
阅读量:0
bias偏置项(bias term)或者称为截距项(intercept term)
简称b
它其实就是函数的截距,与线性方程y = wx + b中的b的意义是一样的。
在y = wx + b中,b表示函数在y轴上的截距,控制着函数偏离原点的距离,其实在神经网络中的偏置单元也是类似的作用。
因此,神经网络的参数也可以表示为:(w,b)
w表示参数矩阵,b表示偏置项或截距项。
那么,有个疑问,神经网络中,加上bias是如何让网络变得更灵活?
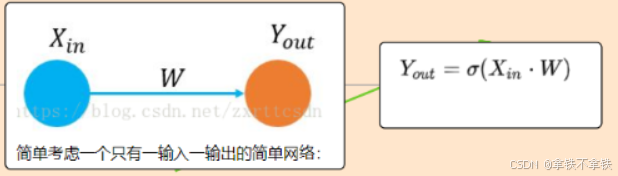

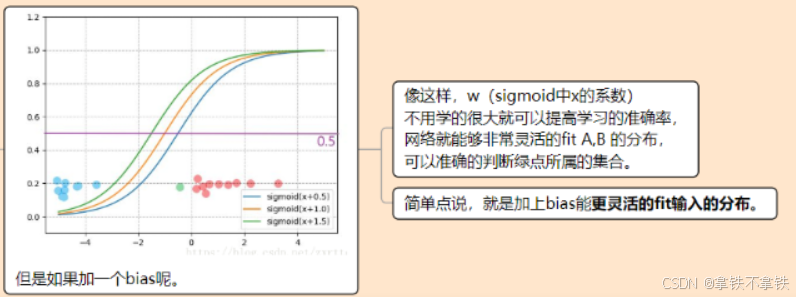
因此,通常网络都会使用bias,但并不是必须,对于网络性能的影响并不是很显著(除非网络太小导致拟合能力太差)。同时在有些场合里,bias的使用也没有意义。比如在batch normalization层之前的层就没必要加,因为会被归一化抵消掉。
实际上,bias相当于多了一个参数。在增加网络少量拟合能力的情况下,bias和其他普通权值相比无论前向还是后向,计算上都要简单,因为只需要一次加法。同时,bias与其它权值的区别在于,其对于输出的影响与输入无关,能够使网络的输出进行整体地调整,算是另一维自由度吧。放在二维上,权值相当于直线地斜率,而bias相当于截距,这二者都是直线参数地一部分,并没有必要区别对待。
卷积之后,如果要接BN操作,最好是不设置偏置,因为不起作用,而且占显卡内存。
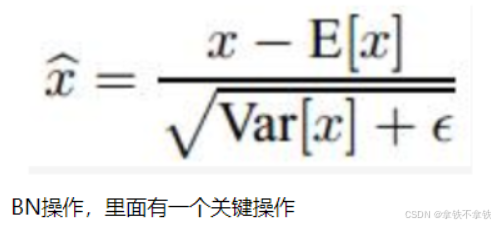
其中x1 = x0 * w0 + b0,而E【x1】= E【x0 * w0】+ b0,所以对于分子而言,加没加偏置,没有影响。
而对于下面分母而言,因为Var是方差操作,所以也没有影响(为什么没影响,回头问问你的数学老师就知道了)
所以,卷积之后,如果要接BN操作。最好是不设置偏置。因为不起作用,而且占显卡内存。
bias的计算方式?
神经网络结构中对偏置单元的计算处理方式有两种。

(1)设置偏置单元=1
并在参数矩阵中设置第0列对应偏置单元的参数,对应的神经网络如下:
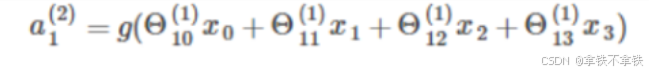
其中,
x0是第一层的偏置单元(设置为1),θ(1)是对应该偏置单元x0的参数,a(2)是第二层的偏置单元,θ(2)是对应的参数。
相当于bias本身值为1,但它连接各个神经元的权值不为1,即整个神经网络只有1个bias,对应有多个不同的权重(权重个数等于hide层和out层神经元的个数)
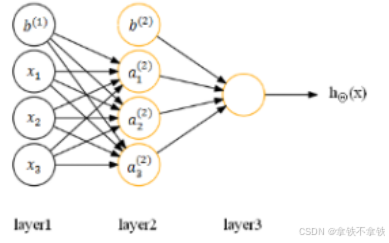
(2)设置偏置单元,不在参数矩阵中设置对应偏置单元的参数,对应的神经网络如下:
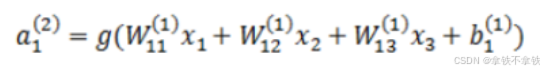
在计算激活值时按照:
其中,
b(1)是w(1)对应的偏置单元向量
b(2)是w(2)对应的偏置单元向量
b(1)是对应a(2)的偏置单元
注意,此时神经网络的参数表示更改为:(W,b)
相当于bias连接各个神经元的所有权重都为1,但bias本身不为1
即......有多个bias,但所有的bias对应的权重都为1,bias的个数等于hide层和out层神经元的个数。
综上,两者的
原理是一致的,只是具体的实现方式不同。
其实在大部分资料和论文中看到的神经网络的参数都是表示为:(W,b),其中W代表weight,b代表bias,包括在UFLDL Tutorial中也是采用(W,b)表示。
