
阅读量:0
1 pkuseg简介
PKUSEG,全称“北京大学语言计算与机器学习研究组开发的分词工具”,它就像一把锋利的瑞士军刀,帮助我们轻松切割文本。
在Python的文本处理领域,有很多分词工具,比如jieba、SnowNLP等。但是,PKUSEG以其高精度和易用性脱颖而出。它不仅能够进行基本的分词,还能识别词性,甚至能够处理一些复杂的语言现象,比如新词识别和歧义消解。
2 pkuseg安装
命令如下:
pip install pkuseg -i https://pypi.tuna.tsinghua.edu.cn/simple3 代码示例
3.1 基本分词
假设我们有一段文本,我们想要把它分成一个个独立的词。下面是如何使用PKUSEG进行基本分词的代码:
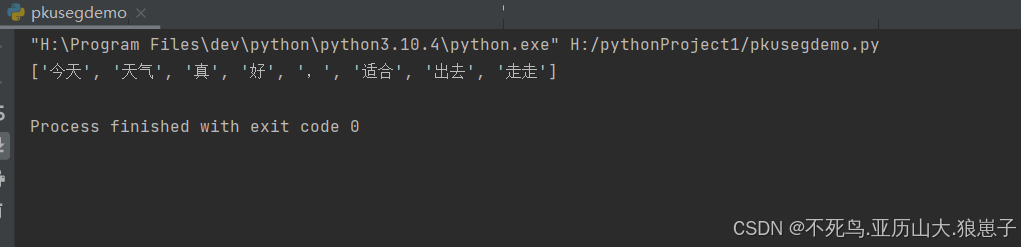
import pkuseg #初始化分词器 seg = pkuseg.pkuseg() # 待分词文本 text = "今天天气真好,适合出去走走" # 进行分词 words = seg.cut(text) print(words)结果如下:
3.2 词性标注
PKUSEG不仅能分词,还能给每个词标注词性。这对于文本分析来说非常有用。下面是一个词性标注的示例:
import pkuseg #初始化分词器 seg = pkuseg.pkuseg(postag=True) # 待分词文本 text = "今天天气真好,适合出去走走" # 进行分词 words = seg.cut(text) print(words)结果如下:

注意:每个字母的意义如下
| 符号 | 含义 | 符号 | 含义 |
| n | 名词 | t | 时间词 |
| s | 处所词 | f | 方位词 |
| m | 数词 | q | 量词 |
| b | 区别词 | r | 代词 |
| v | 动词 | a | 形容词 |
| z | 状态词 | d | 副词 |
| p | 介词 | c | 连词 |
| u | 助词 | y | 语气词 |
| e | 叹词 | o | 拟声词 |
| i | 成语 | l | 习惯用语 |
| j | 简称 | h | 前接成分 |
| k | 后接成分 | g | 语素 |
| x | 非语素字 | w | 标点符号 |
| nr | 人名 | ns | 地名 |
| nt | 机构名称 | nx | 外文字符 |
| nz | 其它专名 | vd | 前接成分 |
| vn | 名动词 | vx | 形式动词 |
| ad | 副形词 | an | 名形词 |
3.3 细领域分词
import pkuseg seg = pkuseg.pkuseg(model_name='medicine') # 程序会自动下载所对应的细领域模型 text = seg.cut('我爱北京天安门') # 进行分词 print(text)3.3 文本情感分析
情感分析是判断文本表达的是正面情绪还是负面情绪。我们首先需要分词,然后根据词性过滤掉无用的词,最后统计正面和负面词汇的数量。
import pkuseg #初始化分词器 seg = pkuseg.pkuseg(postag=True) # 定义正面和负面词汇列表 positive_words = ['好', '好用', '棒', '喜欢'] negative_words = ['差', '糟糕', '讨厌'] # 待分析文本 text = "这个产品真的很好用,但是价格有点高。" # 分词并标注词性 words_with_pos = seg.cut(text) # 统计正面和负面词汇 positive_count = sum(1 for word, pos in words_with_pos if word in positive_words) negative_count = sum(1 for word, pos in words_with_pos if word in negative_words) print(f"正面情绪词汇数量:{positive_count}") print(f"负面情绪词汇数量:{negative_count}")结果如下:

4 总结
PKUSEG的功能远不止于此,它还可以用于命名实体识别、关键词提取等高级文本分析任务。
