
阅读量:0
3dgs代码前向传播部分
先来讨论一下glm,因为定义变量的时候用到了这个。
glm的解释
glm 是指 OpenGL Mathematics,这是一个针对图形编程的数学库。它的全称是 OpenGL Mathematics (GLM),主要用于 OpenGL 的开发。这个库是基于 C++ 的模板库,设计目标是尽可能提供类似 GLSL(OpenGL 着色语言)的语法和功能,使得在 C++ 中使用数学运算时更加直观和方便。
GLM 提供了各种数学功能和数据结构,包括:
- 向量(vec2, vec3, vec4)
- 矩阵(mat2, mat3, mat4)
- 四元数(quaternion)
- 常见的数学函数(如平移、旋转、缩放、透视投影等)
在计算机视觉领域,处理几何变换和坐标系转换时,GLM 非常有用。例如,我们需要进行矩阵运算、向量运算等,都可以通过 GLM 提供的功能来方便地实现。使用方法如下所示。
1. 向量
glm::vec3 v1(1.0f, 2.0f, 3.0f); glm::vec3 v2(4.0f, 5.0f, 6.0f); glm::vec3 v3 = v1 + v2; // 向量加法 2. 矩阵
#include <glm/gtc/matrix_transform.hpp> glm::mat4 identity = glm::mat4(1.0f); // 单位矩阵 glm::mat4 translation = glm::translate(identity, glm::vec3(10.0f, 0.0f, 0.0f)); // 平移矩阵 glm::mat4 rotation = glm::rotate(identity, glm::radians(45.0f), glm::vec3(0.0f, 1.0f, 0.0f)); // 旋转矩阵 3. 四元数
#include <glm/gtc/quaternion.hpp> glm::quat q = glm::angleAxis(glm::radians(90.0f), glm::vec3(0.0f, 1.0f, 0.0f)); // 绕 Y 轴 3dgs的代码的forward部分
球谐函数的建立
submodules\diff-gaussian-rasterization\cuda_rasterizer\forward.cu line 20 // Forward method for converting the input spherical harmonics // coefficients of each Gaussian to a simple RGB color. __device__ glm::vec3 computeColorFromSH(int idx, int deg, int max_coeffs, const glm::vec3* means, glm::vec3 campos, const float* shs, bool* clamped) { ''' 这个函数基于 Zhang 等人 (2022) 的论文"Differentiable Point-Based Radiance Fields for Efficient View Synthesis" 中的代码实现 ''' // 获取当前点的中心位置 glm::vec3 pos = means[idx]; // 计算从相机位置到当前点的位置向量 glm::vec3 dir = pos - campos; // 将位置向量归一化 dir = dir / glm::length(dir); // 获取当前点的 SH 系数 glm::vec3* sh = ((glm::vec3*)shs) + idx * max_coeffs; // 计算 SH 零阶系数的颜色值 glm::vec3 result = SH_C0 * sh[0]; // 如果阶数大于 0,则计算一阶 SH 系数的颜色值 if (deg > 0) { float x = dir.x; float y = dir.y; float z = dir.z; result = result - SH_C1 * y * sh[1] + SH_C1 * z * sh[2] - SH_C1 * x * sh[3]; // 如果阶数大于 1,则计算二阶 SH 系数的颜色值 if (deg > 1) { float xx = x * x, yy = y * y, zz = z * z; float xy = x * y, yz = y * z, xz = x * z; result = result + SH_C2[0] * xy * sh[4] + SH_C2[1] * yz * sh[5] + SH_C2[2] * (2.0f * zz - xx - yy) * sh[6] + SH_C2[3] * xz * sh[7] + SH_C2[4] * (xx - yy) * sh[8]; // 如果阶数大于 2,则计算三阶 SH 系数的颜色值 if (deg > 2) { result = result + SH_C3[0] * y * (3.0f * xx - yy) * sh[9] + SH_C3[1] * xy * z * sh[10] + SH_C3[2] * y * (4.0f * zz - xx - yy) * sh[11] + SH_C3[3] * z * (2.0f * zz - 3.0f * xx - 3.0f * yy) * sh[12] + SH_C3[4] * x * (4.0f * zz - xx - yy) * sh[13] + SH_C3[5] * z * (xx - yy) * sh[14] + SH_C3[6] * x * (xx - 3.0f * yy) * sh[15]; } } } // 为结果颜色值加上一个偏移量 result += 0.5f; // 将 RGB 颜色值限制在正值范围内。如果值被限制,则需要在反向传播过程中记录此信息。 clamped[3 * idx + 0] = (result.x < 0); clamped[3 * idx + 1] = (result.y < 0); clamped[3 * idx + 2] = (result.z < 0); return glm::max(result, 0.0f); } EWA投影来消除误差
submodules\diff-gaussian-rasterization\cuda_rasterizer\forward.cu line 73 // Forward version of 2D covariance matrix computation // 在 CUDA 设备上定义的函数,用于计算2D协方差矩阵 __device__ float3 computeCov2D(const float3& mean, float focal_x, float focal_y, float tan_fovx, float tan_fovy, const float* cov3D, const float* viewmatrix) { // 该函数实现了 "EWA Splatting" (Zwicker et al., 2002) 中的公式29和31, // 同时考虑了视口的纵横比/缩放。 // 转置用于处理行/列优先顺序。 // 将3D点转换到视图坐标系中 float3 t = transformPoint4x3(mean, viewmatrix); // 定义x和y方向的视锥限制 const float limx = 1.3f * tan_fovx; const float limy = 1.3f * tan_fovy; const float txtz = t.x / t.z; const float tytz = t.y / t.z; // 限制x和y方向的值,使其不超过视锥限制 t.x = min(limx, max(-limx, txtz)) * t.z; t.y = min(limy, max(-limy, tytz)) * t.z; // 计算雅可比矩阵J,表示从3D到2D的投影变换 glm::mat3 J = glm::mat3( focal_x / t.z, 0.0f, -(focal_x * t.x) / (t.z * t.z), 0.0f, focal_y / t.z, -(focal_y * t.y) / (t.z * t.z), 0, 0, 0); // 提取视图矩阵的前3x3部分,用于线性变换 glm::mat3 W = glm::mat3( viewmatrix[0], viewmatrix[4], viewmatrix[8], viewmatrix[1], viewmatrix[5], viewmatrix[9], viewmatrix[2], viewmatrix[6], viewmatrix[10]); // 计算组合变换矩阵T glm::mat3 T = W * J; // 从输入的3D协方差矩阵中构建Vrk矩阵 glm::mat3 Vrk = glm::mat3( cov3D[0], cov3D[1], cov3D[2], cov3D[1], cov3D[3], cov3D[4], cov3D[2], cov3D[4], cov3D[5]); // 计算最终的2D协方差矩阵 glm::mat3 cov = glm::transpose(T) * glm::transpose(Vrk) * T; // 应用低通滤波器:每个高斯函数应至少在一个像素宽/高 // 丢弃第3行和第3列 cov[0][0] += 0.3f; cov[1][1] += 0.3f; // 返回2D协方差矩阵的三个元素 return { float(cov[0][0]), float(cov[0][1]), float(cov[1][1]) }; } EWA Splatting论文中6.2.2节的描述
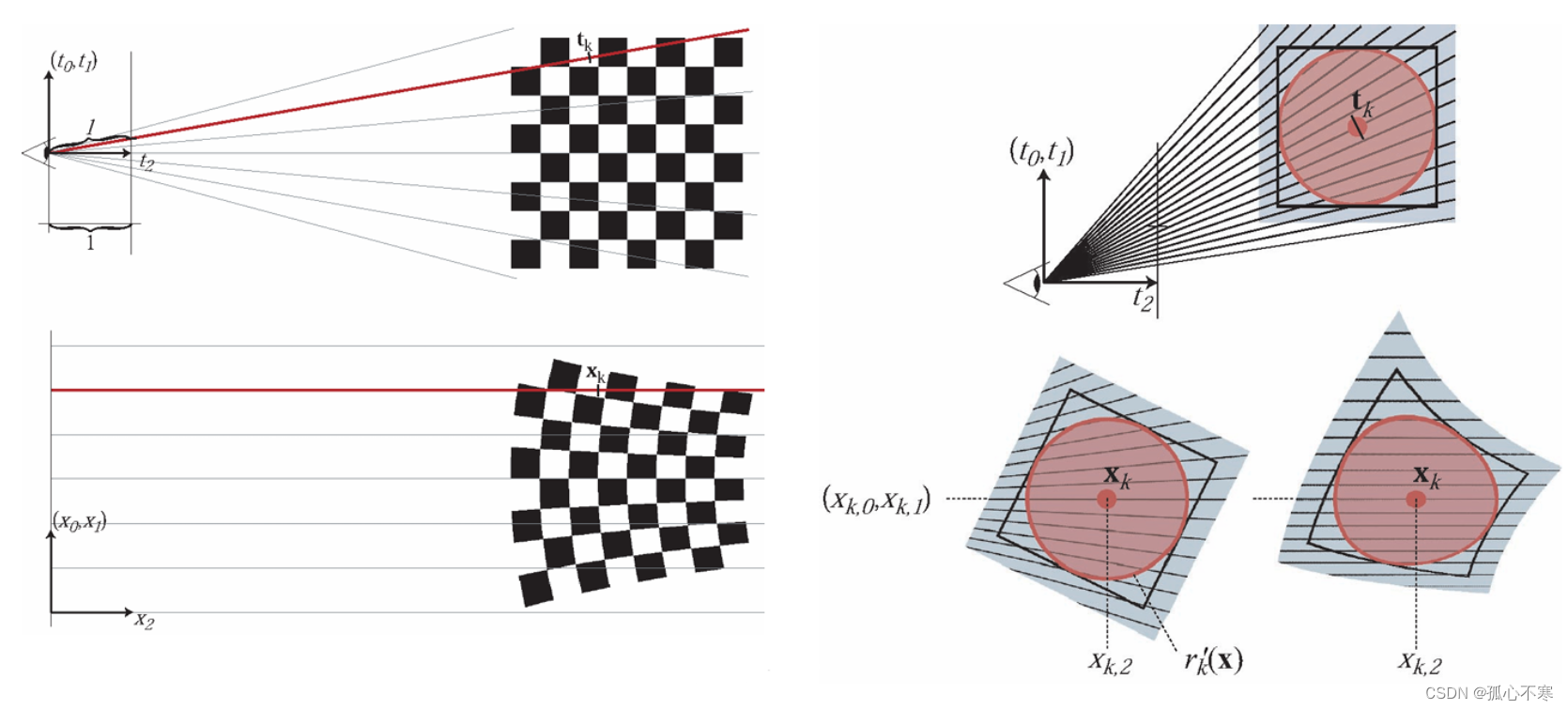
我们将视图变换与将相机坐标转换为射线坐标的投影变换连接起来,如图8所示。相机空间的定义是相机坐标系的原点在投影中心,投影平面是 t 2 = 1 t_2 = 1 t2=1 的平面。相机空间和射线空间通过映射 x = t \mathbf{x} = \mathbf{t} x=t相关联。使用第4.1节中的射线空间定义, t \mathbf{t} t及其逆映射 t − 1 \mathbf{t}^{-1} t−1可以表示为:
( x 0 x 1 x 2 ) = ϕ ( t ) = ( t 0 / t 2 t 1 / t 2 ∣ ∣ ( t 0 , t 1 , t 2 ) T ∣ ∣ ) (26) \begin{pmatrix} x_0 \\ x_1 \\ x_2 \end{pmatrix} =\phi(t)= \begin{pmatrix} t_0/t_2 \\ t_1/t_2 \\ ||(t_0,t_1,t_2)^T|| \end{pmatrix} \tag{26} x0x1x2=ϕ(t)=t0/t2t1/t2∣∣(t0,t1,t2)T∣∣(26)
( t 0 t 1 t 2 ) = ϕ − 1 ( x ) = ( x 0 / l ⋅ x 2 x 1 / l ⋅ x 2 1 / l ⋅ x 2 ) (27) \begin{pmatrix} t_0 \\ t_1 \\ t_2 \end{pmatrix} =\phi^{-1}(x)= \begin{pmatrix} x_0/l \cdot x_2 \\ x_1/l \cdot x_2 \\ 1/l \cdot x_2 \end{pmatrix} \tag{27} t0t1t2=ϕ−1(x)=x0/l⋅x2x1/l⋅x21/l⋅x2(27)
其中, l = ∣ ∣ ( x 0 , x 1 , 1 ) ∣ ∣ T l = ||(x_0, x_1, 1)||^T l=∣∣(x0,x1,1)∣∣T。
不幸的是,这些映射不是仿射的,因此我们不能直接应用公式(21): G V n ( Φ − 1 ( u ) − p ) = 1 ∣ M − 1 ∣ G M V M T n ( u − Φ ( p ) ) G^n_V(\Phi^{-1}(u)-p)=\frac{1}{|M^{-1}|}G^{n}_{MVM^T}(u-\Phi(p)) GVn(Φ−1(u)−p)=∣M−1∣1GMVMTn(u−Φ(p))将重建核从相机空间转换到射线空间。为了解决这个问题,我们引入了投影变换的局部仿射近似 ϕ k \phi_k ϕk,它由在点 t k t_k tk的泰勒展开的前两项 ϕ \mathbf{\phi} ϕ定义:
ϕ k ( t ) = x k + J k ⋅ ( t − t k ) (28) \phi_k(\mathbf{t}) = \mathbf{x}_k + J_k \cdot(\mathbf{t} - \mathbf{t}_k) \tag{28} ϕk(t)=xk+Jk⋅(t−tk)(28)
其中 t k \mathbf{t}_k tk 是相机空间中的高斯中心, x k = ϕ ( t k ) \mathbf{x}_k = \phi(\mathbf{t}_k) xk=ϕ(tk)是对应的射线空间中的位置。雅可比矩阵 J k \mathbf{J}_k Jk由在点 t k \mathbf{t}_k tk处的 ϕ \mathbf{\phi} ϕ的偏导数给出:
J k = ∂ ϕ ∂ t ( t k ) = [ 1 / t k , 2 0 − t k , 0 / t k , 2 2 0 1 / t k , 2 − t k , 1 / t k , 2 2 t k , 0 / l ′ t k , 1 / l ′ t k , 2 / l ′ ] (29) J_k = \frac{\partial \mathbf{\phi}}{\partial \mathbf{t}}(\mathbf{t}_k) = \begin{bmatrix} 1/t_{k,2} & 0 & -t_{k,0}/t^2_{k,2} \\ 0 & 1/t_{k,2} & -t_{k,1}/t^2_{k,2} \\ t_{k,0}/l' & t_{k,1}/l' & t_{k,2}/l' \end{bmatrix} \tag{29} Jk=∂t∂ϕ(tk)=1/tk,20tk,0/l′01/tk,2tk,1/l′−tk,0/tk,22−tk,1/tk,22tk,2/l′(29)
其中 l ′ = ∣ ∣ ( t k , 0 , t k , 1 , t k , 2 ) T ∣ ∣ l' = ||(t_{k,0}, t_{k,1}, t_{k,2})^T|| l′=∣∣(tk,0,tk,1,tk,2)T∣∣。
从源到射线空间的复合映射 x = m k ( u ) \mathbf{x} = m_k(\mathbf{u}) x=mk(u) 的局部仿射近似通过 t = φ ( u ) \mathbf{t} = \varphi(\mathbf{u}) t=φ(u)和 x = ϕ k ( t ) \mathbf{x} = \phi_k(\mathbf{t}) x=ϕk(t)的连接给出:
x = m k ( u ) = ϕ k ( φ ( u ) = J k W u + x k + J k ( d − t k ) \mathbf{x} = \mathbf{m}_k(\mathbf{u}) = \phi_k(\varphi(\mathbf{u}) = \mathbf{J}_k W \mathbf{u} + \mathbf{x}_k + \mathbf{J}_k (\mathbf{d} - \mathbf{t}_k) x=mk(u)=ϕk(φ(u)=JkWu+xk+Jk(d−tk)
我们在公式 (25): r k ( u ) = G V k ( u − u k ) r_k(u)=G_{V_k}(u-u_k) rk(u)=GVk(u−uk) 采用替换 u = m k − 1 ( x ) \mathbf{u} = m_k^{-1}(\mathbf{x}) u=mk−1(x) ,并应用到公式 (21) 将重建核映射到射线空间,得到期望的 r k ′ ( x ) r_k'(\mathbf{x}) rk′(x)表达式:
r k ′ ( x ) = G V k ( m − 1 ( x ) − u k ) = 1 ∣ W − 1 J k − 1 ∣ G V k ′ ( x − m ( u k ) ) (30) r_k'(\mathbf{x}) = G_{V_k} (m^{-1}(\mathbf{x}) - \mathbf{u}_k)\\ =\frac{1}{|W^{-1} J_k^{-1}|} G_{V'_k} (\mathbf{x} - m(\mathbf{u}_k)) \tag{30} rk′(x)=GVk(m−1(x)−uk)=∣W−1Jk−1∣1GVk′(x−m(uk))(30)
其中 V k ′ V_k' Vk′是射线坐标中的方差矩阵。根据公式 (21), V k ′ V_k' Vk′ 由以下公式给出:
V k ′ = J k W V k W T J k T (31) V_k' = J_k W V_k W^T J^T_k \tag{31} Vk′=JkWVkWTJkT(31)
请注意,对于均匀或直线数据集, W V k W T W V_k W^T WVkWT的乘积每帧只需计算一次,因为 V k V_k Vk对所有体素都是相同的,而 W W W 只随帧变化。由于雅可比矩阵对每个体素位置不同,因此需要为每个体素重新计算 V k ′ V_k' Vk′,这需要进行两次 3 × 3 3 \times 3 3×3矩阵乘法: V k ′ = J k ( W V k W T ) J k V_k' = J_k (W V_k W^T) J_k Vk′=Jk(WVkWT)Jk。在曲线或不规则体积的情况下,每个重建核都有一个独立的方差矩阵 V k V_k Vk。我们的方法有效地处理了这种情况,只需要一次额外的 3 × 3 3\times3 3×3矩阵乘法,即 V k ′ = ( J k W ) V k ( J k W ) T V_k' = (J_k W) V_k (J_k W)^T Vk′=(JkW)Vk(JkW)T。相比之下,以前的技术通过在屏幕空间计算椭圆核的投影范围,然后建立到圆形足迹表的映射来应对椭圆核。然而,这个过程计算量很大.
如图所示,局部仿射映射对于通过 t k \mathbf{t}_k tk或 x k \mathbf{x}_k xk的射线是精确的。图中为了展示精确映射中的非线性效果而进行了夸张处理。仿射映射本质上用斜正交投影来近似透视投影。因此,平行线得以保留,并且随着射线发散度的增加,近似误差也会增加。然而,误差通常不会导致视觉伪影,因为交叉重建核的射线束的开口角度较小。
一种常见的执行透视投影的方法是首先将足迹函数映射到相机空间中的足迹多边形。下一步,将足迹多边形投影到屏幕空间并光栅化,生成所谓的足迹图像。我们的框架通过将体积映射到射线空间来有效地执行透视投影,这只需要计算雅可比矩阵和两次 3 × 3 3 \times3 3×3矩阵乘法。对于球形重建核,这些矩阵操作可以进一步优化,在7.1节中将会展示
协方差矩阵的构建
submodules\diff-gaussian-rasterization\cuda_rasterizer\forward.cu line 115 __device__ void computeCov3D(const glm::vec3 scale, float mod, const glm::vec4 rot, float* cov3D) { // 创建缩放矩阵 glm::mat3 S = glm::mat3(1.0f); S[0][0] = mod * scale.x; S[1][1] = mod * scale.y; S[2][2] = mod * scale.z; // 标准化四元数以获得有效的旋转 glm::vec4 q = rot; // 假设已经是单位四元数,不再进行额外的标准化 float r = q.x; float x = q.y; float y = q.z; float z = q.w; // 根据四元数计算旋转矩阵 glm::mat3 R = glm::mat3( 1.f - 2.f * (y * y + z * z), 2.f * (x * y - r * z), 2.f * (x * z + r * y), 2.f * (x * y + r * z), 1.f - 2.f * (x * x + z * z), 2.f * (y * z - r * x), 2.f * (x * z - r * y), 2.f * (y * z + r * x), 1.f - 2.f * (x * x + y * y) ); // 计算M矩阵,即缩放后的旋转矩阵 glm::mat3 M = S * R; // 计算3D世界协方差矩阵Sigma glm::mat3 Sigma = glm::transpose(M) * M; // 协方差矩阵是对称的,只存储上三角部分 cov3D[0] = Sigma[0][0]; // Cov(xx) cov3D[1] = Sigma[0][1]; // Cov(xy) cov3D[2] = Sigma[0][2]; // Cov(xz) cov3D[3] = Sigma[1][1]; // Cov(yy) cov3D[4] = Sigma[1][2]; // Cov(yz) cov3D[5] = Sigma[2][2]; // Cov(zz) } 数据预处理
// Perform initial steps for each Gaussian prior to rasterization. // 在光栅化之前,对每个高斯进行初始预处理步骤。 template<int C> __global__ void preprocessCUDA(int P, int D, int M, const float* orig_points, // 原始点的数组 const glm::vec3* scales, // 缩放因子数组 const float scale_modifier, // 缩放因子修正值 const glm::vec4* rotations, // 四元数旋转数组 const float* opacities, // 透明度数组 const float* shs, // 球谐系数数组 bool* clamped, // 是否被夹住的标志数组 const float* cov3D_precomp, // 预计算的3D协方差矩阵 const float* colors_precomp, // 预计算的颜色数组 const float* viewmatrix, // 视图矩阵 const float* projmatrix, // 投影矩阵 const glm::vec3* cam_pos, // 相机位置 const int W, int H, // 图像宽度和高度 const float tan_fovx, float tan_fovy, // tan(fov_x)和tan(fov_y) const float focal_x, float focal_y, // 焦距 int* radii, // 半径数组 float2* points_xy_image, // 点在图像上的坐标数组 float* depths, // 深度数组 float* cov3Ds, // 3D协方差矩阵数组 float* rgb, // RGB颜色数组 float4* conic_opacity, // 圆锥参数和透明度数组 const dim3 grid, // 网格大小 uint32_t* tiles_touched, // 被触及的图块数数组 bool prefiltered) // 是否进行预过滤的标志 { auto idx = cg::this_grid().thread_rank(); if (idx >= P) return; // 初始化半径和触及的图块数为0。如果这些不被改变, // 那么这个高斯将不会进一步处理。 radii[idx] = 0; tiles_touched[idx] = 0; // 执行近裁剪,如果超出视锥体外,则退出。 float3 p_view; if (!in_frustum(idx, orig_points, viewmatrix, projmatrix, prefiltered, p_view)) return; // 将点通过投影变换到视图空间 float3 p_orig = { orig_points[3 * idx], orig_points[3 * idx + 1], orig_points[3 * idx + 2] }; float4 p_hom = transformPoint4x4(p_orig, projmatrix); float p_w = 1.0f / (p_hom.w + 0.0000001f); // 避免除零错误 float3 p_proj = { p_hom.x * p_w, p_hom.y * p_w, p_hom.z * p_w }; // 如果预计算的3D协方差矩阵存在,则使用它;否则根据缩放和旋转参数计算。 const float* cov3D; if (cov3D_precomp != nullptr) { cov3D = cov3D_precomp + idx * 6; } else { computeCov3D(scales[idx], scale_modifier, rotations[idx], cov3Ds + idx * 6); cov3D = cov3Ds + idx * 6; } // 计算2D屏幕空间协方差矩阵 float3 cov = computeCov2D(p_orig, focal_x, focal_y, tan_fovx, tan_fovy, cov3D, viewmatrix); // 计算协方差矩阵的逆(EWA算法) float det = (cov.x * cov.z - cov.y * cov.y); if (det == 0.0f) return; float det_inv = 1.f / det; float3 conic = { cov.z * det_inv, -cov.y * det_inv, cov.x * det_inv }; // 计算在屏幕空间中的扩展范围(通过计算2D协方差矩阵的特征值)。使用扩展范围计算 // 与此高斯重叠的屏幕空间矩形的边界框。如果矩形覆盖0个图块,则退出。 float mid = 0.5f * (cov.x + cov.z); float lambda1 = mid + sqrt(max(0.1f, mid * mid - det)); float lambda2 = mid - sqrt(max(0.1f, mid * mid - det)); float my_radius = ceil(3.f * sqrt(max(lambda1, lambda2))); float2 point_image = { ndc2Pix(p_proj.x, W), ndc2Pix(p_proj.y, H) }; uint2 rect_min, rect_max; getRect(point_image, my_radius, rect_min, rect_max, grid); if ((rect_max.x - rect_min.x) * (rect_max.y - rect_min.y) == 0) return; // 如果颜色已经预计算,则使用它们;否则将球谐系数转换为RGB颜色。 if (colors_precomp == nullptr) { glm::vec3 result = computeColorFromSH(idx, D, M, (glm::vec3*)orig_points, *cam_pos, shs, clamped); rgb[idx * C + 0] = result.x; rgb[idx * C + 1] = result.y; rgb[idx * C + 2] = result.z; } // 存储一些有用的下一步的辅助数据。 depths[idx] = p_view.z; radii[idx] = my_radius; points_xy_image[idx] = point_image; // 将逆2D协方差和透明度整齐地打包到一个float4中 conic_opacity[idx] = { conic.x, conic.y, conic.z, opacities[idx] }; tiles_touched[idx] = (rect_max.y - rect_min.y) * (rect_max.x - rect_min.x); } 执行每个线程的渲染
// 主光栅化方法。每个块协作处理一个图块,每个线程处理一个像素。在数据获取和光栅化之间交替进行。 template <uint32_t CHANNELS> __global__ void __launch_bounds__(BLOCK_X * BLOCK_Y) renderCUDA( const uint2* __restrict__ ranges, // 点范围数组 const uint32_t* __restrict__ point_list, // 点列表 int W, int H, // 图像宽度和高度 const float2* __restrict__ points_xy_image, // 点在图像上的坐标数组 const float* __restrict__ features, // 特征数组 const float4* __restrict__ conic_opacity, // 圆锥参数和透明度数组 float* __restrict__ final_T, // 最终T数组 uint32_t* __restrict__ n_contrib, // 贡献数量数组 const float* __restrict__ bg_color, // 背景颜色数组 float* __restrict__ out_color) // 输出颜色数组 { // 识别当前图块及其关联的最小/最大像素范围。 auto block = cg::this_thread_block(); uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X; uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y }; uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) }; uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y }; uint32_t pix_id = W * pix.y + pix.x; float2 pixf = { (float)pix.x, (float)pix.y }; // 检查此线程是否与有效像素关联或位于外部。 bool inside = pix.x < W && pix.y < H; // 完成的线程可以帮助获取数据,但不进行光栅化。 bool done = !inside; // 加载要处理的ID范围,以位排序列表形式。 uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x]; const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE); int toDo = range.y - range.x; // 分配存储批处理收集数据的空间。 __shared__ int collected_id[BLOCK_SIZE]; __shared__ float2 collected_xy[BLOCK_SIZE]; __shared__ float4 collected_conic_opacity[BLOCK_SIZE]; // 初始化辅助变量 float T = 1.0f; uint32_t contributor = 0; uint32_t last_contributor = 0; float C[CHANNELS] = { 0 }; // 迭代处理批次,直到所有处理完成或范围完成。 for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE) { // 如果整个块都标记为完成光栅化,则结束。 int num_done = __syncthreads_count(done); if (num_done == BLOCK_SIZE) break; // 从全局内存中共同获取每个高斯数据到共享内存中 int progress = i * BLOCK_SIZE + block.thread_rank(); if (range.x + progress < range.y) { int coll_id = point_list[range.x + progress]; collected_id[block.thread_rank()] = coll_id; collected_xy[block.thread_rank()] = points_xy_image[coll_id]; collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id]; } block.sync(); // 迭代处理当前批次中的数据 for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++) { // 跟踪当前范围内的位置 contributor++; // 使用圆锥矩阵进行重采样(参见“Surface Splatting” by Zwicker et al., 2001) float2 xy = collected_xy[j]; float2 d = { xy.x - pixf.x, xy.y - pixf.y }; float4 con_o = collected_conic_opacity[j]; float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y; if (power > 0.0f) continue; // 从3dgs论文中的公式(2)中获得alpha。 // 通过高斯透明度及其从均值指数衰减获得。 // 避免数值不稳定性(参见论文附录)。 float alpha = min(0.99f, con_o.w * exp(power)); if (alpha < 1.0f / 255.0f) continue; float test_T = T * (1 - alpha); if (test_T < 0.0001f) { done = true; continue; } // 从3dgs论文中的公式(3)中计算出颜色贡献。 for (int ch = 0; ch < CHANNELS; ch++) C[ch] += features[collected_id[j] * CHANNELS + ch] * alpha * T; T = test_T; // 跟踪最后一个范围条目,以更新此像素。 last_contributor = contributor; } } // 所有处理有效像素的线程将最终渲染数据写入帧和辅助缓冲区。 if (inside) { final_T[pix_id] = T; n_contrib[pix_id] = last_contributor; for (int ch = 0; ch < CHANNELS; ch++) out_color[ch * H * W + pix_id] = C[ch] + T * bg_color[ch]; } } 后面将对象实例化的部分就不细说了,毕竟参数注释就在前文。
3dgs代码反向传播部分
再来聊一下反向传播的代码,和前向传播类似,只是它们要根据损失对对应的参数求偏导,具体细节我在注释里写的比较详细。
球谐函数的建立
submodules\diff-gaussian-rasterization\cuda_rasterizer\backward.cu line 18 // Backward pass for conversion of spherical harmonics to RGB for // each Gaussian. // 反向传播:从球谐函数到RGB颜色的转换,针对每个高斯函数。 __device__ void computeColorFromSH(int idx, int deg, int max_coeffs, const glm::vec3* means, glm::vec3 campos, const float* shs, const bool* clamped, const glm::vec3* dL_dcolor, glm::vec3* dL_dmeans, glm::vec3* dL_dshs) { // 计算中间值,与前向传播过程一样 glm::vec3 pos = means[idx]; // 高斯均值位置 glm::vec3 dir_orig = pos - campos; // 到视点的方向向量 glm::vec3 dir = dir_orig / glm::length(dir_orig); // 规范化后的方向向量 glm::vec3* sh = ((glm::vec3*)shs) + idx * max_coeffs; // 球谐函数系数数组 // 使用PyTorch的规则进行截断:如果应用了截断,梯度为0。 // dL_dcolor[idx]是对损失函数关于RGB颜色的梯度向量,包括了对红色、绿色和蓝色分量的偏导。 glm::vec3 dL_dRGB = dL_dcolor[idx]; /* clamped[3 * idx + 0], clamped[3 * idx + 1], clamped[3 * idx + 2] 分别表示对应颜色分量(红、绿、蓝)是否应用了截断。 如果 clamped 数组中对应位置的值为 true,则对应的梯度分量乘以 0,即该分量的梯度为 0。 如果 clamped 数组中对应位置的值为 false,则对应的梯度分量乘以 1,即保留原始的梯度值。*/ dL_dRGB.x *= clamped[3 * idx + 0] ? 0 : 1; dL_dRGB.y *= clamped[3 * idx + 1] ? 0 : 1; dL_dRGB.z *= clamped[3 * idx + 2] ? 0 : 1; // dRGBdx, dRGBdy, dRGBdz 分别初始化为 (0, 0, 0),用于累积后续计算中的方向导数(即对位置向量 dir 的导数)。 glm::vec3 dRGBdx(0, 0, 0); glm::vec3 dRGBdy(0, 0, 0); glm::vec3 dRGBdz(0, 0, 0); // x, y, z 是视线方向向量 dir 的分量,通过 dir.x, dir.y, dir.z 初始化。 float x = dir.x; float y = dir.y; float z = dir.z; // 为此高斯函数写入球谐函数梯度的目标位置 glm::vec3* dL_dsh = dL_dshs + idx * max_coeffs; // 没有特殊技巧,只是高中水平的微积分。 // 这里求偏导用了链式法则 float dRGBdsh0 = SH_C0; dL_dsh[0] = dRGBdsh0 * dL_dRGB; if (deg > 0) { float dRGBdsh1 = -SH_C1 * y; float dRGBdsh2 = SH_C1 * z; float dRGBdsh3 = -SH_C1 * x; dL_dsh[1] = dRGBdsh1 * dL_dRGB; dL_dsh[2] = dRGBdsh2 * dL_dRGB; dL_dsh[3] = dRGBdsh3 * dL_dRGB; dRGBdx = -SH_C1 * sh[3]; dRGBdy = -SH_C1 * sh[1]; dRGBdz = SH_C1 * sh[2]; if (deg > 1) { float xx = x * x, yy = y * y, zz = z * z; float xy = x * y, yz = y * z, xz = x * z; float dRGBdsh4 = SH_C2[0] * xy; float dRGBdsh5 = SH_C2[1] * yz; float dRGBdsh6 = SH_C2[2] * (2.f * zz - xx - yy); float dRGBdsh7 = SH_C2[3] * xz; float dRGBdsh8 = SH_C2[4] * (xx - yy); dL_dsh[4] = dRGBdsh4 * dL_dRGB; dL_dsh[5] = dRGBdsh5 * dL_dRGB; dL_dsh[6] = dRGBdsh6 * dL_dRGB; dL_dsh[7] = dRGBdsh7 * dL_dRGB; dL_dsh[8] = dRGBdsh8 * dL_dRGB; dRGBdx += SH_C2[0] * y * sh[4] + SH_C2[2] * 2.f * -x * sh[6] + SH_C2[3] * z * sh[7] + SH_C2[4] * 2.f * x * sh[8]; dRGBdy += SH_C2[0] * x * sh[4] + SH_C2[1] * z * sh[5] + SH_C2[2] * 2.f * -y * sh[6] + SH_C2[4] * 2.f * -y * sh[8]; dRGBdz += SH_C2[1] * y * sh[5] + SH_C2[2] * 2.f * 2.f * z * sh[6] + SH_C2[3] * x * sh[7]; if (deg > 2) { float dRGBdsh9 = SH_C3[0] * y * (3.f * xx - yy); float dRGBdsh10 = SH_C3[1] * xy * z; float dRGBdsh11 = SH_C3[2] * y * (4.f * zz - xx - yy); float dRGBdsh12 = SH_C3[3] * z * (2.f * zz - 3.f * xx - 3.f * yy); float dRGBdsh13 = SH_C3[4] * x * (4.f * zz - xx - yy); float dRGBdsh14 = SH_C3[5] * z * (xx - yy); float dRGBdsh15 = SH_C3[6] * x * (xx - 3.f * yy); dL_dsh[9] = dRGBdsh9 * dL_dRGB; dL_dsh[10] = dRGBdsh10 * dL_dRGB; dL_dsh[11] = dRGBdsh11 * dL_dRGB; dL_dsh[12] = dRGBdsh12 * dL_dRGB; dL_dsh[13] = dRGBdsh13 * dL_dRGB; dL_dsh[14] = dRGBdsh14 * dL_dRGB; dL_dsh[15] = dRGBdsh15 * dL_dRGB; dRGBdx += ( SH_C3[0] * sh[9] * 3.f * 2.f * xy + SH_C3[1] * sh[10] * yz + SH_C3[2] * sh[11] * -2.f * xy + SH_C3[3] * sh[12] * -3.f * 2.f * xz + SH_C3[4] * sh[13] * (-3.f * xx + 4.f * zz - yy) + SH_C3[5] * sh[14] * 2.f * xz + SH_C3[6] * sh[15] * 3.f * (xx - yy)); dRGBdy += ( SH_C3[0] * sh[9] * 3.f * (xx - yy) + SH_C3[1] * sh[10] * xz + SH_C3[2] * sh[11] * (-3.f * yy + 4.f * zz - xx) + SH_C3[3] * sh[12] * -3.f * 2.f * yz + SH_C3[4] * sh[13] * -2.f * xy + SH_C3[5] * sh[14] * -2.f * yz + SH_C3[6] * sh[15] * -3.f * 2.f * xy); dRGBdz += ( SH_C3[1] * sh[10] * xy + SH_C3[2] * sh[11] * 4.f * 2.f * yz + SH_C3[3] * sh[12] * 3.f * (2.f * zz - xx - yy) + SH_C3[4] * sh[13] * 4.f * 2.f * xz + SH_C3[5] * sh[14] * (xx - yy)); } } } // 视点方向是计算的输入。视点方向受高斯均值影响,所以球谐函数梯度必须传播回3D位置。 glm::vec3 dL_ddir(glm::dot(dRGBdx, dL_dRGB), glm::dot(dRGBdy, dL_dRGB), glm::dot(dRGBdz, dL_dRGB)); // 考虑方向规范化 float3 dL_dmean = dnormvdv(float3{ dir_orig.x, dir_orig.y, dir_orig.z }, float3{ dL_ddir.x, dL_ddir.y, dL_ddir.z }); // 损失相对于高斯均值的梯度,但仅对因均值影响视角相关颜色部分感兴趣。 // 其他均值梯度在下面的方法中累积。 dL_dmeans[idx] += glm::vec3(dL_dmean.x, dL_dmean.y, dL_dmean.z); } 单独解释一下球谐函数求偏导的细节:
SH_C0 和 dL_dsh[0]:
dRGBdsh0 = SH_C0:对球谐系数 0 阶(常数项)的梯度。
dL_dsh[0] = dRGBdsh0 * dL_dRGB:将梯度乘以损失函数关于颜色梯度的梯度,用于更新球谐系数的梯度。
deg > 0 时的部分:
在球谐系数的一阶(deg > 0)中,分别计算了对应球谐系数的梯度(dRGBdsh1、dRGBdsh2、dRGBdsh3)。
dL_dsh[1]、dL_dsh[2]、dL_dsh[3] 分别表示对球谐系数的一阶梯度更新。
dRGBdx、dRGBdy、dRGBdz 表示对位置坐标的梯度更新,这些梯度来自于对 x、y、z 方向的偏导数计算。
deg > 1 时的部分:
在球谐系数的二阶(deg > 1)中,计算了更高阶次的球谐系数梯度(dRGBdsh4 到 dRGBdsh8)。
dL_dsh[4] 到 dL_dsh[8] 表示对应球谐系数的二阶梯度更新。
dRGBdx、dRGBdy、dRGBdz 更新加上了更高阶次球谐系数的影响。
deg > 2 时的部分:
在球谐系数的三阶(deg > 2)中,计算了更高阶次的球谐系数梯度(dRGBdsh9 到 dRGBdsh15)。
dL_dsh[9] 到 dL_dsh[15] 表示对应球谐系数的三阶梯度更新。
dRGBdx、dRGBdy、dRGBdz 更新加上了更高阶次球谐系数的影响。
在最后用点乘的方式(glm::vec3 dL_ddir(glm::dot(dRGBdx, dL_dRGB), glm::dot(dRGBdy, dL_dRGB), glm::dot(dRGBdz, dL_dRGB));和链式法则求出了对位置的偏导。
EWA投影来消除误差
submodules\diff-gaussian-rasterization\cuda_rasterizer\backward.cu line 141 // Backward version of INVERSE 2D covariance matrix computation // (due to length launched as separate kernel before other // backward steps contained in preprocess) // 用于计算2D协方差矩阵及相关参数梯度的CUDA核函数 __global__ void computeCov2DCUDA(int P, const float3* means, // 高斯分布的均值数组 const int* radii, // 半径数组(用于检查高斯分布是否有效) const float* cov3Ds, // 3D协方差矩阵数组(扁平化处理) const float h_x, float h_y, // x和y方向的缩放因子 const float tan_fovx, float tan_fovy, // x和y方向的视场角切线值 const float* view_matrix, // 视图变换矩阵 const float* dL_dconics, // 损失相对于二次曲线参数的梯度 float3* dL_dmeans, // 输出:损失相对于均值的梯度 float* dL_dcov) // 输出:损失相对于协方差矩阵的梯度 { auto idx = cg::this_grid().thread_rank(); // 获取CUDA网格中的线程索引 if (idx >= P || !(radii[idx] > 0)) // 确保线程索引在有效范围内且半径为正 return; // 读取当前高斯分布的3D协方差矩阵位置 const float* cov3D = cov3Ds + 6 * idx; // 获取梯度,重新计算2D协方差矩阵和相关的中间前向计算结果 float3 mean = means[idx]; // 获取高斯分布的均值 float3 dL_dconic = { dL_dconics[4 * idx], dL_dconics[4 * idx + 1], dL_dconics[4 * idx + 3] }; // 获取损失相对于二次曲线矩阵的梯度 float3 t = transformPoint4x3(mean, view_matrix); // 使用视图矩阵变换均值 // 将变换后的坐标限制在视场角范围内 const float limx = 1.3f * tan_fovx; const float limy = 1.3f * tan_fovy; const float txtz = t.x / t.z; const float tytz = t.y / t.z; t.x = min(limx, max(-limx, txtz)) * t.z; t.y = min(limy, max(-limy, tytz)) * t.z; // 根据限制确定梯度乘数 const float x_grad_mul = (txtz < -limx || txtz > limx) ? 0 : 1; const float y_grad_mul = (tytz < -limy || tytz > limy) ? 0 : 1; // 变换的雅可比矩阵 glm::mat3 J = glm::mat3(h_x / t.z, 0.0f, -(h_x * t.x) / (t.z * t.z), 0.0f, h_y / t.z, -(h_y * t.y) / (t.z * t.z), 0, 0, 0); // 用于变换的视图矩阵子集 glm::mat3 W = glm::mat3(view_matrix[0], view_matrix[4], view_matrix[8], view_matrix[1], view_matrix[5], view_matrix[9], view_matrix[2], view_matrix[6], view_matrix[10]); // 3D空间中的协方差矩阵 glm::mat3 Vrk = glm::mat3(cov3D[0], cov3D[1], cov3D[2], cov3D[1], cov3D[3], cov3D[4], cov3D[2], cov3D[4], cov3D[5]); // 变换矩阵T glm::mat3 T = W * J; // 计算2D协方差矩阵 glm::mat3 cov2D = glm::transpose(T) * glm::transpose(Vrk) * T; // 带修正的2D协方差矩阵条目 float a = cov2D[0][0] += 0.3f; float b = cov2D[0][1]; float c = cov2D[1][1] += 0.3f; // 梯度的分母 float denom = a * c - b * b; float dL_da = 0, dL_db = 0, dL_dc = 0; float denom2inv = 1.0f / ((denom * denom) + 0.0000001f); // 计算损失相对于2D协方差矩阵条目的梯度 if (denom2inv != 0) { dL_da = denom2inv * (-c * c * dL_dconic.x + 2 * b * c * dL_dconic.y + (denom - a * c) * dL_dconic.z); dL_dc = denom2inv * (-a * a * dL_dconic.z + 2 * a * b * dL_dconic.y + (denom - a * c) * dL_dconic.x); dL_db = denom2inv * 2 * (b * c * dL_dconic.x - (denom + 2 * b * b) * dL_dconic.y + a * b * dL_dconic.z); // 损失相对于3D协方差矩阵条目(Vrk)的梯度 dL_dcov[6 * idx + 0] = (T[0][0] * T[0][0] * dL_da + T[0][0] * T[1][0] * dL_db + T[1][0] * T[1][0] * dL_dc); dL_dcov[6 * idx + 3] = (T[0][1] * T[0][1] * dL_da + T[0][1] * T[1][1] * dL_db + T[1][1] * T[1][1] * dL_dc); dL_dcov[6 * idx + 5] = (T[0][2] * T[0][2] * dL_da + T[0][2] * T[1][2] * dL_db + T[1][2] * T[1][2] * dL_dc); // 由于转置(T) * 转置(Vrk) * T,非对角元素有双重梯度 dL_dcov[6 * idx + 1] = 2 * T[0][0] * T[0][1] * dL_da + (T[0][0] * T[1][1] + T[0][1] * T[1][0]) * dL_db + 2 * T[1][0] * T[1][1] * dL_dc; dL_dcov[6 * idx + 2] = 2 * T[0][0] * T[0][2] * dL_da + (T[0][0] * T[1][2] + T[0][2] * T[1][0]) * dL_db + 2 * T[1][0] * T[1][2] * dL_dc; dL_dcov[6 * idx + 4] = 2 * T[0][2] * T[0][1] * dL_da + (T[0][1] * T[1][2] + T[0][2] * T[1][1]) * dL_db + 2 * T[1][1] * T[1][2] * dL_dc; } else { // 如果分母为零,则将梯度设为零 for (int i = 0; i < 6; i++) dL_dcov[6 * idx + i] = 0; } // 损失相对于中间矩阵T的上2x3部分的梯度 float dL_dT00 = 2 * (T[0][0] * Vrk[0][0] + T[0][1] * Vrk[0][1] + T[0][2] * Vrk[0][2]) * dL_da + (T[1][0] * Vrk[0][0] + T[1][1] * Vrk[0][1] + T[1][2] * Vrk[0][2]) * dL_db; float dL_dT01 = 2 * (T[0][0] * Vrk[1][0] + T[0][1] * Vrk[1][1] + T[0][2] * Vrk[1][2]) * dL_da + (T[1][0] * Vrk[1][0] + T[1][1] * Vrk[1][1] + T[1][2] * Vrk[1][2]) * dL_db; float dL_dT02 = 2 * (T[0][0] * Vrk[2][0] + T[0][1] * Vrk[2][1] + T[0][2] * Vrk[2][2]) * dL_da + (T[1][0] * Vrk[2][0] + T[1][1] * Vrk[2][1] + T[1][2] * Vrk[2][2]) * dL_db; float dL_dT10 = 2 * (T[1][0] * Vrk[0][0] + T[1][1] * Vrk[0][1] + T[1][2] * Vrk[0][2]) * dL_dc + (T[0][0] * Vrk[0][0] + T[0][1] * Vrk[0][1] + T[0][2] * Vrk[0][2]) * dL_db; float dL_dT11 = 2 * (T[1][0] * Vrk[1][0] + T[1][1] * Vrk[1][1] + T[1][2] * Vrk[1][2]) * dL_dc + (T[0][0] * Vrk[1][0] + T[0][1] * Vrk[1][1] + T[0][2] * Vrk[1][2]) * dL_db; float dL_dT12 = 2 * (T[1][0] * Vrk[2][0] + T[1][1] * Vrk[2][1] + T[1][2] * Vrk[2][2]) * dL_dc + (T[0][0] * Vrk[2][0] + T[0][1] * Vrk[2][1] + T[0][2] * Vrk[2][2]) * dL_db; // 将相对于变换矩阵和均值的梯度结合 float3 dL_dt = { x_grad_mul * view_matrix[0] * dL_dT00 + view_matrix[1] * dL_dT01 + view_matrix[2] * dL_dT02, y_grad_mul * view_matrix[4] * dL_dT10 + view_matrix[5] * dL_dT11 + view_matrix[6] * dL_dT12, view_matrix[8] * (dL_dT00 + dL_dT01 + dL_dT02) + view_matrix[9] * (dL_dT10 + dL_dT11 + dL_dT12)}; // 将计算出的梯度分配到输出数组 dL_dmeans[idx] = dL_dt; } 协方差矩阵的构建
submodules\diff-gaussian-rasterization\cuda_rasterizer\backward.cu line 276 // Backward pass for the conversion of scale and rotation to a // 3D covariance matrix for each Gaussian. // 反向传递,用于将比例和旋转转换为每个高斯分布的3D协方差矩阵。 __device__ void computeCov3D(int idx, const glm::vec3 scale, float mod, const glm::vec4 rot, const float* dL_dcov3Ds, glm::vec3* dL_dscales, glm::vec4* dL_drots) { // 重新计算用于3D协方差计算的中间结果。 glm::vec4 q = rot; // 获取旋转四元数 float r = q.x; float x = q.y; float y = q.z; float z = q.w; // 构建旋转矩阵R glm::mat3 R = glm::mat3( 1.f - 2.f * (y * y + z * z), 2.f * (x * y - r * z), 2.f * (x * z + r * y), 2.f * (x * y + r * z), 1.f - 2.f * (x * x + z * z), 2.f * (y * z - r * x), 2.f * (x * z - r * y), 2.f * (y * z + r * x), 1.f - 2.f * (x * x + y * y) ); // 构建缩放矩阵S glm::mat3 S = glm::mat3(1.0f); glm::vec3 s = mod * scale; S[0][0] = s.x; S[1][1] = s.y; S[2][2] = s.z; // 计算矩阵M glm::mat3 M = S * R; // 获取损失相对于3D协方差矩阵的梯度 const float* dL_dcov3D = dL_dcov3Ds + 6 * idx; // 将每个元素的协方差损失梯度转换为矩阵形式 glm::mat3 dL_dSigma = glm::mat3( dL_dcov3D[0], 0.5f * dL_dcov3D[1], 0.5f * dL_dcov3D[2], 0.5f * dL_dcov3D[1], dL_dcov3D[3], 0.5f * dL_dcov3D[4], 0.5f * dL_dcov3D[2], 0.5f * dL_dcov3D[4], dL_dcov3D[5] ); // 计算损失相对于矩阵M的梯度 // dSigma_dM = 2 * M glm::mat3 dL_dM = 2.0f * M * dL_dSigma; glm::mat3 Rt = glm::transpose(R); glm::mat3 dL_dMt = glm::transpose(dL_dM); // 计算损失相对于比例的梯度 glm::vec3* dL_dscale = dL_dscales + idx; dL_dscale->x = glm::dot(Rt[0], dL_dMt[0]); dL_dscale->y = glm::dot(Rt[1], dL_dMt[1]); dL_dscale->z = glm::dot(Rt[2], dL_dMt[2]); dL_dMt[0] *= s.x; dL_dMt[1] *= s.y; dL_dMt[2] *= s.z; // 计算损失相对于归一化四元数的梯度 glm::vec4 dL_dq; dL_dq.x = 2 * z * (dL_dMt[0][1] - dL_dMt[1][0]) + 2 * y * (dL_dMt[2][0] - dL_dMt[0][2]) + 2 * x * (dL_dMt[1][2] - dL_dMt[2][1]); dL_dq.y = 2 * y * (dL_dMt[1][0] + dL_dMt[0][1]) + 2 * z * (dL_dMt[2][0] + dL_dMt[0][2]) + 2 * r * (dL_dMt[1][2] - dL_dMt[2][1]) - 4 * x * (dL_dMt[2][2] + dL_dMt[1][1]); dL_dq.z = 2 * x * (dL_dMt[1][0] + dL_dMt[0][1]) + 2 * r * (dL_dMt[2][0] - dL_dMt[0][2]) + 2 * z * (dL_dMt[1][2] + dL_dMt[2][1]) - 4 * y * (dL_dMt[2][2] + dL_dMt[0][0]); dL_dq.w = 2 * r * (dL_dMt[0][1] - dL_dMt[1][0]) + 2 * x * (dL_dMt[2][0] + dL_dMt[0][2]) + 2 * y * (dL_dMt[1][2] + dL_dMt[2][1]) - 4 * z * (dL_dMt[1][1] + dL_dMt[0][0]); // 计算损失相对于未归一化四元数的梯度 float4* dL_drot = (float4*)(dL_drots + idx); *dL_drot = float4{ dL_dq.x, dL_dq.y, dL_dq.z, dL_dq.w }; } 数据预处理
submodules\diff-gaussian-rasterization\cuda_rasterizer\backward.cu line 343 // Backward pass of the preprocessing steps, except // for the covariance computation and inversion // (those are handled by a previous kernel call) // 反向传播预处理步骤,除了协方差计算和反演 // (这些由先前的内核调用处理) template<int C> __global__ void preprocessCUDA( int P, int D, int M, const float3* means, // 中心点 const int* radii, // 半径 const float* shs, // 球谐函数系数 const bool* clamped, // 是否被限制 const glm::vec3* scales, // 缩放因子 const glm::vec4* rotations, // 旋转四元数 const float scale_modifier, // 缩放修正系数 const float* proj, // 投影矩阵 const glm::vec3* campos, // 相机位置 const float3* dL_dmean2D, // 2D均值损失梯度 glm::vec3* dL_dmeans, // 3D均值损失梯度 float* dL_dcolor, // 颜色损失梯度 float* dL_dcov3D, // 3D协方差损失梯度 float* dL_dsh, // 球谐函数损失梯度 glm::vec3* dL_dscale, // 缩放损失梯度 glm::vec4* dL_drot) // 旋转损失梯度 { auto idx = cg::this_grid().thread_rank(); if (idx >= P || !(radii[idx] > 0)) return; float3 m = means[idx]; // 处理屏幕空间点的梯度 float4 m_hom = transformPoint4x4(m, proj); float m_w = 1.0f / (m_hom.w + 0.0000001f); // 由于渲染过程中的2D均值梯度导致的3D均值损失梯度 glm::vec3 dL_dmean; float mul1 = (proj[0] * m.x + proj[4] * m.y + proj[8] * m.z + proj[12]) * m_w * m_w; float mul2 = (proj[1] * m.x + proj[5] * m.y + proj[9] * m.z + proj[13]) * m_w * m_w; dL_dmean.x = (proj[0] * m_w - proj[3] * mul1) * dL_dmean2D[idx].x + (proj[1] * m_w - proj[3] * mul2) * dL_dmean2D[idx].y; dL_dmean.y = (proj[4] * m_w - proj[7] * mul1) * dL_dmean2D[idx].x + (proj[5] * m_w - proj[7] * mul2) * dL_dmean2D[idx].y; dL_dmean.z = (proj[8] * m_w - proj[11] * mul1) * dL_dmean2D[idx].x + (proj[9] * m_w - proj[11] * mul2) * dL_dmean2D[idx].y; // 这是均值梯度的第二部分。之前的cov2D计算和接下来的SH转换也会影响它。 dL_dmeans[idx] += dL_dmean; // 计算颜色从SHs计算时的梯度更新 if (shs) computeColorFromSH(idx, D, M, (glm::vec3*)means, *campos, shs, clamped, (glm::vec3*)dL_dcolor, (glm::vec3*)dL_dmeans, (glm::vec3*)dL_dsh); // 计算由于从比例/旋转计算协方差而导致的梯度更新 if (scales) computeCov3D(idx, scales[idx], scale_modifier, rotations[idx], dL_dcov3D, dL_dscale, dL_drot); } 执行每个线程的渲染
submodules\diff-gaussian-rasterization\cuda_rasterizer\backward.cu line 398 // 反向渲染过程的CUDA核函数 template <uint32_t C> __global__ void __launch_bounds__(BLOCK_X * BLOCK_Y) renderCUDA( const uint2* __restrict__ ranges, // 每个线程块处理的像素范围 const uint32_t* __restrict__ point_list, // 贡献高斯的点列表 int W, int H, // 图像宽度和高度 const float* __restrict__ bg_color, // 背景颜色 const float2* __restrict__ points_xy_image, // 高斯的像素坐标 const float4* __restrict__ conic_opacity, // 高斯的椎体参数和透明度 const float* __restrict__ colors, // 高斯的颜色 const float* __restrict__ final_Ts, // 最终的T值(所有alpha的乘积) const uint32_t* __restrict__ n_contrib, // 每个像素的贡献高斯数目 const float* __restrict__ dL_dpixels, // 损失函数关于像素颜色的梯度 float3* __restrict__ dL_dmean2D, // 损失函数关于2D均值位置的梯度 float4* __restrict__ dL_dconic2D, // 损失函数关于2D椎体参数的梯度 float* __restrict__ dL_dopacity, // 损失函数关于透明度的梯度 float* __restrict__ dL_dcolors // 损失函数关于颜色的梯度 ) { // 获取当前线程块和线程的信息 auto block = cg::this_thread_block(); const uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X; const uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y }; const uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) }; const uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y }; const uint32_t pix_id = W * pix.y + pix.x; const float2 pixf = { (float)pix.x, (float)pix.y }; const bool inside = pix.x < W && pix.y < H; const uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x]; const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE); bool done = !inside; int toDo = range.y - range.x; // 使用shared memory加载数据,以便在线程块内高效访问 __shared__ int collected_id[BLOCK_SIZE]; __shared__ float2 collected_xy[BLOCK_SIZE]; __shared__ float4 collected_conic_opacity[BLOCK_SIZE]; __shared__ float collected_colors[C * BLOCK_SIZE]; // 在前向传播中,存储了最终的T值,即所有alpha的乘积 const float T_final = inside ? final_Ts[pix_id] : 0; float T = T_final; // 我们从后向前开始,每个像素的最后贡献高斯的ID从前向传播中已知 uint32_t contributor = toDo; const int last_contributor = inside ? n_contrib[pix_id] : 0; // 累积的记录 float accum_rec[C] = { 0 }; float dL_dpixel[C]; if (inside) for (int i = 0; i < C; i++) dL_dpixel[i] = dL_dpixels[i * H * W + pix_id]; float last_alpha = 0; float last_color[C] = { 0 }; // 像素坐标对于归一化屏幕空间视口坐标(-1到1)的梯度 const float ddelx_dx = 0.5 * W; const float ddely_dy = 0.5 * H; // 遍历所有高斯 for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE) { // 加载数据到shared memory,从后向前加载 block.sync(); const int progress = i * BLOCK_SIZE + block.thread_rank(); if (range.x + progress < range.y) { const int coll_id = point_list[range.y - progress - 1]; collected_id[block.thread_rank()] = coll_id; collected_xy[block.thread_rank()] = points_xy_image[coll_id]; collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id]; for (int i = 0; i < C; i++) collected_colors[i * BLOCK_SIZE + block.thread_rank()] = colors[coll_id * C + i]; } block.sync(); // 遍历每个高斯 for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++) { // 跟踪当前高斯的ID。如果此高斯在像素的最后贡献者之前,则跳过。 contributor--; if (contributor >= last_contributor) continue; // 计算混合值,与前向传播相同 const float2 xy = collected_xy[j]; const float2 d = { xy.x - pixf.x, xy.y - pixf.y }; const float4 con_o = collected_conic_opacity[j]; const float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y; if (power > 0.0f) continue; const float G = exp(power); const float alpha = min(0.99f, con_o.w * G); if (alpha < 1.0f / 255.0f) continue; T = T / (1.f - alpha); const float dchannel_dcolor = alpha * T; // 将梯度传播到每个高斯的颜色,并保持对alpha(高斯/像素对的混合因子)的梯度。 float dL_dalpha = 0.0f; const int global_id = collected_id[j]; for (int ch = 0; ch < C; ch++) { const float c = collected_colors[ch * BLOCK_SIZE + j]; // 更新上次的颜色(用于下一次迭代) accum_rec[ch] = last_alpha * last_color[ch] + (1.f - last_alpha) * accum_rec[ch]; last_color[ch] = c; const float dL_dchannel = dL_dpixel[ch]; dL_dalpha += (c - accum_rec[ch]) * dL_dchannel; // 更新关于高斯颜色的梯度。使用原子操作,因为这个像素只是许多受此高斯影响的像素之一。 atomicAdd(&(dL_dcolors[global_id * C + ch]), dchannel_dcolor * dL_dchannel); } dL_dalpha *= T; // 更新上次的alpha(用于下一次迭代) last_alpha = alpha; // 考虑如果没有东西可以混合,则alpha也会影响添加背景颜色的量 float bg_dot_dpixel = 0; for (int i = 0; i < C; i++) bg_dot_dpixel += bg_color[i] * dL_dpixel[i]; dL_dalpha += (-T_final / (1.f - alpha)) * bg_dot_dpixel; // 有用的临时变量 const float dL_dG = con_o.w * dL_dalpha; const float gdx = G * d.x; const float gdy = G * d.y; const float dG_ddelx = -gdx * con_o.x - gdy * con_o.y; const float dG_ddely = -gdy * con_o.z - gdx * con_o.y; // 更新关于高斯2D均值位置的梯度 atomicAdd(&dL_dmean2D[global_id].x, dL_dG * dG_ddelx * ddelx_dx); atomicAdd(&dL_dmean2D[global_id].y, dL_dG * dG_ddely * ddely_dy); // 更新关于高斯2D椎体参数的梯度(2x2矩阵,对称) atomicAdd(&dL_dconic2D[global_id].x, -0.5f * gdx * d.x * dL_dG); atomicAdd(&dL_dconic2D[global_id].y, -0.5f * gdx * d.y * dL_dG); atomicAdd(&dL_dconic2D[global_id].w, -0.5f * gdy * d.y * dL_dG); // 更新关于高斯透明度的梯度 atomicAdd(&(dL_dopacity[global_id]), G * dL_dalpha); } } } 后面对象的实例化也不说了,很好理解。
