
阅读量:0
文章目录
前言
CLIP这篇论文是OpenAI团队在2021年2月底提出的一篇论文,名字叫做《Learning Transferable Visual Models From Natural Language Supervision》,从自然语言的监督中学习可迁移视觉表征,CLIP是Contrastive Language-Image Pre-training的缩写,是一种多模态模型。这篇论文从名字可以看出,是通过自然语言作为监督信号进行CV领域的大规模预训练然后迁移到下游任务。接下来进行CLIP这篇论文的介绍。
一、CLIP理论
1.CLIP思想
在CV领域,基于监督学习的分类模型在推理时最终的输出结果只能是在训练时提前定义好的那些种类,受到分类头的限制。而在NLP领域,文本进文本出的大模型例如GPT3却突破了这种限制并且能够很好的在下游任务上进行Zero-Shot推理而不在需要专门的分类头。这说明在大规模的文本数据上进行训练的模型可以获得聚合监督的效果。因为文本数据中的冗余信息远比图片要少,因此在CV领域以文本作为监督信号或许可以获得像NLP领域那样的Zero-Shot迁移效果。
2.模型结构
CLIP的输入是文本-图像对,文本内容是对于图片的描述,使用Transformer作为文本特征提取器,使用Resnet或者Vision Transformer作为图片特征提取器,然后将提取到的特征通过对比学习的方式算Loss进行参数更新。如下图所示:
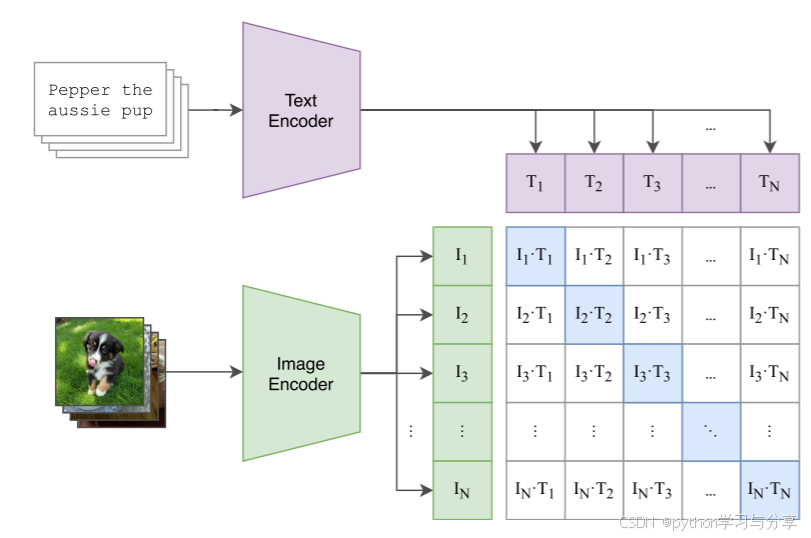
二、CLIP预训练
1.数据集
在CV领域以自然语言作为监督信号的方法之前就有过,但是那些方法大都受限于数据集的规模,并且那时候Transformer还没有出现,对于文本的上下文特征提取做的还没有那么好。因此,为了尝试覆盖尽可能多的视觉概念,OpenAI团队做了一个很大的文本图片配对数据集,大概有4亿文本-图像对,相当于训练GPT2数据集的大小。
2.训练策略
训练时只使用了随机剪裁进行图像增强,并且使用线性层将每个编码器的输出映射到多模态空间。在进行训练目标的选择时,CLIP选用的是对比学习的方法,如下图所示: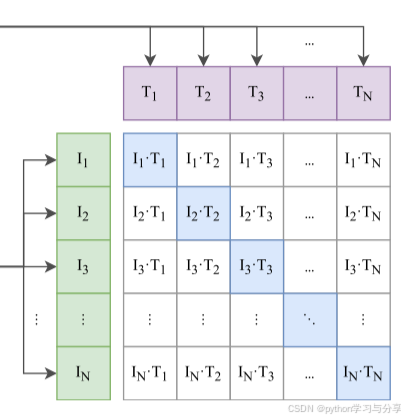
例如输入的Batchsize为N,那么就会有N个文本特征和N个图像特征,这些特征可以组合成一个NXN的特征图,特征图中的对角线元素的文本和图像特征是配对的,为正样本对( N N N个),其他都是负样本对( N 2 − N N^2-N N2−N个)。训练时通过最大化N个正样本对的图像和文本嵌入的余弦相似度,最小化负样本对的图像和文本嵌入的余弦相似度来更新参数。
之所以选择使用对比学习的方式,而不用NLP领域那边的预测文本输出的自监督方式,是因为对于一张图片来说,关注点不同那么对于这张图片的描述也就不同,通过图片特征去预测这张图片对应的文本标签是一件比较困难的事情。而使用对比学习相当于放宽了约束条件,只要训练模型知道图片和哪个文本是对应的就可以。(相当于选择题比填空题要容易一些)
3.模型选择
文本编码器
对于文本编码器,CLIP选择的Transformer的解码器,8个注意力头,宽为512,共堆叠了12个解码器,参数为63M。对于输入的文本token,在第一个位置前加入’BOS’,在最后的位置加入’EOS’,由于Transformer解码器自注意力的特性,把’EOS‘作为整个文本输入的特征代表,将’EOS’的编码后的文本特征进行归一化然后通过线性层映射到多模态空间中。
图像编码器
CLIP的图像编码器有两个版本,分别是使用Resnet和使用Vision Transformer。并分别对其进行了修改使其能够更加适应任务。
三、Zero-Shot推理
在进行下游任务的推理时,例如图片分类,图片编码器的输入是一张图片,而文本编码器的输出是你自己定义的分类文本。例如:
现在有一张图片要进行分类,我们可以自己定义一些分类种类文本[‘猫’,‘狗’,‘鱼’,‘鸟’,‘汽车’],然后进行prompt,把五个单词变成5句话,[‘这是一只猫的图片’,’这是一只够的图片‘,’这是一只鱼的图片‘,‘这是一只鸟的图片’,‘这是一只汽车的图片’]送入到文本编码器中,然后将图片送入图像编码器中,模型会根据输入的文本选择与图片内容最为相近的种类从而完成分类。如下图所示:
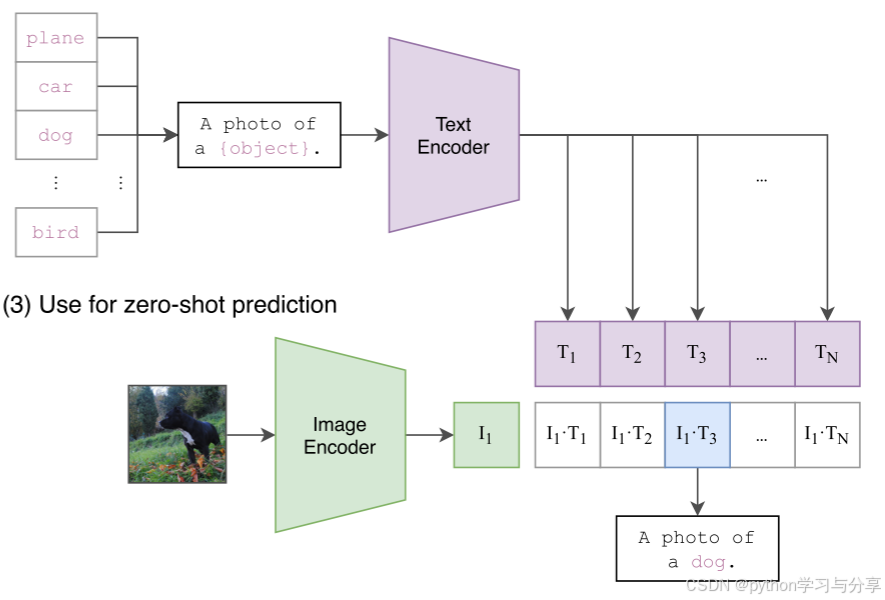
之所以进行prompt engineering有两个原因:1.一词多义,一个单词可能存在好几种意思,需要上下文信息来猜测这个单词的具体含义。2.与预训练时的文本输入保持一致。因为在预训练时的输入大多是一句话,为了减小预训练和推理时的输入gap,在预测时输入也是一句话。
实验表明,为每个任务定制prompt提示文本可以提高Zero-Shot的性能。例如在Oxford-IIIT Pets数据集上进行宠物的分类时,prompt文本可以写成“A photo of a {label}, a type of pet.”。是不是和GPT那边的prompt engineering很像?
与传统的有监督的模型不同的是,有监督10分类模型在推理时只能是10选1,输出只能是你提前定义好的10个种类中的一个。而CLIP可以随意定义自己的分类文本内容,可以是5选1,也可以是6选1,CLIP会根据你输入的文本内容选择与图片最相似的种类。
CLIP可以随意进行Zero-Shot推理的一部分原因是因为训练的数据集很大,覆盖了绝大部分的视觉概念,并且文本的冗余信息较少,模型可以较准确的找出与视觉特征相似度较高的文本种类特征从而完成分类。
四、CLIP伪代码实现
import torch import numpy as np # image_encoder - ResNet or Vision Transformer # text_encoder - Transformer # I [n, h, w, c] - n为batchsize大小 # T [n, l] - l为输入文本token长度 # Linear_i[d_i, d_e] - 将图片特征映射到多模态空间 # Linear_t[d_t, d_e] - 将文本特征映射到多模态空间 # t 可学习的温度系数 I_f = image_encoder(I) #[n, d_i] T_f = text_encoder(T) #[n, d_t] I_e = Linear_i(I_f) # [n,d_e] T_e = Linear_i(T_f) # [n,d_e] # 并行计算文本特征和图像特征的余弦相似度 logits = np.dot(I_e, T_e.T) * np.exp(t) # [n,n] #正样本对都是在对角线上,对应的标签为0到n-1 labels = np.arange(n) #从图片和文本两个维度进行特征匹配损失 loss_i = cross_entropy_loss(logits, labels, axis=0) loss_t = cross_entropy_loss(logits, labels, axis=1) loss = (loss_i + loss_t)/2 optimer.zero_grad() loss.backward() update() 五、CLIP局限性
CLIP还存在着一些局限性,例如虽然能取得和有监督的基线模型差不多的效果,但是距离SOTA的模型差距还很大;其Zero-Shot的推理也很受限于训练数据的分布,对于训练数据中没有出现过的物体,CLIP也很难做的好;CLIP是根据文本中给定的种类去做分类,不能像GPT那种直接根据图片输出种类,并且有时在下游任务的推理时Few-Shot效果比Zero-Shot效果还要差等等。
总结
CLIP是一种利用自然语言作为监督信号的多模态模型,打破了传统的监督学习的固定标签的范式。其使用对比学习的方法进行预训练,并且可以在下游任务上通过文本Prompt进行Zero-Shot推理,在足够的规模性,CLIP可以与特定任务的监督模型相竞争,同时其还有很大的提升空间。
