
阅读量:0
探索数据之间的奥秘:Neo4j图数据库引领新纪元
在数字化浪潮汹涌的今天,数据已成为企业最宝贵的资产之一。然而,随着数据量的爆炸性增长和数据关系的日益复杂,传统的关系型数据库在处理诸如社交网络、推荐系统、生物信息学等高度互联的数据时显得力不从心。Neo4j,作为图数据库领域的佼佼者,遥遥领先!

neo4j简介
- neo4j是由Java实现的开源NoSQL图数据库。自从2003年开始研发,到2007年发布第一版。neo4j现如今已经被各行各业的数十万家公司和组织采用。
neo4j实现了专业数据库级别的图数据模型的存储。与普通的图处理或内存级数据库不同,neo4j提供了完整的数据库特性,包括ACID事物的支持,集群支持,备份与故障转移等。这使其适合于企业级生产环境下的各种应用。
- neo4j的版本说明:
- 企业版:需要高额的付费获得授权,提供高可用,热备份等性能。
- 社区开源版:免费使用,但只能单点运行。
neo4j图数据库概念
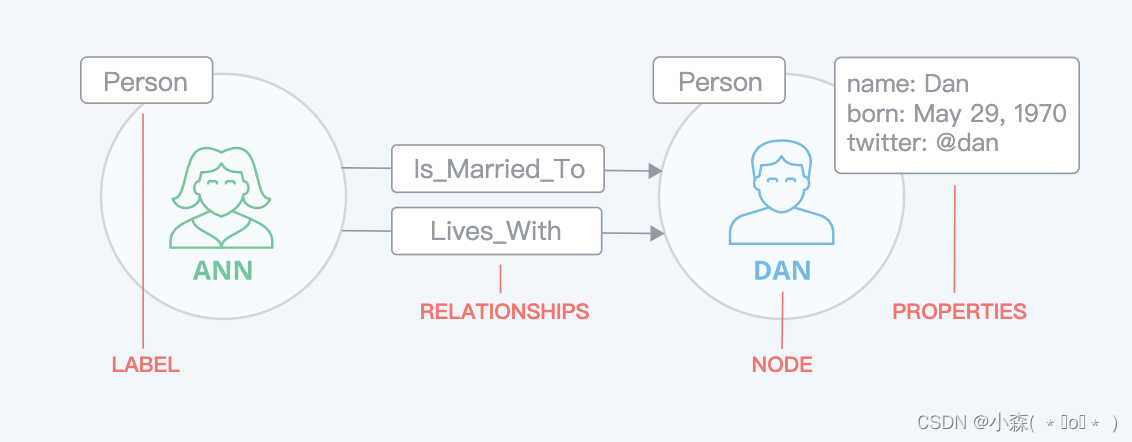
✨️节点:节点是Neo4j图数据库中的基本元素,用于表示实体或对象。每个节点都可以看作是一个独立的实体,如一个人、一部电影或一个城市。
- 可以将节点类比为关系型数据库中的表,对应的标签可以类比为不同的表名,属性就是表中的列。
✨️属性:属性是附加在节点或关系上的键值对,用于描述节点或关系的详细特征。
✨️关系:关系连接两个节点,关系是方向性的,关系可以有一个或多个属性
✨️标签:标签是Neo4j中对节点进行分类和组织的一种方式,类似于关系型数据库中的表名。
neo4j图数据库的安装
neo4j图数据库的安装流程:
第一步:将neo4j安装信息载入到yum检索列表。
第二步:使用yum install命令安装。
第三步:修改配置文件内容 /etc/neo4j/neo4j.conf.
第四步:启动neo4j数据库。
💦第一步:将neo4j安装信息载入到yum检索列表
sudo rpm --import https://debian.neo4j.com/neotechnology.gpg.key sudo yum-config-manager --add-repo https://yum.neo4j.com/stable 💦第二步:使用yum install命令安装
yum install neo4j💦第三步:修改配置文件默认在/etc/neo4j/neo4j.conf
dbms.directories.data=/var/lib/neo4j/data dbms.directories.plugins=/var/lib/neo4j/plugins dbms.directories.certificates=/var/lib/neo4j/certificates dbms.directories.logs=/var/log/neo4j dbms.directories.lib=/usr/share/neo4j/lib dbms.directories.run=/var/run/neo4j # 导入的位置 dbms.directories.import=/var/lib/neo4j/import # 初始化内存大小 dbms.memory.heap.initial_size=512m # web页面地址 dbms.connectors.default_listen_address=0.0.0.0 # HTTP Connector. There can be zero or one HTTP connectors. dbms.connector.http.enabled=true dbms.connector.http.listen_address=:7474 # HTTPS Connector. There can be zero or one HTTPS connectors. dbms.connector.https.enabled=true dbms.connector.https.listen_address=:7473 dbms.connector.bolt.enabled=true dbms.connector.bolt.listen_address=:7687💦第四步:启动neo4j数据库
# 启动命令 neo4j start- 注意:如果使用的是云服务器,那么上述用到了7473端口、7687端口、就需要单独去开端口。
neo4j的可视化管理后台登陆
(云服务器公网IP):7474 --> 进入浏览器界面

🧨Cypher介绍与使用
Cypher是一种描述性的图形查询语言,相当于MySQL中的SQL语句。
create命令
💯创建图数据中的节点
# 创建命令格式: # create是关键字,创建节点名称node_name, 节点标签Node_Label, 放在小括号里面() # 后面把所有属于节点标签的属性放在大括号'{}'里面,依次写出属性名称:属性值,不同属性用逗号','分隔 # 例如下面命令创建一个节点e, 节点标签是Employee, 拥有id, name, salary, deptnp四个属性: CREATE (e:Employee{id:222, name:'Bob', salary:6000, deptnp:12})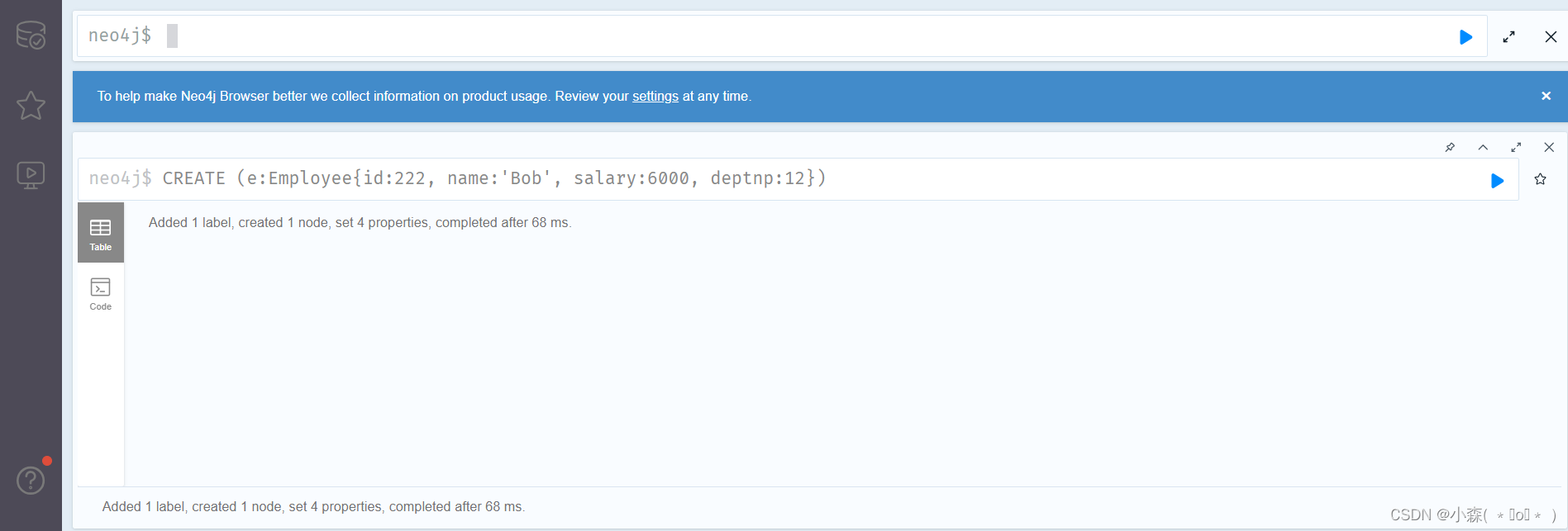
match命令
💯匹配(查询)已有数据
MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno MATCH (n) return n # 查询所有结点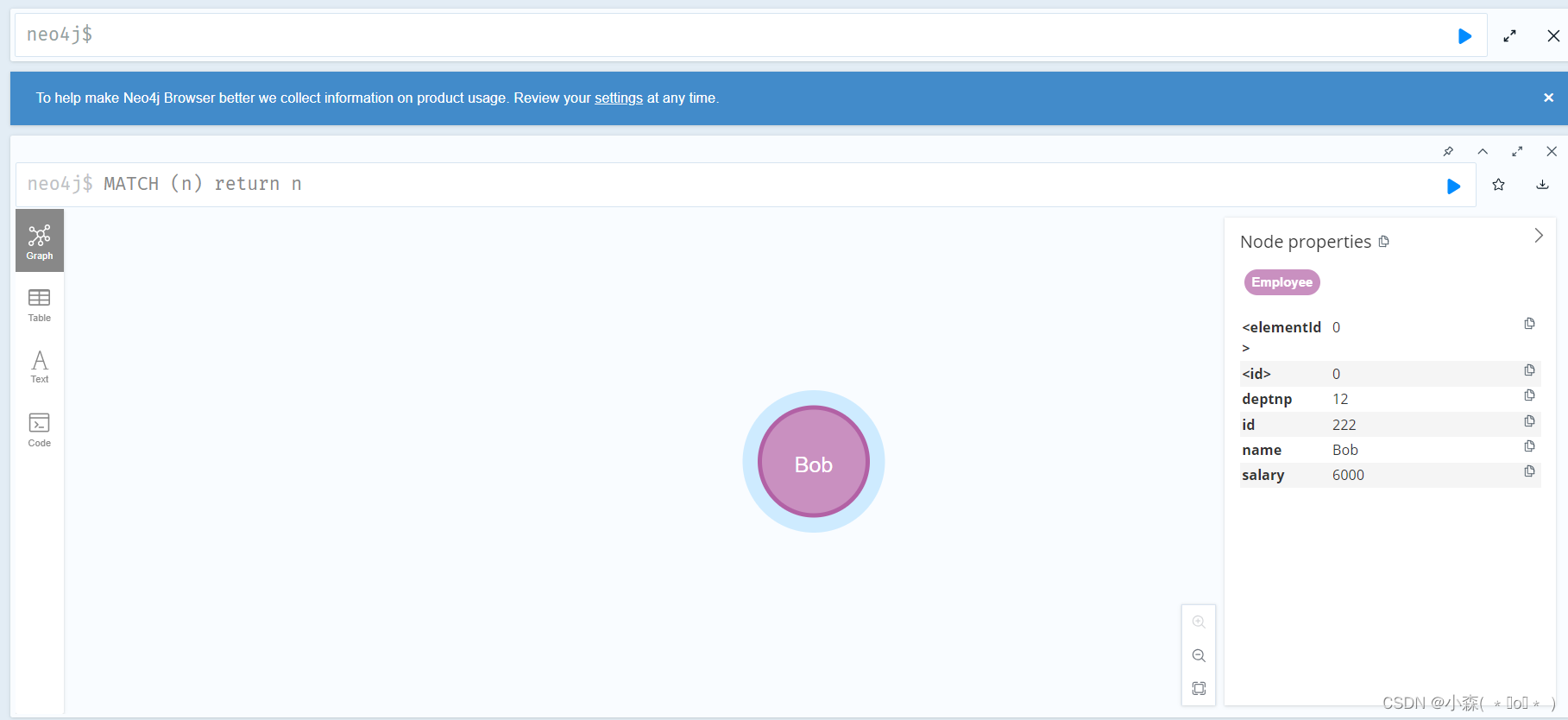
merge命令
💯若节点存在,则等效与match命令; 节点不存在,则等效于create命令。
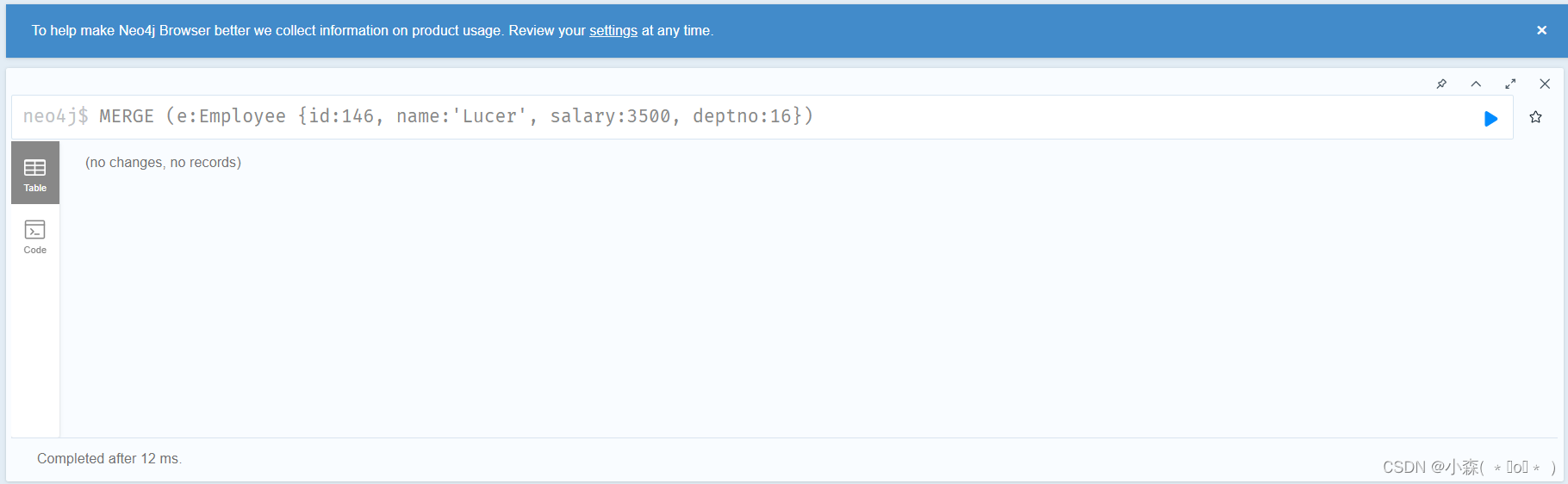
MERGE (e:Employee {id:146, name:'Lucer', salary:3500, deptno:16})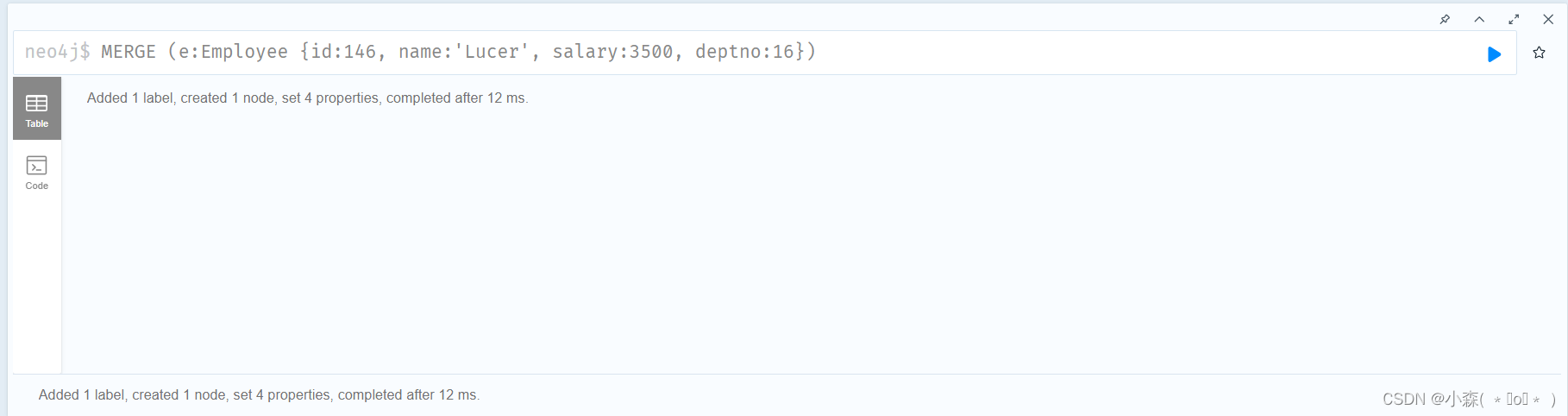
成功创建!
然后再次用merge查询,发现数据库中的数据并没有增加,因为已经存在相同的数据了,merge匹配成功。
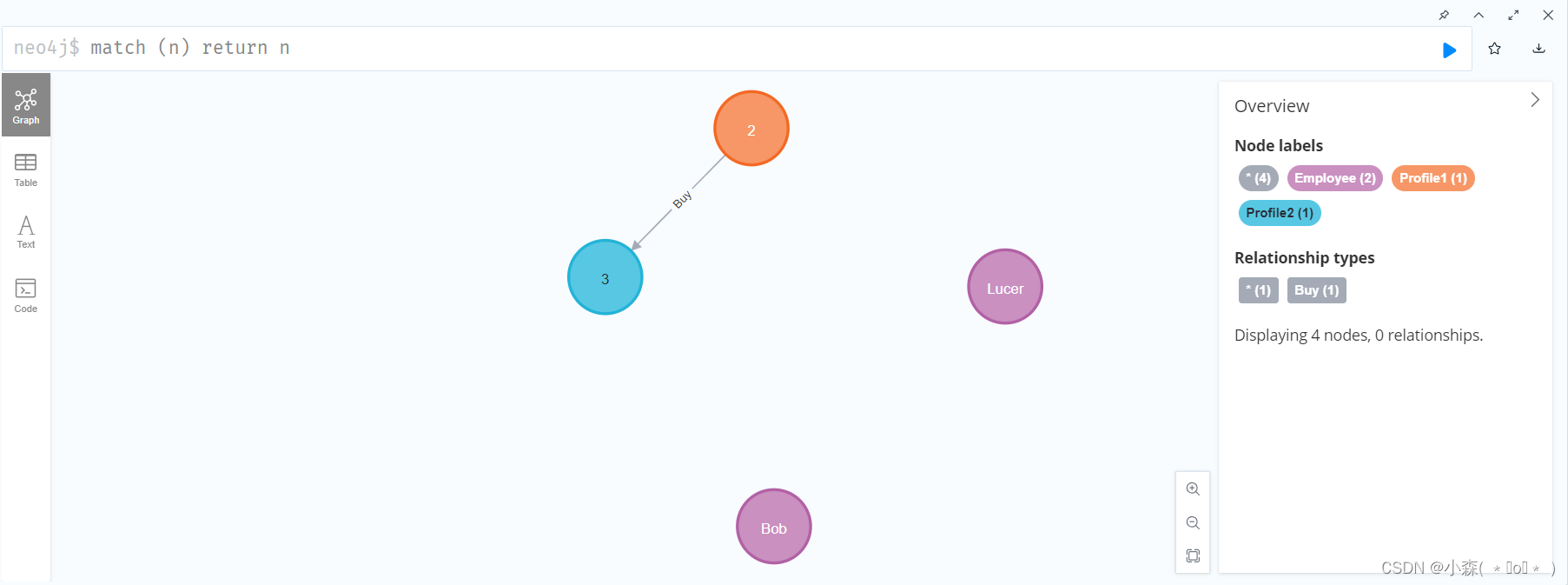
使用create创建关系
💯必须创建有方向性的关系,否则报错。
# 创建一个节点p1到p2的有方向关系,这个关系r的标签为Buy, 代表p1购买了p2, 方向为p1指向p2 CREATE (p1:Profile1)-[r:Buy]->(p2:Profile2)创建完成关系后,再次查看全部:
使用merge创建关系
💯可以创建有/无方向性的关系。
# 创建一个节点p1到p2的无方向关系,这个关系r的标签为miss, 代表p1-miss-p2, 方向为相互的 MERGE (p1:Profile1)-[r:miss]-(p2:Profile2)where命令
💯类似于SQL中的添加查询条件。
# 查询节点Employee中,id值等于123的那个节点 MATCH (e:Employee) WHERE e.id=123 RETURN edelete命令
💯删除节点/关系及其关联的属性。
# 注意:删除节点的同时,也要删除关联的关系边 MATCH (p1:Profile1)-[r]-(p2:Profile2) DELETE p1, r, p2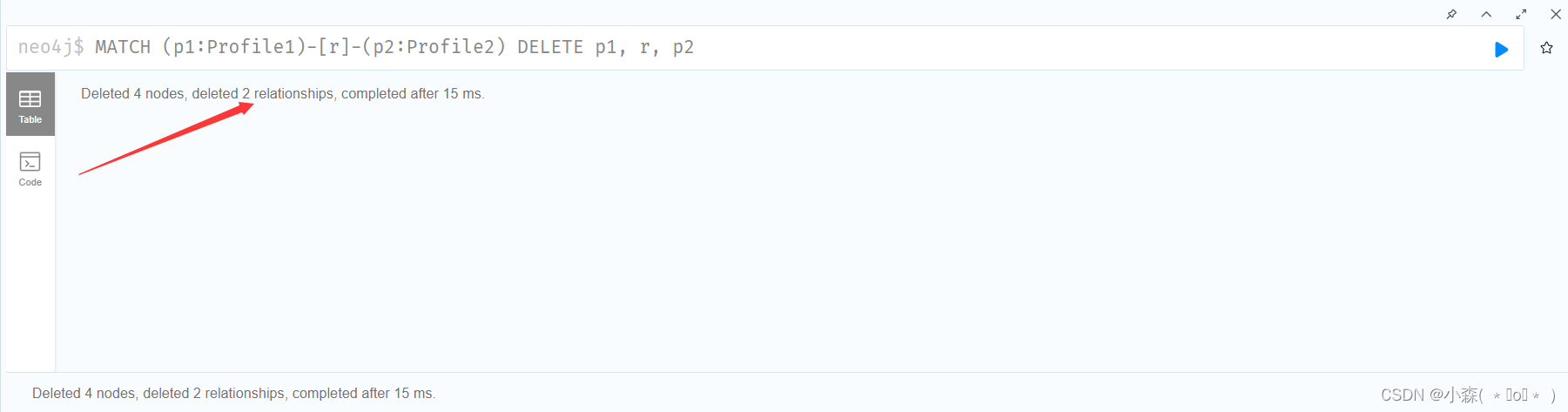
sort命令
Cypher命令中的排序使用的是order by
# 匹配查询标签Employee, 将所有匹配结果按照id值升序排列后返回结果 MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno ORDER BY e.id # 如果要按照降序排序,只需要将ORDER BY e.salary改写为ORDER BY e.salary DESC MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno ORDER BY e.salary DESC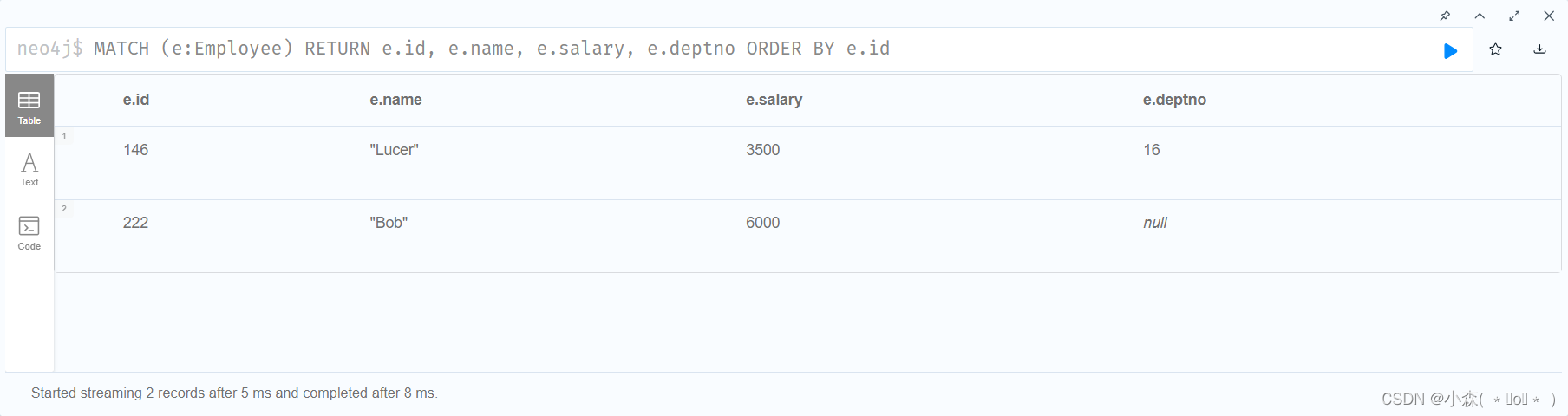
字符串函数:
- toUpper()函数
- toLower()函数
- substring()函数
- replace()函数
toUpper()函数
将一个输入字符串转换为大写字母。
- 演示:
MATCH (e:Employee) RETURN e.id, toUpper(e.name), e.salary, e.deptno 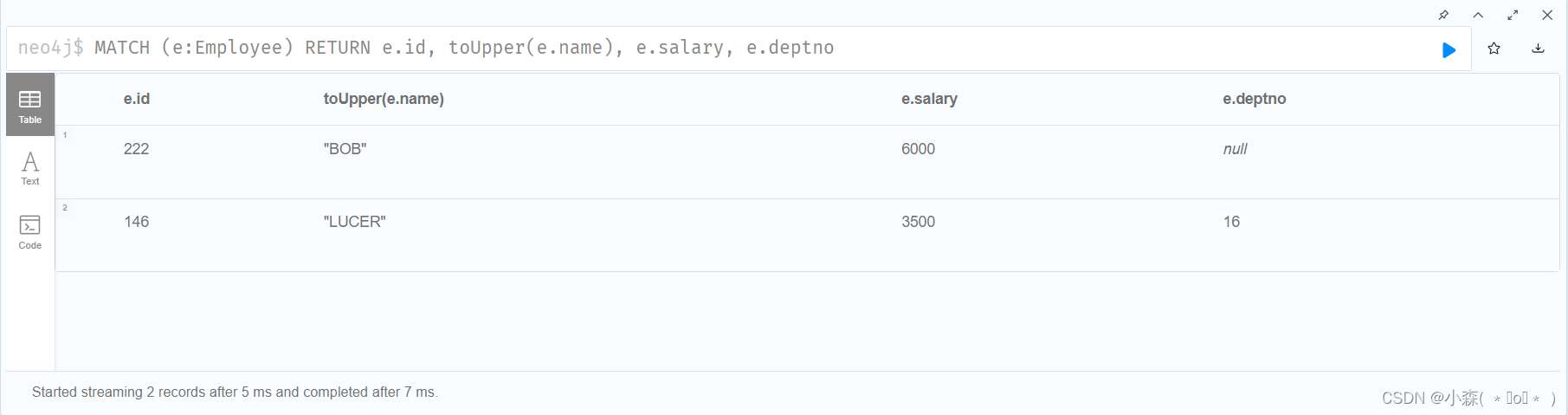
💩toLower()函数 :将一个输入字符串转换为小写字母。
💩substring()函数:返回一个子字符串。
💩replace()函数 :替换掉子字符串。
聚合函数
- count()函数
- max()函数
- min()函数
- sum()函数
- avg()函数
count()函数 :返回由match命令匹配成功的条数。
MATCH (e:Employee) RETURN count( * )
max()函数 :返回由match命令匹配成功的记录中的最大值。
# 返回匹配标签Employee成功的记录中,最高的工资数字 MATCH (e:Employee) RETURN max(e.salary)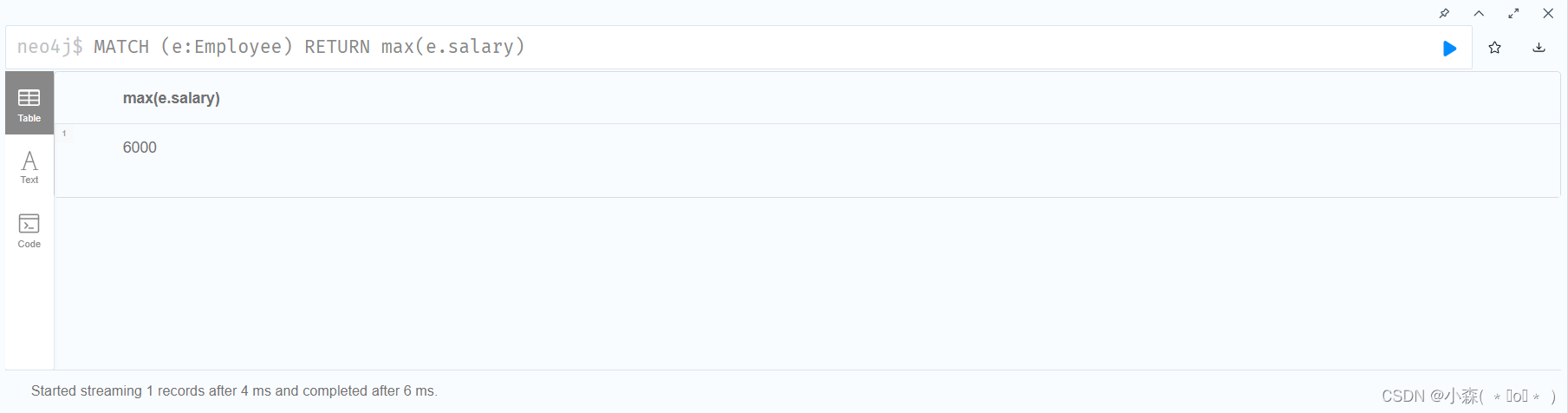
其余的就不过多赘述,相信大家也明白了~
索引index
- Neo4j支持在节点或关系属性上的索引,以提高查询的性能。
- 可以为具有相同标签名称的所有节点的属性创建索引。
创建索引:使用create index on来创建索引。
# 创建节点Employee上面属性id的索引 CREATE INDEX ON:Employee(id) 
在Python中使用neo4j
neo4j-driver是一个python中的package, 作为python中neo4j的驱动,帮助我们在python程序中更好的使用图数据库。
pip install neo4j-driver from neo4j import GraphDatabase uri = "bolt://localhost:7687" # Neo4j 数据库的 Bolt URI user = "neo4j" # 用户名 password = "你的密码" # 密码 driver = GraphDatabase.driver(uri, auth=(user, password)) def create_person(tx, name): """在 Neo4j 数据库中创建一个 Person 节点""" tx.run("CREATE (a:Person {name: $name})", name=name) with driver.session() as session: session.write_transaction(create_person, "Alice") session.write_transaction(create_person, "Bob") def get_person(tx, name): """查询并返回指定名称的 Person 节点""" result = tx.run("MATCH (a:Person {name: $name}) RETURN a.name AS name", name=name) return [record["name"] for record in result] with driver.session() as session: alice_name = session.read_transaction(get_person, "Alice") print(alice_name) # 输出: ['Alice'] driver.close() 