
阅读量:0
目录
一、LSTM提出的背景:
1.RNN存在的问题:
由于RNN的隐藏状态ht用于记录每个句子之前的所有序列信息,而对于长序列问题来说ht会记录太多序列信息导致序列时序特征区分度很差(最前面的序列特征因为进行了太多轮迭代往往不太好从ht中提取),并且RNN默认当前时间步的token单词和该句子的隐藏状态ht中所有序列信息都有同等的相关度,因此一些比较靠前但与当前时间步输入的token相关性高的序列特征在ht中可能就不太被重视,而一些比较靠后但与当前时间步输入的token相关性低的序列特征在ht中被过于关注。
2.LSTM的思想:
2.1回顾GRU的提出:
GRU的提出就是为了解决RNN默认序列内所有token之间的相关性相等问题。
GRU的思想是对于每个时间步的输入token,使用门的控制将隐藏状态ht中与当前token相关性高的序列信息拿来参与计算,而ht中与当前token相关性低的序列信息作为噪音不参与计算。
- 对于需要关注的序列信息,使用更新门来提高关注度
- 对于需要遗忘的序列信息,使用遗忘门来降低关注度
2.2LSTM在GRU上的改进:
LSTM可以理解成GRU的变体,保留了重置门(遗忘门)用来对过去所有时间步的序列信息进行选择、更新门(输入门)用来对当前一个时间步的序列信息进行选择。在此基础上增加了记忆单元Ot用来保存长序列的序列特征,而Ht仅需要保存短序列的序列特征即可,解决了Ht不能很好的保存长序列信息的缺点。除此之外还增加了输出门的概念来控制Ot中分配多少个时间步的序列信息给Ht。
二、遗忘门、输入门、输出门:
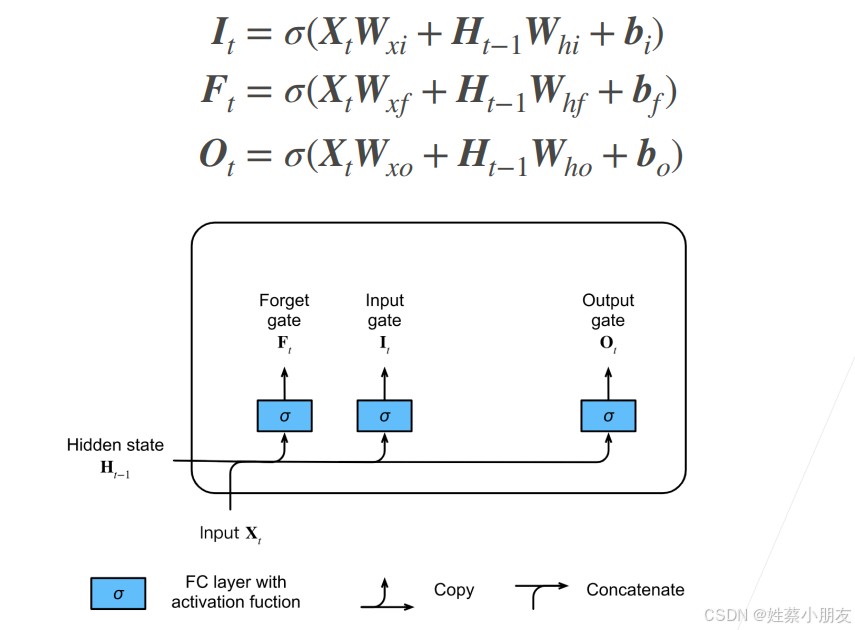
遗忘门、输入门、输出门可以分别看做一个全连接层的隐藏层,这样的话上图就等价于三个并排的隐藏层,其中:
- 每个隐藏层都接收之前时间步的隐藏状态Ht-1和当前时间步的输入token。
- 遗忘门、输入门、输出门有各自的可学习权重参数和偏置值,公式含义类似传统RNN。
- Ft、It、Ot 都是根据过去的隐藏状态 Ht-1 和当前输入 Xt 计算得到的 [0,1] 之间的量(激活函数)。
三、LSTM网络架构:
1.候选记忆单元C~t:
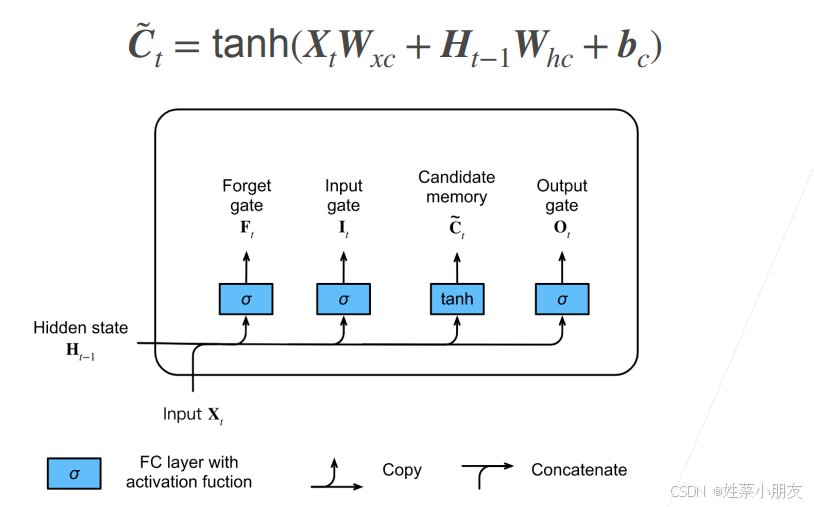
候选记忆单元的计算公式类似于RNN计算Ht的公式,用来记录当前时间步token的序列信息和前t-1个时间步的序列信息。
2.遗忘门、输入门、输出门如何发挥作用:
2.1记忆单元Ct:
LSTM 3D视频讲解链接
首先LSTM在Ht的基础上加入了Ct,其中Ht仅需记录短期序列信息,Ct负责记录长期序列信息。
并且LSTM主要是对Ct更新,而GRU和RNN主要是对Ht更新。
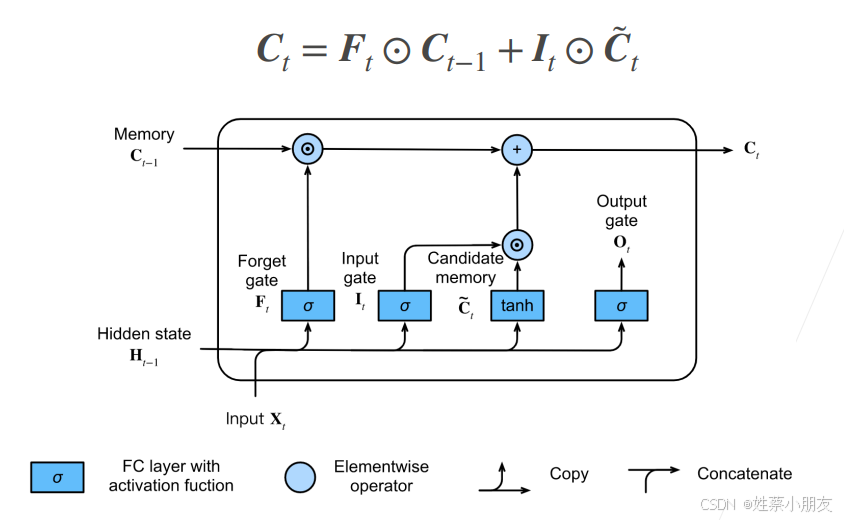
(1)因为Ft是一个[0,1] 之间的量,所以Ft×Ct-1是对之前的长期序列信息Ot-1进行一次选择:Ft 在某个位置的值越趋近于0,则表示Ot-1这个位置的序列信息越倾向于被丢弃,反之保留。
综上,遗忘门的作用是对过去的长序列信息Ot-1进行选择,Ot-1中哪些序列信息当前的Ct是有用的,应该被保存下来,而哪些序列信息是不重要的,应该被遗忘。
(2)因为It是一个[0,1] 之间的量,如果It全为0,则当前记忆单元Ot为上一个时间步的记忆单元Ot-1;如果It全为1,则当前记忆单元Ot为上一个时间步的记忆单元Ot-1和候选记忆单元O~t(候选记忆单元记录当前时间步token的序列信息和前t-1个时间步的序列信息)的和(感觉这里Ot-1和O~t中记录的过去序列信息重复了,设计好像有冗余问题,没有GRU那么完美)。
综上,输入门的作用是决定当前一个时间步的序列信息是否保留,如果It全为1,则说明当前时间步token的序列信息是有用的(候选记忆单元记录当前时间步token的序列信息和前t-1个时间步的序列信息),保留下来加入到记忆单元Ot中;如果It全为0,则说明当前时间步token的序列信息是没有用的,丢弃当前token的序列信息,直接使用上一个时间步的记忆单元Ot-1作为当前的记忆单元Ot(记录迄今t为止长序列信息)。(Ot-1仅包含之前的长序列信息,不包含当前一个时间步的序列信息)
下图形象的展示了遗忘门和输入门的作用:
LSTM 3D视频讲解链接
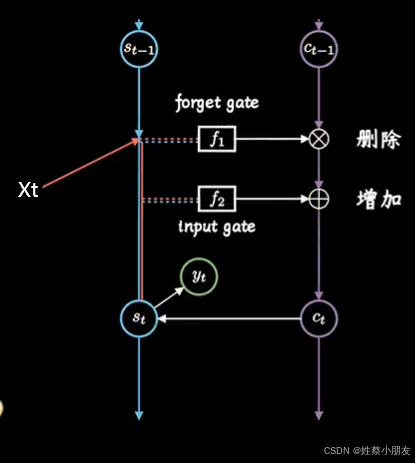
注意GRU中的遗忘门和输入门是对Ht的修改,而LSTM中的遗忘门和输入门是对Ct的修改。
注意记忆单元Ct输出范围是[-2,2]
2.2隐藏状态Ht:
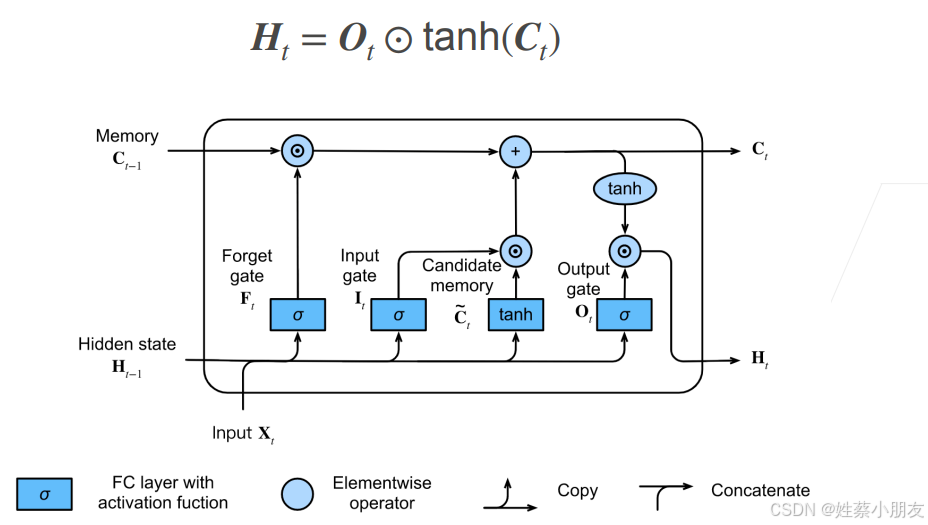
因为Ct是一个[-2,2] 之间的量,为了保证Ht的输出范围,所以需要取tan将Ct变为[-1,1]的范围内。
因为Ot是一个[0,1]之间的量,所以输出门的主要作用是控制当前隐藏状态Ht(记录短期序列信息)的输出,即决定从记忆单元Ot(记录长期序列信息)中传递多久的序列信息给Ht。
3.LSTM:
LSTM网络架构如下,可以看做是四个隐藏层并排的架构。
LSTM不仅循环隐藏状态Ht,还循环记忆单元Ct,其中Ct和Ht分别保存长、短期序列信息,这也是长短期记忆网络的由来。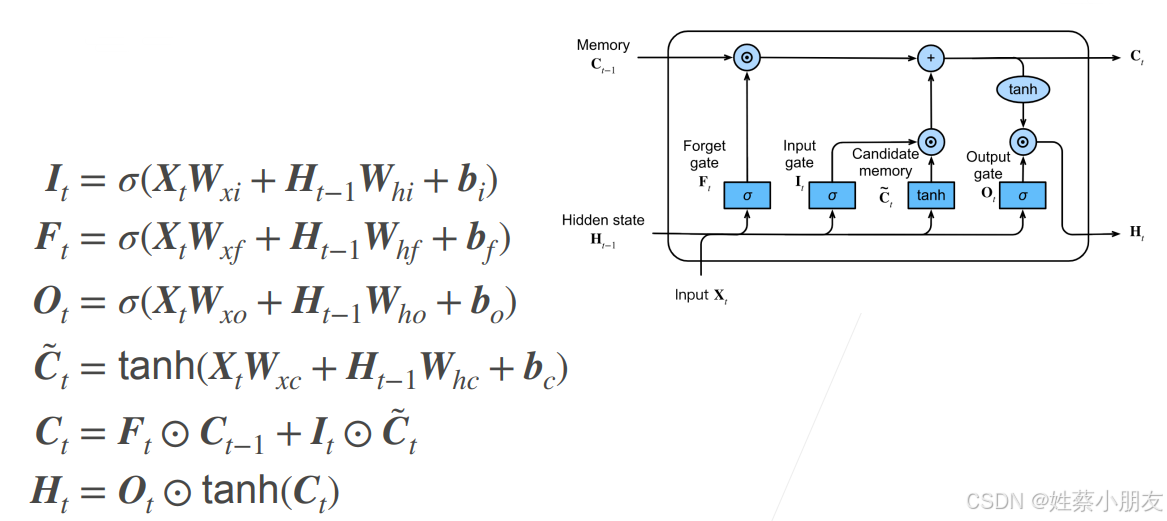
四、训练过程举例******:
以下文预测问题为例,一次epoch训练过程如下。
1.对整个文本进行数据预处理,获得数据字典,这里假设字典中有vocab_size条字典序,这样就转换成了一个vocab_size分类的序列问题。
2.将每个单词token值使用独热编码转换成1×vocab_size的一维向量,作为特征,表示各分类上的概率。
3.每轮epoch输入格式为batch_num×batch_size×num_steps×vocab_size,其中batch_num表示该轮压迫训练多少个batch,batch_size表示每个batch中有多少个句子序列,每个句子有num_steps个单词token,即该batch要训练多少个时间步,即循环time_step次传统神经网络,每个单词为一个一维向量,表示在字典序上的概率。每次训练一个batch,每个时间步t使用该batch中所有batch_size个序列的第t个token集合Xt进行训练(num_steps=t的token),batch尺寸为batch_size×num_steps×vocab_size,Xt尺寸为batch_size×vocab_size。
4.隐藏层参数Whh维度为num_hiddens×num_hiddens,表示隐藏层关于序列信息(隐藏状态)的权重矩阵;Whx维度为vocab_size×num_hiddens,表示隐藏层关于输入特征的权重矩阵;参数bh维度为1×num_hiddens。
5.四个并行隐藏层各自的参数Whi、Whf、Who、Whc维度计算为num_hiddens×num_hiddens,表示隐藏层关于序列信息(隐藏状态)的权重矩阵;四个并行隐藏层各自的参数Wxi、Wxf、Wxo、Wxc维度计算为vocab_size×num_hiddens,表示隐藏层关于输入特征的权重矩阵;参数bi、bf、bo、bc维度计算为1×num_hiddens。这里由于四个隐藏层输出维度相同,所以隐藏内的神经元数目都是相同的=num_hiddens。
6.对于第一个batch,训练过程如下:
6.1.初始化0时刻短序列信息h0,尺寸为(batch_size,神经元个数num_hiddens)。
6.2.初始化0时刻长序列信息C0,尺寸为(batch_size,神经元个数num_hiddens)。
6.3.t1时间步num_steps=1,取该batch所有序列样本的第一个token组成x0,尺寸batch_size×vocab_size,每个vocab一维向量并行放入神经网络学习,首先x0中每个token和ho同时进入遗忘门隐藏层、输入门隐藏层、输出门隐藏层和候选记忆单元隐藏层,输入门隐藏层输出I1=sigmoid(Whi×h0+Wxi×x0+bi)、遗忘门隐藏层输出F1=sigmoid(Whf×h0+Wxf×x0+bf)、输出门隐藏层输出O1=sigmoid(Who×h0+Wxo×x0+bo)、候选记忆单元隐藏层C~1=sigmoid(Whc×h0+Wxc×x0+bc),四个隐藏层分别用来筛选Ct和Ht序列信息,输出维度均为batch_size×num_hiddens。
6.4.F1、I1、C~1和记忆单元C0联合计算,使用遗忘门对过去的序列信息进行筛选、使用输入门对当前的序列信息进行筛选,计算出当前时间步的记忆单元C1。
6.5.O1、当前时间步记忆单元C1联合计算,使用输出门对长序列信息C1进行筛选,计算出当前时间步的隐藏状态h1,隐藏层输出维度batch_size×num_hiddens,h1作为t1时间步的输出层输入、t2时间步的隐藏层输入序列信息(隐藏状态)。
6.6.此时两个操作并行执行:t1时间步的输出层计算、t2时间步的隐藏层计算。
6.6.1首先h1和C1作为t1时间步的输出层输入,输出层有vocab_size个神经元,会执行多分类预测,可学习参数为Woh(num_hiddens×vocab_size)和bo(1×vocab_size),每个token输出维度1×vocab_size,输出层输出维度batch_size×vocab_size,表示各个token在各个分类上的预测。
6.6.2其次,t2时间步num_steps=2,取batch中num_steps=2的token集合为x1,维度为batch_size×vocab_size,并行将每个token一维向量放入神经网络学习,隐藏层输出h2=…,记忆单元C2=…,隐藏层输出维度batch_size×num_hiddens,h2和C2作为t2时间步的输出层输入、t3时间步的隐藏层输入序列信息。
6.7.如此反复每个时间步取一个数据点token集合进行训练,并更新隐藏层输出ht和Ct作为下一个时间步的输入,直到完成所有num_steps个时间步的训练任务,整个batch就训练完成了。
6.8.对于每个时间步上的预测batch_size×vocab_size,num_steps个时间步上总的预测为(num_steps×batch_size,vocab_size),这是该batch的训练总输出。
6.9.使用损失函数计算batch中各个句子中每个token的概率损失,并取均值。
6.10.反向传播算法计算各个参数关于损失函数的梯度。
6.11.梯度裁剪修改梯度。
6.12.梯度下降算法修改参数值。
7.该batch训练完成。进行下一个batch训练,初始化隐藏状态h0、C0…。
五、预测过程举例******:
背景定义同训练过程,模型的预测过程如下。
1.输入prefix长度的前缀,来预测接下来num_preds个token。
2.首先还是将prefix转换成字典序并进行独热编码,尺寸为1×prefix×vocab_size,其中prefix=num_steps。
3.加载模型,初始化时序信息h0\、C0。
4.batch_size为1,在每个时间步上对句子长度每个token一维向量依次作为模型一个时间步的输入,输入维度1×vocab_size,总共计算prefix个时间步,循环计算prefix个时间步后的时序信息hp、Cp,hp和、Cp尺寸为1×num_hiddens(batch_size=1)。
5.将prefix最后一个token和hp、Cp作为模型输入,来预测num_preds个token的第一个token,输出预测结果pred1和时序信息hp1、Cp1,然后将pred1和hp1、Cp1作为输入预测pred2和hp2、Cp2(即使用预测值来预测下一个预测值),直到预测num_preds个预测值。(等价于batch=1,num_steps=num_preds的训练过程)
6.将预测值使用字典转为字符串输出。
六、底层源码:
代码中num_hiddens表示隐藏层神经元个数,由于遗忘门、输入门、输出门的输出维度相同,所以三个隐藏层的神经元个数也是一样的=num_hiddens。
并且除了初始化隐藏状态Ht外,还需要初始化记忆单元Ct。
import torch from torch import nn from d2l import torch as d2l # 数据预处理,获取datalodaer和字典 batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) # 初始化可学习参数 def get_lstm_params(vocab_size, num_hiddens, device): num_inputs = num_outputs = vocab_size def normal(shape): return torch.randn(size=shape, device=device) * 0.01 def three(): return (normal( (num_inputs, num_hiddens)), normal((num_hiddens, num_hiddens)), torch.zeros(num_hiddens, device=device)) W_xi, W_hi, b_i = three() W_xf, W_hf, b_f = three() W_xo, W_ho, b_o = three() W_xc, W_hc, b_c = three() W_hq = normal((num_hiddens, num_outputs)) b_q = torch.zeros(num_outputs, device=device) params = [ W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] for param in params: param.requires_grad_(True) return params # 初始化隐藏状态Ht和记忆单元Ct def init_lstm_state(batch_size, num_hiddens, device): return (torch.zeros((batch_size, num_hiddens), device=device), torch.zeros((batch_size, num_hiddens), device=device)) # 定义LSTM模型 def lstm(inputs, state, params): [ W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params (H, C) = state outputs = [] for X in inputs: I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i) F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f) O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o) C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c) C = F * C + I * C_tilda H = O * torch.tanh(C) Y = (H @ W_hq) + b_q outputs.append(Y) return torch.cat(outputs, dim=0), (H, C) #训练 vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu() num_epochs, lr = 500, 1 model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params, init_lstm_state, lstm) d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device) 七、Pytorch版代码:
num_inputs = vocab_size lstm_layer = nn.LSTM(num_inputs, num_hiddens) model = d2l.RNNModel(lstm_layer, len(vocab)) model = model.to(device) d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device) 