
阅读量:0
PatchCore:工业异常检测中的全面召回

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv10训练自己的数据集(交通标志检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
相关介绍
- [1] PatchCore 源代码地址:https://github.com/amazon-science/patchcore-inspection.git
- [2] PatchCore 论文地址:https://arxiv.org/abs/2106.08265
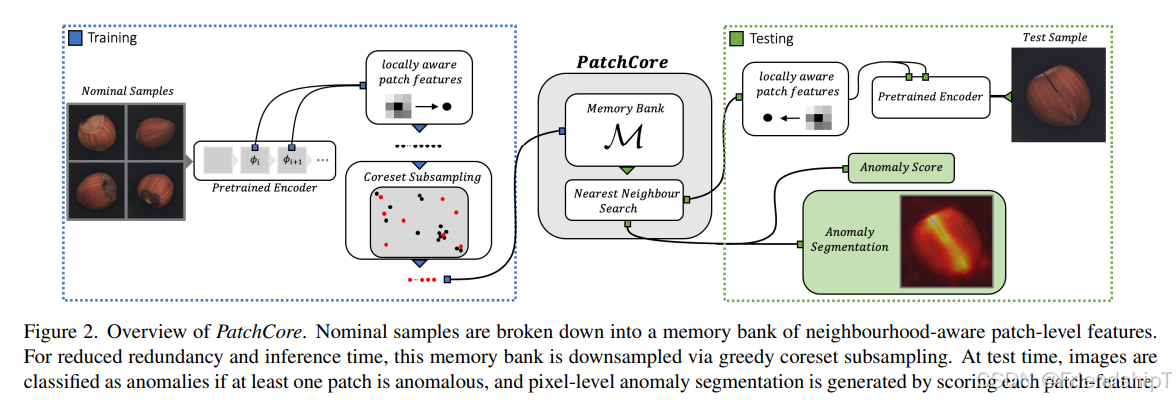
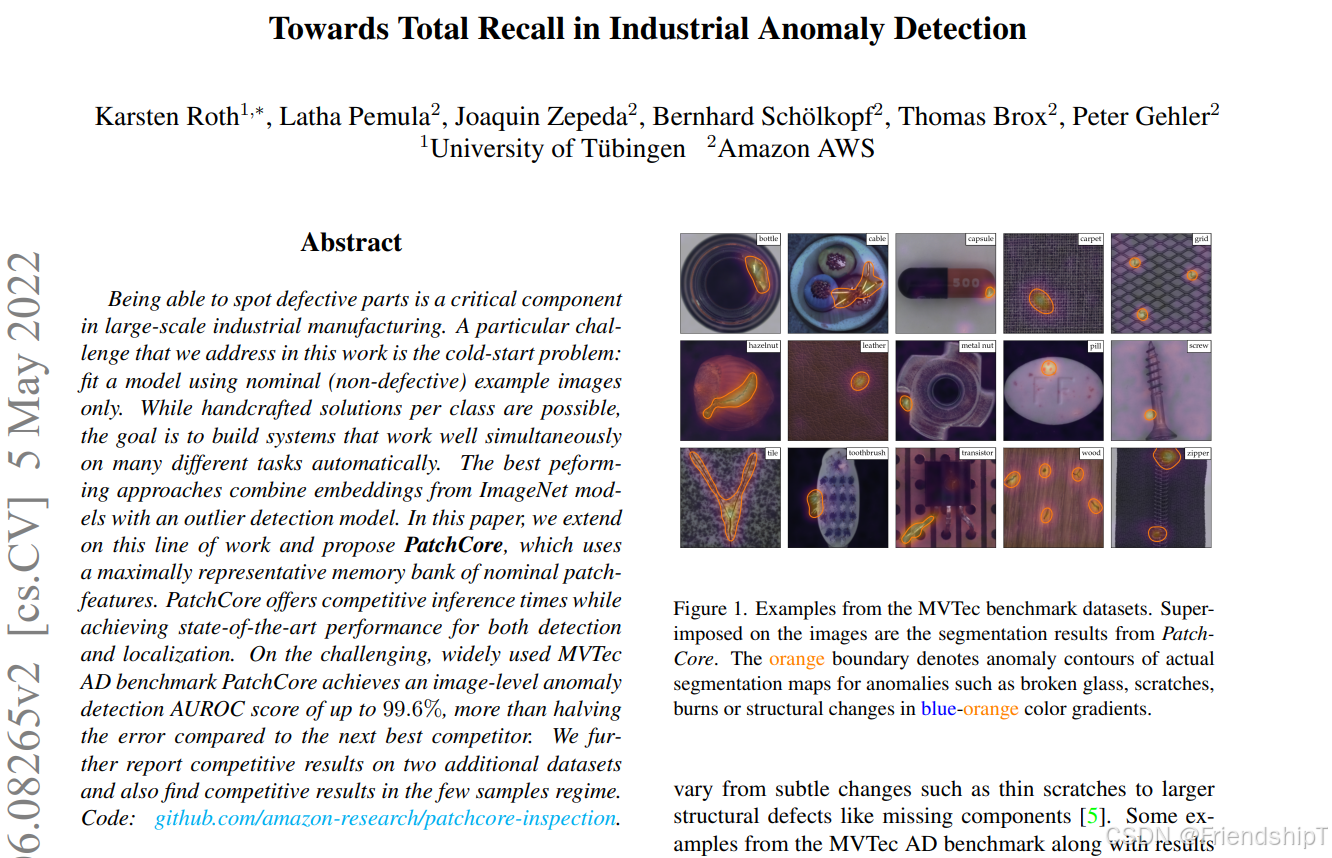
PatchCore是一种用于异常检测的方法,它特别适用于工业视觉检查和其他需要在未见过的正常样本上进行训练的应用场景。这种方法是一种无监督或半监督学习方法。
PatchCore的工作原理:
- 数据预处理:将输入图像分割成多个局部区域(patch)。
- 特征提取:使用预先训练好的卷积神经网络(CNN)提取每个patch的特征向量。
- 背景建模:构建一个背景模型来估计正常patch的分布。这通常是通过计算各个层激活的相似性矩阵,并使用这些矩阵来构建近邻图。
- 异常得分计算:对于一个新的输入图像,计算其patch与背景模型之间的距离,从而得到异常得分。如果得分高于某个阈值,则认为该图像存在异常。
优点:
- 简单快速:不需要对特定任务进行额外的训练,只需要预先训练好的模型。
- 适应性强:可以应用于多种类型的图像数据和不同领域的应用场景。
- 资源效率高:内存占用相对较小,因为只需要存储少量的参考样本。
- 可扩展性:能够随着新的正常样本的增加而更新背景模型。
缺点:
- 依赖于高质量的特征提取器:特征提取的质量直接影响到异常检测的效果。
- 阈值设定:需要人为设置阈值来区分正常和异常样本,这可能需要一定的专业知识和经验。
- 对背景模型的选择敏感:不同的背景建模技术可能会导致显著不同的结果。
- 可能忽略全局信息:由于是基于局部patch进行分析,因此可能会忽略图像中的全局结构信息。
总体来说,PatchCore提供了一种高效且易于实现的异常检测方法,尤其适合于那些难以获得大量标注异常样本的情况。然而,在应用时也需要根据具体问题的特点选择合适的参数和背景模型。
实验环境
click>= 8.0.3 # cudatoolkit>= 10.2 faiss-cpu #faiss-gpu matplotlib>= 3.5.0 pillow>= 8.4.0 pretrainedmodels>= 0.7.4 torch>= 1.10.0 scikit-image>= 0.18.3 scikit-learn>= 1.0.1 scipy>= 1.7.1 torchvision>= 0.11.1 tqdm>= 4.62.3 项目地址
- PatchCore 源代码地址:https://github.com/amazon-science/patchcore-inspection.git
Linux
git clone https://github.com/amazon-science/patchcore-inspection.git cd patchcore-inspection pip install -r requirements.txt Windows
请到
https://github.com/amazon-science/patchcore-inspection.git网站下载源代码zip压缩包。
cd patchcore-inspection pip install -r requirements.txt 项目结构
patchcore-inspection-main ├─bin │ ├─load_and_evaluate_patchcore.py │ └─run_patchcore.py ├─checkpoints ├─images ├─models │ ├─IM224_Ensemble_L2-3_P001_D1024-384_PS-3_AN-1 │ ├─IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1 │ ├─IM320_Ensemble_L2-3_P001_D1024-384_PS-3_AN-1 │ ├─IM320_Ensemble_L2-3_P001_D1024-384_PS-5_AN-5 │ ├─IM320_WR50_L2-3_P001_D1024-1024_PS-3_AN-1 │ └─IM320_WR50_L2-3_P001_D1024-1024_PS-5_AN-3 ├─mvtec │ ├─bottle │ │ ├─ground_truth │ │ │ ├─broken_large │ │ │ ├─broken_small │ │ │ └─contamination │ │ ├─test │ │ │ ├─broken_large │ │ │ ├─broken_small │ │ │ ├─contamination │ │ │ └─good │ │ └─train │ │ └─good ├─src │ └─patchcore │ ├─datasets │ │ └─__pycache__ │ ├─networks │ └─__pycache__ └─test 具体用法
准备数据
- 本文以MVTEC公开数据集中的bottle数据集进行示例。
├─mvtec │ ├─bottle │ │ ├─ground_truth │ │ │ ├─broken_large │ │ │ ├─broken_small │ │ │ └─contamination │ │ ├─test │ │ │ ├─broken_large │ │ │ ├─broken_small │ │ │ ├─contamination │ │ │ └─good │ │ └─train │ │ └─good 

进行训练
# 训练 python bin/run_patchcore.py --gpu 0 --seed 0 --save_patchcore_model --save_segmentation_images --log_group IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1_S0 --log_project MVTecAD_Results model patch_core -b wideresnet50 -le layer2 -le layer3 --pretrain_embed_dimension 1024 --target_embed_dimension 1024 --anomaly_scorer_num_nn 1 --patchsize 3 sampler -p 0.1 approx_greedy_coreset dataset --resize 256 --imagesize 224 --subdatasets "bottle" mvtec patchcore-inspection-main\mvtec patchcore-inspection-main>python bin/run_patchcore.py --gpu 0 --seed 0 --save_patchcore_model --save_segmentation_images --log_group IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1_S0 --log_project MVTecAD_Results model patch_core -b wideresnet50 -le layer2 -le layer3 --pretrain_embed_dimension 1024 --target_embed_dimension 1024 --anomaly_scorer_num_nn 1 --patchsize 3 sampler -p 0.1 approx_greedy_coreset dataset --resize 256 --imagesize 224 --subdatasets "bottle" mvtec INFO:__main__:Training models (1/1) Computing support features...: 3%|█▍ | 3/105 [00:21<09:38, 5.67s/it Computing support features...: 5%|██▍ | 5/105 [00:21<04:39, 2.80s/i Computing support features...: 7%|███▍ | 7/105 [00:22<02:41, 1.65s/ Computing support features...: 9%|████▎ | 9/105 [00:22<01:41, 1.06s Computing support features...: 10%|█████▏ | 11/105 [00:22<01:07, 1.40 Computing support features...: 12%|█ Subsampling...: 3%|█▌ | 421/16385 [00:00<00:14, 1095.01it/sSubsampling...: 3%|█▉ | 538/16385 [00:00<00:14, 1120.04it/sSubsampling...: 4%|██▍ | 652/16385 [00:00<00:13, 1124.00it/Subsampling...: 5%|██▊ | 767/16385 [00:00<00:13, 1129.79it/Subsampling...: 5%|███▏ | 882/16385 [00:00<00:13, 1132.67itSubsampling...: 6%|███▋ | 999/16385 [00:00<00:13, 1144.19itSubsampling...: 7%|████ | 1115/16385 [00:01<00:13, 1147.80itSubsampling...: 8%|████▍ | 1230/16385 [00:01<00:13, 1145.92iSubsampling...: 8%|████▊ | 1345/16385 [00:01<00:13, 1141.07iSubsampling...: 9%|█████▎ | 1460/16385 [00:01<00:13, 1137.73Subsampling...: 10%|█████▋ | 1577/16385 [00:01<00:12, 1144.88Subsampling...: 10%|██████ | 1692/16385 [00:01<00:12, 1140.60Subsampling...: 11%|██████▌ | 1807/16385 [00:01<00:12, 1137.4Subsampling...: 12%|██████▉ INFO:__main__:Embedding test data with models (1/1) Inferring...: 2%|█▋ | 1/42 [00:21<14:41, 21.49s/itInferring...: 5%|███▎ | 2/42 [00:21<06:05, 9.13s/Inferring...: 7%|████▉ | 3/42 [00:22<03:22, 5.18sInferring...: 10%|██████▌ | 4/42 [00:22<02:05, 3.3Inferring...: 12%|████████▏ | 5/42 [00:23<01:23, 2Inferring...: 14%|█████████▊ | 6/42 [00:23<00:58, Inferring...: 17%|███████████▌ | 7/42 [00:24<00:42,Inferring...: 19%|█████████████▏ | 8/42 [00:24<00:3Inferring...: 21%|██████████████▊ | 9/42 [00:25<00:Inferring...: 24%|█ Generating Segmentation Images...: 2%|█▏ | 2/83 [00:00<00:29, 2.76it/sGenerating Segmentation Images...: 4%|█▋ | 3/83 [00:01<00:28, 2.82it/sGenerating Segmentation Images...: 5%|██▎ | 4/83 [00:01<00:30, 2.56it/Generating Segmentation Images...: 6%|██▉ | 5/83 [00:01<00:28, 2.69it/Generating Segmentation Images...: 7%|███▍ | 6/83 [00:02<00:27, 2.76itGenerating Segmentation Images...: 8%|████ | 7/83 [00:02<00:27, 2.78itGenerating Segmentation Images...: 10%|████▋ | 8/83 [00:02<00:26, 2.85iGenerating Segmentation Images...: 11%|█████▏ | 9/83 [00:03<00:25, 2.89Generating Segmentation Images...: 12%|█████▋ INFO:__main__:Computing evaluation metrics. INFO:__main__:instance_auroc: 1.000 INFO:__main__:full_pixel_auroc: 0.985 INFO:__main__:anomaly_pixel_auroc: 0.980 INFO:patchcore.patchcore:Saving PatchCore data. INFO:__main__: ----- INFO:patchcore.utils:instance_auroc: 1.000 INFO:patchcore.utils:full_pixel_auroc: 0.985 INFO:patchcore.utils:anomaly_pixel_auroc: 0.980 进行测试
#测试 python bin/load_and_evaluate_patchcore.py --gpu 0 --seed 0 --save_segmentation_images "evaluateAnswer/bottle" patch_core_loader -p "patchcore-inspection-main\model\MVTecAD_Results\IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1_S0_2\models\mvtec_bottle" dataset --resize 256 --imagesize 224 -d "bottle" mvtec "patchcore-inspection-main\mvtec" patchcore-inspection-main>python bin/load_and_evaluate_patchcore.py --gpu 0 --seed 0 --save_segmentation_images "evaluateAnswer/bottle" patch_core_loader -p "D:\tfx\mytest\patchcore-inspection-main\model\MVTecAD_Results\IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1_S0_2\models\mvtec_bottle" dataset --resize 256 --imagesize 224 -d "bottle" mvtec "D:\tfx\mytest\patchcore-inspection-main\mvtec" INFO:__main__:Command line arguments: bin/load_and_evaluate_patchcore.py --gpu 0 --seed 0 --save_segmentation_images evaluateAnswer/bottle patch_core_loader -p D:\tfx\mytest\patchcore-inspection-main\model\MVTecAD_Results\IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1_S0_2\models\mvtec_bottle dataset --resize 256 --imagesize 224 -d bottle mvtec INFO:__main__:Embedding test data with models (1/1) Inferring...: 2%|█▋ | 2/83 [00:21<12:15, 9.08s/itInferring...: 4%|██▍ | 3/83 [00:22<06:43, 5.05s/iInferring...: 5%|███▎ Generating Segmentation Images...: 2%|█▏ | 2/83 [00:00<00:33, 2.38it/sGenerating Segmentation Images...: 4%|█▋ | 3/83 [00:01<00:30, 2.64it/s Generating Segmentation Images...: 5%|██▎ Generating Segmentation Images...: 100%|████████████████████████████████████████INFO:__main__:Computing evaluation metrics. INFO:__main__:instance_auroc: 1.000 INFO:__main__:full_pixel_auroc: 0.985 INFO:__main__:anomaly_pixel_auroc: 0.980 INFO:__main__: ----- INFO:patchcore.utils:instance_auroc: 1.000 INFO:patchcore.utils:full_pixel_auroc: 0.985 INFO:patchcore.utils:anomaly_pixel_auroc: 0.980 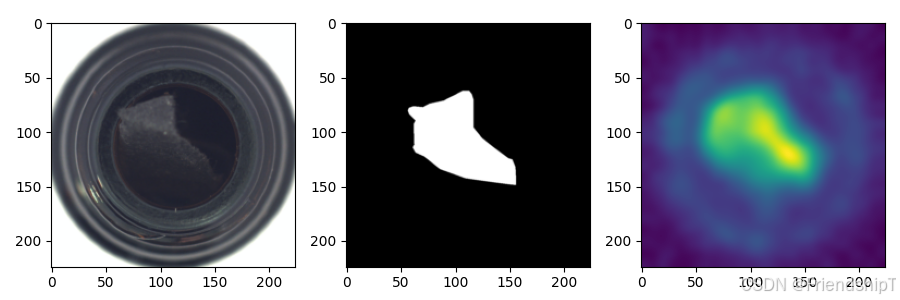
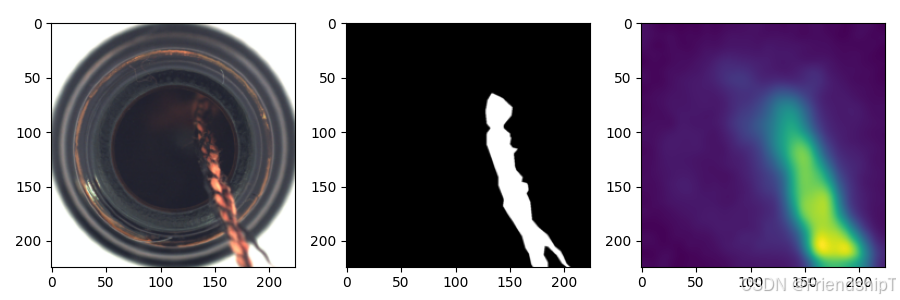
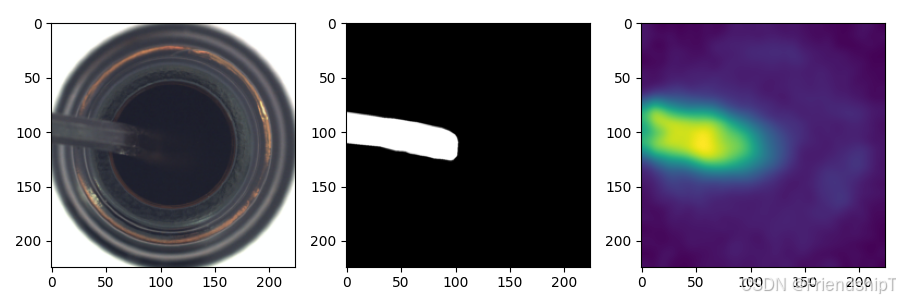
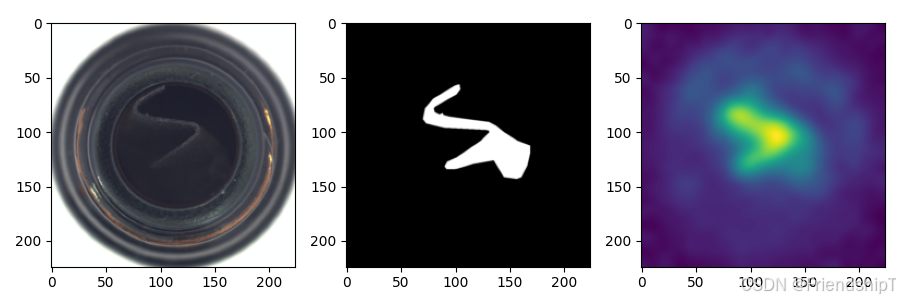
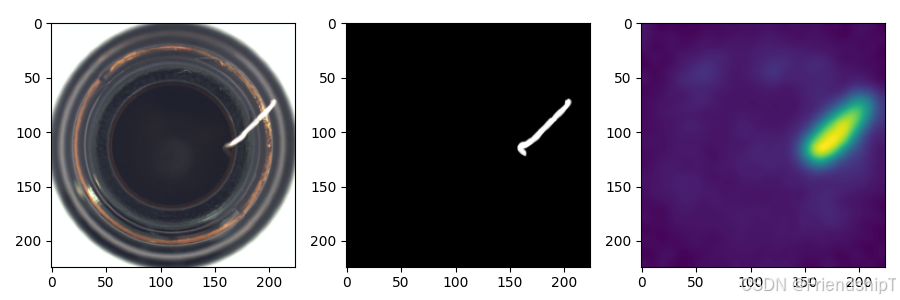
常见问题
ModuleNotFoundError: No module named ‘patchcore’
Traceback (most recent call last): File "run_patchcore.py", line 10, in <module> import patchcore.backbones ModuleNotFoundError: No module named 'patchcore' 解决方法
在运行命令前,先设置环境变量:
# linux export PYTHONPATH=src # windows set PYTHONPATH=src OMP: Error
OMP: Error #15: Initializing libomp140.x86_64.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://openmp.llvm.org/ 解决方法
在运行命令前,先设置环境变量:
# linux export KMP_DUPLICATE_LIB_OK=True # windows set KMP_DUPLICATE_LIB_OK=True AttributeError: ‘MVTecDataset’ object has no attribute ‘transform_std’
File "bin/run_patchcore.py", line 439, in <module> main() File "D:\Users\Main\anaconda3\envs\pc\lib\site-packages\click\core.py", line 1157, in __call__ return self.main(*args, **kwargs) File "D:\Users\Main\anaconda3\envs\pc\lib\site-packages\click\core.py", line 1078, in main rv = self.invoke(ctx) File "D:\Users\Main\anaconda3\envs\pc\lib\site-packages\click\core.py", line 1720, in invoke return _process_result(rv) File "D:\Users\Main\anaconda3\envs\pc\lib\site-packages\click\core.py", line 1657, in _process_result value = ctx.invoke(self._result_callback, value, **ctx.params) File "D:\Users\Main\anaconda3\envs\pc\lib\site-packages\click\core.py", line 783, in invoke return __callback(*args, **kwargs) File "bin/run_patchcore.py", line 170, in run patchcore.utils.plot_segmentation_images( File "D:\tfx\mytest\patchcore-inspection-main\src\patchcore\utils.py", line 51, in plot_segmentation_images image = image_transform(image) File "bin/run_patchcore.py", line 153, in image_transform dataloaders["testing"].dataset.transform_std AttributeError: 'MVTecDataset' object has no attribute 'transform_std' 解决方法
- 因为主干是基于imagenet数据集训练的,所以均值和方差都是imagenet,因此可以在patchcore/datasets/mvtec.py中,在类class MVTecDataset 的def init 的函数中加入下面两行
- 参考issues80:
in patchcore/datasets/mvtec.py in class MVTecDataset in def init add this rows:
self.transform_std = IMAGENET_STD self.transform_mean = IMAGENET_MEAN 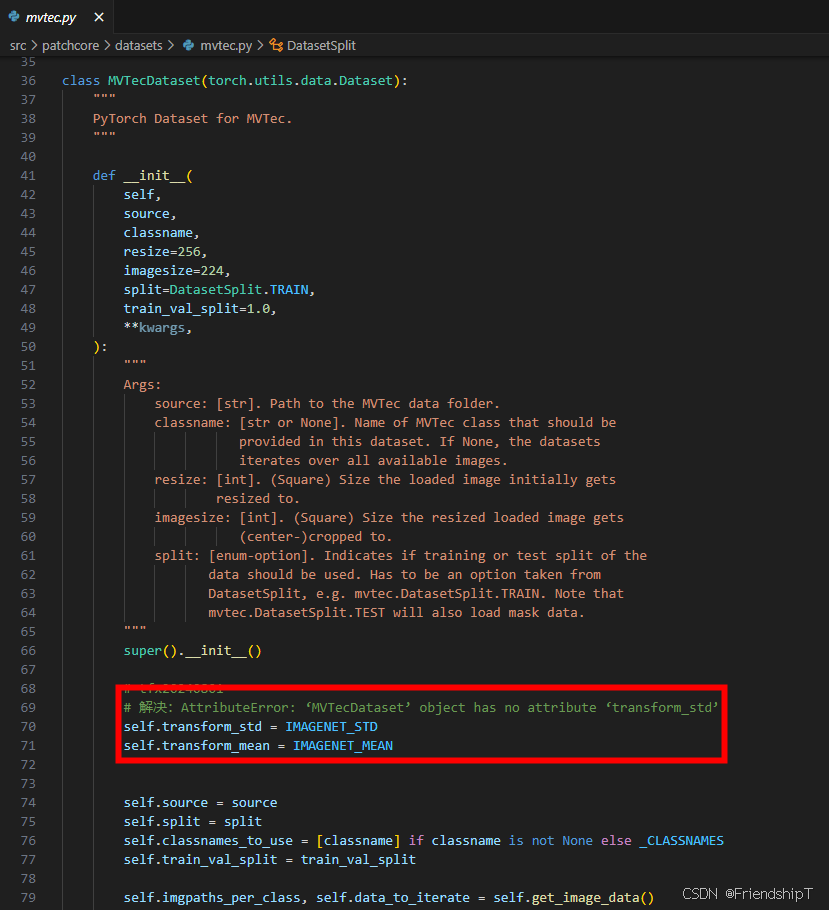
保存结果图时总是会将原图覆盖掉
- src/patchcore/utils.py代码存在bug,需要进行了修改,如下图所示。
# 解决:保存结果图时总是会将原图覆盖掉 folder_name = os.path.basename(os.path.dirname(image_path)) save_path = os.path.join(savefolder, folder_name) if not os.path.exists(save_path): os.makedirs(save_path) savename = os.path.join(save_path, os.path.basename(image_path)) 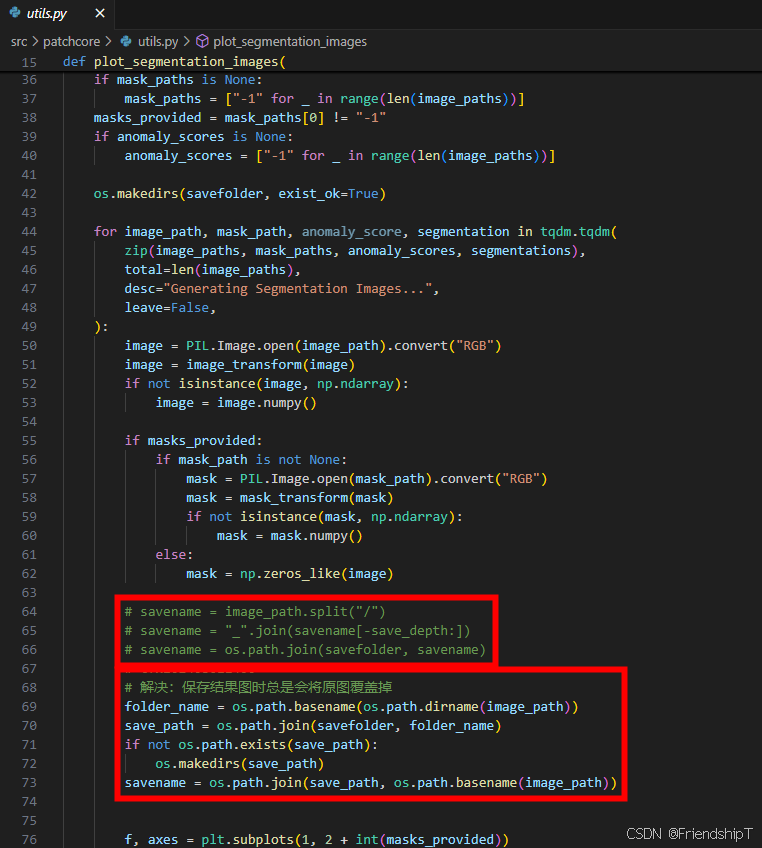
参考文献
[1] PatchCore 源代码地址:https://github.com/amazon-science/patchcore-inspection.git
[2] PatchCore 论文地址:https://arxiv.org/abs/2106.08265
[3] https://link.springer.com/content/pdf/10.1007/s11263-020-01400-4.pdf
[4] https://www.mvtec.com/company/research/datasets/mvtec-ad/
[5] https://blog.csdn.net/xiao3_tai/article/details/136504813
[6] https://blog.csdn.net/m0_63828250/article/details/137158892
[7] https://blog.csdn.net/WD_SS/article/details/139673512
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv10训练自己的数据集(交通标志检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
