注裁剪的代码:
from ultralytics.data.split_dota import split_test, split_trainval # 分割训练集和验证集,同时包含标签。标签需要是YOLO格式的, # 即:0 0.332813 0.164062 0.403125 0.15 0.45 0.373437 0.379688 0.389062 # # @param data_root str,数据根目录的路径。 # @param save_dir str,保存分割后数据集的目录路径。 # @param rates list,用于设定不同尺度分割比例的列表,例如[0.5, 1.0, 1.5]表示三个尺度。 # @param gap int,设定在数据集中间隔多少个样本进行一次分割。 split_trainval( data_root=r"F:\yolov8_obb_version\datasets", save_dir=r"F:\yolov8_obb_version\DOTAv1.0-split", rates=[1.0, 1.5], # multiscale 1.0(640x640) 1.5(426x426) gap=100, ) # 分割测试集,不包含标签。 # # @param data_root str,数据根目录的路径。 # @param save_dir str,保存分割后数据集的目录路径。 # @param rates list,用于设定不同尺度分割比例的列表,例如[0.5, 1.0, 1.5]表示三个尺度。 # @param gap int,设定在数据集中间隔多少个样本进行一次分割。 split_test( data_root=r"F:\\yolov8_obb_version\datasets", save_dir=r"F:\yolov8_obb_version\DOTAv1.0-split", rates=[1.0, 1.5], # multiscale gap=100, 运行代码之前记得调整导入函数的参数,运行代码之后裁剪的图像和对应的标注文件会在DOTAv1.0-split文件夹中。
三、模型配置
(1)新建模型配置文件my-data8-obb.yaml
在yolov8\ultralytics\cfg\datasets路径下,新建my-data8-obb.yaml文件(复制粘贴其中某一个yaml文件改个名字),写入如下代码,其中参数根据自己的情况设置
path: F:\object_detection\yolov8_obb_version2\yolov8\data # dataset root dir train: images/train # train images (relative to 'path') 4 images val: images/val # val images (relative to 'path') 4 images # Classes for DOTA 1.0 names: 0: dog(2)修改模型配置文件yolov8-obb.yaml
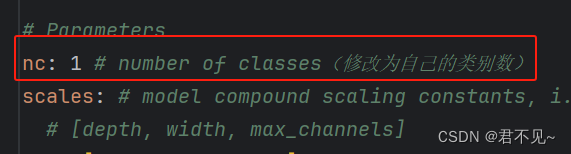
在yolov8\ultralytics\cfg\models\v8路径下,修改yolov8-obb.yaml文件,将nc参数修改为自己的数据集类别数
四、训练
(1)根据自己的实际情况修改yolov8\ultralytics\cfg\default.yaml文件中的训练参数
如果自己的数据集类别只有一种,就将single-cls参数设置为True

(2)运行下面的代码即可开始训练
如果你使用的权重是“yolov8n-obb.pt”,只需要把下面代码中的配置文件yolov8x-obb.yaml改成yolov8n-obb.yaml,依此类推
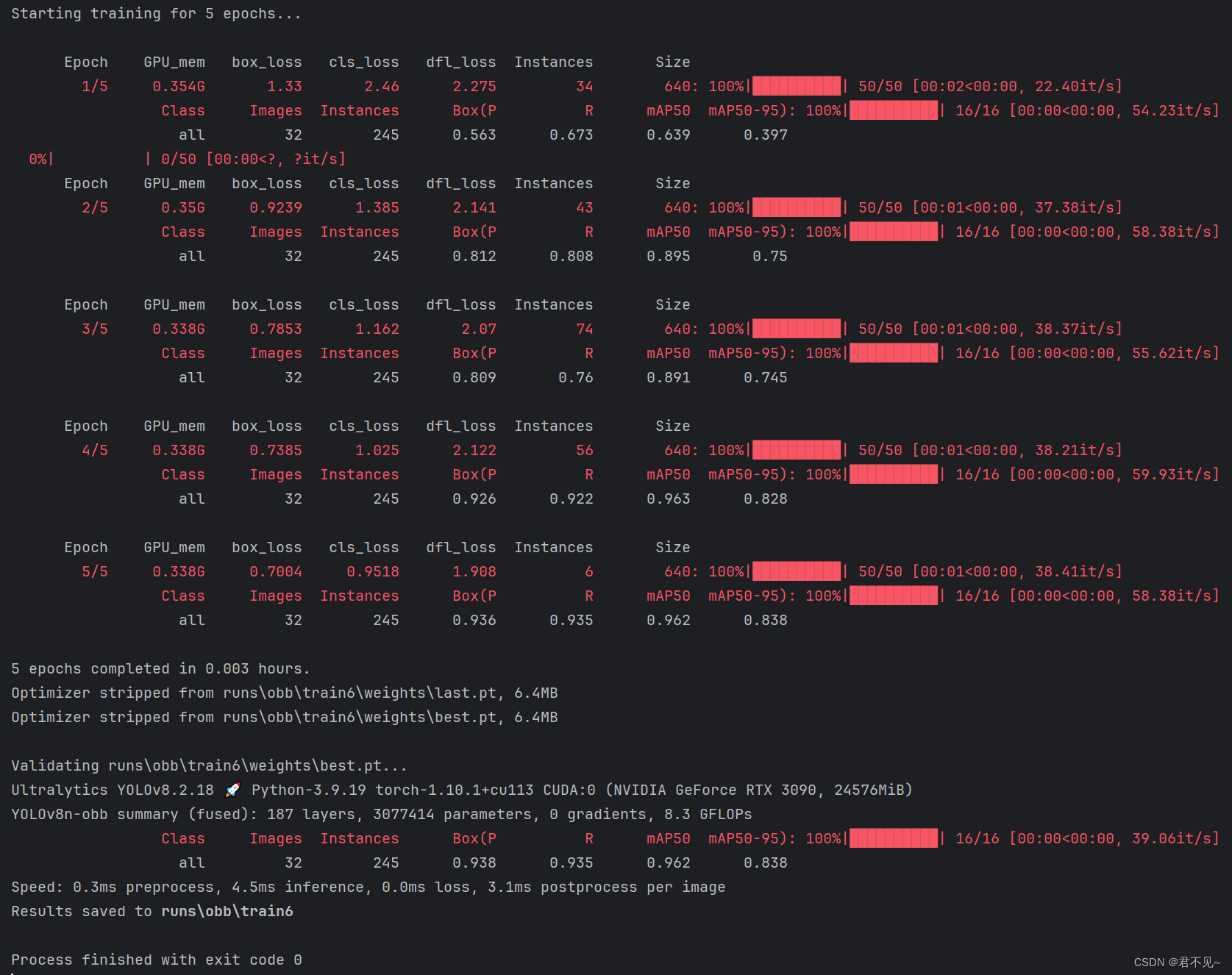
from ultralytics import YOLO def main(): model = YOLO('ultralytics/cfg/models/v8/yolov8x-obb.yaml').load('pt/yolov8x-obb.pt') # build from YAML and transfer weights model.train(data='ultralytics/cfg/datasets/my-data8-obb.yaml', epochs=5, imgsz=640, batch=16, workers=4) if __name__ == '__main__': main()训练过程及结果(5个Epoch)
五、验证
在根目录下创建一个名为eval.py的脚本,写入下面的代码,其中的参数根据自己的情况设置
from ultralytics import YOLO def main(): model = YOLO(r'runs/obb/train/weights/best.pt') model.val(data='ultralytics/cfg/datasets/my-data8-obb.yaml', imgsz=640, batch=4, workers=4) if __name__ == '__main__': main()运行代码的结果:

下面是验证保存的图像(标签为dog是因为在使用lableimg2制作标签的时候懒得改了,采用了软件默认的dog)

六、推理
在根目录下创建一个名为predict.py的脚本,写入下面的代码,其中的参数根据自己的情况设置
from ultralytics import YOLO model = YOLO('runs/obb/train/weights/best.pt') results = model('predict_images/2024_0018.jpg', save=True) print(results[0].obb.xywhr[:, -1] * 180 / 3.14159265358979323846)运行代码的结果

推理保存的图像(标签为dog是因为在使用lableimg2制作标签的时候懒得改了,采用了软件默认的dog)

目前就做了这些工作,在数据集数量和质量方面还存在不足,在接下来会解决这部分的问题
这只是一个篇分享经验的文章,难免有错误或者遗漏的地方,欢迎交流指正
