
阅读量:0
讲了很多理论,最后来一篇实践作为结尾。本次案例根据阿里云的博金大模型挑战赛的题目以及数据集做一次实践。
完整代码地址:https://github.com/forever1986/finrag.git
本次实践代码有参考:https://github.com/Tongyi-EconML/FinQwen/
目录
1 题目内容
根据原先的挑战赛,总结题目要求如下:
1)题目要求基于大模型构建一个问答系统
2)问答系统数据来源包括pdf文档和关系型数据库
3)回答内容可能是通过pdf获得内容,也可能需要先查询数据库,再根据获得的内容得到最终回答
该案例原先设计是为了“通义千问金融大模型”,我们这里只是为了展现一下RAG系统构建实战过程,因此不会一定使用“通义千问金融大模型”。
1.1 数据集说明
数据集下载地址:https://www.modelscope.cn/datasets/BJQW14B/bs_challenge_financial_14b_dataset/files
主要下载3部分
- pdf中的所有pdf文件
- dataset中的“博金杯比赛数据.db”
- question.json(这个是测试集问题)
简单来说就是回答question.json中的问题,问题的答案包括在pdf和db中,通过RAG形式获取最终答案。
2 设计思路
2.1 总体思路
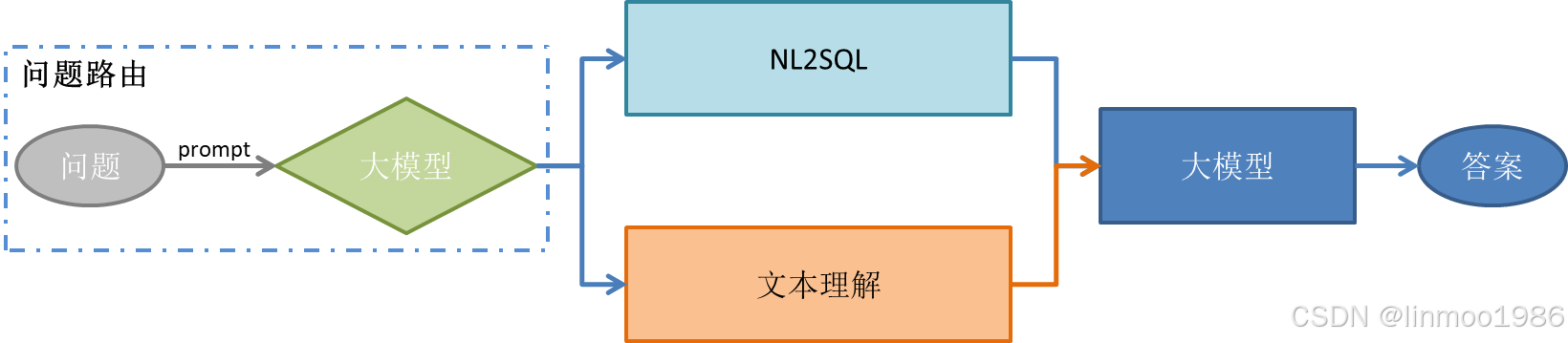
总体设计思路如下:
- 问题路由,从question.json可以得出问题的答案要么在PDF中,要么在DB中,因此要优先判断问题是查询PDF还是DB
- 文本理解,如果问题的答案来自PDF,那么就是走查询PDF的路径
- SQL查询,如果问题的答案来自DB,那么就走NL2SQL的路径
- 最终答案,根据查询结果,让大模型得出想要的答案格式
2.2 RAG应用点
- 文档处理:本次应用中,需要读取PDF数据,并进行检索。这里包括解析、分块、embedding、检索等。
- 查询结构内容:本次应用中,需要从DB数据库中进行SQL查询,因此包括Text-to-SQL等
- 路由:本次应用中,需要将问题分类到PDF或者DB,事实上就使用到了RAG的路由模块。
- 重排:本次应用中,为了提高准确率,通过检索得到的结果,进行重排后扔给大模型
2.3 代码地址
本次实践的代码地址已经上传github:https://github.com/forever1986/finrag.git
3 实现过程
3.1 问题路由
从question.json中将问题做一个路由。我们从检索增强生成RAG系列5–RAG提升之路由(routing)中总结的2种方式,Logical routing和Semantic routing,本案例中2种方式都可以采用。下面演示采用Logical routing的方式。
Logical routing其实就是采用prompt的方式,让大模型给出一个路由结果,这里我们也有2种方式可以选择:
- 提示词,当你的大模型参数量或者推理能力较强的时候,可以直接使用prompt+few shot方式
- 指令微调,通过给出一定数量(500个指令数据),对模型进行微调,比如通过公司名、问题模板等方式进行指令微调,让大模型具备分类能力
下面通过提示词和该案例的特点,进行问题路由。
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 提取pdf的公司名称,该案例特点就是pdf主要是公司的招股文书,而question.json中问题提及到公司名称,因此可以通过给prompt加上公司名称来提示大模型进行准确回答
import os import config import pandas as pd from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI # 初始化模型 llm = ChatOpenAI( temperature=0.95, model="glm-4", openai_api_key="你的API KEY", openai_api_base="https://open.bigmodel.cn/api/paas/v4/" ) df = pd.DataFrame(columns=['filename', 'company']) i = 1 for filename in os.listdir(config.text_files_path): if filename.endswith(".txt"): file_path = os.path.join(config.text_files_path, filename) with open(file_path, 'r', encoding='utf-8') as file: content = file.read() template = ChatPromptTemplate.from_template( "你是一个能精准提取信息的AI。" "我会给你一篇招股说明书,请输出此招股说明书的主体是哪家公司,若无法查询到,则输出无。\n" "{t}\n\n" "请指出以上招股说明书属于哪家公司,请只输出公司名。" ) chain = template | llm response = chain.invoke({"t": content[:3000]}) print(response.content) df.at[i, 'filename'] = filename df.at[i, 'company'] = response.content i += 1 df.to_csv(config.company_save_path) - 下面通过自定义agent和tool的方式进行问题路由,关键设计在于prompt中增加公司名称和few-shot方式,下面只是贴出主要流程的代码(全部代码可以下载全部代码)。
- 其中config、util.instances和util.prompts都是基础类
- pdf_retrieve_chain和sql_retrieve_chain是自定义的tool的function
import re from typing import Sequence, Union import pandas as pd from langchain.agents import AgentExecutor, AgentOutputParser from langchain.agents.chat.prompt import FORMAT_INSTRUCTIONS from langchain.agents.format_scratchpad import format_log_to_str from langchain.tools.render import render_text_description from langchain_core.agents import AgentAction, AgentFinish from langchain_core.language_models import BaseLanguageModel from langchain_core.prompts import BasePromptTemplate, ChatPromptTemplate from langchain_core.runnables import Runnable, RunnablePassthrough from langchain_core.tools import BaseTool, Tool import config from SQL_retrieve_chain import sql_retrieve_chain from util.instances import LLM from pdf_retrieve_chain import from util import prompts def create_react_my_agent( llm: BaseLanguageModel, tools: Sequence[BaseTool], prompt: BasePromptTemplate ) -> Runnable: # noqa: E501 missing_vars = {"tools", "tool_names", "agent_scratchpad"}.difference( prompt.input_variables ) if missing_vars: raise ValueError(f"Prompt missing required variables: {missing_vars}") # 读取公司名称 df = pd.read_csv(config.company_save_path) company_list = df['company'] company_content = '' for company in company_list: company_content = company_content + "\n" + company # print(company_content) prompt = prompt.partial( tools=render_text_description(list(tools)), tool_names=", ".join([t.name for t in tools]), company=company_content ) llm_with_stop = llm.bind(stop=["\n观察"]) temp_agent = ( RunnablePassthrough.assign( agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]), ) | prompt | llm_with_stop | MyReActSingleInputOutputParser() ) return temp_agent class MyReActSingleInputOutputParser(AgentOutputParser): def get_format_instructions(self) -> str: return FORMAT_INSTRUCTIONS def parse(self, text: str) -> Union[AgentAction, AgentFinish]: FINAL_ANSWER_ACTION = "Final Answer:" FINAL_ANSWER_AND_PARSABLE_ACTION_ERROR_MESSAGE = ( "Parsing LLM output produced both a final answer and a parse-able action:" ) includes_answer = FINAL_ANSWER_ACTION in text regex = ( r"Action\s*\d*\s*:[\s]*(.*?)[\s]*Action\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)" ) action_match = re.search(regex, text, re.DOTALL) if action_match: action = action_match.group(1).strip() action_input = action_match.group(2) tool_input = action_input.strip(" ") tool_input = tool_input.strip('"') return AgentAction(action, tool_input, text) elif includes_answer: return AgentFinish( {"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text ) else: return AgentFinish( {"output": text}, text ) @property def _type(self) -> str: return "react-single-input" auto_tools = [ Tool( name="招股说明书", func=pdf_retrieve_chain, description="招股说明书检索", ), Tool( name="查询数据库", func=sql_retrieve_chain, description="查询数据库检索结果", ), ] tmp_prompt = ChatPromptTemplate.from_template(prompts.AGENT_CLASSIFY_PROMPT_TEMPLATE) agent = create_react_my_agent(LLM, auto_tools, prompt=tmp_prompt) agent_executor = AgentExecutor( agent=agent, tools=auto_tools, verbose=True ) result = agent_executor.invoke({"question": "报告期内,华瑞电器股份有限公司人工成本占主营业务成本的比例分别为多少?"}) # result = agent_executor.invoke({"question": "请帮我计算,在20210105,中信行业分类划分的一级行业为综合金融行业中,涨跌幅最大股票的股票代码是?涨跌幅是多少?百分数保留两位小数。股票涨跌幅定义为:(收盘价 - 前一日收盘价 / 前一日收盘价)* 100%。"}) print(result["output"]) 3.2 文本理解
这部分分为2个阶段,第一个阶段是文档处理,第二部分是检索排序。在设计该模块时,我们在检索增强生成RAG系列3–RAG优化之文档处理中讲过解析、分块、embedding、向量数据库都对最终结果的准确度或者召回率会产生较大影响。但是实际实践中,如果按照普通方式进行解析、分块、embedding最终检索的准确率一定不高,因此在不同场景的应用中,需要做一些技巧性,从而提高最终检索召回率。
3.2.1 总体设计思路
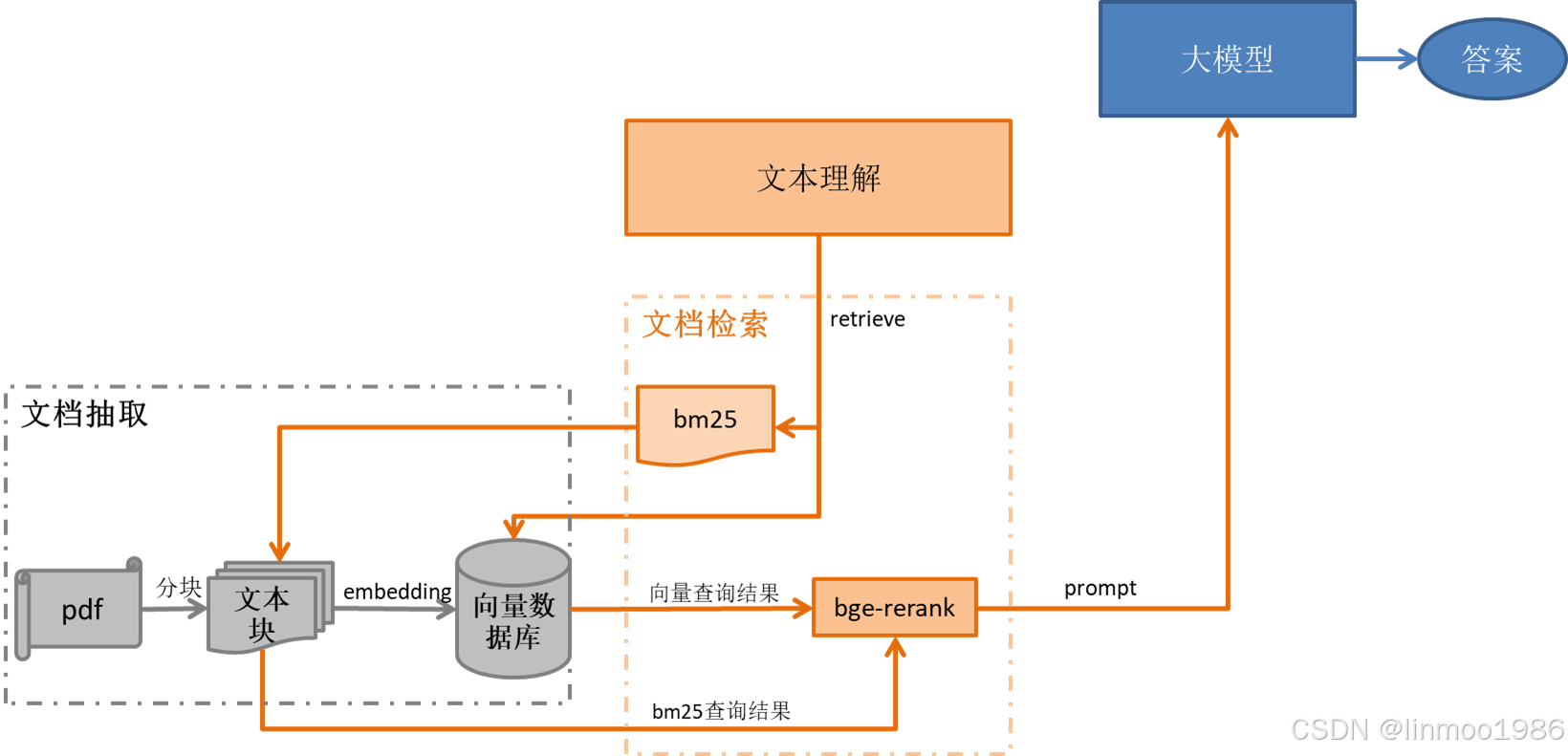
本案例是一个金融招股书的检索,每一份招股书都是对应一个公司,而question.json中对于检索招股书都会涉及公司名称,因此该部分的设计可以利用该特性进行设计
- 对pdf文档进行解析为txt,并以对应公司名称进行存储
- 分块,对文档进行2个层次分块,先进行较大长度分块,然后通过将较大长度的分块进行细分块,这样公司-大分块-小分块的映射关系,在检索的时候,可以通过公司进行匹配,在embedding中,可以通过小分块匹配后,找到大分块,这样增加上下文内容,从而提高召回率
- 通过问题与公司之间的匹配度,获得公司名称
- 通过双链路检索(稀疏BM25检索和密集embedding相似度检索),增加检索结果的准确率
- 通过重排,将2种查询结果进行重排,增加检索结果的准确率
3.2.2 文档抽取
对于本案例中,pdf的格式大致相同,而且主要包括文字和表格。在本次案例中尝试了一些开源的pdfplumber、pdfminer、gptpdf、RAGFlow等,说一下总结
- pdfplumber、pdfminer虽然能解析表格,但是对于一些特别的表格,比如该案例中一些没有左右边框的表格解析不好,另外一些换行也需要自己处理,一般都比较难处理好。
- RAGFlow解析效果不错,特别是表格和自动换行,但是也会出现部分问题解析错误的,但是整体效果比pdfplumber、pdfminer好很多。
- gptpdf通过截图+大模型的方式进行解析,首先是需要费用,其次尝试过chatgpt之外的模型(使用其它大模型需要改提示语、agent等),效果也很不好,另外它将图片、表格圈出来,再让大模型去识别图片和表格,经常会将表格上下的文本也圈进去。
下面代码是本次实践中使用pdfplumber方式进行解析,大概原理如下:
- 通过pdfplumber的find_tables获取表格
- 循环表格,获取表格之上的文字,获取表格的markdown格式
- 最后一个表格时,获取表格之下的文字
- 存在问题:部分没有左右边框的表格处理不好;没有实现较好的换行;页眉页尾等不相关内容未做处理;
import re import pdfplumber # 通过表格的top和bottom来读取页面的文章,通过3种情况 # 1) 第一种情况:top和bottom为空,则代表纯文本 # 2) 第二种情况,top为空,bottom不为空,则代表处理最后一个表格下面的文本 # 3) 第三种情况,top和bottom不为空,则代表处理表格上面的文本 def check_lines(page, top, bottom): try: # 获取文本框 lines = page.extract_words() except Exception as e: print(f'页码: {page.page_number}, 抽取文本异常,异常信息: {e}') return '' # empty util check_re = '(?:。|;|单位:元|单位:万元|币种:人民币)$' page_top_re = '(招股意向书(?:全文)?(?:(修订版)|(修订稿)|(更正后))?)' text = '' last_top = 0 last_check = 0 if top == '' and bottom == '': if len(lines) == 0: print(f'{page.page_number}页无数据, 请检查!') return '' for l in range(len(lines)): each_line = lines[l] # 第一种情况:top和bottom为空,则代表纯文本 if top == '' and bottom == '': if abs(last_top - each_line['top']) <= 2: text = text + each_line['text'] elif last_check > 0 and (page.height * 0.9 - each_line['top']) > 0 and not re.search(check_re, text): if '\n' not in text and re.search(page_top_re, text): text = text + '\n' + each_line['text'] else: text = text + each_line['text'] else: if text == '': text = each_line['text'] else: text = text + '\n' + each_line['text'] # 第二种情况,top为空,bottom不为空,则代表处理最后一个表格下面的文本 elif top == '': if each_line['top'] > bottom: if abs(last_top - each_line['top']) <= 2: text = text + each_line['text'] elif last_check > 0 and (page.height * 0.85 - each_line['top']) > 0 and not re.search(check_re, text): if '\n' not in text and re.search(page_top_re, text): text = text + '\n' + each_line['text'] else: text = text + each_line['text'] else: if text == '': text = each_line['text'] else: text = text + '\n' + each_line['text'] # 第三种情况,top和bottom不为空,则代表处理表格上面的文本 else: if top > each_line['top'] > bottom: if abs(last_top - each_line['top']) <= 2: text = text + each_line['text'] elif last_check > 0 and (page.height * 0.85 - each_line['top']) > 0 and not re.search(check_re, text): if '\n' not in text and re.search(page_top_re, text): text = text + '\n' + each_line['text'] else: text = text + each_line['text'] else: if text == '': text = each_line['text'] else: text = text + '\n' + each_line['text'] last_top = each_line['top'] last_check = each_line['x1'] - page.width * 0.83 return text # 删除没有数据的列 def drop_empty_cols(data): # 删除所有列为空数据的列 transposed_data = list(map(list, zip(*data))) filtered_data = [col for col in transposed_data if not all(cell == '' for cell in col)] result = list(map(list, zip(*filtered_data))) return result # 通过判断页面是否有表格 # 1) 如果没有表格,则按照读取文本处理 # 2) 如果有表格,则获取每个表格的top坐标和bottom坐标,按照表格顺序,先读取表格之上的文字,在使用markdown读取表格 # 3) 不断循环2),等到最后一个表格,只需要读取表格之下的文字即可 def extract_text_and_tables(page): all_text = "" bottom = 0 try: tables = page.find_tables() except: tables = [] if len(tables) >= 1: count = len(tables) for table in tables: # 判断表格底部坐标是否小于0 if table.bbox[3] < bottom: pass else: count -= 1 # 获取表格顶部坐标 top = table.bbox[1] text = check_lines(page, top, bottom) text_list = text.split('\n') for _t in range(len(text_list)): all_text += text_list[_t] + '\n' bottom = table.bbox[3] new_table = table.extract() r_count = 0 for r in range(len(new_table)): row = new_table[r] if row[0] is None: r_count += 1 for c in range(len(row)): if row[c] is not None and row[c] not in ['', ' ']: if new_table[r - r_count][c] is None: new_table[r - r_count][c] = row[c] else: new_table[r - r_count][c] += row[c] new_table[r][c] = None else: r_count = 0 end_table = [] for row in new_table: if row[0] is not None: cell_list = [] cell_check = False for cell in row: if cell is not None: cell = cell.replace('\n', '') else: cell = '' if cell != '': cell_check = True cell_list.append(cell) if cell_check: end_table.append(cell_list) end_table = drop_empty_cols(end_table) markdown_table = '' # 存储当前表格的Markdown表示 for i, row in enumerate(end_table): # 移除空列,这里假设空列完全为空,根据实际情况调整 row = [cell for cell in row if cell is not None and cell != ''] # 转换每个单元格内容为字符串,并用竖线分隔 processed_row = [str(cell).strip() if cell is not None else "" for cell in row] markdown_row = '| ' + ' | '.join(processed_row) + ' |\n' markdown_table += markdown_row # 对于表头下的第一行,添加分隔线 if i == 0: separators = [':---' if cell.isdigit() else '---' for cell in row] markdown_table += '| ' + ' | '.join(separators) + ' |\n' all_text += markdown_table + '\n' if count == 0: text = check_lines(page, '', bottom) text_list = text.split('\n') for _t in range(len(text_list)): all_text += text_list[_t] + '\n' else: text = check_lines(page, '', '') text_list = text.split('\n') for _t in range(len(text_list)): all_text += text_list[_t] + '\n' return all_text def extract_text(pdf_path): with pdfplumber.open(pdf_path) as pdf: all_text = "" for i, page in enumerate(pdf.pages): all_text += extract_text_and_tables(page) return all_text if __name__ == '__main__': # 使用示例 test_pdf_path = "data/pdf/3e0ded8afa8f8aa952fd8179b109d6e67578c2dd.pdf" extracted_text = extract_text(test_pdf_path) pdf_save_path = "data/pdf_txt_file2/宁波华瑞电器股份有限公司.txt" with open(pdf_save_path, 'w', encoding='utf-8') as file: file.write(extracted_text) 3.2.3 文档分块
通过将3.2.1中得到的txt文档进行分块,分块步骤如下:
- 进行大的分块,然后将大分块再次进行小分块
- 将小分块做2部分存储,一部分存储pkl文件是用于bm25检索,一部分存储在faiss向量数据库用于向量检索
- 将文档–大分块–小分块的映射关系进行存储,每个招股文件存储为一个pkl文件
import os import faiss import numpy import pickle import config from tqdm import tqdm from util.instances import BEG_MODEL from langchain.text_splitter import RecursiveCharacterTextSplitter # 将每个公司的txt文件进行分块,并将分别存储在本地文件和本地向量数据库 # 本地文件存为pkl,用于bm25的相似度查询 # 本地向量数据库,用于embedding的相似度查询 def splitter_doc(txt_file, model, splitter=False, doc_chunk_size=800, doc_chunk_overlap=100, sub_chunk_size=150, sub_chunk_overlap=50): if not splitter: pkl_save_path = os.path.join(config.pkl_save_path, txt_file.split('.')[0] + '.pkl') if os.path.exists(pkl_save_path): print('当前文件已经初始化完成,无需再次初始化,如希望重新写入,则将参数splitter设为True') return # 第一步,读取txt文件 cur_file_path = os.path.join('data/pdf_txt_file2', txt_file) with open(cur_file_path, 'r', encoding='utf-8') as file: file_doc = file.read() # 第二步,先将文档切块 text_splitter = RecursiveCharacterTextSplitter(chunk_size=doc_chunk_size, chunk_overlap=doc_chunk_overlap, separators=["\n"], keep_separator=True, length_function=len) parent_docs = text_splitter.split_text(file_doc) print(len(parent_docs)) # 第三步,将切块再次切分小文本 cur_text = [] child_parent_dict = {} # 子模块与父模块的dict for doc in parent_docs: text_splitter = RecursiveCharacterTextSplitter(chunk_size=sub_chunk_size, chunk_overlap=sub_chunk_overlap, separators=["\n", ], keep_separator=True, length_function=len) child_docs = text_splitter.split_text(doc) for child_doc in child_docs: child_parent_dict[child_doc] = doc cur_text += child_docs # 第四步,将文本向量化,返回一个key为文本,value为embedding的dict result_dict = dict() for doc in tqdm(cur_text): result_dict[doc] = numpy.array(model.encode(doc)) # 第五步,将dict存储为.pkl文件,用于bm25相似度查询 pkl_save_path = os.path.join(config.pkl_save_path, txt_file.split('.')[0] + '.pkl') if os.path.exists(pkl_save_path): os.remove(pkl_save_path) print('存在旧版本pkl文件,进行先删除,后创建') with open(pkl_save_path, 'wb') as file: pickle.dump(result_dict, file) print('完成pkl数据存储:', pkl_save_path) pkl_dict_save_path = os.path.join(config.pkl_save_path, txt_file.split('.')[0] + '_dict' + '.pkl') if os.path.exists(pkl_dict_save_path): os.remove(pkl_dict_save_path) print('存在旧版本pkl dict文件,进行先删除,后创建') with open(pkl_dict_save_path, 'wb') as file: pickle.dump(child_parent_dict, file) print('完成pkl dict数据存储:', pkl_dict_save_path) # 第六步,将dict中的向量化数据存储到faiss数据库 result_vectors = numpy.array(list(result_dict.values())) dim = result_vectors.shape[1] index = faiss.IndexFlatIP(dim) faiss.normalize_L2(result_vectors) index.add(result_vectors) faiss_save_path = os.path.join(config.faiss_save_path, txt_file.replace('txt', 'faiss')) if os.path.exists(faiss_save_path): os.remove(faiss_save_path) print('存在旧版本faiss索引文件,进行先删除,后创建') faiss.write_index(index, faiss_save_path) print('完成faiss向量存储:', faiss_save_path) if __name__ == '__main__': txt_file_name = '宁波华瑞电器股份有限公司.txt' # 存储数据 splitter_doc(txt_file_name, BEG_MODEL) 3.2.4 文档检索+重排
关于向量搜索能否取代传统的一些文本搜索的问题,相信网上已经做了很多的讨论。我想说的是做过真正实践的人就不会问出这样的问题。这里采用的就是BM25+向量检索的双重。并根据检索增强生成RAG系列7–RAG提升之高级阶段中的重排BGE-reranker模型进行重排。
注意:这里面有个rerank_api方法调用bge的rerank,需要下载bge-reranker-base,并启动一个api服务。这里只是贴出主要流程代码,全代码参考github
import os import json import faiss import numpy import config import pickle import requests import pandas as pd from util import prompts from rank_bm25 import BM25Okapi from requests.adapters import HTTPAdapter from util.instances import LLM, BEG_MODEL from langchain_core.prompts import ChatPromptTemplate class Query: def __init__(self, question, docs, top_k=5): super().__init__() self.question = question self.docs = docs self.top_k = top_k def to_dict(self): return { 'question': self.question, 'docs': self.docs, 'top_k': self.top_k } # 使用bm25进行检索 def bm25_retrieve(query, contents): bm25 = BM25Okapi(contents) # 对于每个文档,计算结合BM25 bm25_scores = bm25.get_scores(query) # 根据得分排序文档 sorted_docs = sorted(zip(contents, bm25_scores), key=lambda x: x[1], reverse=True) # print("通过bm25检索结果,查到相关文本数量:", len(sorted_docs)) return sorted_docs # 使用faiss向量数据库的索引进行查询 def embedding_retrieve(query, txt_file, model): embed_select_docs = [] faiss_save_path = os.path.join("data/embedding_index", txt_file+'.faiss') if os.path.exists(faiss_save_path): index = faiss.read_index(faiss_save_path) query_embedding = numpy.array(model.encode(query)) _, search_result = index.search(query_embedding.reshape(1, -1), 5) pkl_save_path = os.path.join(config.pkl_save_path, txt_file.split('.')[0] + '.pkl') with open(pkl_save_path, 'rb') as file: docs_dict = pickle.load(file) chunk_docs = list(docs_dict.keys()) embed_select_docs = [chunk_docs[i] for i in search_result[0]] # 存储为列表 # print("通过embedding检索结果,查到相关文本数量:", len(embed_select_docs)) else: print('找不到对于的faiss文件,请确认是否已经进行存储') return embed_select_docs def search(query, model, llm, top_k=5): # 读取公司名称列表 df = pd.read_csv(config.company_save_path) company_list = df['company'].to_numpy() # 使用大模型获得最终公司的名称 prompt = ChatPromptTemplate.from_template(prompts.COMPANY_PROMPT_TEMPLATE) chain = prompt | llm response = chain.invoke({"company": company_list, "question": query}) # print(response.content) company_name = response.content for name in company_list: if name in company_name: company_name = name break # print(company_name) # 通过bm25获取相似度最高的chunk pkl_file = os.path.join(config.pkl_save_path, company_name + '.pkl') with open(pkl_file, 'rb') as file: docs_dict = pickle.load(file) chunk_docs = list(docs_dict.keys()) bm25_chunks = [docs_tuple[0] for docs_tuple in bm25_retrieve(query, chunk_docs)[:top_k]] # 通过embedding获取相似度最高的chunk embedding_chunks = embedding_retrieve(query, company_name, model) # 重排 chunks = list(set(bm25_chunks + embedding_chunks)) # print("通过双路检索结果:", len(chunks)) arg = Query(question=query, docs=chunks, top_k=top_k) chunk_similarity = rerank_api(arg) # for r in chunk_similarity.items(): # print(r) # 获取父文本块 result_docs = [] pkl_dict_file = os.path.join(config.pkl_save_path, company_name + '_dict' + '.pkl') with open(pkl_dict_file, 'rb') as file: child_parent_dict = pickle.load(file) for key, _ in sorted(chunk_similarity.items(), key=lambda x: x[1], reverse=True): for child_txt, parent_txt in child_parent_dict.items(): # 遍历父文本块 if key == child_txt: # 根据匹配的子文本块找到父文本 result_docs.append(parent_txt) # print("==========最终结果==============") # for d in result_docs: # print(d) return result_docs def rerank_api(query, url="http://127.0.0.1:8000/bge_rerank"): headers = {"Content-Type": "application/json"} data = json.dumps(query.__dict__) s = requests.Session() s.mount('http://', HTTPAdapter(max_retries=3)) try: res = s.post(url, data=data, headers=headers, timeout=600) if res.status_code == 200: return res.json() else: return None except requests.exceptions.RequestException as e: print(e) return None if __name__ == '__main__': user_query = '报告期内,华瑞电器股份有限公司人工成本占主营业务成本的比例分别为多少?' # 检索 search(user_query, BEG_MODEL, LLM) 3.3 NL2SQL
本案例中一部分问题是需要通过查询DB获取结果的。在检索增强生成RAG系列6–RAG提升之查询结构内容(Query Construction)中讨论过几种不同的查询结构内容,而本案例中就需要Text-to-SQL。Text-to-SQL需要3个步骤
- 将问题转换为SQL语句,也就是SQL的生成
- 执行SQL语句,这个主要是执行DB的查询并获得查询结果
- 生成最终结果
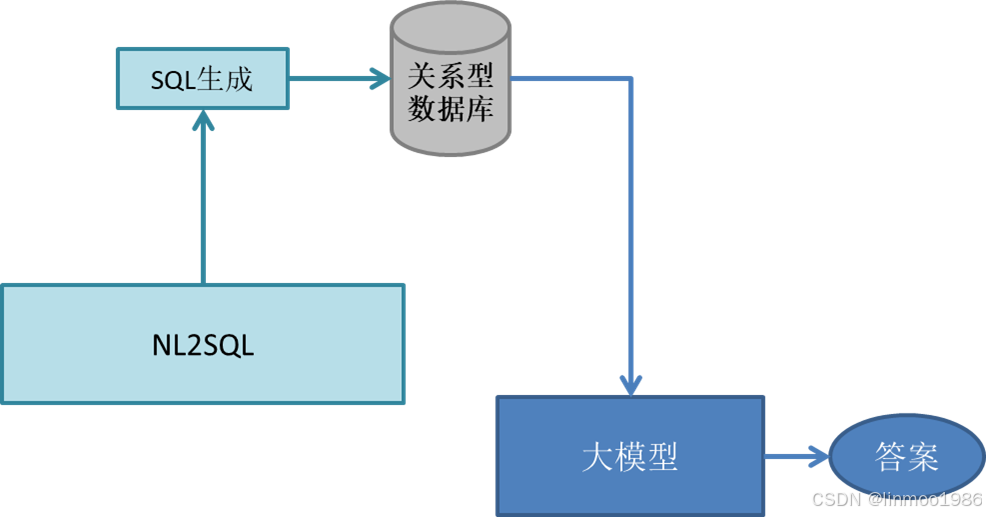
3.3.1 SQL生成
关于SQL的生成有几种不同的方法,有的利用prompt,有的利用微调,有的利用特殊模型等等,这方面的具体可以自行研究,该案例中,通过某一个通用大模型来实现,因此可以采用以下2种方式:
- 提示词,直接使用prompt+few shot方式
- 指令微调,通过给出一定数量(500+指令数据),对模型进行微调,比如通过表名、字段名等方式进行指令微调,让大模型具备特定场景下生成SQL能力
无论使用上面哪一种,最终你需要一些few shot或者一些指令数据,这方面也是可以通过2种方式进行获得:
- 人工编辑+ChatGPT生成
- 通过算法聚类
该案例中是将question.json中关于需要生成SQL的问题进行整理,组成demo数据(ICL_EXP.csv,来自比赛团队中整理好的现成数据),并使用Jaccard对问题与demo中的问题进行相似度计算,获取几条相似度靠前的demo,然后通过prompt+few-shot方式进行SQL生成。
import csv import re import copy import config import pandas as pd from util.instances import TOKENIZER, LLM from util import prompts from langchain_core.prompts import ChatPromptTemplate def generate_sql(question, llm, example_question_list, example_sql_list, tmp_example_token_list, example_num=5): pattern1 = r'\d{8}' # 过滤掉一些数字的正则表达式 sql_pattern_start = '```sql' sql_pattern_end = '```' temp_question = question # 提取数字 date_list = re.findall(pattern1, temp_question) temp_question2_for_search = temp_question # 将数字都替换为空格 for t_date in date_list: temp_question2_for_search.replace(t_date, ' ') temp_tokens = TOKENIZER(temp_question2_for_search) temp_tokens = temp_tokens['input_ids'] # 计算与已有问题的相似度--使用Jaccard进行相似度计算 similarity_list = list() for cyc2 in range(len(tmp_example_token_list)): similarity_list.append(len(set(temp_tokens) & set(tmp_example_token_list[cyc2])) / (len(set(temp_tokens)) + len(set(tmp_example_token_list[cyc2])))) # 求与第X个问题相似的问题 t = copy.deepcopy(similarity_list) # 求m个最大的数值及其索引 max_index = [] for _ in range(example_num): number = max(t) index = t.index(number) t[index] = 0 max_index.append(index) # 防止提示语过长 temp_length_test = "" short_index_list = list() # 匹配到的问题下标 for index in max_index: temp_length_test = temp_length_test + example_question_list[index] temp_length_test = temp_length_test + example_sql_list[index] if len(temp_length_test) > 2000: break short_index_list.append(index) # print("找到相似的模板:", short_index_list) # 组装prompt prompt = ChatPromptTemplate.from_template(prompts.GENERATE_SQL_TEMPLATE) examples = '' for index in short_index_list: examples = examples + "问题:" + example_question_list[index] + '\n' examples = examples + "SQL:" + example_sql_list[index] + '\n' chain = prompt | llm response = chain.invoke({"examples": examples, "table_info": prompts.TABLE_INFO, "question": temp_question}) # print("问题:", temp_question) # print("SQL:", response.content) sql = response.content start_index = sql.find(sql_pattern_start) + len(sql_pattern_start) end_index = -1 if start_index >= 0: end_index = sql[start_index:].find(sql_pattern_end) + start_index if start_index < end_index: sql = sql[start_index:end_index] return prompt.invoke({"examples": examples, "table_info": prompts.TABLE_INFO, "question": temp_question}), sql else: print("generate sql error:", temp_question) return "error", "error" if __name__ == '__main__': # 第一步:读取问题和SQL模板,使用tokenizer进行token化 sql_examples_file = pd.read_csv(config.sql_examples_path, delimiter=",", header=0) g_example_question_list = list() g_example_sql_list = list() g_example_token_list = list() for cyc in range(len(sql_examples_file)): g_example_question_list.append(sql_examples_file[cyc:cyc + 1]['问题'][cyc]) g_example_sql_list.append(sql_examples_file[cyc:cyc + 1]['SQL'][cyc]) tokens = TOKENIZER(sql_examples_file[cyc:cyc + 1]['问题'][cyc]) tokens = tokens['input_ids'] g_example_token_list.append(tokens) # 第二步:测试问题及结果文件 question_csv_file = pd.read_csv(config.question_classify_path, delimiter=",", header=0) question_sql_file = open(config.question_sql_path, 'w', newline='', encoding='utf-8-sig') csvwriter = csv.writer(question_sql_file) csvwriter.writerow(['问题id', '问题', 'SQL', 'prompt']) # 第三步:循环问题,使用Jaccard进行相似度计算问题与模板中的问题相似度最高的几条记录 for cyc in range(len(question_csv_file)): if question_csv_file['分类'][cyc] == '查询数据库': result_prompt, result = generate_sql(question_csv_file['问题'][cyc], LLM, g_example_question_list, g_example_sql_list, g_example_token_list) csvwriter.writerow([str(question_csv_file[cyc:(cyc + 1)]['问题id'][cyc]), str(question_csv_file[cyc:(cyc + 1)]['问题'][cyc]), result, result_prompt]) else: print("pass question:", question_csv_file['问题'][cyc]) pass 3.3.2 结果生成
由于SQL查询结果一般是一个json格式或者数组格式的一个数据,还需要通过大模型将数据转换成最终自然语言的结果。同样也是具备多种方式,而本案例中可以采用如下:
- 提示词,直接使用prompt+few shot方式
- 指令微调,通过给出一定数量(500+指令数据),对模型进行微调。
本次演示跟SQL生成一样,也是采用prompt+few-shot方式,其中demo数据(ICL_EXP.csv,来自比赛团队中整理好的现成数据),并使用Jaccard对问题与demo中的问题进行相似度计算。
import csv import re import copy import config import pandas as pd from util.instances import LLM, TOKENIZER from util import prompts from langchain_core.prompts import ChatPromptTemplate def generate_answer(question, fa, llm, example_question_list, example_info_list, example_fa_list, tmp_example_token_list, example_num=5): pattern1 = r'\d{8}' # 过滤掉一些数字的正则表达式 temp_question = question # 提取数字 date_list = re.findall(pattern1, temp_question) temp_question2_for_search = temp_question # 将数字都替换为空格 for t_date in date_list: temp_question2_for_search.replace(t_date, ' ') temp_tokens = TOKENIZER(temp_question2_for_search) temp_tokens = temp_tokens['input_ids'] # 计算与已有问题的相似度--使用Jaccard进行相似度计算 similarity_list = list() for cyc2 in range(len(tmp_example_token_list)): similarity_list.append(len(set(temp_tokens) & set(tmp_example_token_list[cyc2])) / (len(set(temp_tokens)) + len(set(tmp_example_token_list[cyc2])))) # 求与第X个问题相似的问题 t = copy.deepcopy(similarity_list) # 求m个最大的数值及其索引 max_index = [] for _ in range(example_num): number = max(t) index = t.index(number) t[index] = 0 max_index.append(index) # 防止提示语过长 temp_length_test = "" short_index_list = list() # 匹配到的问题下标 for index in max_index: temp_length_test = temp_length_test + example_question_list[index] temp_length_test = temp_length_test + example_fa_list[index] if len(temp_length_test) > 2000: break short_index_list.append(index) # print("找到相似的模板:", short_index_list) # 组装prompt prompt = ChatPromptTemplate.from_template(prompts.ANSWER_TEMPLATE) examples = '' for index in short_index_list: examples = examples + "问题:" + example_question_list[index] + '\n' examples = examples + "资料:" + example_info_list[index] + '\n' examples = examples + "答案:" + example_fa_list[index] + '\n' chain = prompt | llm response = chain.invoke({"examples": examples, "FA": fa, "question": temp_question}) # print("答案:", response.content) return response.content if __name__ == '__main__': # 第一步:读取问题和FA模板,使用tokenizer进行token化 sql_examples_file = pd.read_csv(config.sql_examples_path, delimiter=",", header=0) g_example_question_list = list() g_example_info_list = list() g_example_fa_list = list() g_example_token_list = list() for cyc in range(len(sql_examples_file)): g_example_question_list.append(sql_examples_file[cyc:cyc + 1]['问题'][cyc]) g_example_info_list.append(sql_examples_file[cyc:cyc + 1]['资料'][cyc]) g_example_fa_list.append(sql_examples_file[cyc:cyc + 1]['FA'][cyc]) tokens = TOKENIZER(sql_examples_file[cyc:cyc + 1]['问题'][cyc]) tokens = tokens['input_ids'] g_example_token_list.append(tokens) # 第二步:拿到答案 result_csv_file = pd.read_csv(config.question_sql_check_path, delimiter=",", header=0) answer_file = open(config.answer_path, 'w', newline='', encoding='utf-8-sig') csvwriter = csv.writer(answer_file) csvwriter.writerow(['问题id', '问题', '资料', 'FA']) # 第三步:循环问题,使用Jaccard进行相似度计算问题与模板中的问题相似度最高的几条记录 for cyc in range(len(result_csv_file)): if result_csv_file['flag'][cyc] == 1: result = generate_answer(result_csv_file['问题'][cyc], result_csv_file['执行结果'][cyc], LLM, g_example_question_list, g_example_info_list, g_example_fa_list, g_example_token_list) csvwriter.writerow([str(result_csv_file[cyc:(cyc + 1)]['问题id'][cyc]), str(result_csv_file[cyc:(cyc + 1)]['问题'][cyc]), str(result_csv_file[cyc:(cyc + 1)]['执行结果'][cyc]), result]) 3.4 agent+tool方式
通过自定义agent和tool方式,将整个流程串联起来:
import re from typing import Sequence, Union import pandas as pd from langchain.agents import AgentExecutor, AgentOutputParser from langchain.agents.chat.prompt import FORMAT_INSTRUCTIONS from langchain.agents.format_scratchpad import format_log_to_str from langchain.tools.render import render_text_description from langchain_core.agents import AgentAction, AgentFinish from langchain_core.language_models import BaseLanguageModel from langchain_core.prompts import BasePromptTemplate, ChatPromptTemplate from langchain_core.runnables import Runnable, RunnablePassthrough from langchain_core.tools import BaseTool, Tool import config from SQL_retrieve_chain import sql_retrieve_chain from util.instances import LLM from pdf_retrieve_chain import pdf_retrieve_chain from util import prompts def create_react_my_agent( llm: BaseLanguageModel, tools: Sequence[BaseTool], prompt: BasePromptTemplate ) -> Runnable: # noqa: E501 missing_vars = {"tools", "tool_names", "agent_scratchpad"}.difference( prompt.input_variables ) if missing_vars: raise ValueError(f"Prompt missing required variables: {missing_vars}") # 读取公司名称 df = pd.read_csv(config.company_save_path) company_list = df['company'] company_content = '' for company in company_list: company_content = company_content + "\n" + company # print(company_content) prompt = prompt.partial( tools=render_text_description(list(tools)), tool_names=", ".join([t.name for t in tools]), company=company_content ) llm_with_stop = llm.bind(stop=["\n观察"]) temp_agent = ( RunnablePassthrough.assign( agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]), ) | prompt | llm_with_stop | MyReActSingleInputOutputParser() ) return temp_agent class MyReActSingleInputOutputParser(AgentOutputParser): def get_format_instructions(self) -> str: return FORMAT_INSTRUCTIONS def parse(self, text: str) -> Union[AgentAction, AgentFinish]: FINAL_ANSWER_ACTION = "Final Answer:" FINAL_ANSWER_AND_PARSABLE_ACTION_ERROR_MESSAGE = ( "Parsing LLM output produced both a final answer and a parse-able action:" ) includes_answer = FINAL_ANSWER_ACTION in text regex = ( r"Action\s*\d*\s*:[\s]*(.*?)[\s]*Action\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)" ) action_match = re.search(regex, text, re.DOTALL) if action_match: action = action_match.group(1).strip() action_input = action_match.group(2) tool_input = action_input.strip(" ") tool_input = tool_input.strip('"') return AgentAction(action, tool_input, text) elif includes_answer: return AgentFinish( {"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text ) else: return AgentFinish( {"output": text}, text ) @property def _type(self) -> str: return "react-single-input" auto_tools = [ Tool( name="招股说明书", func=pdf_retrieve_chain, description="招股说明书检索", ), Tool( name="查询数据库", func=sql_retrieve_chain, description="查询数据库检索结果", ), ] tmp_prompt = ChatPromptTemplate.from_template(prompts.AGENT_CLASSIFY_PROMPT_TEMPLATE) agent = create_react_my_agent(LLM, auto_tools, prompt=tmp_prompt) agent_executor = AgentExecutor( agent=agent, tools=auto_tools, verbose=True ) result = agent_executor.invoke({"question": "报告期内,华瑞电器股份有限公司人工成本占主营业务成本的比例分别为多少?"}) # result = agent_executor.invoke({"question": "请帮我计算,在20210105,中信行业分类划分的一级行业为综合金融行业中,涨跌幅最大股票的股票代码是?涨跌幅是多少?百分数保留两位小数。股票涨跌幅定义为:(收盘价 - 前一日收盘价 / 前一日收盘价)* 100%。"}) print(result["output"]) 4 提高召回率
本次案例中,虽然简单实现了功能过程,还需要在不同环节中提高其召回率,才能达到真正RAG业务使用级别。这里总结一下本次实践中还需要哪些提升,以及方案中存在哪些问题
- 问题路由:采用的是prompt+few-shot方式,缺点的过于依赖prompt
- 文档解析:采用pdfplumber进行解析,在本案例中的效果其实一般,部分表格没有解析得很好,另外换行也是有待提高。因此这部分可以做改进
- 文档分块:虽然采用2层方式进行分块,增加了召回上下文大小,但是整体召回率还是不高,需要不断优化分块大小,通过调试获得最终的结果
- 文档检索:通过BM25和向量检索的结合,但是实践中2种也不一定能很好的召回相关性最高的内容,还是要结合其它传统检索方式,比如ES等获得更为精确的召回结果
- SQL生成:通过模板few-shot的方式,缺点就是依赖于demo库,需要比较大的人工整理,也依赖于demo库中的样例丰富性。更为通用的方式是采用专业SQL生成大模型,会得到更好的准确率
- 问题生成:本案例中也是通过demo库提供few-shot方式,如果通过一定指令微调,可能更为适应其泛化能力
5 总结
本次通过一次实践过程给大家演示一下RAG的落地过程。我们可以发现虽然前面2~7中讲了很多理论,在实际过程中算是入门的应用,过程中针对具体场景,我们还是需要做其他大量工作,特别是数据处理、寻找更高召回率的步骤慢慢探索。
