
阅读量:0
文章目录
0. 背景
在采用 HuggingFace 提供的 Transformers 库来训练模型时,如果出现模型训练中断的情况,此时我们希望断点接训,TraningArguments 有一个参数:resume_from_checkpoint=True,用来将保存的 Checkpoint 重新拉起接着训练,Checkpoint 保存了模型的状态参数信息。
此时有一个疑问,再次恢复训练后,模型状态恢复了,但是之前训练过的数据还会重头再训练一遍吗?会不会跳过这部分数据?
查询了网上对这个问题的讲解,发现有一个参数: ignore_data_skip ,但是解释不清楚,最终发现很多是错误的,下面就这个参数进行详细解释。
1. 官方解释
我们先看一下 HuggingFace 的官方对 ignore_data_skip 参数的解释,详情参考这里:

翻译一下:
ignore_data_skip (bool, 可选, 默认 False) 恢复训练时,是否跳过epochs和batches,以便在与前一次训练相同的阶段加载数据。如果设置为True,训练将开始得更快(因为跳过步骤可能需要很长时间),但不会产生与中断训练相同的结果。
从上面的解释来看,默认情况下即 False,会跳过已经处理过的数据,即从新的数据开始处理;如果设置为 True,那么不会跳过已经处理过的数据,还会从已训练过的数据再来开始训练。
2. 查看源码
为了进一步验证上面的解释,只能看一下源码关于这个参数的处理了,在 Python 库的 transformers/trainer.py :
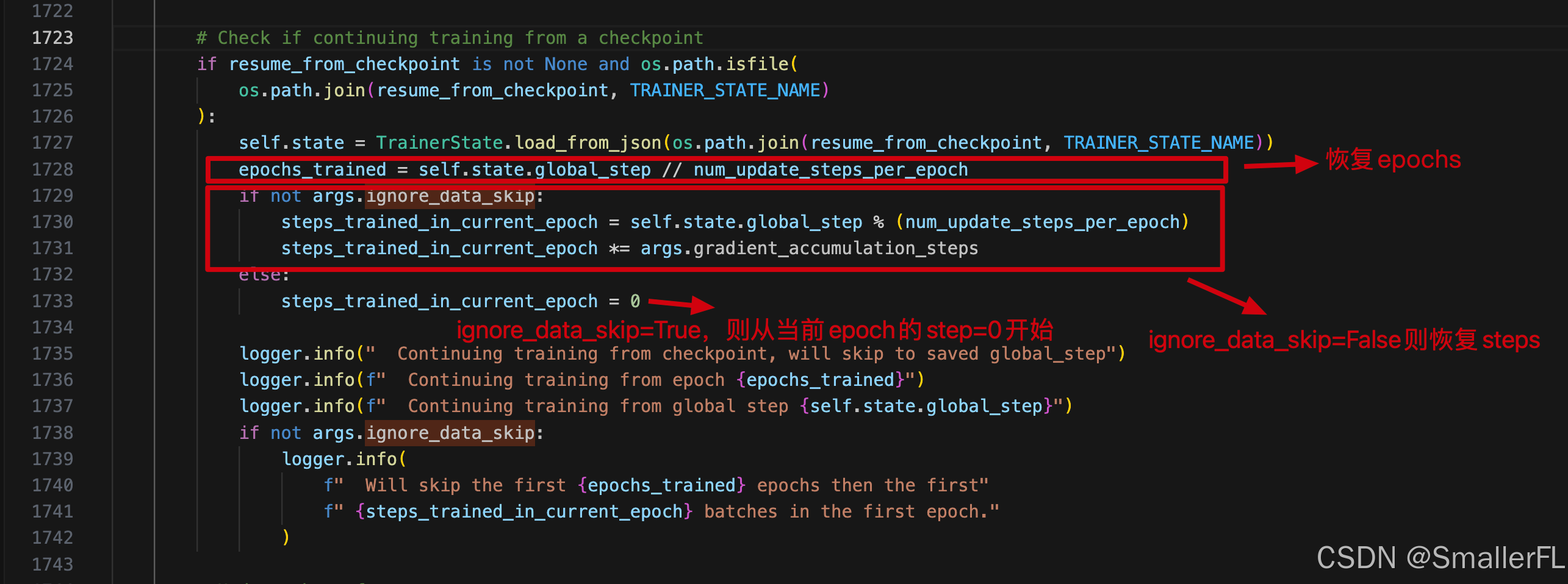
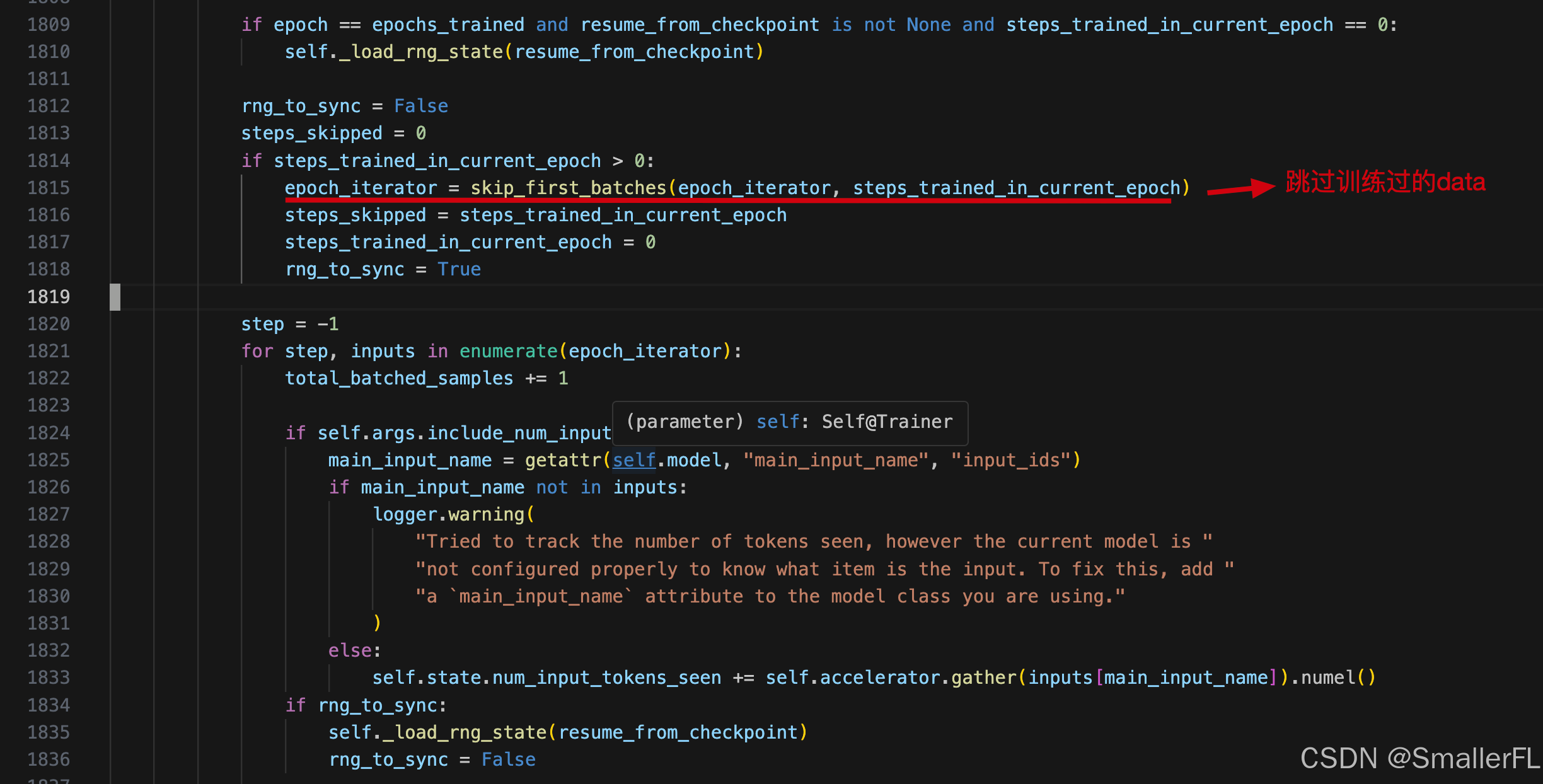
从上图中可以看出几点:
- 当设置了
resume_from_checkpoint=True之后,epochs都会恢复,ignore_data_skip并不会影响已经训练过的 epoch。例如,之前模型训练了2个epoch,并且在第3个epoch的1000步中断了,那么恢复后的epoch还是从第3个开始; - 设置
ignore_data_skip=True会在恢复后的 epochs 从头开始训练。例如,之前模型训练了2个epoch,并且在第3个epoch的1000步中断了,那么设置ignore_data_skip=True,就会从第3个epoch的0步开始训练。如果设置ignore_data_skip=False则接着1000步训练。
3. 验证
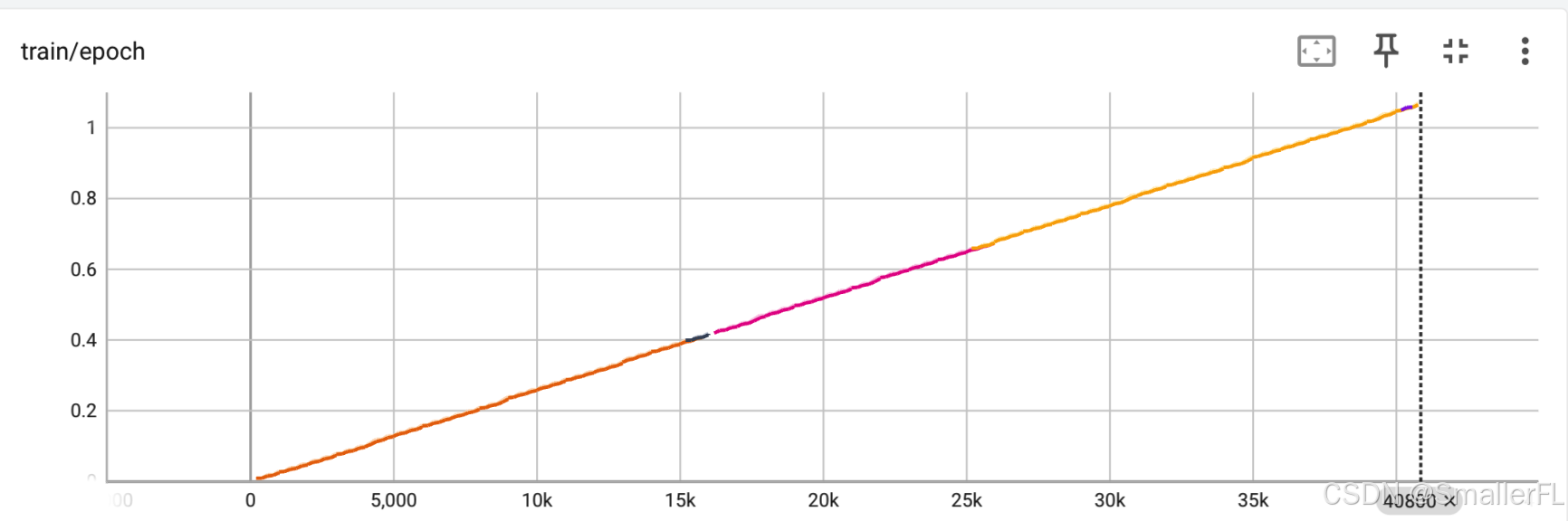
例如此次训练,中间断了很多次,重新拉起训练后还是基本上接着后面训练,并未从0开始。
4. 总结
断点重训,设置了 resume_from_checkpoint=True 后,一般情况下 ignore_data_skip 保持默认 False 即可。
