
阅读量:0
使用Hugging Face的Pytorch版本BERT模型进行Fine-tune实现文本分类
Hugging Face确实可以让BERT变得很容易使用,这里介绍一下如何使用Hugging Face的Pytorch版本BERT模型进行Fine-tune实现文本分类。
文章目录
Tokenize
首先,我们需要看看如何对中文预料进行Tokenize的操作。废话不说,这里直接上代码。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese") batch_sentences = [ "我在广州", "今天天气很好", "今天是2022年9月23日", ] encoded_input = tokenizer(batch_sentences, padding="max_length", truncation=True, max_length=20) print(encoded_input) 这里直接使用了,transformers下面的AutoTokenizer,使用bert-base-chinese来编码,输出的结果如下。
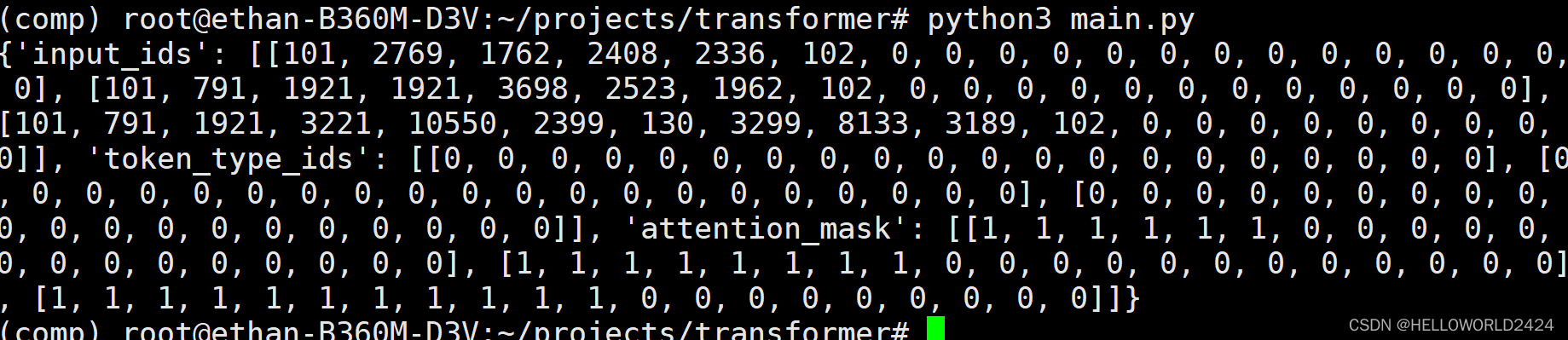
可以看到,这里定义了max_seq_length=20,不足加padding,超过自动截断,头尾加入101,102代表截断。
Decode
decode是Tokenize的反操作,这里对第一句编码进行decode操作。
data = tokenizer.decode(encoded_input["input_ids"][0]) print(data) 得出来在前后添加了开始和结束符号,和PAD

构建并训练模型
我们这里是用了
THUCNews
数据集,打开网页下载THUCNews.zip文件即可,里面一共有10个类别,这里只使用了2类,为了加快训练速度,分别用了体育和娱乐。所以定义model时候,需要指明文本类别数。
AutoModelForSequenceClassification.from_pretrained(“bert-base-chinese”, num_labels=2)
构建和训练模型的代码如下面所示:
import torch from torch.utils.data import DataLoader from tqdm import tqdm from transformers import AutoModelForSequenceClassification, AdamW, AutoTokenizer, get_scheduler from dataset import MyDataset tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese") train_dataset = MyDataset(file_path="./THUCNews", tokenizer=tokenizer) train_dataloader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True) model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2) optimizer = AdamW(model.parameters(), lr=5e-5) num_epochs = 3 num_training_steps = num_epochs * len(train_dataloader) lr_scheduler = get_scheduler( name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps ) device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") model.to(device) progress_bar = tqdm(range(num_training_steps)) model.train() for epoch in range(num_epochs): for segment_ids, labels in train_dataloader: outputs = model(segment_ids.to(device), labels=labels.to(device)) loss = outputs.loss loss.backward() optimizer.step() lr_scheduler.step() optimizer.zero_grad() progress_bar.update(1) #保存模型参数 torch.save(model.state_dict(), "new_classify.pth") #加载模型参数 model.load_state_dict(torch.load("new_classify.pth")) 训练过程如下所示,训练完成会保存模型。
模型评估
import torch import evaluate from torch.utils.data import DataLoader from transformers import AutoModelForSequenceClassification, AutoTokenizer from dataset import MyDataset # 载入模型 model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2) model.load_state_dict(torch.load("new_classify.pth")) # 准备测试集 tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese") eval_dataset = MyDataset(file_path="./THUCNews_test", tokenizer=tokenizer) eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=8, shuffle=True, drop_last=True) device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") metric = evaluate.load("accuracy") model.to(device) model.eval() for segment_ids, labels in eval_dataloader: with torch.no_grad(): outputs = model(segment_ids.to(device), labels=labels.to(device)) logits = outputs.logits predictions = torch.argmax(logits, dim=-1) metric.add_batch(predictions=predictions.cpu().numpy(), references=labels.cpu().numpy()) result = metric.compute() print(result) 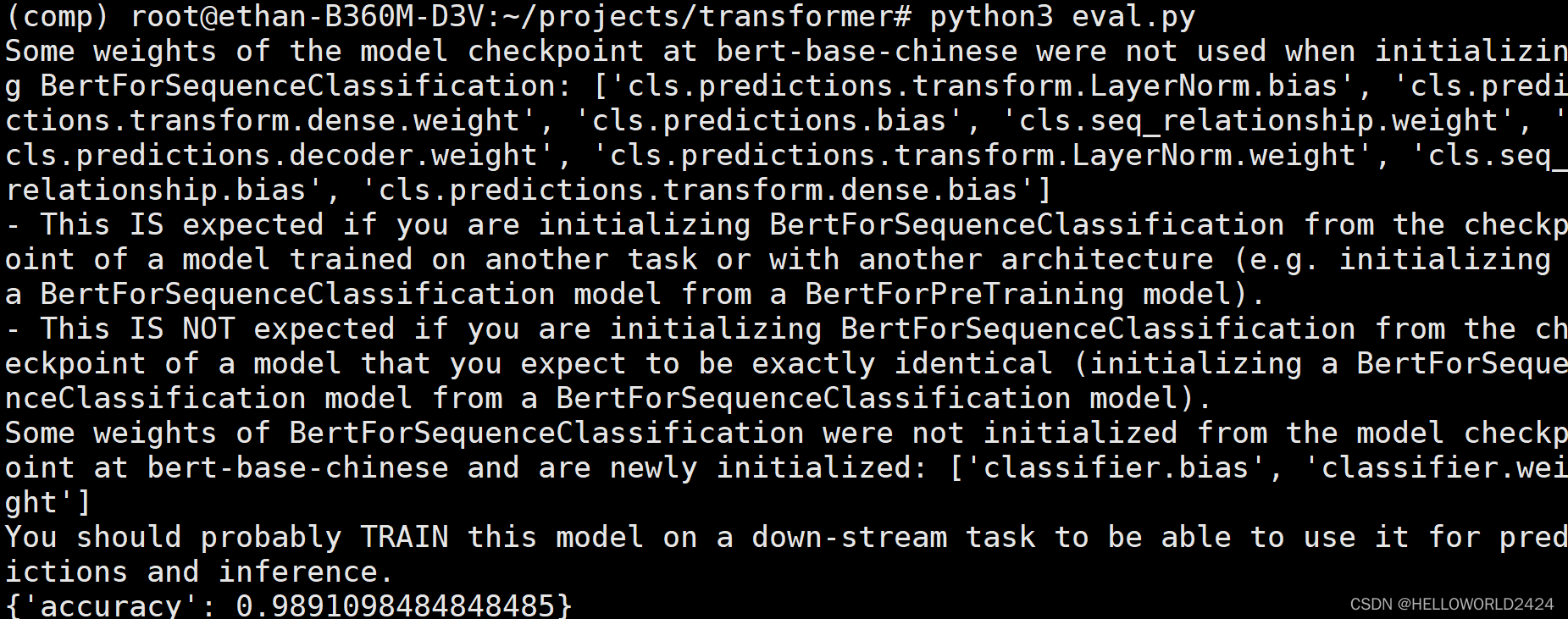
这里的预测准确率为98.9%左右,BERT模型还是YYDS的。
