阅读量:0
对象分割任务的目标是找到图像中目标对象的边界。实际应用例如自动驾驶汽车和医学成像分析。这里将使用PyTorch开发一个深度学习模型来完成多对象分割任务。多对象分割的主要目标是自动勾勒出图像中多个目标对象的边界。
对象的边界通常由与图像大小相同的分割掩码定义,在分割掩码中属于目标对象的所有像素基于预定义的标记被标记为相同。
目录
创建数据集
from torchvision.datasets import VOCSegmentation from PIL import Image from torchvision.transforms.functional import to_tensor, to_pil_image class myVOCSegmentation(VOCSegmentation): def __getitem__(self, index): img = Image.open(self.images[index]).convert('RGB') target = Image.open(self.masks[index]) if self.transforms is not None: augmented= self.transforms(image=np.array(img), mask=np.array(target)) img = augmented['image'] target = augmented['mask'] target[target>20]=0 img= to_tensor(img) target= torch.from_numpy(target).type(torch.long) return img, target from albumentations import ( HorizontalFlip, Compose, Resize, Normalize) mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] h,w=520,520 transform_train = Compose([ Resize(h,w), HorizontalFlip(p=0.5), Normalize(mean=mean,std=std)]) transform_val = Compose( [ Resize(h,w), Normalize(mean=mean,std=std)]) path2data="./data/" train_ds=myVOCSegmentation(path2data, year='2012', image_set='train', download=False, transforms=transform_train) print(len(train_ds)) val_ds=myVOCSegmentation(path2data, year='2012', image_set='val', download=False, transforms=transform_val) print(len(val_ds)) import torch import numpy as np from skimage.segmentation import mark_boundaries import matplotlib.pylab as plt %matplotlib inline np.random.seed(0) num_classes=21 COLORS = np.random.randint(0, 2, size=(num_classes+1, 3),dtype="uint8") def show_img_target(img, target): if torch.is_tensor(img): img=to_pil_image(img) target=target.numpy() for ll in range(num_classes): mask=(target==ll) img=mark_boundaries(np.array(img) , mask, outline_color=COLORS[ll], color=COLORS[ll]) plt.imshow(img) def re_normalize (x, mean = mean, std= std): x_r= x.clone() for c, (mean_c, std_c) in enumerate(zip(mean, std)): x_r [c] *= std_c x_r [c] += mean_c return x_r展示训练数据集示例图像
img, mask = train_ds[10] print(img.shape, img.type(),torch.max(img)) print(mask.shape, mask.type(),torch.max(mask)) plt.figure(figsize=(20,20)) img_r= re_normalize(img) plt.subplot(1, 3, 1) plt.imshow(to_pil_image(img_r)) plt.subplot(1, 3, 2) plt.imshow(mask) plt.subplot(1, 3, 3) show_img_target(img_r, mask) 

展示验证数据集示例图像
img, mask = val_ds[10] print(img.shape, img.type(),torch.max(img)) print(mask.shape, mask.type(),torch.max(mask)) plt.figure(figsize=(20,20)) img_r= re_normalize(img) plt.subplot(1, 3, 1) plt.imshow(to_pil_image(img_r)) plt.subplot(1, 3, 2) plt.imshow(mask) plt.subplot(1, 3, 3) show_img_target(img_r, mask)

创建数据加载器
通过torch.utils.data针对训练和验证集分别创建Dataloader,打印示例观察效果
from torch.utils.data import DataLoader train_dl = DataLoader(train_ds, batch_size=4, shuffle=True) val_dl = DataLoader(val_ds, batch_size=8, shuffle=False) for img_b, mask_b in train_dl: print(img_b.shape,img_b.dtype) print(mask_b.shape, mask_b.dtype) break for img_b, mask_b in val_dl: print(img_b.shape,img_b.dtype) print(mask_b.shape, mask_b.dtype) break

创建模型
创建并打印deeplab_resnet模型结构,使用预训练权重
from torchvision.models.segmentation import deeplabv3_resnet101 import torch model=deeplabv3_resnet101(pretrained=True, num_classes=21) device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') model=model.to(device) print(model)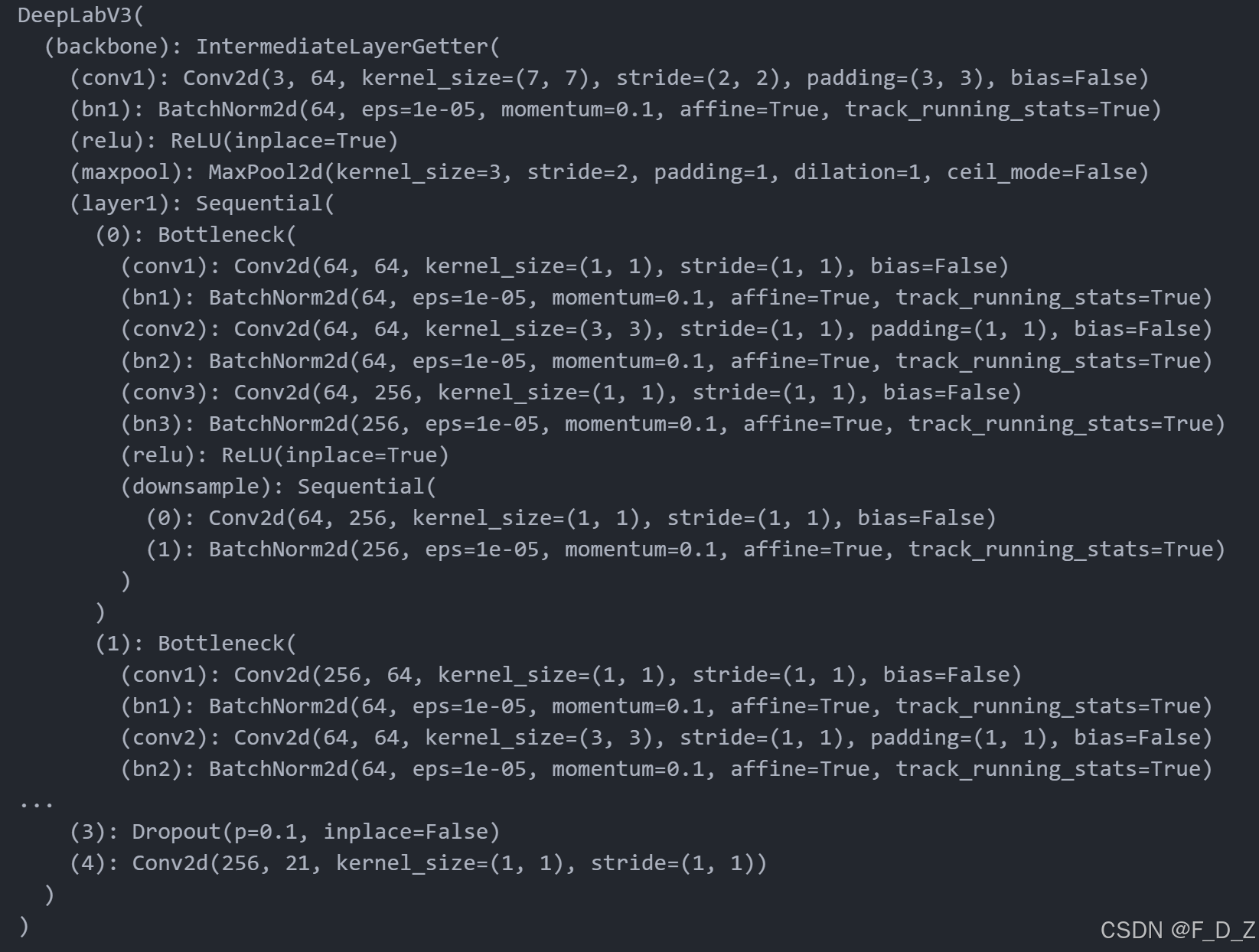
部署模型
在验证数据集的数据批次上部署模型观察效果
from torch import nn model.eval() with torch.no_grad(): for xb, yb in val_dl: yb_pred = model(xb.to(device)) yb_pred = yb_pred["out"].cpu() print(yb_pred.shape) yb_pred = torch.argmax(yb_pred,axis=1) break print(yb_pred.shape) plt.figure(figsize=(20,20)) n=2 img, mask= xb[n], yb_pred[n] img_r= re_normalize(img) plt.subplot(1, 3, 1) plt.imshow(to_pil_image(img_r)) plt.subplot(1, 3, 2) plt.imshow(mask) plt.subplot(1, 3, 3) show_img_target(img_r, mask)可见勾勒对象方面效果很好

定义损失函数和优化器
from torch import nn criterion = nn.CrossEntropyLoss(reduction="sum")from torch import optim opt = optim.Adam(model.parameters(), lr=1e-6) def loss_batch(loss_func, output, target, opt=None): loss = loss_func(output, target) if opt is not None: opt.zero_grad() loss.backward() opt.step() return loss.item(), None from torch.optim.lr_scheduler import ReduceLROnPlateau lr_scheduler = ReduceLROnPlateau(opt, mode='min',factor=0.5, patience=20,verbose=1) def get_lr(opt): for param_group in opt.param_groups: return param_group['lr'] current_lr=get_lr(opt) print('current lr={}'.format(current_lr))![]()
训练和验证模型
def loss_epoch(model,loss_func,dataset_dl,sanity_check=False,opt=None): running_loss=0.0 len_data=len(dataset_dl.dataset) for xb, yb in dataset_dl: xb=xb.to(device) yb=yb.to(device) output=model(xb)["out"] loss_b, _ = loss_batch(loss_func, output, yb, opt) running_loss += loss_b if sanity_check is True: break loss=running_loss/float(len_data) return loss, None import copy def train_val(model, params): num_epochs=params["num_epochs"] loss_func=params["loss_func"] opt=params["optimizer"] train_dl=params["train_dl"] val_dl=params["val_dl"] sanity_check=params["sanity_check"] lr_scheduler=params["lr_scheduler"] path2weights=params["path2weights"] loss_history={ "train": [], "val": []} metric_history={ "train": [], "val": []} best_model_wts = copy.deepcopy(model.state_dict()) best_loss=float('inf') for epoch in range(num_epochs): current_lr=get_lr(opt) print('Epoch {}/{}, current lr={}'.format(epoch, num_epochs - 1, current_lr)) model.train() train_loss, train_metric=loss_epoch(model,loss_func,train_dl,sanity_check,opt) loss_history["train"].append(train_loss) metric_history["train"].append(train_metric) model.eval() with torch.no_grad(): val_loss, val_metric=loss_epoch(model,loss_func,val_dl,sanity_check) loss_history["val"].append(val_loss) metric_history["val"].append(val_metric) if val_loss < best_loss: best_loss = val_loss best_model_wts = copy.deepcopy(model.state_dict()) torch.save(model.state_dict(), path2weights) print("Copied best model weights!") lr_scheduler.step(val_loss) if current_lr != get_lr(opt): print("Loading best model weights!") model.load_state_dict(best_model_wts) print("train loss: %.6f" %(train_loss)) print("val loss: %.6f" %(val_loss)) print("-"*10) model.load_state_dict(best_model_wts) return model, loss_history, metric_history import os opt = optim.Adam(model.parameters(), lr=1e-6) lr_scheduler = ReduceLROnPlateau(opt, mode='min',factor=0.5, patience=20,verbose=1) path2models= "./models/" if not os.path.exists(path2models): os.mkdir(path2models) params_train={ "num_epochs": 10, "optimizer": opt, "loss_func": criterion, "train_dl": train_dl, "val_dl": val_dl, "sanity_check": True, "lr_scheduler": lr_scheduler, "path2weights": path2models+"sanity_weights.pt", } model, loss_hist, _ = train_val(model, params_train)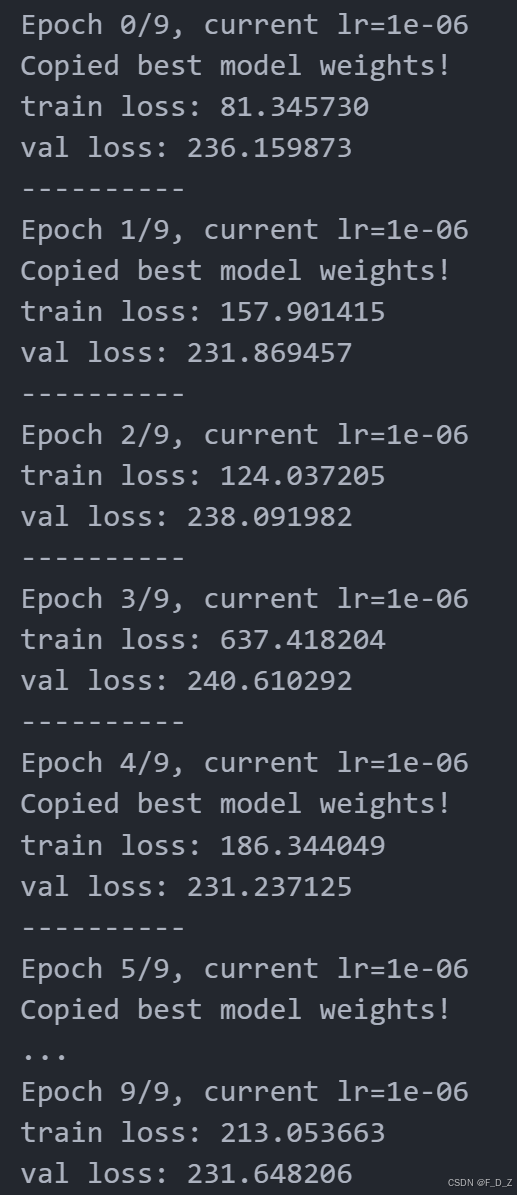
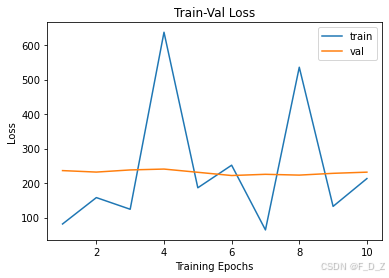
绘制了训练和验证损失曲线
num_epochs=params_train["num_epochs"] plt.title("Train-Val Loss") plt.plot(range(1,num_epochs+1),loss_hist["train"],label="train") plt.plot(range(1,num_epochs+1),loss_hist["val"],label="val") plt.ylabel("Loss") plt.xlabel("Training Epochs") plt.legend() plt.show()