目录
基于 MindSpore 的条件随机场(CRF)类的实现与应用代码分析
基于 BiLSTM 和 CRF 的序列标注模型构建与数据准备代码分析
基于 MindSpore 的条件随机场得分计算函数代码分析
定义了一个名为 compute_score 的函数,用于计算条件随机场(CRF)的得分。
首先,通过 pip 命令卸载并重新安装指定版本的 mindspore 库,并查看当前的 mindspore 版本。在 compute_score 函数中,输入参数包括 emissions(发射概率)、tags(标签)、seq_ends(序列结束位置)、mask(掩码)、trans(转移概率矩阵)、start_trans(起始转移概率)和 end_trans(结束转移概率)。函数首先将数据类型进行统一处理,然后初始化得分 score 为起始转移概率与第一次发射概率之和。接着,通过一个循环,根据掩码的值,依次累加标签之间的转移概率和相应的发射概率。最后,考虑结束转移概率,根据序列结束位置获取最后一个标签,并将对应的结束转移概率累加到得分中。
总的来说,该函数的目的是根据给定的各种概率和标签信息,计算出整个序列的得分。
代码如下:
%%capture captured_output # 实验环境已经预装了mindspore==2.3.0rc1,如需更换mindspore版本,可更改下面mindspore的版本号 !pip uninstall mindspore -y !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.3.0rc1 # 查看当前 mindspore 版本 !pip show mindspore def compute_score(emissions, tags, seq_ends, mask, trans, start_trans, end_trans): # emissions: (seq_length, batch_size, num_tags) # tags: (seq_length, batch_size) # mask: (seq_length, batch_size) seq_length, batch_size = tags.shape mask = mask.astype(emissions.dtype) # 将score设置为初始转移概率 # shape: (batch_size,) score = start_trans[tags[0]] # score += 第一次发射概率 # shape: (batch_size,) score += emissions[0, mnp.arange(batch_size), tags[0]] for i in range(1, seq_length): # 标签由i-1转移至i的转移概率(当mask == 1时有效) # shape: (batch_size,) score += trans[tags[i - 1], tags[i]] * mask[i] # 预测tags[i]的发射概率(当mask == 1时有效) # shape: (batch_size,) score += emissions[i, mnp.arange(batch_size), tags[i]] * mask[i] # 结束转移 # shape: (batch_size,) last_tags = tags[seq_ends, mnp.arange(batch_size)] # score += 结束转移概率 # shape: (batch_size,) score += end_trans[last_tags] return score计算条件随机场归一化因子的函数代码分析
定义了一个名为 compute_normalizer 的函数,用于计算条件随机场(CRF)中的归一化因子。
首先,获取了发射概率矩阵 emissions 的序列长度。然后,初始化得分 score 为起始转移概率加上第一次的发射概率。
接下来,通过一个循环从第二个位置开始计算。在每次循环中,对当前的得分进行维度扩展,对发射概率也进行维度扩展,根据特定公式计算下一个得分,并通过 logsumexp 函数进行处理。根据掩码的值来决定是否更新得分。
最后,在得分中加上结束转移概率,并再次使用 logsumexp 函数对所有可能的路径得分在特定维度上进行计算,得到最终的结果。
总的来说,这个函数的主要目的是通过一系列的计算和处理,得出条件随机场中所有可能路径得分的归一化因子。
代码如下:
def compute_normalizer(emissions, mask, trans, start_trans, end_trans): # emissions: (seq_length, batch_size, num_tags) # mask: (seq_length, batch_size) seq_length = emissions.shape[0] # 将score设置为初始转移概率,并加上第一次发射概率 # shape: (batch_size, num_tags) score = start_trans + emissions[0] for i in range(1, seq_length): # 扩展score的维度用于总score的计算 # shape: (batch_size, num_tags, 1) broadcast_score = score.expand_dims(2) # 扩展emission的维度用于总score的计算 # shape: (batch_size, 1, num_tags) broadcast_emissions = emissions[i].expand_dims(1) # 根据公式(7),计算score_i # 此时broadcast_score是由第0个到当前Token所有可能路径 # 对应score的log_sum_exp # shape: (batch_size, num_tags, num_tags) next_score = broadcast_score + trans + broadcast_emissions # 对score_i做log_sum_exp运算,用于下一个Token的score计算 # shape: (batch_size, num_tags) next_score = ops.logsumexp(next_score, axis=1) # 当mask == 1时,score才会变化 # shape: (batch_size, num_tags) score = mnp.where(mask[i].expand_dims(1), next_score, score) # 最后加结束转移概率 # shape: (batch_size, num_tags) score += end_trans # 对所有可能的路径得分求log_sum_exp # shape: (batch_size,) return ops.logsumexp(score, axis=1)条件随机场的维特比解码及后处理函数代码分析
主要定义了两个函数:viterbi_decode 和 post_decode。
viterbi_decode 函数用于执行维特比解码。首先获取掩码的序列长度,初始化得分 score 为起始转移概率加上第一次的发射概率,并记录历史信息。在循环中,通过维度扩展和计算得到下一个得分,找出得分取值最大的标签并保存其索引,更新得分,最终加上结束转移概率。
post_decode 函数用于对维特比解码的结果进行后处理。首先获取批处理大小和序列结束位置,创建一个用于存储最佳标签序列的列表。然后对每个样例,先找到使最后一个标记对应的预测概率最大的标签,再通过回溯历史信息,依次找到每个标记对应的最大概率标签,将逆序求解的标签序列反转得到正序,最后将每个样例的最佳标签序列添加到列表中并返回。
总的来说,这两个函数共同实现了条件随机场中基于维特比算法的解码以及对解码结果的后处理,以得到最终的最佳预测序列。
代码如下:
def viterbi_decode(emissions, mask, trans, start_trans, end_trans): # emissions: (seq_length, batch_size, num_tags) # mask: (seq_length, batch_size) seq_length = mask.shape[0] score = start_trans + emissions[0] history = () for i in range(1, seq_length): broadcast_score = score.expand_dims(2) broadcast_emission = emissions[i].expand_dims(1) next_score = broadcast_score + trans + broadcast_emission # 求当前Token对应score取值最大的标签,并保存 indices = next_score.argmax(axis=1) history += (indices,) next_score = next_score.max(axis=1) score = mnp.where(mask[i].expand_dims(1), next_score, score) score += end_trans return score, history def post_decode(score, history, seq_length): # 使用Score和History计算最佳预测序列 batch_size = seq_length.shape[0] seq_ends = seq_length - 1 # shape: (batch_size,) best_tags_list = [] # 依次对一个Batch中每个样例进行解码 for idx in range(batch_size): # 查找使最后一个Token对应的预测概率最大的标签, # 并将其添加至最佳预测序列存储的列表中 best_last_tag = score[idx].argmax(axis=0) best_tags = [int(best_last_tag.asnumpy())] # 重复查找每个Token对应的预测概率最大的标签,加入列表 for hist in reversed(history[:seq_ends[idx]]): best_last_tag = hist[idx][best_tags[-1]] best_tags.append(int(best_last_tag.asnumpy())) # 将逆序求解的序列标签重置为正序 best_tags.reverse() best_tags_list.append(best_tags) return best_tags_list 基于 MindSpore 的条件随机场(CRF)类的实现与应用代码分析
主要使用 MindSpore 库实现了一个条件随机场(CRF)的类。首先,导入了所需的库和模块。sequence_mask 函数用于根据序列的实际长度和最大长度生成掩码矩阵。CRF 类具有初始化方法 __init__ ,用于设置条件随机场的参数,如标签数量、是否批量优先、归约方式等,并初始化起始转移、结束转移和转移参数。construct 方法根据是否提供了真实标签 tags 来决定执行解码操作 _decode 还是前向计算 _forward 。_forward 方法在进行前向计算时,处理了数据的维度和掩码,计算了得分的分子和分母,从而得到对数似然值,并根据归约方式进行处理返回结果。_decode 方法用于在没有提供真实标签时执行维特比解码操作。
总的来说,这个类实现了条件随机场的基本功能,包括前向计算和解码,并能够根据不同的输入和设置进行灵活的处理和计算。
代码如下:
import mindspore as ms import mindspore.nn as nn import mindspore.ops as ops import mindspore.numpy as mnp from mindspore.common.initializer import initializer, Uniform def sequence_mask(seq_length, max_length, batch_first=False): """根据序列实际长度和最大长度生成mask矩阵""" range_vector = mnp.arange(0, max_length, 1, seq_length.dtype) result = range_vector < seq_length.view(seq_length.shape + (1,)) if batch_first: return result.astype(ms.int64) return result.astype(ms.int64).swapaxes(0, 1) class CRF(nn.Cell): def __init__(self, num_tags: int, batch_first: bool = False, reduction: str = 'sum') -> None: if num_tags <= 0: raise ValueError(f'invalid number of tags: {num_tags}') super().__init__() if reduction not in ('none', 'sum', 'mean', 'token_mean'): raise ValueError(f'invalid reduction: {reduction}') self.num_tags = num_tags self.batch_first = batch_first self.reduction = reduction self.start_transitions = ms.Parameter(initializer(Uniform(0.1), (num_tags,)), name='start_transitions') self.end_transitions = ms.Parameter(initializer(Uniform(0.1), (num_tags,)), name='end_transitions') self.transitions = ms.Parameter(initializer(Uniform(0.1), (num_tags, num_tags)), name='transitions') def construct(self, emissions, tags=None, seq_length=None): if tags is None: return self._decode(emissions, seq_length) return self._forward(emissions, tags, seq_length) def _forward(self, emissions, tags=None, seq_length=None): if self.batch_first: batch_size, max_length = tags.shape emissions = emissions.swapaxes(0, 1) tags = tags.swapaxes(0, 1) else: max_length, batch_size = tags.shape if seq_length is None: seq_length = mnp.full((batch_size,), max_length, ms.int64) mask = sequence_mask(seq_length, max_length) # shape: (batch_size,) numerator = compute_score(emissions, tags, seq_length-1, mask, self.transitions, self.start_transitions, self.end_transitions) # shape: (batch_size,) denominator = compute_normalizer(emissions, mask, self.transitions, self.start_transitions, self.end_transitions) # shape: (batch_size,) llh = denominator - numerator if self.reduction == 'none': return llh if self.reduction == 'sum': return llh.sum() if self.reduction == 'mean': return llh.mean() return llh.sum() / mask.astype(emissions.dtype).sum() def _decode(self, emissions, seq_length=None): if self.batch_first: batch_size, max_length = emissions.shape[:2] emissions = emissions.swapaxes(0, 1) else: batch_size, max_length = emissions.shape[:2] if seq_length is None: seq_length = mnp.full((batch_size,), max_length, ms.int64) mask = sequence_mask(seq_length, max_length) return viterbi_decode(emissions, mask, self.transitions, self.start_transitions, self.end_transitions)基于 BiLSTM 和 CRF 的序列标注模型构建与数据准备代码分析
主要定义了一个结合双向 LSTM(BiLSTM)和条件随机场(CRF)的模型 BiLSTM_CRF,并进行了一些数据准备工作。
BiLSTM_CRF 类在初始化时,构建了词嵌入层、双向 LSTM 层、从隐藏层到标签的全连接层,以及一个 CRF 层。
construct 方法中,输入经过词嵌入得到嵌入向量,再经过双向 LSTM 得到输出,然后通过全连接层得到特征,最后将特征输入到 CRF 层进行处理。
在后续部分,准备了训练数据 training_data,并创建了词到索引和标签到索引的映射 word_to_idx 和 tag_to_idx,用于将文本数据转换为模型可接受的数字形式。
总的来说,实现了一个用于序列标注任务的模型架构,并进行了初步的数据预处理工作,为后续的模型训练做好了准备。
代码如下:
class BiLSTM_CRF(nn.Cell): def __init__(self, vocab_size, embedding_dim, hidden_dim, num_tags, padding_idx=0): super().__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=padding_idx) self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, bidirectional=True, batch_first=True) self.hidden2tag = nn.Dense(hidden_dim, num_tags, 'he_uniform') self.crf = CRF(num_tags, batch_first=True) def construct(self, inputs, seq_length, tags=None): embeds = self.embedding(inputs) outputs, _ = self.lstm(embeds, seq_length=seq_length) feats = self.hidden2tag(outputs) crf_outs = self.crf(feats, tags, seq_length) return crf_outs embedding_dim = 16 hidden_dim = 32 training_data = [( "清 华 大 学 坐 落 于 首 都 北 京".split(), "B I I I O O O O O B I".split() ), ( "重 庆 是 一 个 魔 幻 城 市".split(), "B I O O O O O O O".split() )] word_to_idx = {} word_to_idx['<pad>'] = 0 for sentence, tags in training_data: for word in sentence: if word not in word_to_idx: word_to_idx[word] = len(word_to_idx) tag_to_idx = {"B": 0, "I": 1, "O": 2} len(word_to_idx)运行结果:
21
BiLSTM-CRF 模型的训练准备与数据处理代码分析
在完成之前模型定义和数据预处理的基础上,进一步进行模型训练的准备工作。首先创建了 BiLSTM_CRF 模型,并定义了优化器 SGD 以及计算梯度的函数 grad_fn 。然后定义了 train_step 函数,用于执行梯度计算、参数更新并返回损失值。prepare_sequence 函数用于处理输入的序列数据和标签。它首先找出所有序列中的最大长度,然后对于每个序列和对应的标签,记录其实际长度,将序列中的词和标签转换为对应的索引值,并进行填充操作,使得所有序列长度一致,最后将处理后的结果转换为 MindSpore 的张量并返回。通过 prepare_sequence 函数处理训练数据 training_data ,得到处理后的数据 data 、标签 label 和序列长度 seq_length ,并查看它们的形状。
总的来说,为模型的训练做好了数据准备和训练函数的定义。
代码如下:
model = BiLSTM_CRF(len(word_to_idx), embedding_dim, hidden_dim, len(tag_to_idx)) optimizer = nn.SGD(model.trainable_params(), learning_rate=0.01, weight_decay=1e-4) grad_fn = ms.value_and_grad(model, None, optimizer.parameters) def train_step(data, seq_length, label): loss, grads = grad_fn(data, seq_length, label) optimizer(grads) return loss def prepare_sequence(seqs, word_to_idx, tag_to_idx): seq_outputs, label_outputs, seq_length = [], [], [] max_len = max([len(i[0]) for i in seqs]) for seq, tag in seqs: seq_length.append(len(seq)) idxs = [word_to_idx[w] for w in seq] labels = [tag_to_idx[t] for t in tag] idxs.extend([word_to_idx['<pad>'] for i in range(max_len - len(seq))]) labels.extend([tag_to_idx['O'] for i in range(max_len - len(seq))]) seq_outputs.append(idxs) label_outputs.append(labels) return ms.Tensor(seq_outputs, ms.int64), \ ms.Tensor(label_outputs, ms.int64), \ ms.Tensor(seq_length, ms.int64) data, label, seq_length = prepare_sequence(training_data, word_to_idx, tag_to_idx) data.shape, label.shape, seq_length.shape运行结果:
((2, 11), (2, 11), (2,))
BiLSTM-CRF 模型的训练与预测结果处理代码分析
进行了模型的训练过程,并对训练结果进行了预测和处理。首先,通过 %%time 记录代码的执行时间。然后使用 tqdm 创建一个进度条,进行 steps 次的训练迭代。在每次迭代中,调用 train_step 函数进行训练并获取损失值,更新进度条的显示信息。训练完成后,使用模型对输入数据进行预测,得到得分和历史信息,并通过 post_decode 函数进行后处理得到预测结果 predict 。接着,创建了从索引到标签的映射 idx_to_tag ,并定义了 sequence_to_tag 函数,将预测结果中的索引转换为对应的标签。最后,调用 sequence_to_tag 函数对预测结果进行处理并得到最终的标签序列。总的来说,实现了模型的训练和对预测结果的转换与处理。
代码如下:
%%time from tqdm import tqdm steps = 500 with tqdm(total=steps) as t: for i in range(steps): loss = train_step(data, seq_length, label) t.set_postfix(loss=loss) t.update(1) score, history = model(data, seq_length) score predict = post_decode(score, history, seq_length) predict idx_to_tag = {idx: tag for tag, idx in tag_to_idx.items()} def sequence_to_tag(sequences, idx_to_tag): outputs = [] for seq in sequences: outputs.append([idx_to_tag[i] for i in seq]) return outputs sequence_to_tag(predict, idx_to_tag)运行结果:
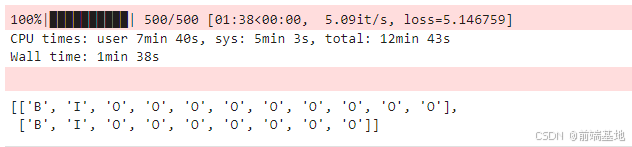
打印时间: