
阅读量:0
目录
进程优先级
权限是为了解决能不能享受资源的问题,优先级则是为了解决享受资源的顺序的问题。
进程要访问某种资源,就需要用排队的方式,确定享受资源的先后顺序。因为资源是少数,进程是多数。要想和谐的将这些进程都有序的运行,就必须通过排队的方式。
在Linux中,进程优先级字段是进程信息中的PRI字段。
ps -al #查看当前进程 ps -l #查看当前进程
Linux中进程的优先级本质就是一个整型变量,默认优先级是80。
进程优先级是可以被修改的,Linux进程优先级的范围是[60,99]。
Linux进程优先级本质就是数字,数字越小,优先级越高。
Linux修改进程优先级是通过NI值间接修改的。
修改进程优先级方法:
1、打开任务管理器
top #打开任务管理器2、输入r和进程pid
3、设置NI值
最终优先级=初始优先级(始终值80)+NI值
用户只能通过修改NI值间接修改进程优先级。
每次输入的NI值都是被覆盖的。
初始优先级始终是80。
NI值不属于优先级数据,是进程优先级的修正数据。
NI值的大小范围为[-20,19]
如果设置新的NI值超过了系统规定范围,就按照极值来确定。比如NI值输入-100,就被系统默认为-20。
Linux为什么要规定NI值的范围从而使用户间接修改进程优先级呢?
原因是为了限制多人使用资源,从而导致的CPU调度不平衡,优先级高的会先得到资源,导致常规进程很难得到资源所引发进程饥饿问题。
所以,任何分时(实时操作系统)的操作系统,在调度上都较为公平的调度。就是为了解决进程饥饿问题。
进程切换
前期知识补充
现代操作系统大致分为
1.分时操作系统:基于时间片轮转处理进程(由调度器完成,调度器基于时间片、优先级轮转执行),CPU公平调度,进程优先级差距不明显。
2.实时操作系统:当前进程执行完成之后再执行下一个,所有的进程都按照顺序排队执行,允许进程修改优先级插队执行。
我们日常计算机操作系统一般都采用分时操作系统。
竞争性:进程之间通过优先级竞争资源享用顺序。
独立性:多个进程运行时进程之间相互独立,互不干扰。
并行性:多个进程在多个CPU上同时运行,这多个进程之间的关系即为并行。
并发性:多个进程在同一个CPU上运行,由于受时间片、进程优先级发生进程轮转,加上CPU处理很快,所以,我们感知多个进程是同时推进执行的,这多个进程之间的关系称为并发。
注意:并行中的多个CPU不是多核CPU,多核CPU还是一个CPU,只是好几个运算器+一个控制器,可以同时处理不同分支的代码和数据。
CPU周围有很多寄存器,这些寄存器各司其职完成CPU执行这个进程时数据的保存工作。
来帮助CPU更好的执行接下来的工作。
进程切换
CPU调度执行进程时,操作系统会为其维护一个运行队列,当一个进程被CPU调度执行时,会将这个进程对应的代码和数据执行处理,处理的一些临时变量等数据保存在对应的寄存器中,eip寄存器中保存下一次执行的代码的地址(也就是PC指针)。放到寄存器中的处理数据都属于通用数据信息,属于进程特有的数据被CPU处理之后会保存在自己进程的PCB中(因为进程具有独立性)。当这个进程的时间片到了之后,CPU就会将处理这个进程所产生的数据信息拷贝到该进程的PCB中,等到下次再次执行到这个进程时,这个进程先将上次的数据信息在CPU寄存器中拷贝回来,这个过程叫做恢复,继续接着上次执行的位置继续执行(这个是eip寄存器保证的)。
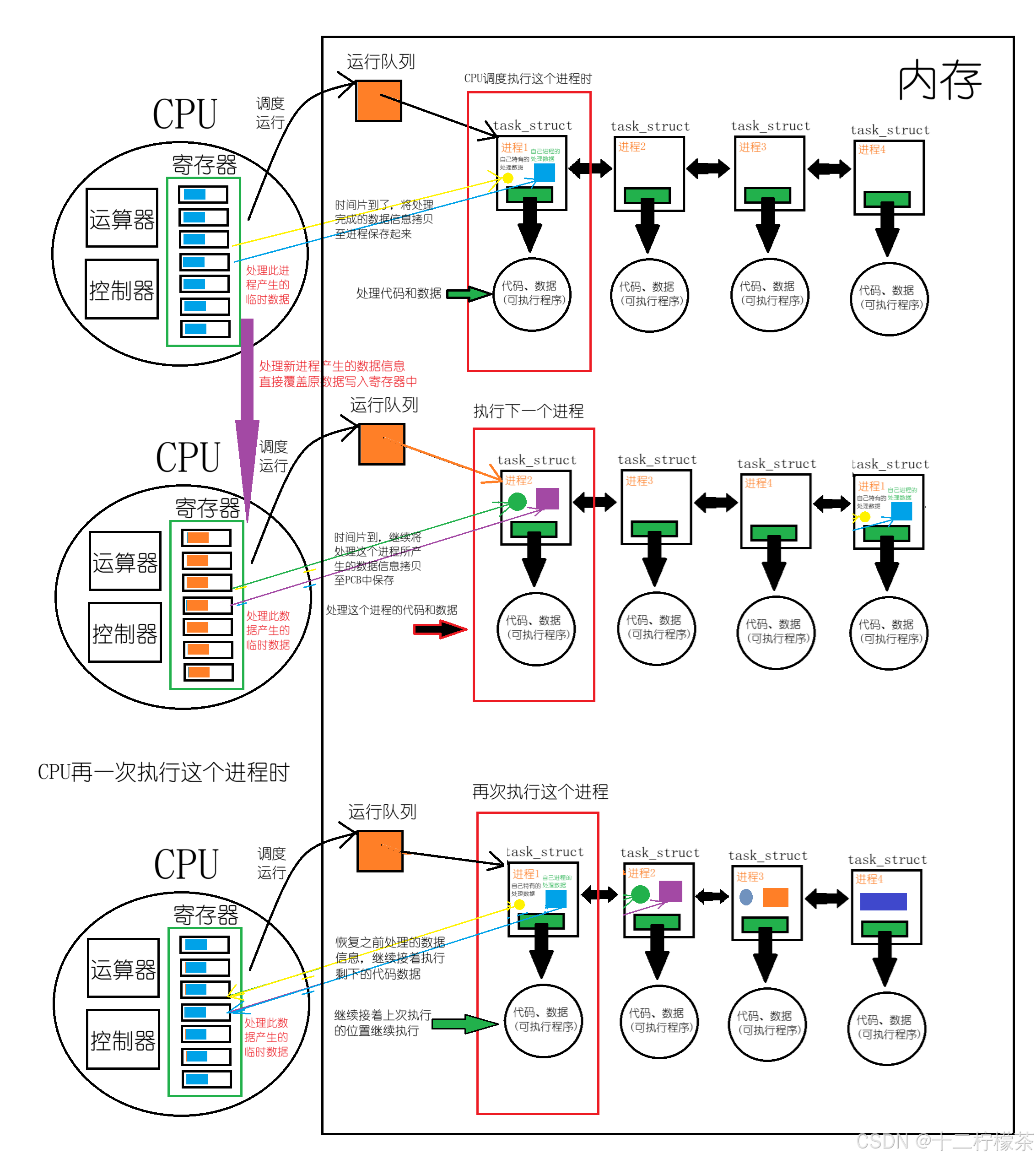
进程在运行的过程中,要产生大量的数据,放在CPU寄存器中。
CPU内部的所有临时数据,我们叫做进程的硬件上下文数据。
硬件上下文数据让我们的进程PCB进行拷贝称为保护上下文数据。
当进程被调度的时候,进程被放到CPU上开始运行,将曾经保存的硬件上下文数据进行恢复。
所有的保存都是为了最终的恢复。
所有的恢复,都是为了继续上次的运行位置继续运行。
CPU内的寄存器只有一套,每个进程在切换之前就必须将自己在调度过程中CPU处理的上下文数据保存至自己的PCB中,等到再次调度这个进程时恢复,接着上次处理位置继续处理。
虽然寄存器数据放在了一个共享的CPU设备里面,但是所有的数据,其实都是被进程私有的,也就是说,只有进程自己才可以访问这些数据。
所以,寄存器内部保存的数据,可以有多套。
进程调度
进程调度算法要考虑优先级、进程饥饿、效率问题。
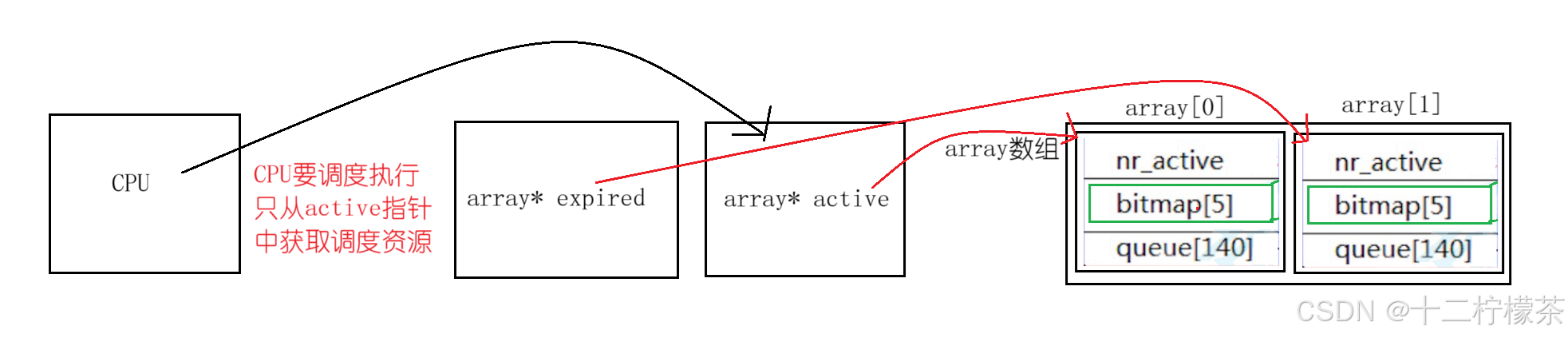
操作系统在运行队列中维护了一个array结构体数组。通过array结构体数组完成对进程的调度工作,并且设置了两个指针,active指向array[0],expired指针指向array[1],CPU要调度进程只从active中拿数据,通过active指针访问array[0]的调度任务数据。当执行完成active指针指向的调度数据时,交换指针active、expired指针内容,此时,CPU就可以继续调度执行另一个调度数据了。
在CPU处理active指针指向的调度数据时,此时由时间片轮转的进程和新创建的进程进入expired指针所指向的数组中,由此,就可以将先一段时间创建的进程率先执行,后一段时间的进程延后执行。并且同一时间段的进程按照优先级先后顺序执行。
下面研究一下array数组如何管理进程调度
array数组中每个元素都是一个结构体,nr_active表示当前活跃进程个数,bitmap作为后续检测,这个之后再谈,queue数组每个元素位置记录tast_struct指针。

queue数组为进程指针数组,里面的[100,139]元素记录着对应进程地址。根据进程优先级[60,99]映射到queue数组中。比如,进程优先级为60的就映射到queue数组元素下标为100处链接。
bitmap数组通过哈希映射,每个bit位都映射queue数组中PCB指针是否为NULL,0表示该位置指针为NULL,1表示该位置指针为非NULL,可以调度执行,能够更加便捷的寻找出当前还有那个优先级的进程没有被执行。如果没有bitmap数组,就要去遍历queue数组,会降低效率。
下面是整体的过程。
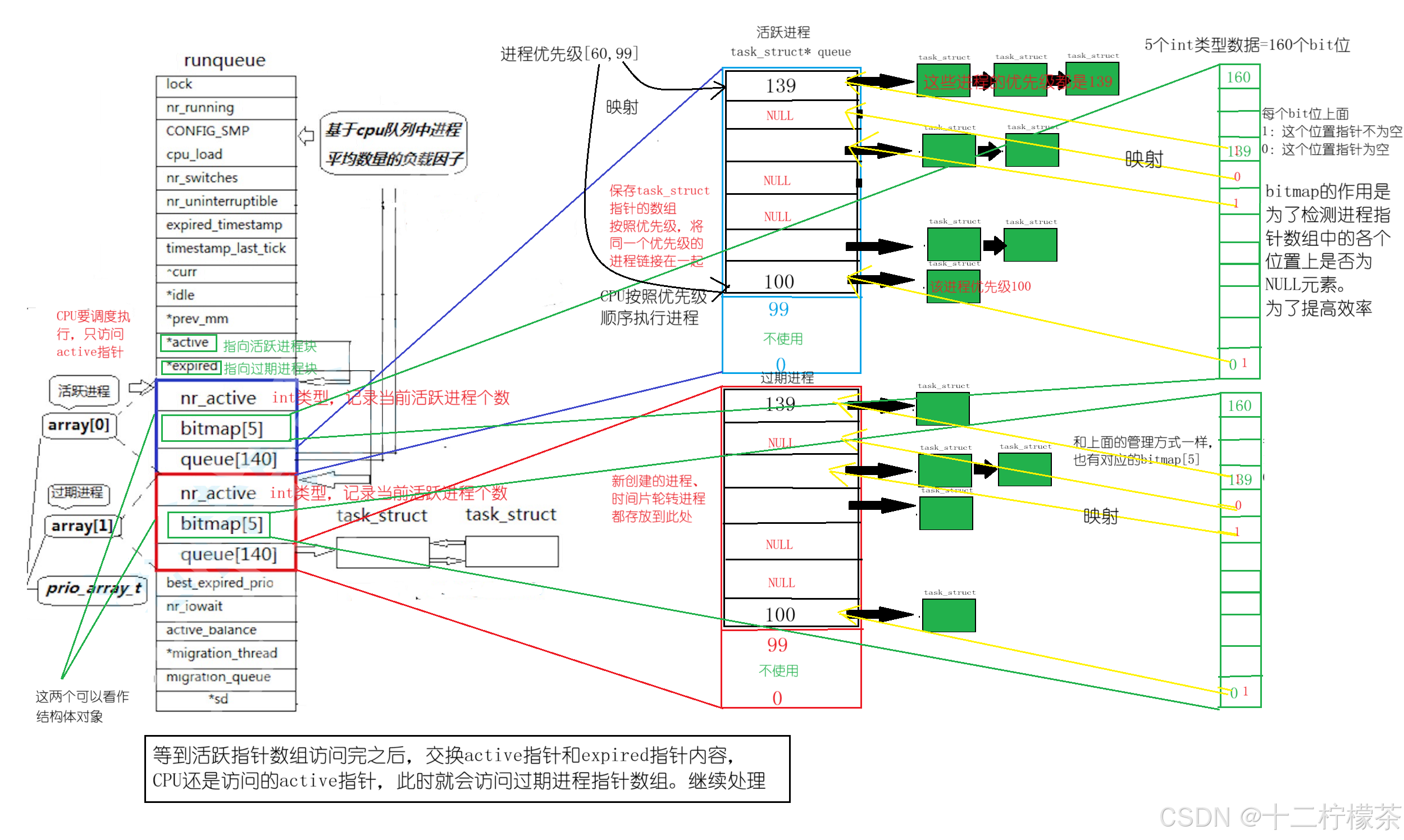
CPU只通过active指针访问调度数据,当前active指向的进程指针数组称为活跃进程,另一个称为过期进程,活跃进程由于进程时间片轮转、进程切换会被链接到过期进程的queue数组中去,活跃进程执行完成之后,会将active指针和expired指针的内容进行交换,CPU再执行下一批进程,由此往复执行进程。
以上就是Linux早期版本的进程调度大致做法。
