
阅读量:0
摘要
本实验报告详细阐述了在“大数据技术原理”课程中进行的MapReduce编程实验。实验环境基于Hadoop平台和Ubuntu操作系统。实验的核心内容包括使用MapReduce编程模型实现文件的合并去重、排序以及对给定表格信息的挖掘。实验过程中,我们首先在Hadoop分布式文件系(HDFS)中创建了必要的输入和输出目录,并上传了相应的数据文件。随后,编写了MapReduce程序,并通过Java语言实现了数据处理逻辑。实验中遇到的问题包括Hadoop的启动顺序、jar文件的导出位置以及程序中包的导入等,这些问题都通过相应的解决方案得到了妥善处理。
实验结果表明,MapReduce模型能够有效地处理大规模数据集,通过Map函数和Reduce函数的协同工作,实现了数据的高效合并、去重和排序。本实验不仅加深了对MapReduce编程原理的理解,而且提升了解决实际大数据问题的能力。
关键词:MapReduce;Hadoop;大数据;数据处理
一.实验环境:
- Hadoop
- Ubuntu
二.实验内容与完成情况:
1.编程实现文件合并和去重:



(1)先删除HDFS中与当前Linux用户hadoop对应的input和output目录:

(2)在HDFS中新建与当前Linux用户hadoop对应的input目录:
![]()
(3)创建A.txt B.txt:
![]()
(4)上传到HDFS:
![]()
![]()
(5)代码:
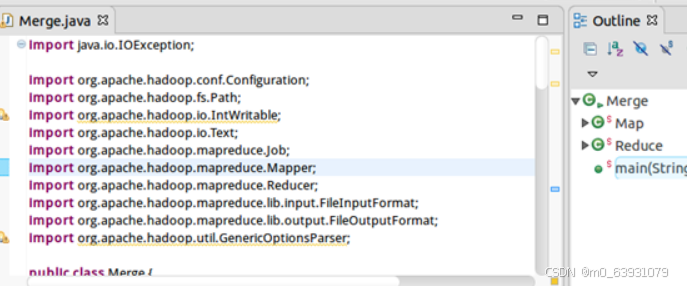
(6)运行结果:
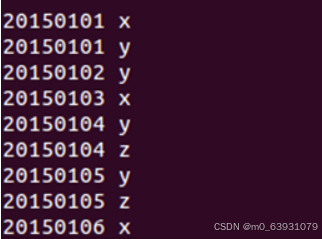
2.编程实现对输入文件排序


(1)先删除HDFS中与当前Linux用户hadoop对应的input和output目录:

(2)在HDFS中新建与当前Linux用户hadoop对应的input目录:
![]()
(3)创建test1.txt test2.txt test3:
![]()
![]()
(4)代码:
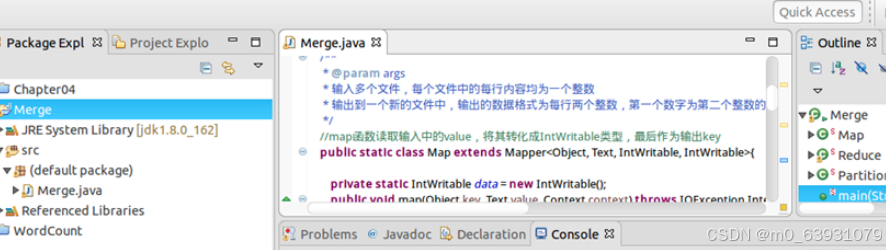
(5)结果:
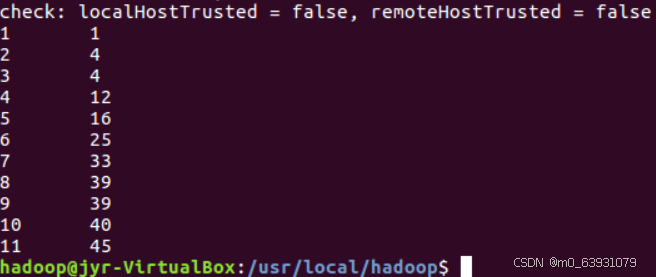
3.对给定表格信息挖掘:
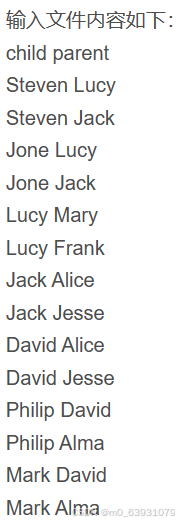

(1)先删除HDFS中与当前Linux用户hadoop对应的input和output目录:

(2)在HDFS中新建与当前Linux用户hadoop对应的input目录:
![]()
(3)创建test1.txt
代码:
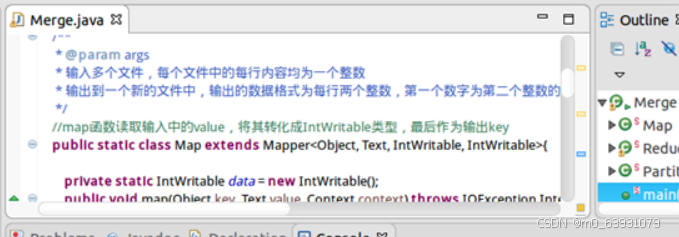
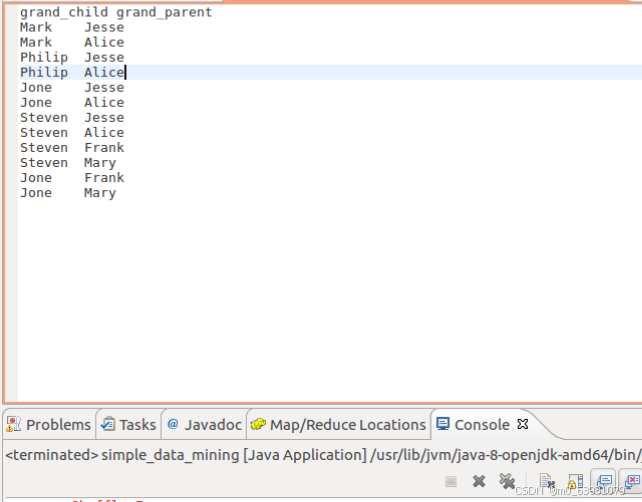
(4)结果:
三.出现的问题及解决方案:
1.实验开始编写程序之前,需要将hadoop启动方才可以继续编写程序。
2.程序导出的时候,需要将jar文件导出到相应的hadoop程序的文件夹下,这样方便程序的运行。
3.编写程序的时候,需要将导入的包一一对应,确保所有的包都导入到程序之中。
四.总结:
MapRedece分为两部分,一个是Map函数,一个是Reduce函数。Map函数接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。 Reduce函数接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
