
阅读量:0
好多小伙伴问游戏后端现在都是C++吗?可以说现在大部分还是C++,虽然也有Golang,但是综合考虑起来,还得是C++。
这几年Java都卷成麻花了,在网上也看到好多帖子劝退Java。怎么说呢?各有特点吧,各有自己擅长的领域,也看个人的选择和爱好。
粉丝福利, 免费领取C/C++ 开发学习资料包、技术视频/项目代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发/音视频开发/Qt开发/游戏开发/Linuxn内核等进阶学习资料和最佳学习路线)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
C++开发
1、类的静态成员函数的特点?
- 无需对象实例:静态成员函数不依赖于类的对象实例,可以直接通过类名调用。例如,ClassName::StaticFunction()。
- 访问限制:静态成员函数只能访问静态成员变量和其他静态成员函数,不能访问非静态成员变量和非静态成员函数。因为静态成员函数在调用时并不依赖于具体的对象实例,所以没有this指针。
- 共享属性:静态成员变量和静态成员函数是类的共享成员,所有对象实例共享同一份静态成员数据。这对于实现全局属性或全局行为非常有用。
- 生命周期:静态成员函数和静态成员变量在程序运行开始时分配内存,直到程序结束时才释放内存。它们的生命周期贯穿整个程序运行过程。
- 内存分配:静态成员变量存储在静态存储区中,而不是在对象的内存空间中。静态成员函数的代码段则与普通成员函数无异,但它们不依赖于对象实例。
- 可以作为回调函数:由于静态成员函数不需要对象实例,它们可以作为普通函数指针使用,适用于某些需要回调函数的场景。
给一个示例代码,静态成员函数的使用:
#include <iostream> using namespace std; class MyClass { public: // 静态成员变量 static int staticVar; // 静态成员函数 static void staticFunction() { cout << "Static Function Called. staticVar = " << staticVar << endl; // 不能访问非静态成员变量或非静态成员函数 // nonStaticFunction(); // 错误 } // 非静态成员函数 void nonStaticFunction() { cout << "Non-Static Function Called." << endl; } }; // 静态成员变量的初始化 int MyClass::staticVar = 0; int main() { // 通过类名调用静态成员函数 MyClass::staticFunction(); // 修改静态成员变量 MyClass::staticVar = 10; // 通过类名再次调用静态成员函数 MyClass::staticFunction(); // 创建对象实例 MyClass obj; // 通过对象实例调用静态成员函数(不推荐) obj.staticFunction(); return 0; }输出:
Static Function Called. staticVar = 0 Static Function Called. staticVar = 10 Static Function Called. staticVar = 102、虚函数是怎么实现的?
虚函数表(vtable)
虚函数表是一个函数指针数组,每个类都有一个虚函数表,用来存储该类的虚函数的地址。当一个类定义了虚函数时,编译器会为该类生成一个虚函数表。
虚函数指针(vptr)
每个含有虚函数的类的对象中,编译器会自动添加一个虚函数指针(vptr),该指针指向该类的虚函数表。通过这个指针,对象可以在运行时找到正确的函数实现,从而实现动态绑定。
实现过程
- 类定义:
- 当一个类定义了虚函数,编译器会为该类生成一个虚函数表。
- 虚函数表中存储了该类的所有虚函数的地址。
- 对象创建:
- 当创建一个对象时,该对象会包含一个指向该类虚函数表的指针(vptr)。
- vptr在对象构造时被初始化,指向相应的虚函数表。
- 函数调用:
- 当通过基类指针或引用调用虚函数时,程序会通过对象的vptr找到虚函数表,然后根据虚函数表中的地址调用实际的函数实现。
虚函数的动态绑定
虚函数的动态绑定是通过虚函数表和虚函数指针在运行时实现的。当调用虚函数时,程序会根据对象的vptr找到正确的函数地址,从而实现动态绑定。这使得C++可以在运行时根据实际对象类型调用相应的函数,实现多态性。
虚函数的优点
- 多态性:通过虚函数,可以在基类指针或引用的基础上调用子类的实现,实现多态性。
- 灵活性:虚函数允许子类重写父类的方法,使得代码更具灵活性和可扩展性。
虚函数的缺点
- 开销:使用虚函数需要额外的内存开销来存储虚函数表和虚函数指针,同时在运行时也有一定的性能开销,因为需要通过虚函数表查找函数地址。
- 不支持内联:虚函数通常不能内联,因为它们的调用在编译时无法确定具体的函数实现。
3、一个对象最多只有一个虚函数指针吗?
单一继承情况下的虚函数指针
在单一继承的情况下,每个包含虚函数的类的对象会有一个vptr,这个vptr指向该类的虚函数表(vtable)。
class Base { public: virtual void show() { cout << "Base class show function" << endl; } virtual ~Base() = default; }; class Derived : public Base { public: void show() override { cout << "Derived class show function" << endl; } };上述例子中,无论是Base类还是Derived类的对象,都会有一个vptr指向它们各自的虚函数表。
多重继承情况下的虚函数指针
在多重继承的情况下,每个对象可能会有多个虚函数指针。这是因为每个基类都有自己的虚函数表,而每个继承自多个基类的类的对象必须维护多个虚函数指针,以指向各个基类的虚函数表。
class Base1 { public: virtual void show1() { cout << "Base1 show1 function" << endl; } virtual ~Base1() = default; }; class Base2 { public: virtual void show2() { cout << "Base2 show2 function" << endl; } virtual ~Base2() = default; }; class Derived : public Base1, public Base2 { public: void show1() override { cout << "Derived show1 function" << endl; } void show2() override { cout << "Derived show2 function" << endl; } };上述例子中,Derived类从Base1和Base2继承而来。因此,Derived类的对象将包含两个vptr,一个指向Base1的虚函数表,另一个指向Base2的虚函数表。
单一继承
对于单一继承,一个类只有一个基类,因此对象只需一个vptr。
Base* ptr = new Derived(); ptr->show(); // 调用Derived的show函数多重继承
对于多重继承,一个类有多个基类,每个基类都有自己的虚函数表,因此对象需要多个vptr。
Derived* d = new Derived(); Base1* b1 = d; Base2* b2 = d; b1->show1(); // 调用Derived的show1函数 b2->show2(); // 调用Derived的show2函数这种情况下,d对象有两个vptr,一个指向Base1的虚函数表,另一个指向Base2的虚函数表。
4、友元函数能作为虚函数吗?
友元函数
友元函数是一种非成员函数,但它可以访问类的私有成员和保护成员。友元函数是通过在类内声明friend关键字来指定的。友元函数的主要目的是为了提供一种机制,使非成员函数可以访问类的私有数据。
class MyClass { private: int data; public: MyClass(int value) : data(value) {} // 声明友元函数 friend void showData(const MyClass& obj); }; // 友元函数定义 void showData(const MyClass& obj) { cout << "Data: " << obj.data << endl; } int main() { MyClass obj(10); showData(obj); // 调用友元函数,输出 "Data: 10" return 0; }在这个例子中,showData函数是MyClass类的友元函数,它能够访问MyClass对象的私有成员data。
虚函数
虚函数是类的成员函数,通过在基类中使用virtual关键字声明。虚函数的主要目的是实现多态性,使得通过基类指针或引用调用派生类的重写函数。
class Base { public: virtual void show() { cout << "Base class show function" << endl; } virtual ~Base() = default; }; class Derived : public Base { public: void show() override { cout << "Derived class show function" << endl; } }; int main() { Base* bptr = new Derived(); bptr->show(); // 输出 "Derived class show function" delete bptr; return 0; }在这个例子中,通过基类指针bptr调用虚函数show,实现了运行时的多态性。
友元函数不能是虚函数的原因
- 非成员函数:友元函数不是类的成员函数,而虚函数必须是类的成员函数。虚函数需要在类的虚函数表中有一个条目,以便在运行时进行动态绑定,而友元函数不在类的范围内,因此无法包含在虚函数表中。
- 访问机制:虚函数是通过对象的vptr指向的虚函数表来实现动态绑定的,而友元函数没有这种机制。友元函数只是一个普通的函数,它不依赖于具体的对象实例,没有vptr指向它。
- 多态性要求:虚函数的主要目的是为了实现多态性,使得基类指针或引用能够调用派生类的重写函数。友元函数不具备这种需求和功能。
5、内联成员函数可以是虚函数吗?
内联函数
内联函数是一种提示编译器将函数调用展开为函数体内的代码,以避免函数调用的开销。内联函数通过在函数定义前加上inline关键字来声明。内联函数通常用于短小、频繁调用的函数。
虚函数
虚函数是用于实现多态性的成员函数,允许通过基类指针或引用调用派生类的重写函数。虚函数通过在基类中使用virtual关键字声明。
内联函数和虚函数的结合
内联函数可以是虚函数,但在实际使用中存在一些限制和考虑。以下是详细的解释:
- 虚函数的内联属性:
- 虚函数可以在类定义中声明为内联函数。然而,虚函数在基类中的内联声明不会自动使其在派生类中内联。派生类重写的虚函数需要显式地内联。
- 内联只是对编译器的建议,编译器可能会忽略内联建议,特别是在虚函数的情况下。
- 多态性和内联的冲突:
- 虚函数的多态性依赖于运行时的动态绑定,即通过虚函数表(vtable)在运行时确定调用哪个函数实现。这种动态绑定在某些情况下会阻碍内联展开,因为内联展开需要在编译时确定调用目标。
- 如果通过基类指针或引用调用虚函数,编译器在编译时无法确定实际调用的函数实现,因此不能内联展开。
- 特殊情况下的内联:
- 如果编译器在编译时能够确定虚函数的实际类型(例如,通过具体对象调用而不是通过基类指针或引用),那么编译器可能会内联该虚函数。
- 以下示例展示了这种情况:
#include <iostream> class Base { public: virtual void show() { std::cout << "Base class show function" << std::endl; } }; class Derived : public Base { public: inline void show() override { std::cout << "Derived class show function" << std::endl; } }; int main() { Derived d; d.show(); // 可能被内联展开 Base* bptr = &d; bptr->show(); // 不会被内联展开,因为是通过基类指针调用 return 0; }6、模板函数可以是虚函数吗?
模板函数
模板函数是一种函数,它允许我们在编写代码时使用泛型类型。模板函数在编译时会根据提供的具体类型生成具体的函数实例。
template<typename T> void show(T value) { std::cout << value << std::endl; }虚函数
虚函数是用于实现运行时多态性的成员函数,允许基类指针或引用调用派生类的重写函数。虚函数依赖于虚函数表(vtable)和虚函数指针(vptr)来在运行时动态绑定函数调用。
class Base { public: virtual void show() { std::cout << "Base class show function" << std::endl; } }; class Derived : public Base { public: void show() override { std::cout << "Derived class show function" << std::endl; } };模板函数与虚函数的区别
- 编译时与运行时:
- 模板函数在编译时实例化,具体类型在编译时确定,生成对应的函数代码。
- 虚函数在运行时动态绑定,通过虚函数表和虚函数指针确定调用哪个具体的函数实现。
- 函数表机制:
- 虚函数依赖于虚函数表,而模板函数在编译时生成具体的函数实例,无法在编译时生成统一的虚函数表结构。
- 由于模板函数是在编译时生成具体实例,而不是在类定义时确定,所以无法将其地址放入虚函数表中。
为什么模板函数不能是虚函数
- 模板函数在编译时实例化:
- 模板函数在使用时根据具体类型实例化,这意味着编译器在编译期生成特定类型的函数代码。在类定义时,编译器无法知道所有可能的模板实例化,因此无法创建虚函数表条目。
- 虚函数表的固定结构:
- 虚函数表在类定义时创建并固定下来,包含指向虚函数的指针。模板函数实例化是在编译期进行的,与虚函数表的运行时动态绑定机制不兼容。
7、模板函数是怎么实现的,为什么能实现多态?
模板函数的实现
模板函数的实现是通过模板实例化完成的。当我们定义一个模板函数时,并不会立即生成函数代码。只有在使用该模板函数时(即实例化模板函数时),编译器才会生成对应的具体函数代码。
template<typename T> void show(T value) { std::cout << value << std::endl; } 当我们调用这个模板函数时,
show(10); // T 实例化为 int show(3.14); // T 实例化为 double show("Hello"); // T 实例化为 const char* 编译器会生成以下具体的函数实例:
void show(int value) { std::cout << value << std::endl; } void show(double value) { std::cout << value << std::endl; } void show(const char* value) { std::cout << value << std::endl; } 编译时多态性
模板函数通过模板实例化实现编译时多态性,这意味着在编译期生成不同类型的函数实例。编译时多态性主要依赖于编译期的类型推导和模板实例化机制。
template<typename T> T add(T a, T b) { return a + b; } int main() { int x = add(1, 2); // 生成 add(int, int) double y = add(1.1, 2.2); // 生成 add(double, double) return 0; } 8、有用过智能指针吗,有哪些类型,分别是什么区别?
1. std::unique_ptr
std::unique_ptr是独占所有权的智能指针,确保一个对象在同一时间只有一个智能指针指向它。
- 特点:
- 独占所有权,不能复制,只能移动。
- 在离开作用域时自动释放所指向的对象。
- 提供轻量级的所有权转移机制(移动语义)。
- 使用场景:
- 适用于确定某个对象只会有一个所有者的情况。
- 用于资源管理,例如文件句柄、网络连接等。
- 示例代码:#include <memory>
#include <iostream>
void uniquePtrExample() {
std::unique_ptr<int> p1(new int(10));
std::cout << *p1 << std::endl;
// std::unique_ptr<int> p2 = p1; // 错误,不能复制
std::unique_ptr<int> p2 = std::move(p1); // 移动p1到p2
if (!p1) {
std::cout << "p1 is null" << std::endl;
}
}
2. std::shared_ptr
std::shared_ptr是共享所有权的智能指针,可以有多个智能指针指向同一个对象。对象会在最后一个引用离开作用域时被销毁。
- 特点:
- 共享所有权,通过引用计数实现。
- 可以复制和赋值,引用计数会相应增加或减少。
- 在所有共享指针离开作用域后自动释放所指向的对象。
- 使用场景:
- 适用于多个所有者共享同一个资源的情况。
- 适用于需要动态内存管理但不确定对象生命周期的情况。
- 示例代码:
#include <memory> #include <iostream> void sharedPtrExample() { std::shared_ptr<int> p1(new int(20)); std::shared_ptr<int> p2 = p1; // p1和p2共享所有权 std::cout << *p1 << ", " << *p2 << std::endl; std::cout << "use count: " << p1.use_count() << std::endl; }3. std::weak_ptr
std::weak_ptr是一种不控制对象生命周期的智能指针,与std::shared_ptr配合使用,解决循环引用的问题。
- 特点:
- 不影响对象的引用计数。
- 可以从std::shared_ptr创建,弱引用不会增加引用计数。
- 需要使用std::weak_ptr的lock方法提升为std::shared_ptr以访问对象。
- 使用场景:
- 适用于需要观察一个共享对象,但不想影响其生命周期的情况。
- 解决std::shared_ptr的循环引用问题。
- 示例代码:
#include <memory> #include <iostream> void weakPtrExample() { std::shared_ptr<int> p1 = std::make_shared<int>(30); std::weak_ptr<int> wp = p1; // 创建弱引用 std::shared_ptr<int> p2 = wp.lock(); // 提升为共享引用 if (p2) { std::cout << *p2 << std::endl; std::cout << "use count: " << p2.use_count() << std::endl; } }智能指针的对比
9、noexcept关键字了解吗?
noexcept可以用于声明一个函数不会抛出异常。有两种形式:
- 无条件形式:明确表示函数不会抛出异常。
- 条件形式:基于一个布尔表达式来决定函数是否不会抛出异常。
无条件形式
无条件形式的noexcept声明一个函数在任何情况下都不会抛出异常。
void func() noexcept { // This function is guaranteed not to throw an exception }条件形式
条件形式的noexcept根据一个布尔表达式来决定函数是否不会抛出异常。常见的用法是通过类型特性来判断。
template<typename T> void func(T t) noexcept(noexcept(T())) { // This function will not throw an exception if T's constructor does not throw } 使用noexcept的原因
- 性能优化:标记为noexcept的函数可以进行更多的优化,例如在调用这些函数时不需要生成处理异常的代码路径。
- 提高可预测性:当一个函数标记为noexcept时,调用者可以确信该函数不会抛出异常,从而简化错误处理逻辑。
- 提高安全性:在某些场景下(例如在析构函数中),抛出异常会导致程序异常终止。使用noexcept可以避免这种情况。
示例代码
以下是一些示例代码,展示了如何使用noexcept关键字:
简单的无条件noexcept
void doWork() noexcept { // Guaranteed not to throw an exception } int main() { doWork(); return 0; } 带有条件的noexcept
#include <type_traits> template<typename T> void maybeThrow(T t) noexcept(std::is_nothrow_copy_constructible<T>::value) { // Will not throw if T's copy constructor is noexcept } int main() { int a = 5; maybeThrow(a); // OK, int is nothrow copy constructible std::string s = "Hello"; maybeThrow(s); // OK, std::string's copy constructor may throw return 0; } 与其他C++特性的结合
与移动构造函数和移动赋值运算符的结合
在实现移动构造函数和移动赋值运算符时,使用noexcept可以避免不必要的性能开销。
class MyClass { public: MyClass(MyClass&& other) noexcept { // Move constructor } MyClass& operator=(MyClass&& other) noexcept { // Move assignment operator return *this; } }; 标准库中的noexcept
C++标准库中很多函数和运算符都使用了noexcept来优化性能和行为。例如,标准库容器在执行某些操作(如std::vector的移动操作)时会检查元素类型的构造函数和赋值运算符是否是noexcept的。
10、完美转发了解吗?
万能引用(Universal References)
万能引用是指模板参数的类型推导时可以同时表示左值引用和右值引用的引用。万能引用的形式是T&&,其中T是模板参数。
template<typename T> void func(T&& arg) { // arg 是万能引用 } 完美转发的实现
完美转发通过结合万能引用和std::forward来实现。std::forward根据传入的参数类型决定是将参数转发为左值引用还是右值引用。
std::forward的用法
std::forward是一个标准库函数,用于保留参数的左值或右值性质。以下是一个例子:
#include <utility> #include <iostream> void process(int& lref) { std::cout << "Lvalue reference" << std::endl; } void process(int&& rref) { std::cout << "Rvalue reference" << std::endl; } template<typename T> void wrapper(T&& arg) { process(std::forward<T>(arg)); // 使用std::forward进行完美转发 } int main() { int x = 10; wrapper(x); // Lvalue reference wrapper(10); // Rvalue reference return 0; } 完美转发的优势
- 避免不必要的拷贝:通过完美转发,能够避免不必要的对象拷贝,提高程序性能。
- 保留参数特性:完美转发保留了参数的左值或右值属性,使得被调用函数能够正确处理参数。
11、vector底层是怎么实现的,是线程安全的吗?
std::vector 的底层数据结构是一个连续的动态数组,元素在内存中排列成一系列的单元。这使得通过索引来访问元素非常高效,因为它可以通过内存指针和偏移量直接计算出元素的地址。
C++标准并没有规定std::vector必须是线程安全的。因此,在多线程环境中,如果有一个线程正在修改std::vector,而另一个线程同时对其进行访问(读取或修改),就有可能导致竞态条件(Race Condition)和数据竞争(Data Race)。为了确保在多线程环境下的安全使用,可以使用互斥锁(Mutex)或其他线程同步机制来保护std::vector的访问。
12、说一下最小堆的插入和删除的过程?
最小堆的插入操作
- 插入元素:首先将新元素插入到堆的末尾(即数组的最后一个位置)。
- 上浮操作:然后将新元素与其父节点进行比较。如果新元素的值小于父节点的值,则交换它们的位置,继续向上比较直到满足最小堆的性质为止。
插入操作的时间复杂度为O(log n),其中n为堆中元素的个数。
最小堆的删除操作
- 删除根节点:首先将根节点(堆顶元素)删除。为了保持完全二叉树的结构,通常将堆的最后一个元素移动到根节点的位置。
- 下沉操作:然后将新的根节点与其子节点中较小的节点进行比较。如果新根节点的值大于子节点的值,则交换它们的位置,继续向下比较直到满足最小堆的性质为止。
删除操作的时间复杂度也是O(log n),其中n为堆中元素的个数。
示例代码
#include <iostream> #include <vector> class MinHeap { private: std::vector<int> heap; // 上浮操作 void heapifyUp(int index) { int parent = (index - 1) / 2; while (index > 0 && heap[index] < heap[parent]) { std::swap(heap[index], heap[parent]); index = parent; parent = (index - 1) / 2; } } // 下沉操作 void heapifyDown(int index) { int left = 2 * index + 1; int right = 2 * index + 2; int smallest = index; if (left < heap.size() && heap[left] < heap[smallest]) { smallest = left; } if (right < heap.size() && heap[right] < heap[smallest]) { smallest = right; } if (smallest != index) { std::swap(heap[index], heap[smallest]); heapifyDown(smallest); } } public: // 插入操作 void insert(int value) { heap.push_back(value); heapifyUp(heap.size() - 1); } // 删除操作 int extractMin() { if (heap.empty()) { throw std::out_of_range("Heap is empty"); } int root = heap.front(); heap[0] = heap.back(); heap.pop_back(); heapifyDown(0); return root; } // 获取堆顶元素(最小元素) int getMin() { if (heap.empty()) { throw std::out_of_range("Heap is empty"); } return heap.front(); } // 获取堆的大小 size_t size() { return heap.size(); } // 判断堆是否为空 bool empty() { return heap.empty(); } }; int main() { MinHeap heap; heap.insert(3); heap.insert(2); heap.insert(1); heap.insert(15); heap.insert(5); std::cout << "Heap size: " << heap.size() << std::endl; while (!heap.empty()) { std::cout << heap.extractMin() << " "; } std::cout << std::endl; return 0; }13、解决哈希冲突有哪些方法?
- 拉链法(Chaining):
拉链法是一种开放地址法,它将多个映射到同一槽位的元素存储在一个链表(或其他数据结构)中。
当哈希冲突发生时,元素被添加到链表中。在查找、插入和删除元素时,首先找到对应的槽位,然后在链表中搜索或操作。
拉链法的优点是简单且易于实现,但在链表变得很长时,性能可能会下降。
- 线性探测法(Linear Probing):
线性探测法是一种封闭地址法,当哈希冲突发生时,它会查找下一个可用的槽位。
如果槽位被占用,就线性地查找下一个槽位,直到找到一个空槽位或达到表的末尾。
线性探测法可能导致聚集现象,即连续的槽位会被多次占用,降低性能。因此,通常需要解决二次聚集或更复杂的聚集问题。
- 二次探测法(Quadratic Probing):
二次探测法是线性探测法的变种,它使用二次函数来查找下一个可用的槽位,以减少聚集现象。
二次探测法的探测步长是一个二次函数的结果,通常是 c1 * i^2 + c2 * i,其中 c1 和 c2 是常数,i 是探测的次数。
二次探测法的性能通常比线性探测法好,但仍然可能出现聚集。
- 双重哈希(Double Hashing):
双重哈希是一种封闭地址法,它使用两个不同的哈希函数来确定下一个探测位置。
当哈希冲突发生时,它首先使用第一个哈希函数来计算下一个槽位,如果该槽位已被占用,则使用第二个哈希函数来计算下一个槽位。
双重哈希法可以减少聚集问题,但需要精心选择和设计哈希函数。
- 再哈希(Rehashing):
当哈希表中的负载因子(已占用槽位数与总槽位数之比)达到一定阈值时,可以进行再哈希。
再哈希是将哈希表的大小扩展一倍,并重新将所有元素插入新的表中。这可以减小负载因子,减少哈希冲突的可能性。
- 建立一个好的哈希函数:
最好的方法是设计一个能够尽可能减少冲突的哈希函数。好的哈希函数应该均匀地分散键,使哈希表的槽位均匀利用。
- 分离链接哈希表(Separate Chaining Hash Table):
这种方法是将哈希表的每个槽位都构建为一个独立的数据结构,如链表、树或其他哈希表。这样,即使发生冲突,也能够高效地存储多个值。
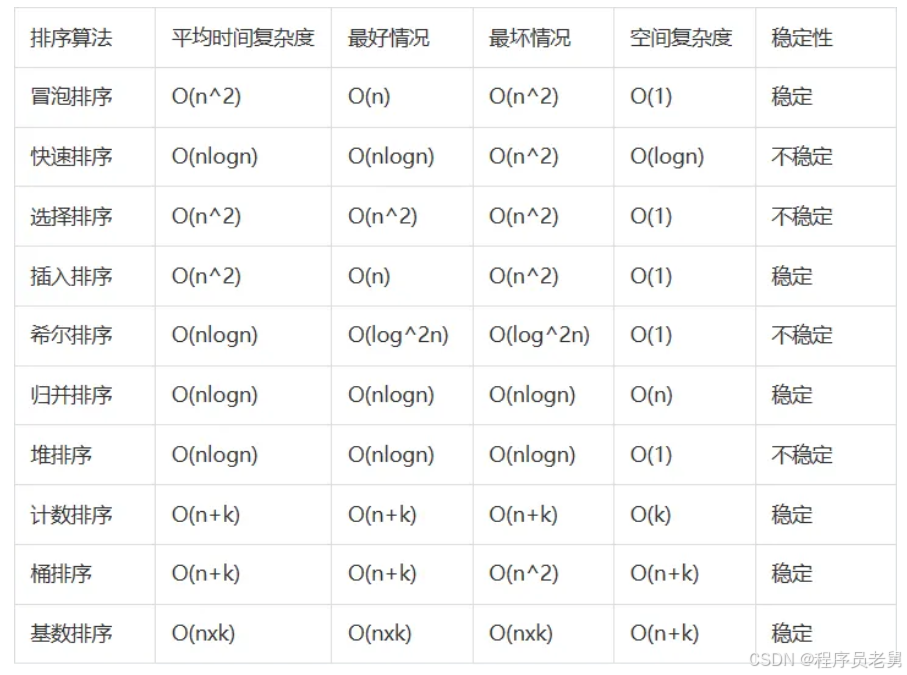
14、快速排序是稳定排序吗,插入排序是稳定排序吗?
操作系统
15、用户态和内核态的区别?除了系统调用还有哪些情况会切换用户态和内核态?
用户态和内核态的区别
- 访问权限:
- 用户态:只能访问受限的内存区域,不能直接访问硬件和某些内核数据结构。用户态程序执行受限的指令集,确保系统稳定性和安全性。
- 内核态:具有最高权限,能够访问所有内存地址,执行所有CPU指令,并直接与硬件交互。
- 运行环境:
- 用户态:应用程序通常运行在用户态,受操作系统保护,不直接与硬件打交道。
- 内核态:操作系统核心组件(如驱动程序、内核服务)运行在内核态。
- 切换成本:
- 从用户态切换到内核态(或者反过来)涉及上下文切换,保存当前状态并加载目标态的状态,具有一定的性能开销。
切换用户态和内核态的情况
除了系统调用(System Call)以外,还有以下情况会触发用户态与内核态的切换:
- 硬件中断:当硬件设备(如键盘、网卡、硬盘)发出中断信号时,CPU会暂停当前用户态进程,切换到内核态,执行对应的中断服务程序(Interrupt Service Routine,ISR)。
- 异常处理:当CPU执行指令时遇到异常(如除零错误、无效指令、内存访问违规)时,会触发异常处理,切换到内核态,执行异常处理程序。
- 陷入指令(Trap Instruction):一些CPU指令(如x86架构中的int指令)会显式地从用户态切换到内核态,以处理特定的任务或请求。
内核态与用户态的切换过程
切换过程涉及保存当前CPU状态(寄存器、程序计数器等),切换到新的上下文,并加载新状态:
- 保存当前上下文:保存用户态寄存器和程序计数器到内核栈。
- 切换到内核栈:切换栈指针到内核栈。
- 加载内核上下文:加载内核态寄存器和程序计数器。
- 执行内核代码:处理系统调用、中断或异常。
- 返回用户态:处理完成后,恢复用户态上下文,返回用户态继续执行。
16、零拷贝了解吗?
零拷贝的概念
在传统的数据传输过程中,数据可能会在用户态和内核态之间多次拷贝,这会导致性能开销。零拷贝技术旨在减少或消除这些不必要的拷贝操作,直接在内核态完成数据传输。
零拷贝的实现方式
零拷贝的实现方式有多种,以下是几种常见的方法:
- mmap 和 write使用mmap将文件映射到进程的地址空间,然后通过write系统调用直接将数据发送到网络或其他输出设备。这种方式避免了用户态和内核态之间的数据拷贝。
int fd = open("file.txt", O_RDONLY); struct stat file_stat; fstat(fd, &file_stat); void *mapped = mmap(NULL, file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0); write(socket_fd, mapped, file_stat.st_size); munmap(mapped, file_stat.st_size); close(fd);- sendfilesendfile系统调用可以在文件描述符之间直接传输数据,而无需将数据复制到用户态。这在网络编程中非常有用,例如从文件发送数据到套接字。
int file_fd = open("file.txt", O_RDONLY); off_t offset = 0; sendfile(socket_fd, file_fd, &offset, file_size); close(file_fd);splice 和 tee
splice系统调用允许在两个文件描述符之间移动数据,而无需将数据复制到用户态。tee系统调用可以复制数据流,而无需额外的数据拷贝。
int pipe_fds[2]; pipe(pipe_fds); splice(file_fd, NULL, pipe_fds[1], NULL, file_size, SPLICE_F_MOVE); splice(pipe_fds[0], NULL, socket_fd, NULL, file_size, SPLICE_F_MOVE);零拷贝的优点
- 性能提升:减少了数据在内存中的拷贝次数,从而降低了CPU负载,提高了数据传输效率。
- 降低延迟:减少了上下文切换和数据拷贝的开销,从而降低了数据传输的延迟。
- 减少内存带宽占用:由于减少了数据的复制,内存带宽的占用也相应减少。
零拷贝的应用场景
- 网络编程:例如,高性能的Web服务器(如Nginx)和文件传输协议(FTP)服务器中使用零拷贝技术来提高数据传输性能。
- 文件I/O:在文件备份、数据迁移和数据库系统中,通过零拷贝技术可以提高大文件传输的效率。
- 多媒体应用:在视频流和音频流的传输中,零拷贝技术可以减少延迟,提高播放的流畅性。
零拷贝的局限性
- 硬件支持:零拷贝技术依赖于底层硬件的支持,不同的硬件平台和操作系统可能对零拷贝的支持有所不同。
- 编程复杂度:实现零拷贝技术需要深入理解操作系统和硬件的工作原理,编程复杂度较高。
- 适用性:零拷贝技术并不适用于所有场景,特别是在需要对数据进行复杂处理或修改的情况下,零拷贝可能不适用。
17、知道什么是写时拷贝吗?
写时拷贝的基本概念
写时拷贝的基本思想是,在创建数据的副本时,不立即复制数据,而是让副本和原始数据共享同一块内存区域。只有当其中一个副本试图修改数据时,系统才真正执行数据的复制操作。这种策略有助于节省内存和减少不必要的数据复制开销。
写时拷贝的实现机制
写时拷贝的实现通常涉及以下几个步骤:
- 共享内存:初始情况下,多个进程或数据副本共享同一块内存区域,并且该内存区域被标记为只读。
- 引用计数:系统维护一个引用计数器,记录有多少个副本共享这块内存区域。
- 写操作检测:当其中一个副本试图写入数据时,系统检测到写操作,并执行实际的数据复制。
- 实际拷贝:系统为试图修改数据的副本分配新的内存区域,将原始数据复制到新区域,然后进行写操作。其他副本仍然共享原始内存区域。
写时拷贝的应用场景
写时拷贝广泛应用于操作系统和文件系统中,以下是几个典型的应用场景:
- 操作系统进程创建(fork):在Unix和Linux系统中,创建一个新进程时,通常使用fork系统调用。fork创建一个新进程,并使新进程共享父进程的内存区域。当任一进程尝试写入共享内存时,系统才执行实际的数据复制。这种方式提高了进程创建的效率。
pid_t pid = fork(); if (pid == 0) { // 子进程 } else if (pid > 0) { // 父进程 } else { // 错误处理 }2.虚拟内存分页:
- 在虚拟内存系统中,多个进程可以共享同一个内存页。当一个进程试图写入共享内存页时,系统执行写时拷贝,将共享内存页复制到新的物理页,并将写入操作应用于新的物理页。
- 3.文件系统:
- 一些文件系统(如ZFS、Btrfs)利用写时拷贝技术来实现快照和数据备份。当创建快照时,系统不立即复制文件数据,而是共享相同的数据块。当有写操作发生时,才复制数据块。
写时拷贝的优点
- 节省内存:通过延迟实际数据复制,写时拷贝技术减少了内存使用,尤其在创建大量副本时效果显著。
- 提高效率:在很多情况下,副本只需要读取数据而不进行写操作,这种情况下写时拷贝避免了不必要的复制操作,提升了系统效率。
- 实现简单:写时拷贝通过共享内存区域和引用计数的方式实现,机制相对简单但效果显著。
写时拷贝的局限性
- 写操作开销:当发生写操作时,系统需要执行实际的数据复制,这会带来一定的性能开销,尤其在写操作频繁的情况下。
- 实现复杂性:尽管机制简单,但在实现过程中需要仔细管理内存共享和引用计数,确保系统的正确性和稳定性。
- 硬件支持:写时拷贝需要硬件支持,比如内存管理单元(MMU)的页表保护位和写时拷贝的异常处理机制。
18、知道什么是缺页中断吗?
缺页中断的概念
在虚拟内存系统中,每个进程拥有一个虚拟地址空间,这个空间被分成固定大小的块,称为页(Page)。这些页被映射到物理内存中的物理页框(Frame)。当一个进程试图访问一个未映射到物理内存的虚拟页时,就会发生缺页中断。
缺页中断的处理过程
- 检测缺页:CPU检测到访问了一个无效的虚拟内存地址(即未映射到物理内存),并生成缺页中断。
- 保存上下文:CPU保存当前进程的状态,包括寄存器和程序计数器,以便稍后能够恢复。
- 查找页面:操作系统检查页表,确定缺页发生的原因。如果页面在交换区或文件中存在,则继续下一步。
- 分配物理页框:操作系统在物理内存中分配一个空闲的页框。如果没有空闲页框,则需要选择一个现有的页框进行替换(可能使用页置换算法,如LRU、FIFO等)。
- 读取页面:将缺页所在的页面从磁盘或交换区读取到物理内存中,并更新页表,指示该虚拟页现在已经映射到物理页框。
- 恢复进程:恢复被中断的进程的状态,并重新执行导致缺页中断的指令。
缺页中断的分类
- 软缺页(Minor Page Fault):当请求的页面已经在物理内存中,但页表项尚未更新时,发生软缺页。处理软缺页相对简单,只需更新页表即可。
- 硬缺页(Major Page Fault):当请求的页面不在物理内存中,需要从磁盘或交换区读取时,发生硬缺页。硬缺页处理开销较大,因为需要进行I/O操作。
19、常见的页面替换算法有哪些?
1. 最佳页面替换算法 (Optimal Page Replacement, OPT)
- 概念:选择未来最长时间内不会被访问的页面进行替换。
- 优点:能够达到最小的缺页率。
- 缺点:实际实现中无法预知未来页面的访问顺序,因此主要用于理论分析和比较。
2. 最近最久未使用算法 (Least Recently Used, LRU)
- 概念:选择最近最久未被使用的页面进行替换。
- 优点:有效减少缺页率,在实际系统中性能较好。
- 缺点:实现复杂,需要维护每个页面的访问时间,开销较大。
3. 先进先出算法 (First-In-First-Out, FIFO)
- 概念:选择最早进入内存的页面进行替换。
- 优点:实现简单,维护一个队列即可。
- 缺点:可能导致Belady’s anomaly,即增加内存反而增加缺页率。
4. 第二次机会算法 (Second Chance, Clock)
- 概念:是FIFO的改进版。给每个页面一个使用位,如果页面被访问过,使用位设为1,否则为0。选择替换页面时,如果页面的使用位为1,则重置为0并跳过,直到找到一个使用位为0的页面进行替换。
- 优点:比FIFO更有效,考虑了页面的访问历史。
- 缺点:实现相对复杂,但仍然高效。
5. 最近未使用算法 (Least Recently Used, NRU)
- 概念:将页面分为四类:最近被访问且修改过、最近被访问但未修改、未被访问但修改过、未被访问且未修改。优先替换未被访问且未修改的页面。
- 优点:简单且有效,适用于多数情况。
- 缺点:不如LRU准确,但实现较简单。
6. 最近最少使用算法 (Least Frequently Used, LFU)
- 概念:选择访问次数最少的页面进行替换。
- 优点:适用于某些特定应用场景。
- 缺点:可能会保留一些短期频繁访问但不再使用的页面,导致性能下降。
7. 最少频率未使用算法 (Most Recently Used, MRU)
- 概念:选择最近被使用的页面进行替换。
- 优点:适用于某些特定应用场景,如缓存等。
- 缺点:一般情况下不如LRU和FIFO。
8. 随机页面替换算法 (Random)
- 概念:随机选择一个页面进行替换。
- 优点:实现非常简单。
- 缺点:性能较差,缺乏智能选择机制。
网络
20、每次https请求的过程中会发生什么?
1. 建立TCP连接
客户端与服务器建立TCP连接:HTTPS在应用层使用SSL/TLS协议,而在传输层则使用TCP协议。首先,客户端和服务器通过三次握手建立一个TCP连接。
2. SSL/TLS握手
- 客户端发送“ClientHello”消息:客户端向服务器发送一个“ClientHello”消息,其中包含客户端支持的SSL/TLS版本、加密算法套件(cipher suites)、压缩方法以及一个随机数。
- 服务器回应“ServerHello”消息:服务器响应一个“ServerHello”消息,其中包含服务器选择的SSL/TLS版本、加密算法套件、压缩方法以及一个随机数。
- 服务器证书:服务器发送它的数字证书给客户端。这个证书由受信任的证书颁发机构(CA)签名,并包含服务器的公钥和其他信息。
- (可选)服务器密钥交换:视使用的加密算法而定,服务器可能发送附加的密钥交换信息。
- 服务器“Hello Done”消息:服务器发送一个“ServerHelloDone”消息,表明服务器的握手部分完成。
- 客户端证书验证:客户端验证服务器证书的有效性和真实性。
- 客户端密钥交换:客户端生成一个预主密钥(pre-master secret),并用服务器的公钥加密,然后发送给服务器。
- (可选)客户端证书:视使用的SSL/TLS版本和配置而定,客户端可能会发送它自己的数字证书给服务器,以便进行双向认证。
- 生成会话密钥:双方使用协商的预主密钥和随机数生成对称会话密钥。此对称密钥将用于加密随后的会话数据。
- 客户端“Finished”消息:客户端发送一个“Finished”消息,表示客户端握手部分完成。这个消息由会话密钥加密,并包含所有握手消息的摘要。
- 服务器“Finished”消息:服务器也发送一个“Finished”消息,表示服务器握手部分完成。这个消息同样由会话密钥加密,并包含所有握手消息的摘要。
3. 加密的HTTP请求/响应
- 加密数据传输:现在,客户端和服务器之间的通信使用对称会话密钥进行加密。客户端发送HTTP请求时,先将请求数据用会话密钥加密,然后通过TCP连接发送到服务器。
- 服务器处理请求:服务器接收到加密的HTTP请求后,用会话密钥解密,处理请求,生成响应。
- 加密响应数据:服务器将响应数据用会话密钥加密,然后通过TCP连接发送回客户端。
- 客户端解密响应数据:客户端接收到加密的响应数据后,用会话密钥解密,得到实际的HTTP响应内容。
4. 关闭连接
关闭TCP连接:通常在HTTP/1.1协议中,连接会保持一段时间以便处理后续请求。完成所有请求和响应后,客户端和服务器通过四次挥手关闭TCP连接。
21、tls握手的过程详细讲一下?
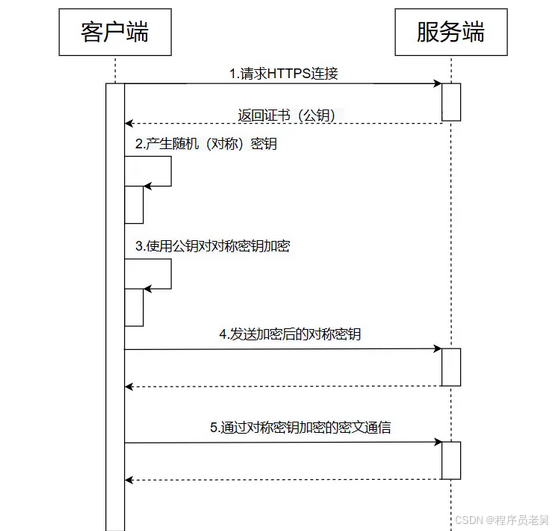
- 客户端向服务端发起第一次握手请求,告诉服务端客户端所支持的SSL的指定版本、加密算法及密钥长度等信息。
- 服务端将自己的公钥发给数字证书认证机构,数字证书认证机构利用自己的私钥对服务器的公钥进行数字签名,并给服务器颁发公钥证书。
- 服务端将证书发给客户端。
- 客服端利用数字认证机构的公钥,向数字证书认证机构验证公钥证书上的数字签名,确认服务器公开密钥的真实性。
- 客户端使用服务端的公开密钥加密自己生成的对称密钥,发给服务端。
- 服务端收到后利用私钥解密信息,获得客户端发来的对称密钥。
- 通信双方可用对称密钥来加密解密信息。
22、具体有哪些对称加密算法和非对称加密算法?
对称加密算法
对称加密算法使用相同的密钥进行加密和解密。
- DES (Data Encryption Standard)
- 密钥长度:56位
- 块大小:64位
- 优点:曾经广泛使用
- 缺点:密钥长度太短,容易被破解
- 3DES (Triple DES)
- 密钥长度:112或168位
- 块大小:64位
- 优点:通过三次DES加密增强安全性
- 缺点:计算速度较慢
- AES (Advanced Encryption Standard)
- 密钥长度:128、192或256位
- 块大小:128位
- 优点:安全性高,速度快,广泛使用
- 缺点:无明显缺点
- Blowfish
- 密钥长度:32到448位(常用128位)
- 块大小:64位
- 优点:速度快,灵活的密钥长度
- 缺点:块大小较小
- Twofish
- 密钥长度:128、192或256位
- 块大小:128位
- 优点:安全性高,适用于硬件和软件实现
- 缺点:较复杂
- RC4
- 密钥长度:1到2048位(常用40到128位)
- 流加密算法
- 优点:简单且快速
- 缺点:存在已知的弱点,不推荐新项目使用
- ChaCha20
- 密钥长度:256位
- 流加密算法
- 优点:速度快,安全性高,适用于硬件和软件实现
- 缺点:无明显缺点
非对称加密算法
非对称加密算法使用不同的密钥进行加密和解密,通常包括公钥和私钥。
- RSA (Rivest–Shamir–Adleman)
- 密钥长度:1024、2048、4096位(推荐2048位或更高)
- 优点:安全性高,广泛使用
- 缺点:密钥生成和加解密速度较慢
- DSA (Digital Signature Algorithm)
- 密钥长度:1024、2048、3072位(推荐2048位或更高)
- 优点:用于数字签名
- 缺点:仅用于签名,不用于加密
- ECC (Elliptic Curve Cryptography)
- 密钥长度:160到521位(常用256位)
- 优点:相对于RSA,提供相同安全性所需的密钥长度更短,速度更快
- 缺点:实现复杂,使用相对较少
- ElGamal
- 密钥长度:与RSA相当
- 优点:基于离散对数问题,适用于加密和签名
- 缺点:密钥和密文较长,速度较慢
- Diffie-Hellman (DH)
- 密钥长度:与RSA相当
- 优点:用于密钥交换
- 缺点:本身不用于加密,仅用于密钥协商
对称加密与非对称加密的结合使用
在实际应用中,对称加密和非对称加密常常结合使用,以利用两者的优点。
- 混合加密:使用非对称加密算法(如RSA)来加密对称加密算法(如AES)的会话密钥,然后使用对称加密算法来加密实际数据。这样可以既保证数据传输的安全性,又提高加解密速度。
- 数字签名和证书:使用非对称加密算法(如RSA或DSA)生成数字签名,验证数据的完整性和发送方的身份,同时使用证书来管理和分发公钥。
23、你知道什么是mtu吗?
MTU的基本概念
- 定义:MTU是指网络层协议能够传输的最大数据包(或帧)的大小。超过这个大小的数据包会被拆分成多个较小的片段进行传输。
- 单位:字节。
不同网络的MTU值
不同类型的网络有不同的MTU值。
- 以太网:常见的MTU值是1500字节。
- Wi-Fi(IEEE 802.11):典型的MTU值也是1500字节。
- PPP(Point-to-Point Protocol):常见的MTU值是576字节。
- IPv6:最小MTU值是1280字节。
MTU的重要性
MTU的大小对网络性能有显著影响:
- 传输效率:较大的MTU值可以减少数据包的数量,减少协议头的开销,提高传输效率。然而,过大的MTU值可能会导致网络中转设备的处理负担增加。
- 数据包碎片化:如果数据包大小超过路径中某段链路的MTU值,数据包将被分片(fragmentation)。分片会增加网络开销,并且重组分片需要额外的处理。
- 网络性能:合理设置MTU值可以优化网络性能,避免过多的分片和重新组装操作。
MTU的设置与调整
MTU值可以在网络接口(如以太网接口、无线接口等)上进行配置。配置MTU值时需要考虑以下因素:
- 网络类型:根据网络的类型选择合适的MTU值。例如,以太网通常使用1500字节的MTU值。
- 路径MTU发现(Path MTU Discovery, PMTUD):这是一个机制,用于发现路径中所有链路的最小MTU值,并动态调整数据包的大小以避免分片。PMTUD通过发送带有“不分片”标志的ICMP包来发现路径上的最小MTU。
- MTU黑洞问题:在某些情况下,ICMP包可能被网络中的某些设备(如防火墙)丢弃,导致PMTUD无法正常工作,称为MTU黑洞问题。此时可以手动调整MTU值来解决问题。
如何检测和调整MTU值
在不同操作系统上,可以使用不同的命令来查看和调整MTU值。例如:
- Linux:
- 查看MTU值:ifconfig eth0
- 修改MTU值:sudo ifconfig eth0 mtu 1400
- Windows:
- 查看MTU值:netsh interface ipv4 show subinterfaces
- 修改MTU值:netsh interface ipv4 set subinterface "Local Area Connection" mtu=1400 store=persistent
24、针对游戏开发你觉得tcp和udp哪个更好?
TCP
优点:
- 可靠性:TCP提供可靠的数据传输,确保数据包按顺序到达且没有丢失。
- 流控制:TCP具有流控制机制,防止网络拥塞。
- 错误检测和纠正:TCP能够检测并纠正数据传输中的错误。
缺点:
- 延迟:TCP的可靠性机制(如重传和确认)会增加延迟,这对于需要快速响应的游戏(如实时射击游戏)来说可能是一个问题。
- 头部开销:TCP的数据包头部较大,相对于UDP增加了一些开销。
- 连接管理:TCP需要建立和维护连接,这也会增加一定的复杂性和开销。
适用场景:
- 回合制游戏:如棋牌类、策略类游戏,这类游戏对实时性要求不高,更注重数据的可靠传输。
- 网络聊天和登录验证:需要确保消息的可靠传输和顺序性。
UDP
优点:
- 低延迟:UDP不需要建立连接和确认机制,传输速度快,延迟低,适合对实时性要求高的应用。
- 头部开销小:UDP的数据包头部较小,传输效率高。
- 灵活性:UDP允许应用程序自行处理数据包的顺序和重传,提供了更大的灵活性。
缺点:
- 不可靠:UDP不保证数据包的顺序和完整性,数据包可能丢失、重复或乱序到达。
- 无流控制:UDP没有内置的流控制机制,可能导致网络拥塞。
适用场景:
- 实时游戏:如射击游戏、赛车游戏、多人在线竞技游戏(MOBA),这类游戏需要低延迟的实时传输,允许少量数据包丢失。
- 实时音视频传输:如游戏内的语音聊天,要求低延迟且能容忍部分数据丢失。
手撕
26、有一个链表,比如说12345,然后希望重排序成15243?
思路
- 找到链表的中间节点,可以使用快慢指针的方法找到中间节点。
- 将链表分成两个部分,前半部分为1->2,后半部分为3->4->5。
- 将后半部分链表反转,得到5->4->3。
- 合并两个链表,交替插入节点,得到1->5->2->4->3。
参考代码
C++
#include <iostream> struct ListNode { int val; ListNode* next; ListNode(int x) : val(x), next(nullptr) {} }; ListNode* reverseList(ListNode* head) { ListNode* prev = nullptr; ListNode* curr = head; while (curr) { ListNode* next = curr->next; curr->next = prev; prev = curr; curr = next; } return prev; } void reorderList(ListNode* head) { if (!head || !head->next) { return; } // 找到链表的中间节点 ListNode* slow = head; ListNode* fast = head; while (fast->next && fast->next->next) { slow = slow->next; fast = fast->next->next; } // 将链表分成两个部分 ListNode* secondHalf = slow->next; slow->next = nullptr; // 反转后半部分链表 secondHalf = reverseList(secondHalf); // 合并两个链表 ListNode* p1 = head; ListNode* p2 = secondHalf; while (p2) { ListNode* tmp1 = p1->next; ListNode* tmp2 = p2->next; p1->next = p2; p2->next = tmp1; p1 = tmp1; p2 = tmp2; } } void printList(ListNode* head) { ListNode* curr = head; while (curr) { std::cout << curr->val << " "; curr = curr->next; } std::cout << std::endl; } int main() { ListNode* head = new ListNode(1); head->next = new ListNode(2); head->next->next = new ListNode(3); head->next->next->next = new ListNode(4); head->next->next->next->next = new ListNode(5); std::cout << "Original list: "; printList(head); reorderList(head); std::cout << "Reordered list: "; printList(head); return 0; }粉丝福利, 免费领取C/C++ 开发学习资料包、技术视频/项目代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发/音视频开发/Qt开发/游戏开发/Linuxn内核等进阶学习资料和最佳学习路线)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
