阅读量:0
目录
一. 回顾
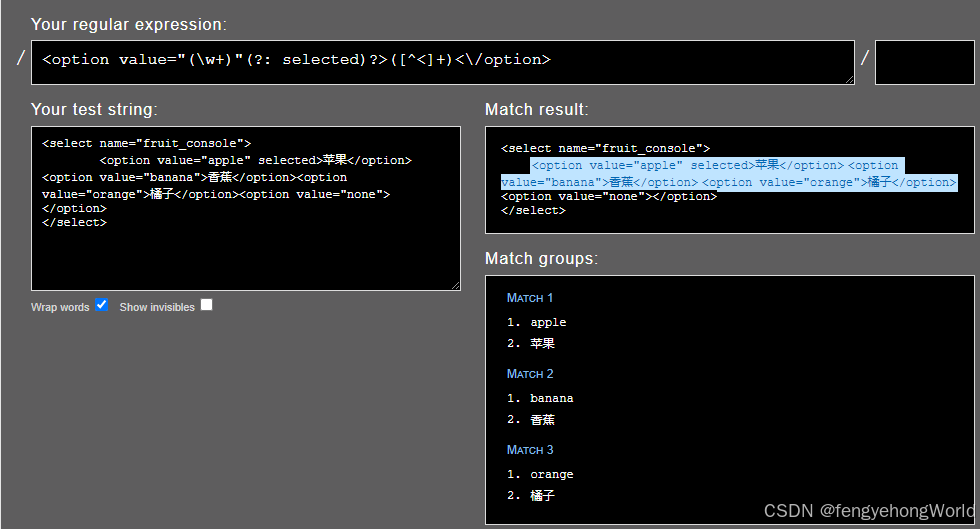
我们在正则表达式 分组与非捕获组这篇文章中,有如下分组匹配案例
<select name="fruit_console"> <option value="apple" selected>苹果</option> <option value="banana">香蕉</option> <option value="orange">橘子</option> <option value="none"></option> </select> ⏹<option value="(\w+)"(?:\s+selected)?>(.+)<\/option>
- 我们使用上述正则表达式分组匹配了option元素中的value和文本
二. 遇到的问题
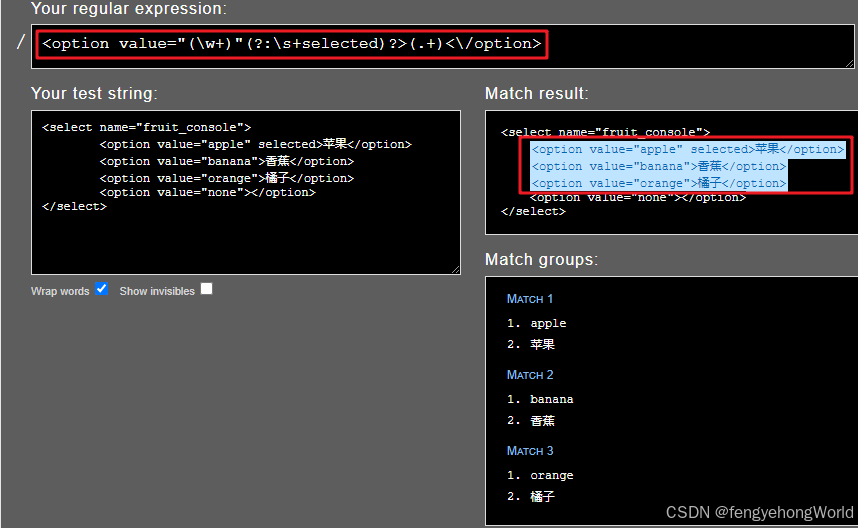
😵如果option元素都在同一行的话,继续使用之前的正则表达式
<option value="(\w+)"(?:\s+selected)?>(.+)<\/option>
进行匹配的话
<select name="fruit_console"> <option value="apple" selected>苹果</option><option value="banana">香蕉</option><option value="orange">橘子</option><option value="none"></option> </select> 😒就会遇到下面的问题
apple是我们预期的匹配值- 但是匹配到
苹果之后,还继续向后匹配到了很多预期外的数据 - 预想的是匹配3组数据,但是实际只匹配到1组,而且匹配失败
三. 分析
⏹正则表达式有两种模式
- 贪婪模式:尽可能的多匹配文本
- 正则表达式默认情况下是贪婪模式
*,+,{}都默认贪婪匹配
- 非贪婪模式:会尽可能少的匹配文本
- 在量词后面加上
?就可以转换为非贪婪匹配
- 在量词后面加上
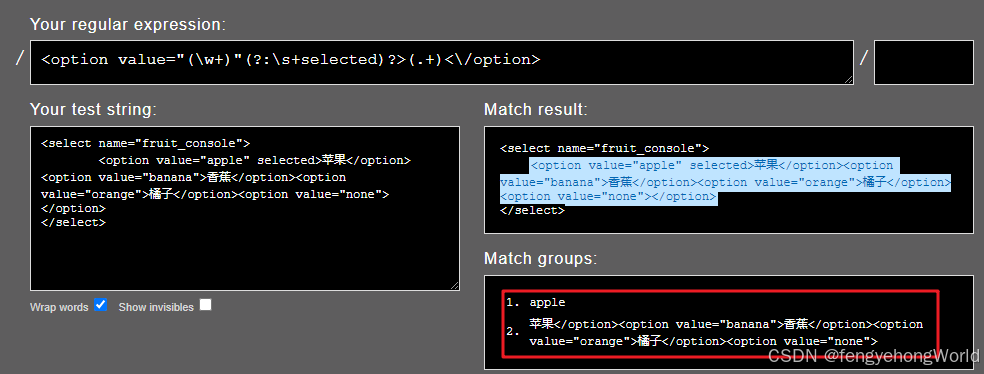
⭐我们使用下面的正则表达式
<option value="(\w+)"(?:\s+selected)?>(.+)<\/option>
⭐匹配下面的HTML的时候
<option value="apple" selected>苹果</option><option value="banana">香蕉</option><option value="orange">橘子</option><option value="none"></option> 🤔当(.+)进行匹配的时候,由于html都在一行,当匹配到苹果的时候,由于苹果后面还有符合条件的文本,于是贪婪模式的(.+)会继续向后匹配,直到匹配到最后。
四. 解决
4.1 转换为非贪婪模式匹配
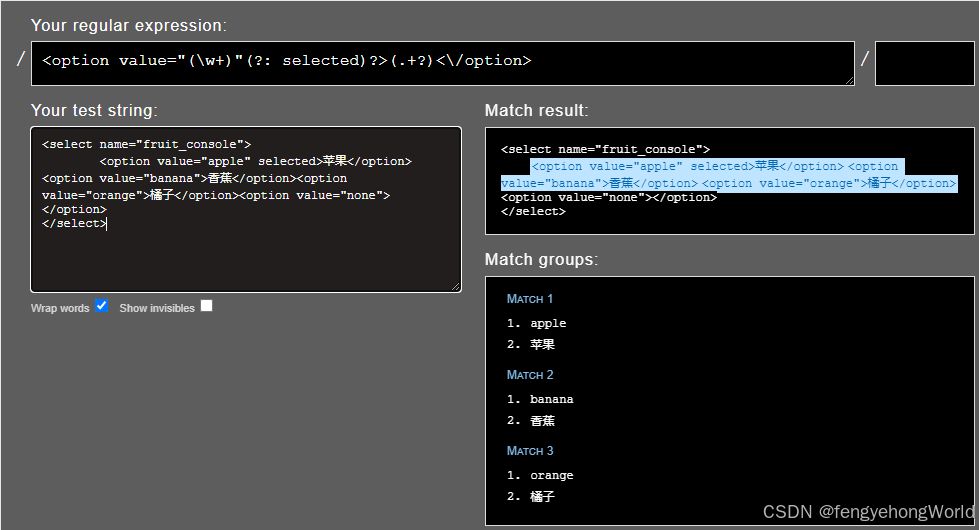
⏹<option value="(\w+)"(?: selected)?>(.+?)<\/option>
- 通过添加
?,将贪婪的.+转换为非贪婪的.+? - 在非贪婪匹配模式下,
(.+?)匹配到苹果之后,就不会继续向后匹配了
4.2 提高匹配的精度
⏹<option value="(\w+)"(?: selected)?>([^<]+)<\/option>
[^<]+:匹配除了<之外的所有内容- 也就是说当匹配到
>苹果<的时候,由于苹果的后面有一个<,因此就只会匹配到苹果,不会继续向后匹配 - 从而完成了精确匹配