阅读量:0
Python爬虫:下载人生格言
爬取网页

将这些格言下载存储到本地
代码:
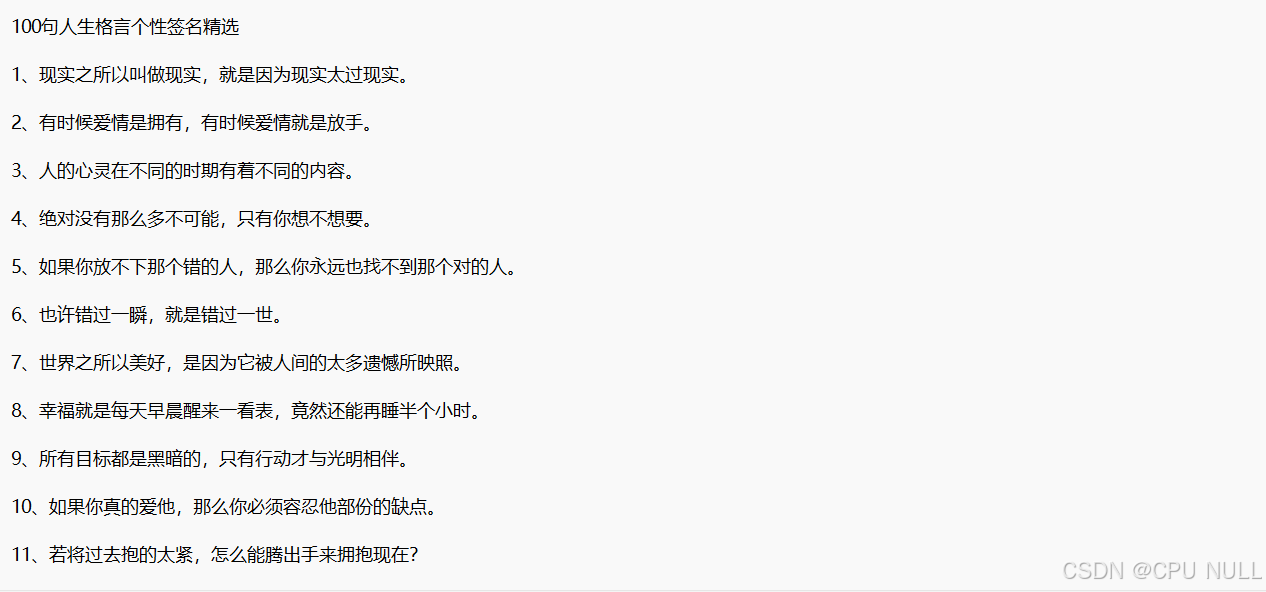
import requests #导入requests库,用于提取网页 from lxml import etree#导入lxml库,用于Xpath数据解析 #请求头 header={ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0' }#每个浏览器的user-agent不一样,在浏览器中查找 url="http://m.3chongmen.com/renshenggeyan/162.html"#请求网址 res1=requests.get(url=url,headers=header).text html=etree.HTML(res1) title=html.xpath('//div[@class="title"]/h1/text()')[0]#数据解析,提取标题 content=html.xpath('//div[@class="content"]/text()')#数据解析,提取内容 content="".join(content) print(title) print(content) 运行结果:
分析:
- 导入requests库
requests库是第三方库,要提前安装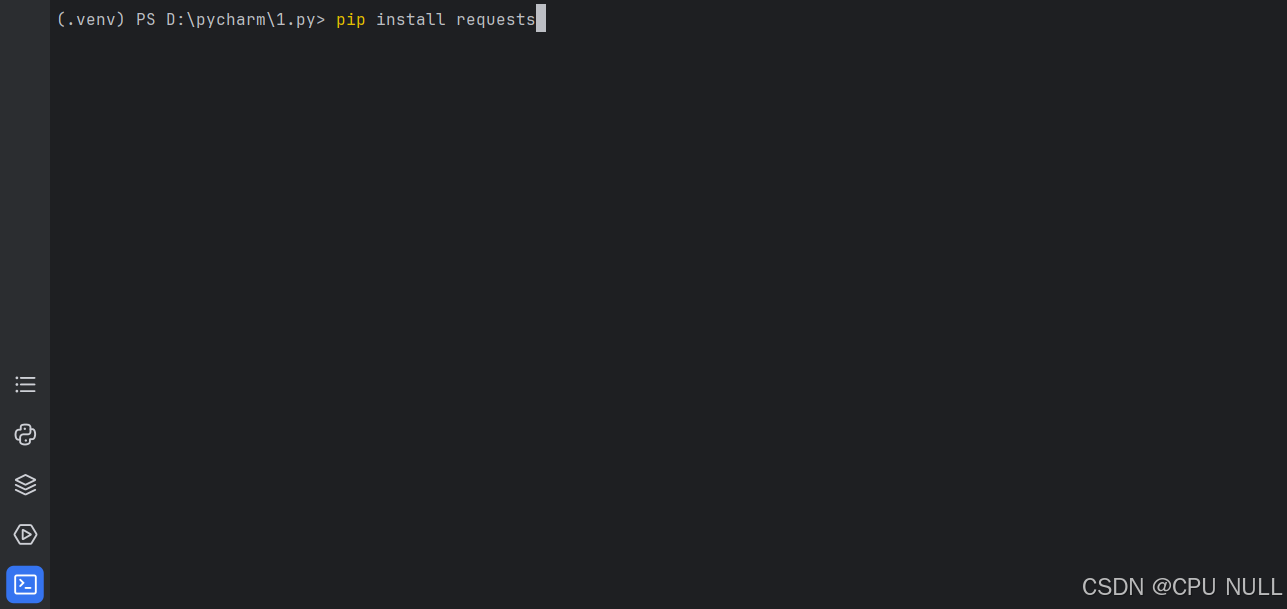
输入指令进行安装
pip install requests *导入lxml库
输入指令
pip install lxml headers
最简单的只用加上user-agent就可以了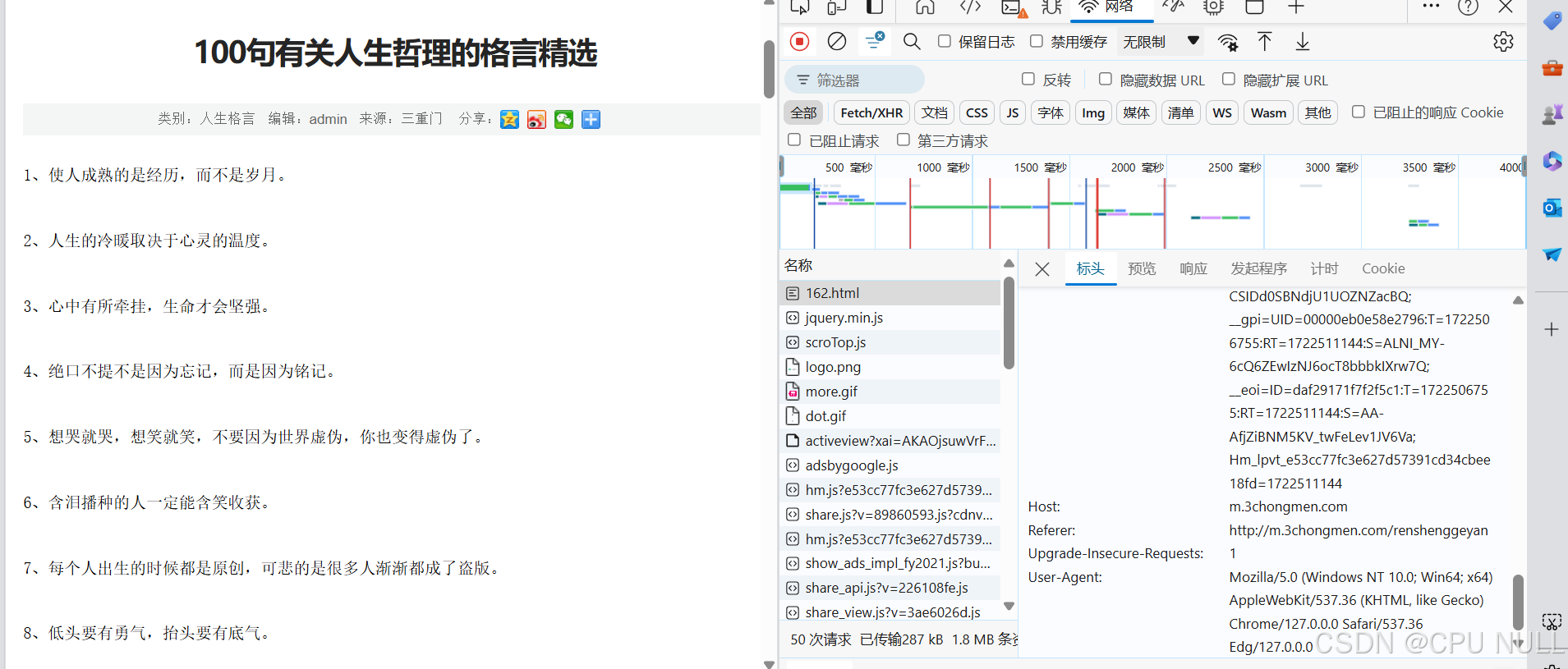
鼠标右键,选择”检查“,点击”网络“,ctrl+R刷新页面,点击第一份文件,点击”标头“,滑到最下方查找”User-Agent“,复制到pycharm中即可数据解析Xpath
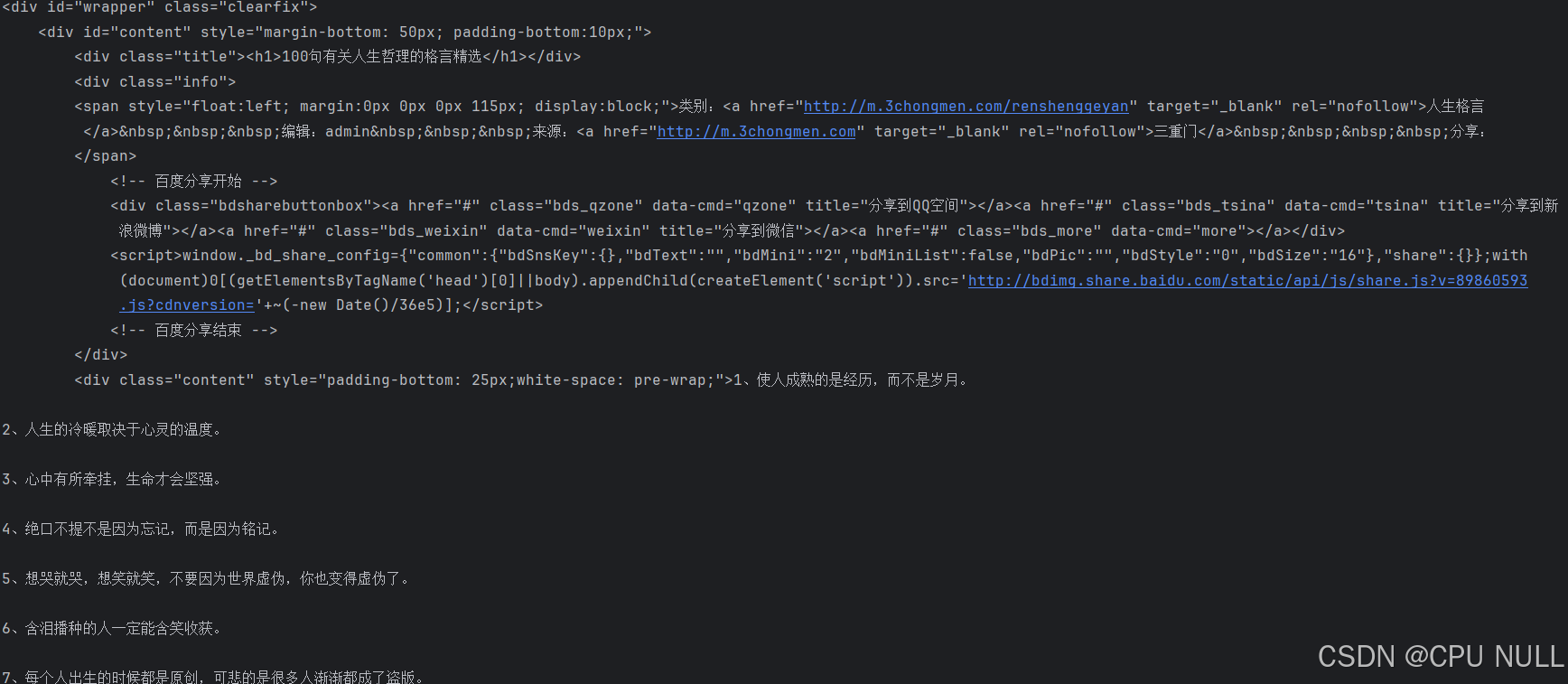
用requets获取的源代码如图,想要的信息就在这里面,我们需要提取出来,因此就要用到Xpath进行解析,要先学习一下Xpath语法和lxml库的使用,可以在网上查找相关资料
拓展
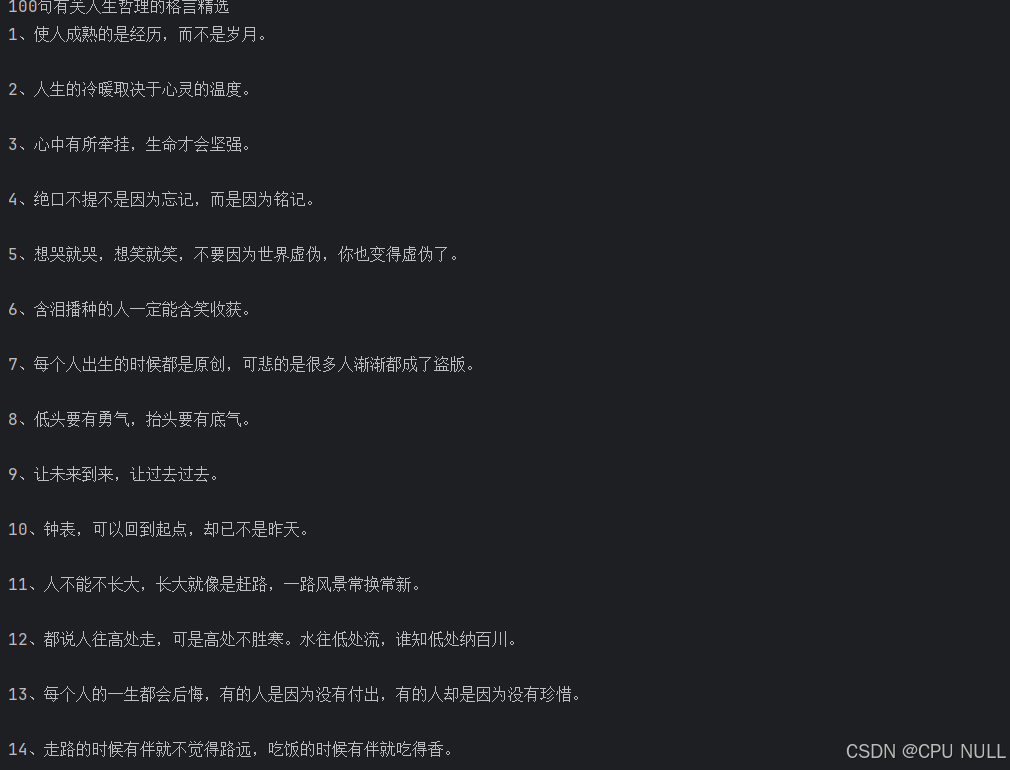
将目录下的所有人生格言提取并保存在本地
代码
import requests from lxml import etree header={ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0' } def spider(url): res1=requests.get(url=url,headers=header).text html=etree.HTML(res1) content=html.xpath('//div[@class="content"]/text()') content="".join(content) title=html.xpath('//div[@class="title"]/h1/text()')[0] return title,content url1="http://m.3chongmen.com/renshenggeyan" res=requests.get(url=url1,headers=header).text html=etree.HTML(res) links=html.xpath('//ul[@class="list_cnt"]//a[@target="_blank"]/@href') for link in links: title,content=spider(link) with open(f'格言/{title}.txt','w',encoding='utf-8') as f: f.write(title+'\n\n') f.write(content) 运行结果: