
阅读量:0
简介: 概括如下:在构建一个兼容多种LLM推理框架的平台时,开发者选择了Ray分布式框架,以解决资源管理和适配问题。然而,在尝试集成vllm时遇到挑战,因为vllm内部自管理Ray集群,与原有设计冲突。经过一系列尝试,包括调整资源分配、修改vllm源码和利用Ray部署的`placement_group_bundles`特性,最终实现了兼容,但依赖于非官方支持的解决方案。在面对vllm新版本和Ray部署的`reconfigure`方法问题时,又需权衡和调整实现方式。尽管面临困难,开发者认为使用Ray作为统一底层仍具有潜力。
ray作为开源的分布式框架,我一直对其抱有好感。所以在尝试搭建一个LLM inference平台的时候我想到了ray。
这个想法是在去年下半年的时候萌发的,当时开源界已经有很多LLM inference的框架,比如:huggingface transformer(包括accelerate)包,deepspeed-inference/deepspeed-FastGen(似乎现在做了集成,改名为deepspeed-MII),还有GGUF格式的inference,以及今天的主角vllm。 但是缺乏一个能够兼容上述主流框架的平台,这个平台底层能够为负载分配计算资源,向上可以适配多种inference框架。这样能够最大满足用户的不同需求,如:使用不同inference框架来运行LLM模型(比如新出的模型,vllm等框架还没有适配,那得使用基本的transformer包,或者比较不同框架运行同一个模型的差异等等)。
我最先到的是使用k8s,但是当时发现即使是最基础的包含hg transformer的镜像都超过7g(现在可能会有改观),这个劝退了我,所以我转投ray(也许是一个错误)。
ray的基本原理是:以node为单位组成ray cluster,inference代码以进程的方式跑在node上,这样可以共享lib,部分避免了上面提到k8s方案的问题。做资源分配的时候创建placegroup(PG), PG中包含bundles, 比如{“CPU”: 1, “GPU”: 4} 就是一个bundle,inference代码跑在这种被分配的资源中,然后根据node的capacity进行调度(类似k8s schedule)。
在最初的实现中,这个机制工作的很好:
- 解析model配置,如model ID啊,需要的资源啊,是不是要做张量并行啊,autoscale配置(ray支持autoscale和serverless),加载model和推理model用到的参数等等
- 根据资源需求和并行参数创建PG/bundles
- 将inference代码运行在PG/bundles里,然后做后续的工作,如使用指定的inference框架加载模型啊,等等
这套做法在适配hg transformer包,llama.cpp, 甚至deepspeed inference的时候够工作的很好,但是在vllm的时候遇到了问题,我想把他称之为vllm第一次折磨。
vllm的实现中有一点很有意思,如果设置了tensor_parallel > 1, 那么默认启动/连接ray cluster,使用ray作为张量并行的底层平台(ray version <= 0.4.1行为)。这就给我们的实现带来了很大的困难:
- 我的实现:根据resource需求创建PG -> inference框架跑在PG的bundle中
- vllm的实现: 启动vllm的engine(vllm叫法)-> engine根据张量并行和资源要求联系/创建 ray cluster,并创建PG,然后跑inference代码
矛盾点很明显,vllm将ray置于其框架之下,而我们的实现是把框架作为ray的一个负载,这一上一下就为集成带来了很大的困难。
好在这个问题最终得到了解决,方案是vllm engine可以接受一个已经存在的PG,这样避免了vllm自己创建,维持了我们方案的一致性,当然也付出了很大的调研时间,但最终是解决了(vllm version 0.2.0 - 0.2.6)
虽然问题得到了解决,但是我心里仍然很不安,原因很简单:我的解决方案并不是vllm官方支持的,只是通过研读源码,自行找到的解决方案。在社区未来的升级中大概率会被破坏掉!
根据墨菲定律,问题来的很快!在今年早些时候Qwen1.5架构出来以后,我发现之前集成的vllm版本(v0.2.6)并未适配Qwen1.5,无奈之下,开始对当时最新的vllm 0.4.1进行升级。
我愿把这次集成称为vllm第二次折磨。
不出所料,问题出现了!
问题还比较棘手,在介绍问题之前,我先讲下我原本的实现:
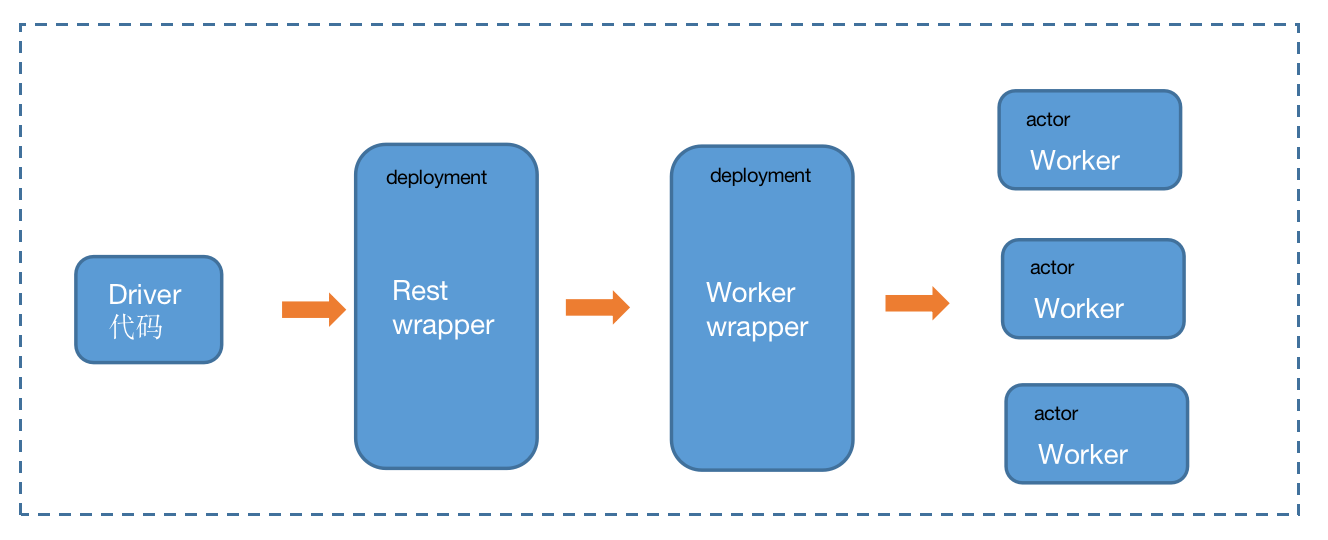
如上图,
- 外面的虚线代表ray cluster
- Driver(ray的说法)代码会创建一个ray deployment,这个deployment主要作用是使用fastapi做一个rest的实现,后期对外提供rest服务。注意,这个deployment没有分配GPU,默认分配一个CPU.
- 在Rest wrapper这个ray deployment中bind(ray说法)另外一个ray deployment:Worker wrapper,这个deployment的主要作用是创建PG,并将模型加载,推理等代码跑在创建的worker(bundles)中。注意,这个deployment也没有分配GPU资源。
- Workers, 是ray actor,根据用户配置的资源需求和张量并行的配置(worker的数量)分配了相应的GPU。
在vllm的适配中,vllm engine的启动是在Worker wrapper中完成的,创建完PG后交给vllm engine,这个逻辑在vllm version 0.2.0 - 0.2.6工作的很好,但是在vllm 0.4.1中遇到了新的麻烦:
新版的vllm在启动engine的时候做了大量的工作,需要GPU/cuda的支持,比如决定用那个attention framework(xformers, flash attention等),详见vllm attention实现。 这就意味着得为worker wrapper这个原本不需要GPU的ray deployment分配GPU资源,这在我看来是不可接受的。
为了解决这个问题,我做了如下探索:
- 为worker wrapper分配0.1GPU, 这会连带某一个worker只会得到0.9个GPU,但是遭到了失败,原因是在vllm的实现中,worker之间是通过nccl进行通信的,nccl要求完整的GPU。
- 研究了vllm源码(vllm ray实现源码),说实话,这个实现给我带来了很大的困扰,我也在社区提了issus,希望能得到当时的设计文档,但是并未得到有价值的回复(吐槽vllm社区哈)。最终我通过继承社区的实现修改了部分逻辑,原理是让启动engine时部分需要GPU的代码跑在worker中,因为这些代码是一次性执行,所以不会影响最终worker的执行。
虽然问题解决了,但是不安更严重了,这次的解决方案更加的hack,完全不是社区支持的。
带着这样的担忧,我开始寻找其他解决方案,幸运的是,我找到了ray社区给出的方案:ray给出的方案, 不幸的是这个方案在vllm最新版本中并不工作,我无奈提了个pr去fix,一周多还没有merge,当然这是另外一个话题。
这个方案中给出了新的解决方法:不去创建PG, 使用ray deployment的placement_group_bundles参数,为worker wrapper声明(非分配)足够的资源,在我们的情况中是[{“CPU”: 1}, {“CPU”: 1, “GPU”: 1}, {“CPU”: 1, “GPU”: 1}],这是tensor_parallel == 2的情况。
这是个很有趣的方案,可以解决我的难题。
但实践过程充满了波折:我在实现中使用了ray deployment的reconfigure方法来使用客户化数据(model的各种参数等),但是后来发现只要deployment中有reconfigure方法,那么placement_group_bundles的配置就不生效,我没有深入研究ray deployment的实现,一度认为reconfigure方法被调用的时间点也许相应包含GPU资源的PG还未建立,但是后来发现,只要reconfigure方法存在,哪怕是空方法,那么placement_group_bundles就不生效,已经提出issue到ray社区,仍未获得回复。
但是这已经不影响我的实现了,放弃使用reconfigure就可以了。
这个称为vllm第2.5次折磨!
总结一下,使用ray作为兼容多个inference 框架的底层也许是个有价值的想法,随着inference的继续发展,可能会越来越有吸引力,但是难度也存在,需要不停的解决问题,但这也是程序员的乐趣所在。
