
阅读量:0
个人学习笔记,课程为数学建模清风付费课程
目录
一、为什么引入ARCH模型?
数据呈现波动聚集性(volatility clustering) 长期来看时间序列平稳,短期来看不平稳,存在异方差

二、 ARCH模型
2.1概念
ARCH 模型 ( Autoregressive conditional heteroskedasticity model )全称“自回归条件异方差模型”,在现代高频金融时间序列中,数据经常出现波动性聚集的特点,但从长期来看数据是平稳的,即长期方差(无条件方差)是定值,但从短期来看方差是不稳定的,我们称这种异方差为条件异方差。传统的时间序列模型如ARMA 模型识别不出来这一特征。
ARCH 模型由美国加州大学恩格尔 (Engle) 教授 1982 年在《计量经济学》杂志(Econometrica )的一篇论文中首次提出,此后在计量经济领域中得到迅速发展,恩格尔教授也于2003年获诺贝尔经济学奖。
2.2适用情形
数据呈现波动聚集性(volatility clustering)长期来看时间序列平稳,短期来看不平稳,存在异方差
2.3条件异方差

因为加法条件异方差的性质不容易探究,因此我们所说的ARCH模型均是下面的乘法条件异方差模型。另外,大家可以看出,实际上ARCH模型是在ARMA模型的基础上提出来的,两者的区别在于扰动项的设置不同,在ARMA模型中扰动项是最简单的白噪声序列。
2.4ARCH(1)模型和ARCH(q)模型

三、GARCH(p,q)模型
3.1ARCH(q)效应和GARCH(p,q)效应

3.2GARCH效应检验

3.2.1检验GARCH效应:LM检验

四、深成B指时间序列的预测建模
4.1摘要
深证成份股指数是深圳证券交易所编制的一种成份股指数,是从上市的所有股票中抽取具有市场代表性的40家上市公司的股票作为计算对象,并以流通股为权数计算得出的加权股价指数,综合反映深交所上市 A、B股的股价走势。成份B股指数变更为包含深圳市场10只B股的B股总收益指数。我们将时间区间选取为2014年1月至2018年5月,共计1064个交易日的收盘价数据,在下文中,分别建立了ARMA模型和GARCH模型对其收益率进行了预测,得到了良好的结果。 ( 代号:399003 )
4.2原始数据时间序列图
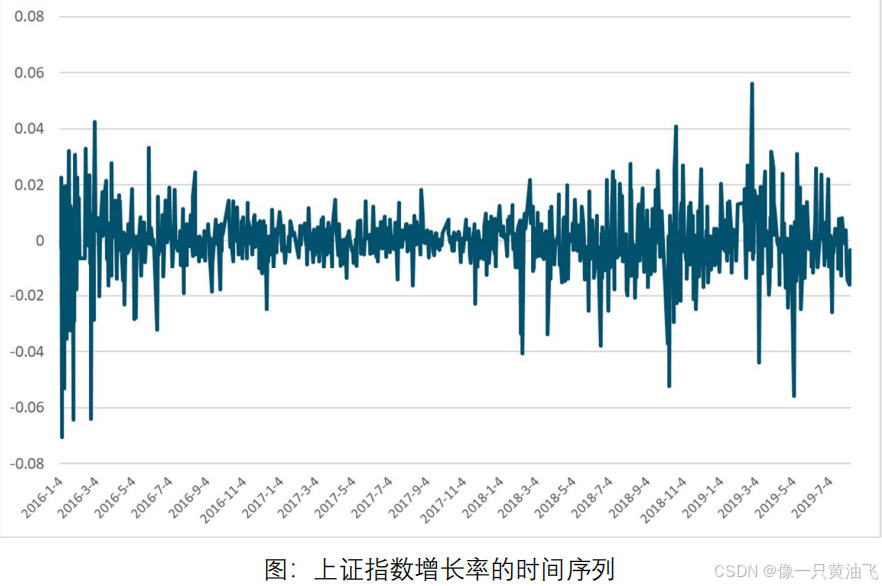
根据2014年1月至2018年5月共计1064个交易日的收盘价数据,我们做出了B股指数的时序图从图中可以看出,指数序列非平稳,尤其是2015年到2016年之间波动十分剧烈。

4.3收益率序列图
因此,我们对原始数据进行处理,计算其收益率,所用公式如下:

4.4单位根检验
下面,我们进一步检验收益率序列有无单位根,利用Stata做ADF检验,得到的结果如下表所示:

ADF检验的原假设:数据是单位根序列,备择假设:数据是平稳序列 注意:平稳数据建模用ARMA模型(或者ARIMA(p,0,q)),单位根数据建模用ARIMA模型。上表结果显示p值为0,在99%的置信水平下拒绝原假设,故序列平稳。
4.5ACF和PACF图

由ACF图和PACF图,3阶和8阶相关系数较为显著,8阶之后的显著可能由于误差导致,不予考虑。 (1阶虽然显著,但其包含的信息太少,我们对高频数据进行建模时往往不考虑) 因此,为保证模型选取的准确性,我们拟合了四个模型并从中选取最优的模型。其中Model1:ARMA(3,3);Model2:ARMA(8,8);Model3:ARMA(3,8);Model4:ARMA(8,3)。
4.6AIC和BIC选择模型
太多的滞后项会增加预测的误差,太少的滞后项又会遗失部分相关信息。经验和理论知识通常是用来决定滞后项阶数的最好方式,然而,依然存在着一些准则帮助我们确定滞后的阶数。为了确定哪个模型拟合效果最好,我们分别估计出了这四种模型,并给出了对应的AIC和BIC值,我们认为AIC与BIC值较小,模型拟合效果较好。

我们根据AIC和BIC准则可知,这四个模型中应选取Model1,即ARMA(3,3)模型。此时,AIC值和BIC值的平均值最小。
4.7ARMA(3,3)模型的估计结果

4.8残差序列的分布直方图

4.9检验残差是否为白噪声
接着,我们使用Ljung‐Box Q检验,来检验ARMA模型的有效性,检验结果为下表所示:

滞后12项的检验值的P值大于0.05,在5%的显著性水平下并不能拒绝原假设。故可以认为通过白噪声检验,即我们认为回归得到的残差不存在较明显的相关性,因此模型有效性较好。
4.10对残差的平方进行LM检验

4.11利用AIC、BIC选择合适的模型
通过比较AIC和BIC,最终我们选择使用带有GARCH(1,1)且 vt服从t分布的扰动项的ARMA(3,3)模型进行估计。
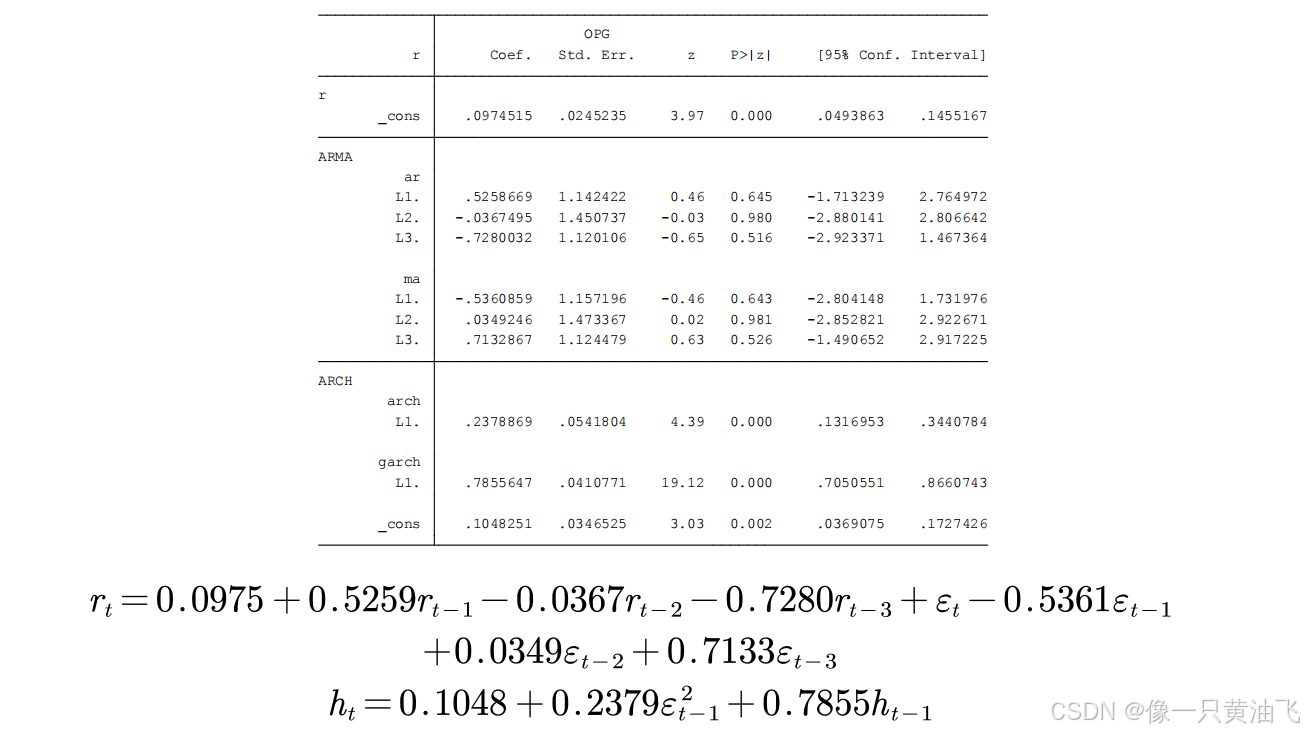
 4.12GARCH模型估计的结果
4.12GARCH模型估计的结果
4.13预测结果

五、总结

