
阅读量:0
Stable Diffusion之最全详解图解

1. Stable Diffusion介绍
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。
它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络之一。它是由初创公司StabilityAI、CompVis与Runway合作开发,并得到EleutherAI和LAION的支持。 截至2022年10月,StabilityAI筹集了1.01亿美元的资金。
Stable Diffusion的源代码和模型权重已分别公开发布在GitHub和Hugging Face,可以在大多数配备有适度GPU的电脑硬件上运行。而以前的专有文生图模型(如DALL-E和Midjourney)只能通过云计算服务访问。
1.1 研究背景
AI 绘画作为 AIGC(人工智能创作内容)的一个应用方向,它绝对是 2022 年以来 AI 领域最热门的话题之一。AI 绘画凭借着其独特创意和便捷创作工具迅速走红,广受关注。举两个简单例子,左边是利用 controlnet 新魔法把一张四个闺蜜在沙滩边上的普通合影照改成唯美动漫风,右边是 midjourney v5 最新版本解锁的逆天神技, 只需输入文字“旧厂街风格,带着浓浓 90 年代氛围感”即可由 AI 一键生成超逼真图片!
Stable Diffusion,是一个 2022 年发布的文本到图像潜在扩散模型,由 CompVis、Stability AI 和 LAION 的研究人员创建的。要提到的是,Stable Diffusion 技术提出者 StabilityAI 公司在 2022 年 10 月完成了 1.01 亿美元的融资,估值目前已经超过 10 亿美元。
1.2 学术名词
| 学术名词 | 相关解释 |
|---|---|
| Diffusion Model | 扩散模型,一款支持文本生成图像的算法模型,目前市面上主流的 DALL E、Midjourney、Stable Diffusion 等 AI 绘画工具都是基于此底层模型开发的 |
| Latent Diffusion Model | 即潜在扩散模型,基于上面扩散模型基础上研制出的更高级模型,升级点在于图像图形生成速度更快,而且对计算资源和内存消耗需求更低 |
| Stable Diffusion | 简称SD模型,其底层模型就是上面的潜在扩散模型,之所以叫这个名字是因为其研发公司名叫Stability AI,相当于品牌冠名了 |
| Stable Diffusion Web Ul | 简称SD WebUI,用于操作上面Stable Diffusion模型的网页端界面,通过该操作系统就能控制模型出图,而无需学习代码 |
2.Stable Diffusion原理解析
2.1 技术架构
Stable Diffusion是一种扩散模型(diffusion model)的变体,叫做“潜在扩散模型”(latent diffusion model; LDM)。扩散模型是在2015年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。Stable Diffusion由3个部分组成:变分自编码器(VAE)、U-Net和一个文本编码器。与其学习去噪图像数据(在“像素空间”中),而是训练VAE将图像转换为低维潜在空间。添加和去除高斯噪声的过程被应用于这个潜在表示,然后将最终的去噪输出解码到像素空间中。在前向扩散过程中,高斯噪声被迭代地应用于压缩的潜在表征。每个去噪步骤都由一个包含ResNet骨干的U-Net架构完成,通过从前向扩散往反方向去噪而获得潜在表征。最后,VAE解码器通过将表征转换回像素空间来生成输出图像。研究人员指出,降低训练和生成的计算要求是LDM的一个优势。
去噪步骤可以以文本串、图像或一些其他数据为条件。调节数据的编码通过交叉注意机制(cross-attention mechanism)暴露给去噪U-Net的架构。为了对文本进行调节,一个预训练的固定CLIP ViT-L/14文本编码器被用来将提示词转化为嵌入空间。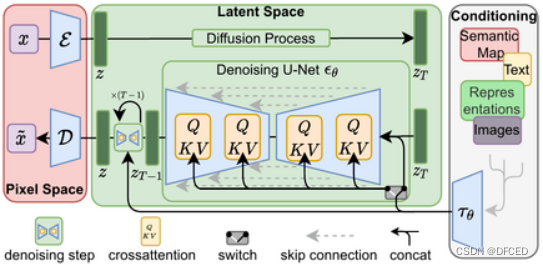
(以上图片来自于网络)
2.2 原理介绍
Stable Diffusion 技术,作为 Diffusion 改进版本,通过引入隐向量空间来解决 Diffusion 速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者上色任务。作为一篇基础原理介绍,这里着重解析最常用的“文生图(text to image)”为主线,介绍 stable diffusion 计算思路以及分析各个重要的组成模块。
下图是一个基本的文生图流程,把中间的 Stable Diffusion 结构看成一个黑盒,那黑盒输入是一个文本串“paradise(天堂)、cosmic(广阔的)、beach(海滩)”,利用这项技术,输出了最右边符合输入要求的生成图片,图中产生了蓝天白云和一望无际的广阔海滩。
Stable Diffusion 组成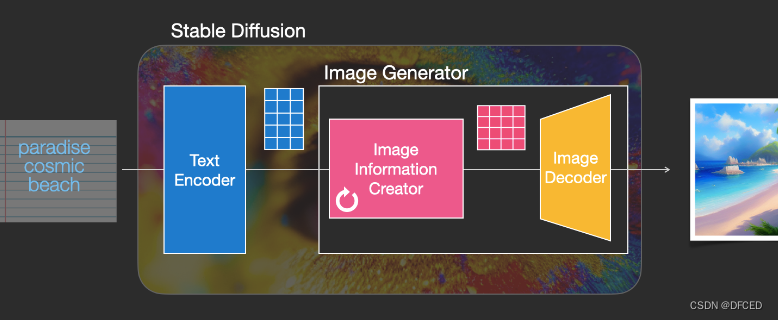
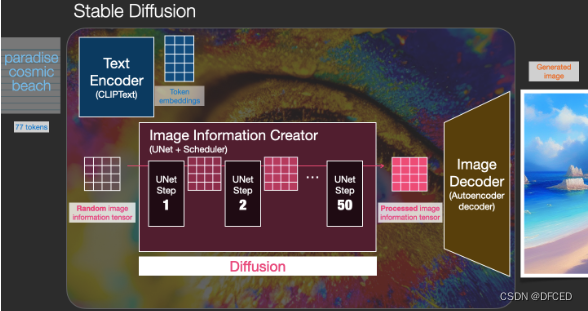
Stable Diffusion 的核心思想是,由于每张图片满足一定规律分布,利用文本中包含的这些分布信息作为指导,把一张纯噪声的图片逐步去噪,生成一张跟文本信息匹配的图片。它其实是一个比较组合的系统,里面包含了多个模型子模块,接下来把黑盒进行一步步拆解。stable diffusion 最直接的问题是,如何把人类输入的文字串转换成机器能理解的数字信息。这里就用到了文本编码器 text encoder(蓝色模块),可以把文字转换成计算机能理解的某种数学表示,它的输入是文字串,输出是一系列具有输入文字信息的语义向量。有了这个语义向量,就可以作为后续图片生成器 image generator(粉黄组合框)的一个控制输入,这也是 stable diffusion 技术的核心模块。图片生成器,可以分成两个子模块(粉色模块+黄色模块)来介绍。下面介绍下 stable diffusion 运行时用的主要模块:
1.文本编码器(蓝色模块),功能是把文字转换成计算机能理解的某种数学表示,在第三部分会介绍文本编码器是怎么训练和如何理解文字,暂时只需要了解文本编码器用的是 CLIP 模型,它的输入是文字串,输出是一系列包含文字信息的语义向量。
2.图片信息生成器(粉色模块) 是 stable diffusion 和 diffusion 模型的区别所在,也是性能提升的关键,有两点区别:
① 图片信息生成器的输入输出均为低维图片向量(不是原始图片),对应上图里的粉色 44 方格。同时文本编码器的语义向量作为图片信息生成器的控制条件,把图片信息生成器输出的低维图片向量进一步输入到后续的图片解码器(黄色)生成图片。(注:原始图片的分辨率为 512512,有RGB 三通道,可以理解有 RGB 三个元素组成,分别对应红绿蓝;低维图片向量会降低到 64*64 维度)
② Diffusion 模型一般都是直接生成图片,不会有中间生成低维向量的过程,需要更大计算量,在计算速度和资源利用上都比不过 stable diffusion;
那低维空间向量是如何生成的?是在图片信息生成器里由一个 Unet 网络和一个采样器算法共同完成,在 Unet 网络中一步步执行生成过程,采样器算法控制图片生成速度,下面会在第三部分详细介绍这两个模块。Stable Diffusion 采样推理时,生成迭代大约要重复 30~50 次,低维空间变量在迭代过程中从纯噪声不断变成包含丰富语义信息的向量,图片信息生成器里的循环标志也代表着多次迭代过程。
(3) 图片解码器(黄色模块) 输入为图片信息生成器的低维空间向量(粉色 4*4 方格),通过升维放大可得到一张完整图片。由于输入到图片信息生成器时做了降维,因此需要增加升维模块。这个模块只在最后阶段进行一次推理,也是获得一张生成图片的最终步骤。
扩散过程
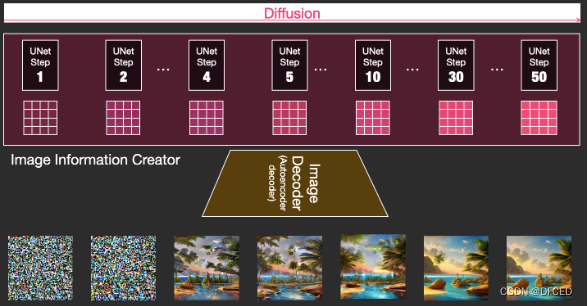
- 扩散过程发生在图片信息生成器中,把初始纯噪声隐变量输入到 Unet 网络后结合语义控制向量,重复 30~50 次来不断去除纯噪声隐变量中的噪声,并持续向隐向量中注入语义信息,就可以得到一个具有丰富语义信息的隐空间向量(右下图深粉方格)。采样器负责统筹整个去噪过程,按照设计模式在去噪不同阶段中动态调整 Unet 去噪强度。
- 更直观看一下,如下图 所示,通过把初始纯噪声向量和最终去噪后的隐向量都输到后面的图片解码器,观察输出图片区别。从下图可以看出,纯噪声向量由于本身没有任何有效信息,解码出来的图片也是纯噪声;而迭代 50 次去噪后的隐向量已经耦合了语义信息,解码出来也是一张包含语义信息的有效图片。
3.1 Diffusion前向过程

Diffusion的前向(q)和逆向§过程
特性1:重参数(reparameterization trick)

特性2:任意时刻的 xt可以由 x0 和 β表示

3.2 Diffusion逆向(推断)过程



