
阅读量:0
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
AI大模型探索之路-实战篇7:Function Calling技术实战自动生成函数
AI大模型探索之路-实战篇8:多轮对话与Function Calling技术应用
AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
AI大模型探索之路-实战篇10:数据预处理的艺术:构建Agent智能数据分析平台的基础
AI大模型探索之路-实战篇11: Function Calling技术整合:强化Agent智能数据分析平台功能
AI大模型探索之路-实战篇12: 构建互动式Agent智能数据分析平台:实现多轮对话控制
AI大模型探索之路-实战篇13: 从对话到报告:打造能记录和分析的Agent智能数据分析平台
目录
一、前言
在之前的文章里,我们展示了如何利用大型模型的推理能力和Function Calling技术实现从自然语言到数据查询分析处理的转变。然而,除了依赖大模型自身的能力之外,有时我们还需要处理一些超出大模型能力范围的任务,例如调用本地代码库进行数据的可视化展示。因此,本文将介绍如何通过为Agent智能数据分析平台增添新外挂——Python代码解释器,来进一步增强其能力。
二、实现本地Python代码解释器
1、定义数据提取函数
定义一个数据提取服务,用于读取数据库表信息,放入到df变量中,并设置成全局变量
def extract_data(sql_query,df_name): """ 用于借助pymysql,将MySQL中的iquery数据库中的表读取并保存到本地Python环境中。 :param sql_query: 字符串形式的SQL查询语句,用于提取MySQL中iquery数据库中的某张表。 :param df_name: 将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。 :return:表格读取和保存结果 """ mysql_pw = "iquery_agent" connection = pymysql.connect( host='localhost', # 数据库地址 user='iquery_agent', # 数据库用户名 passwd=mysql_pw, # 数据库密码 db='iquery', # 数据库名 charset='utf8' # 字符集选择utf8 ) # 使用pandas的read_sql方法,根据SQL查询语句从数据库中读取数据,并将结果保存到本地变量中 globals()[df_name] = pd.read_sql(sql_query, connection) return "已成功完成%s变量创建" % df_name 2、数据查询汲取测试
测试数据查询,并传入一个本地变量用于接收查询到的数据
sql_query = "SELECT * FROM user_demographics LIMIT 10" data_name = "test_dataframe" extract_data(sql_query,data_name) 输出:
3、变量数据查看
查看本地的全局变量,确认是否有接收到数据
test_dataframe 输出: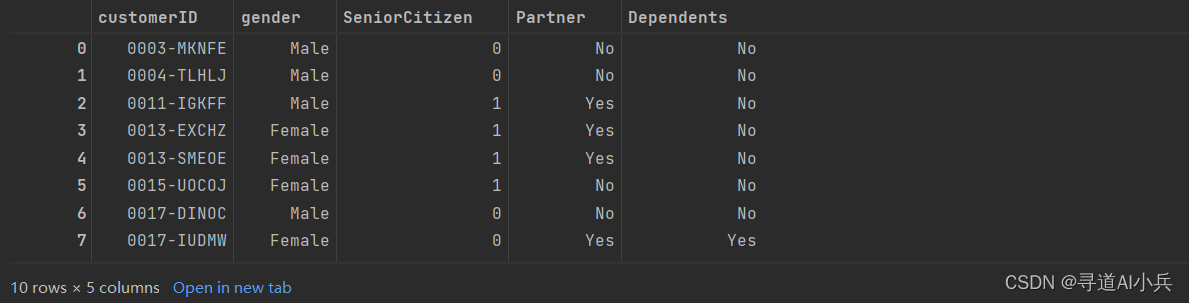
4、数据汲取函数信息生成
使用函数自动生成器,生成数据库查询函数的信息
#定义函数列表 functions_list = [extract_data] #函数信息生成测试 tools = auto_functions(functions_list) tools 输出: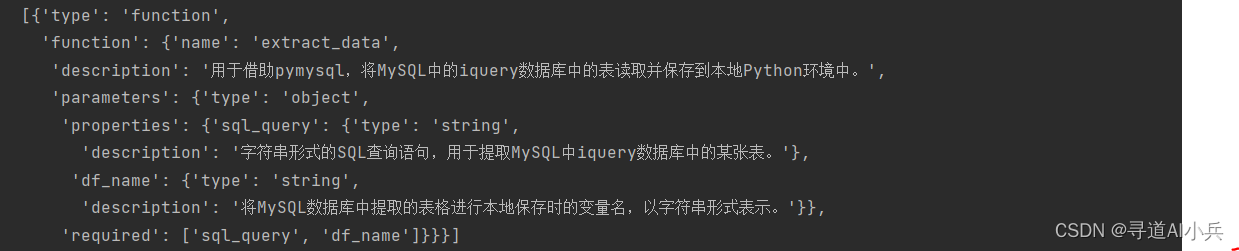
注意:读取数据库和python代码解析的函数信息建议采用自己手写的方式,避免大模型不稳定,有时候生成的格式不对
5、大模型调用测试
测试大模型能否正常找到对于的数据汲取的函数
messages=[ {"role": "user", "content": "请帮我读取iquery数据库中的user_payments,并保存至本地"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 输出:
6、定义python代码执行函数
定义一个能够在本地执行python代码的工具函数
# 能够在本地执行python代码的外部函数 # 定义一个名为python_inter的函数,该函数接受一个字符串类型的python代码作为参数 def python_inter(py_code): """ 该函数的主要作用是对iquery数据库中各张数据表进行查询和处理,并获取最终查询或处理结果。 :param py_code: 字符串形式的Python代码,此代码用于执行对iquery数据库中各张数据表进行操作 :return:返回代码运行的最终结果 """ # 记录函数开始执行时,全局作用域内的变量名 global_vars_before = set(globals().keys()) try: # 尝试执行传入的代码,代码的作用域为全局作用域 exec(py_code, globals()) except Exception as e: # 如果代码执行出错,返回错误信息 return str(e) # 记录代码执行后,全局作用域内的变量名 global_vars_after = set(globals().keys()) # 获取执行代码后新产生的全局变量名 new_vars = global_vars_after - global_vars_before # 如果有新的全局变量产生 if new_vars: # 返回新的全局变量及其值 result = {var: globals()[var] for var in new_vars} return str(result) else: try: # 如果没有新的全局变量产生,尝试计算并返回代码的执行结果 return str(eval(py_code, globals())) except Exception as e: # 如果计算代码执行结果也出错,返回成功执行代码的消息 return "已经顺利执行代码" 7、自动生成python代码执行函数的信息
利用大模型生成funcation calling需要的函数信息(实践运用时建议手写,避免大模型不稳定生成格式不对)
functions_list = [python_inter] tools = auto_functions(functions_list) tools 输出:
8、第一次大模型调用测试(python代码执行函数调用测试)
1)调用大模型,并找到工具函数
通过大模型API自动调用python代码执行函数,检查确认大模型是否能找的工具函数python_inter
messages=[ {"role": "user", "content": "已经读取iquery数据库中的user_payments数据表,并保存为test_dataframe"}, {"role": "user", "content": "test_dataframe是已经定义好的变量"}, {"role": "user", "content": "请帮我检查test_dataframe中总共包含几个字段"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 
2)获取代码变量
py_code=response.choices[0].message.tool_calls[0].function.arguments #格式转换 code = json.loads(py_code) #查看代码 code 输出:(查看变量)
3)取出变量信息
code_str = code.get("py_code") #取出代码 code_str 
4)执行代码,看结果
#Python代码执行测试(查看经过python代码格式化之后的数据库数据) python_inter(code_str) 
9、第二次大模型调用测试
第二次大模型API调用测试,获取查询user_payments数据表,获取字段信息和取值范围。
messages=[ {"role": "user", "content": "已经读取iquery数据库中的user_payments数据表,并保存为test_dataframe"}, {"role": "user", "content": "test_dataframe是已经定义好的变量"}, {"role": "user", "content": "请帮我检查test_dataframe中各字段的基本类型和取值范围"} ] response = client.chat.completions.create( model="gpt-3.5-turbo-16k", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 输出:
函数信息查看、提取
code = json.loads(response.choices[0].message.tool_calls[0].function.arguments) code_str = code.get("py_code") code_str 
代码执行测试
python_inter(code_str) 
10、第三次大模型调用测试
第三次大模型API调用测试,获取查询user_payments数据表,并统计缺失列。
messages=[ {"role": "user", "content": "已经读取iquery数据库中的user_payments数据表,并保存为test_dataframe"}, {"role": "user", "content": "test_dataframe是已经定义好的变量"}, {"role": "user", "content": "请帮我检查test_dataframe中各列的缺失值情况,并将统计结果保存为missing_value对象"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 输出:
查看变量信息:missing_value
获取查看函数
code = json.loads(response.choices[0].message.tool_calls[0].function.arguments) code_str = code.get("py_code") code_str 
代码执行
python_inter(code_str) 
查看执行后的变量
missing_value 
三、可视化展示数据
借助Python代码解释器进行可视化数据展示
1、获取数据
根据大模型获取test_dataframe中gender字段信息
messages=[ {"role": "user", "content": "已经读取iquery数据库中的user_payments数据表,并保存为test_dataframe"}, {"role": "user", "content": "test_dataframe是已经定义好的变量"}, {"role": "user", "content": "请帮我统计test_dataframe中gender字段的不同取值分布情况,并以可视化形式进行展示"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 
查看函数信息
code = json.loads(response.choices[0].message.tool_calls[0].function.arguments) code_str = code.get("py_code") code_str 
2、可视化展示
执行python代码解释器,进行可视化展示
python_inter(code_str) 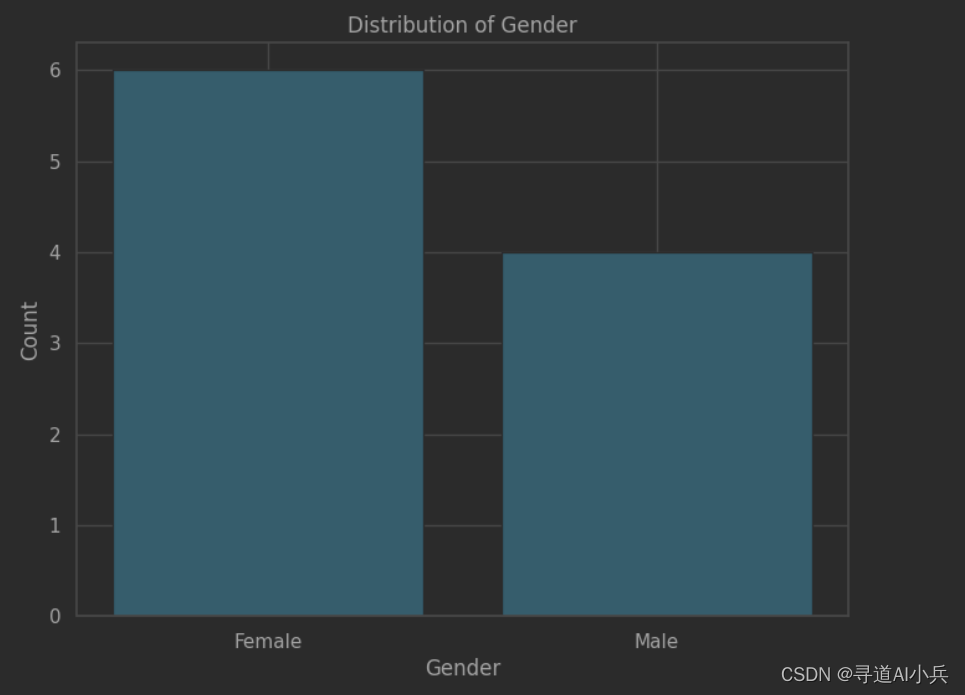
四、把可视化图片存入云盘文档
1、图形绘制测试
import matplotlib.pyplot as plt # 创建一个图形 fig, ax = plt.subplots() ax.plot([1, 2, 3, 4, 5]) 
查看类型
type(fig) 
2、定义图片存储服务
from docx import Document import matplotlib.pyplot as plt import os import tempfile def append_img_in_doc(folder_name, doc_name, img): """" 往文件里追加图片 @param folder_name=目录名,doc_name=文件名,img=图片对象,数据类型为matplotlib.figure.Figure对象 """ base_path = "/root/autodl-tmp/iquery项目/iquery云盘" ## 目录地址 full_path_folder=base_path+"/"+folder_name ## 文件地址 full_path_doc = os.path.join(full_path_folder, doc_name)+".doc" # 检查目录是否存在,如果不存在则创建 if not os.path.exists(full_path_folder): os.makedirs(full_path_folder) # 检查文件是否存在 if os.path.exists(full_path_doc): print(full_path_doc) # 文件存在,打开并追加内容 document = Document(full_path_doc) else: # 文件不存在,创建一个新的文档对象 document = Document() # 追加图片 # 将matplotlib的Figure对象保存为临时图片文件 with tempfile.NamedTemporaryFile(delete=False, suffix='.png') as tmpfile: fig.savefig(tmpfile.name, format='png') # 将图片插入到.docx文档中 document.add_picture(tmpfile.name) # 保存文档 document.save(full_path_doc) print(f"图片已追加到 {doc_name}") append_img_in_doc(folder_name="电信用户行为分析", doc_name="数据分析问答", img=fig) 
五、 实现把图片变为fig对象的代码逻辑
1、获取数据
messages=[ {"role": "user", "content": "已经读取iquery数据库中的user_payments数据表,并保存为test_dataframe"}, {"role": "user", "content": "test_dataframe是已经定义好的变量"}, {"role": "user", "content": "请帮我统计test_dataframe中gender字段的不同取值分布情况,并以可视化形式进行展示,可视化展示时请尽量绘制更加清晰美观的图片"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 
2、查看代码
code = json.loads(response.choices[0].message.tool_calls[0].function.arguments) code_str = code.get("py_code") code_str 
3、执行代码(可视化展示)
python_inter(code_str) 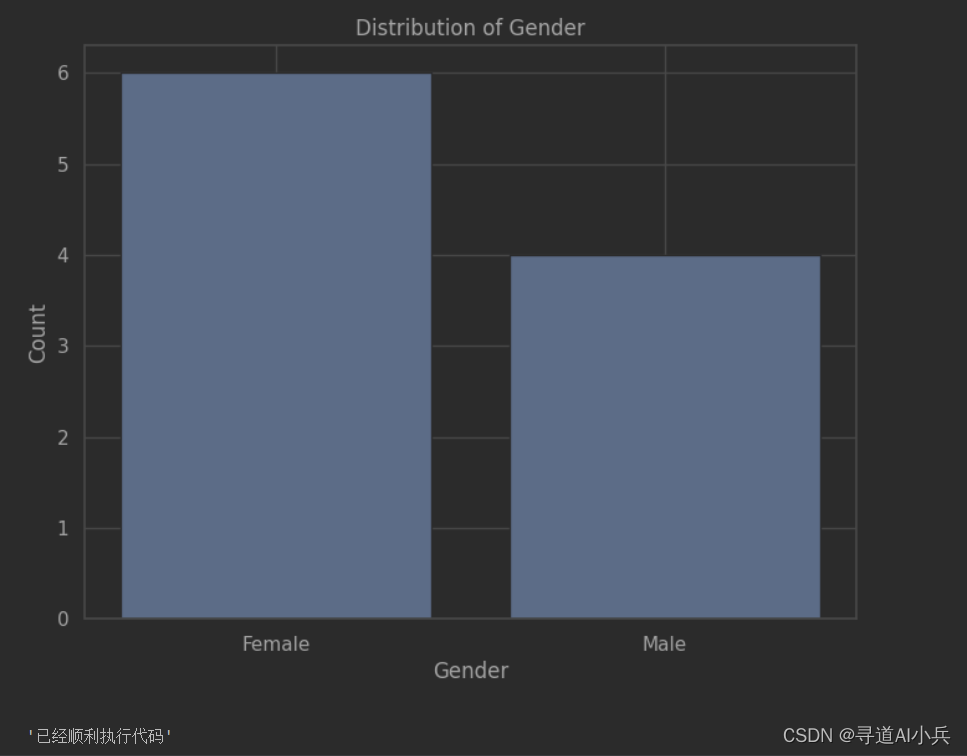
4、定义insert_fig_objec函数,插入matplotlib图形对象
1)查看代码
code_str 
2)在给定的代码字符串(code_str)中插入一个名为fig的matplotlib图形对象
检查代码字符串中是否已经存在fig对象的创建,如果不存在,则在第一次出现绘图相关代码的位置之前插入fig对象的创建。这样可以确保在使用matplotlib绘图时,所有的绘图操作都在同一个图形对象上进行
def insert_fig_object(code_str): global fig # 检查是否已存在 fig 对象的创建 if 'fig = plt.figure' in code_str: return code_str # 如果存在,则返回原始代码字符串 # 定义可能的库别名和全名 plot_aliases = ['plt.', 'matplotlib.pyplot.','plot'] sns_aliases = ['sns.', 'seaborn.'] # 寻找第一次出现绘图相关代码的位置 first_plot_occurrence = min((code_str.find(alias) for alias in plot_aliases + sns_aliases if code_str.find(alias) >= 0), default=-1) # 如果找到绘图代码,则在该位置之前插入 fig 对象的创建 if first_plot_occurrence != -1: plt_figure_index = code_str.find('plt.figure') if plt_figure_index != -1: # 寻找 plt.figure 后的括号位置,以确定是否有参数 closing_bracket_index = code_str.find(')', plt_figure_index) # 如果找到了 plt.figure(),则替换为 fig = plt.figure() modified_str = code_str[:plt_figure_index] + 'fig = ' + code_str[plt_figure_index:closing_bracket_index + 1] + code_str[closing_bracket_index + 1:] else: modified_str = code_str[:first_plot_occurrence] + 'fig = plt.figure()\n' + code_str[first_plot_occurrence:] return modified_str else: return code_str # 如果没有找到绘图代码,则返回原始代码字符串 5、insert_fig_objec函数测试
code_temp1=( "import matplotlib.pyplot as plt\n\n# 统计gender字段的不同取值分布情况\ngender_counts = test_dataframe['gender'].value_counts()\n\n# 绘制柱状图\nplt.figure(figsize=(8, 6))\nplt.bar(gender_counts.index, gender_counts.values)\nplt.xlabel('Gender')\nplt.ylabel('Count')\nplt.title('Distribution of Gender')\n\n# 展示图形\nplt.show()" ) modified_str = insert_fig_object(code_temp1) print(modified_str) 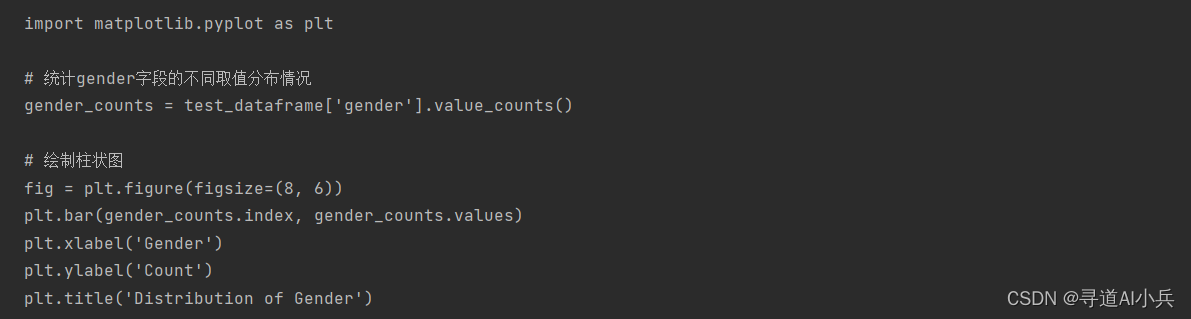
6、可视化展示gender字段取值分布1
- 导入matplotlib.pyplot库,并将其别名为plt。
- 统计test_dataframe中gender字段的不同取值分布情况,将结果存储在gender_counts变量中。
- 创建一个8x6大小的图形对象fig。
- 使用plt.bar()函数绘制柱状图,横坐标为gender_counts的索引(即不同的性别取值),纵坐标为gender_counts的值(即每个性别取值的数量)。
- 设置横轴标签为’Gender’,纵轴标签为’Count’,标题为’Distribution of Gender’。
- 使用plt.show()函数展示图形。
import matplotlib.pyplot as plt # 统计gender字段的不同取值分布情况 gender_counts = test_dataframe['gender'].value_counts() # 绘制柱状图 fig = plt.figure(figsize=(8, 6)) plt.bar(gender_counts.index, gender_counts.values) plt.xlabel('Gender') plt.ylabel('Count') plt.title('Distribution of Gender') # 展示图形 plt.show() 输出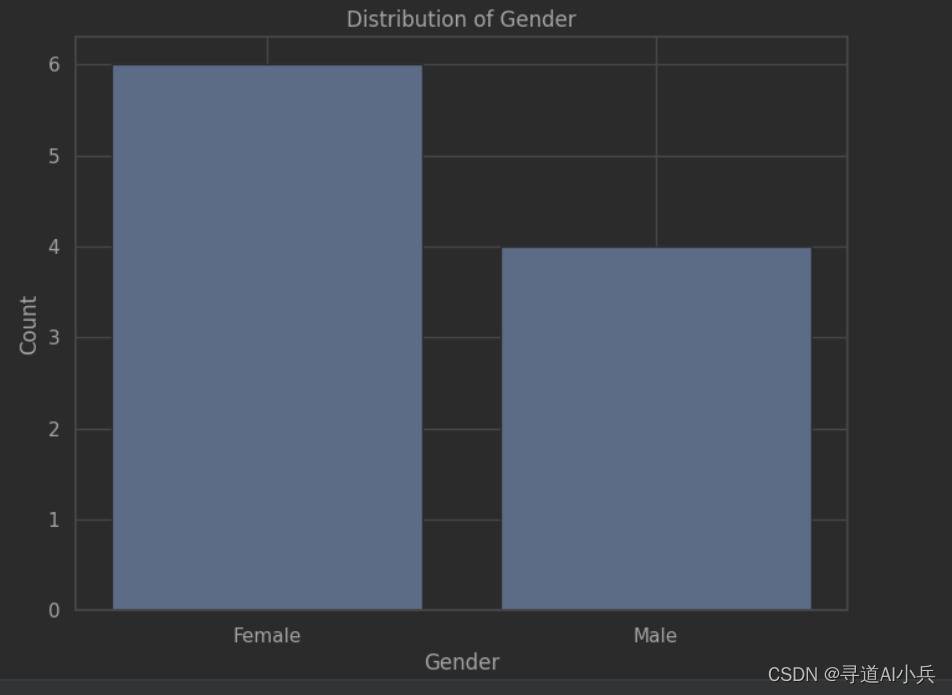
7、可视化展示gender字段取值分布2
使用了seaborn库来设置图形样式和绘制柱状图
import matplotlib.pyplot as plt import seaborn as sns counts = test_dataframe['gender'].value_counts() fig = plt.figure(figsize=(8,6)) sns.set(style='whitegrid') sns.barplot(x=counts.index, y=counts.values) plt.title('Distribution of Gender in test_dataframe') plt.xlabel('Gender') plt.ylabel('Count') plt.show() 输出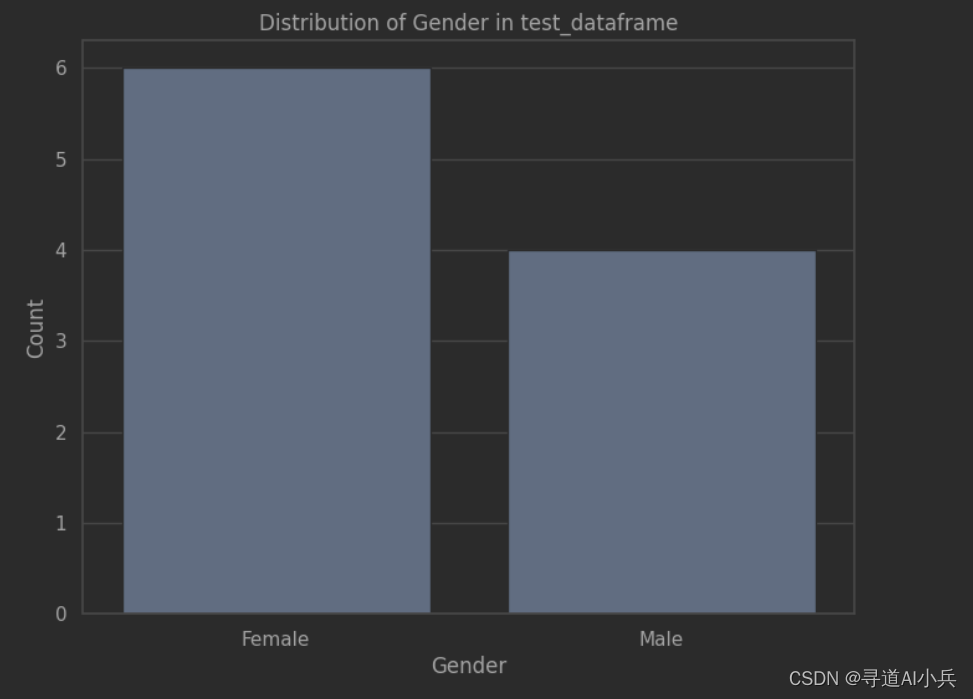
8、提取代码格式化输出
def extract_python(json_str): # 使用literal_eval将字符串转换为字典 dict_data = json.loads(json_str) # 提取'sql_query'的值 py_code_value = dict_data['py_code'] # 提取并返回'sql_query'的值 return py_code_value json_str = response.choices[0].message.tool_calls[0].function.arguments print(json_str) print(extract_python(json_str)) 输出:
9、重新定义python代码执行函数
def python_inter(py_code): """ 用于对iquery数据库中各张数据表进行查询和处理,并获取最终查询或处理结果。 :param py_code: 字符串形式的Python代码,用于执行对iquery数据库中各张数据表进行操作 :return:代码运行的最终结果 """ # 添加图片对象,如果存在绘图代码,则创建fig对象 py_code = insert_fig_object(py_code) global_vars_before = set(globals().keys()) try: exec(py_code, globals()) except Exception as e: return str(e) global_vars_after = set(globals().keys()) new_vars = global_vars_after - global_vars_before if new_vars: result = {var: globals()[var] for var in new_vars} return str(result) else: try: return str(eval(py_code, globals())) except Exception as e: return "已经顺利执行代码" 测试
python_inter(code_str) 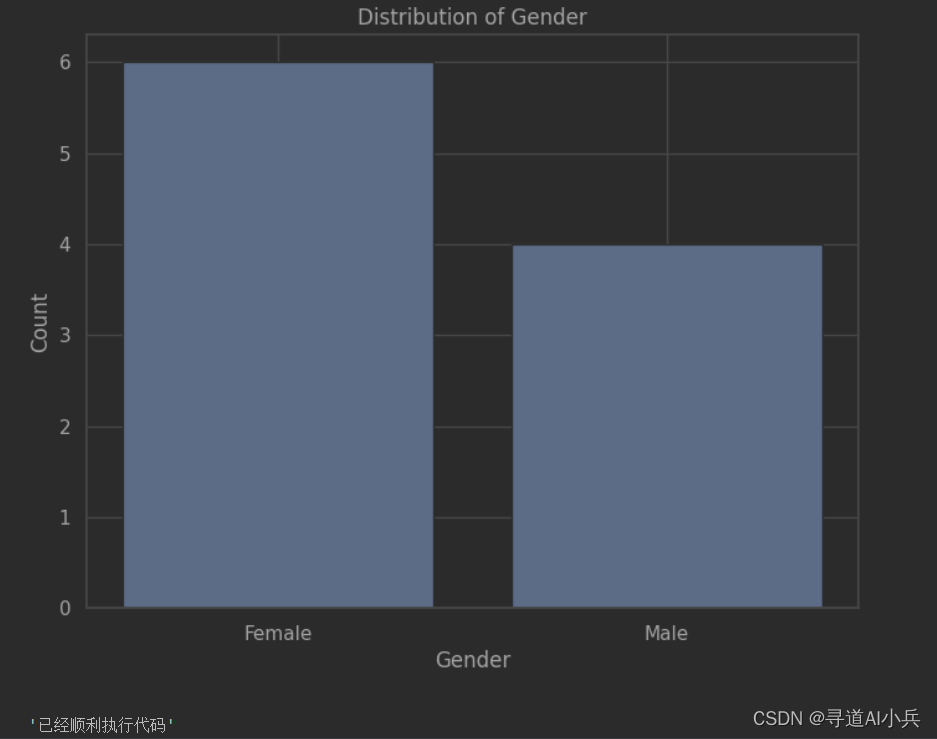
10、查看fg对象
fig 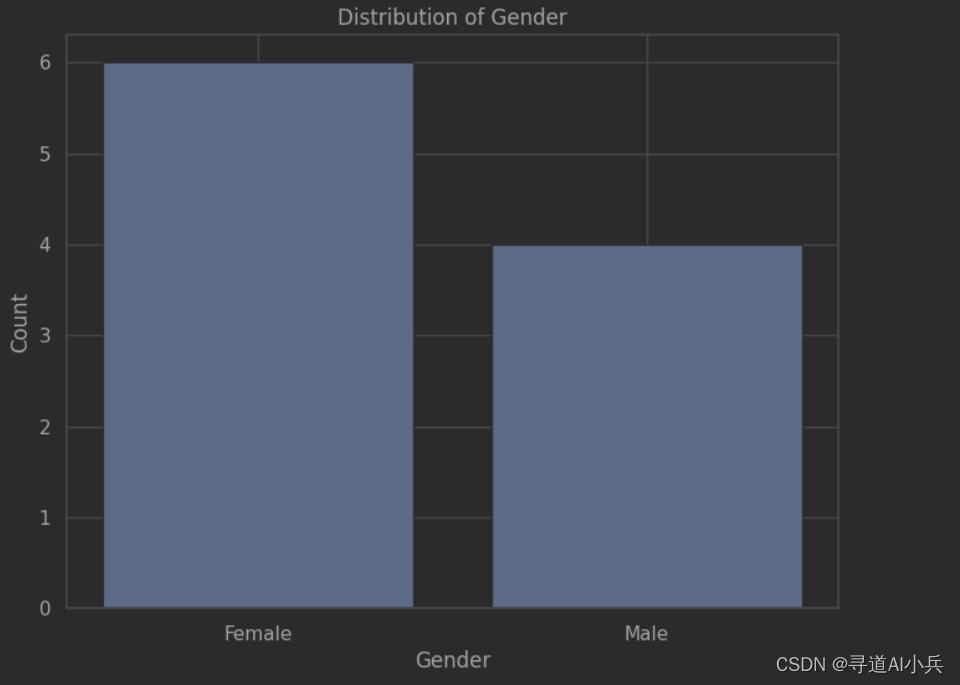
六、多轮对话增加Python代码解释器效果
1、定义Python代码提取函数
def extract_python(json_str): if isinstance(json_str, dict): return json_str['py_code'] # 使用literal_eval将字符串转换为字典 dict_data = json.loads(json_str) # 提取'sql_query'的值 py_code_value = dict_data['py_code'] # 提取并返回'sql_query'的值 return py_code_value 2、大模型两次调用封装
def check_code_run(messages, project_name, doc_name, functions_list=None, tools=None, model="gpt-3.5-turbo", auto_run = True): """ 能够自动执行外部函数调用的对话模型 :param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象 :param prject_name: 项目名 :param doc_name: 文件名 :param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象 :param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo :return:Chat模型输出结果 """ code = None # 如果没有外部函数库,则执行普通的对话任务 if functions_list == None: response = client.chat.completions.create( model=model, messages=messages, ) response_message = response.choices[0].message final_response = response_message.content # 若存在外部函数库,则需要灵活选取外部函数并进行回答 else: # 创建外部函数库字典 available_functions = {func.__name__: func for func in functions_list} # 第一次调用大模型 response = client.chat.completions.create( model=model, messages=messages, tools=tools, tool_choice="auto", ) response_message = response.choices[0].message tool_calls = response_message.tool_calls if tool_calls: messages.append(response_message) for tool_call in tool_calls: function_name = tool_call.function.name function_to_call = available_functions[function_name] function_args = json.loads(tool_call.function.arguments) ######################################### # 创建code对象 if 'sql_inter' in function_name or 'extract_data' in function_name: code = extract_sql(function_args) # 将代码字符串转换为Markdown格式 markdown_code = f"```sql\n{code}\n```" else: code = extract_python(function_args) code = insert_fig_object(code) # 将代码字符串转换为Markdown格式 markdown_code = f"```python\n{code}\n```" ######################################### if auto_run == False: print("已将问题转化为如下代码准备运行:") # 在Jupyter Notebook中展示Markdown格式的代码 display(Markdown(markdown_code)) #sql_query = extract_sql_by_str(function_args) #print("抽取出来的SQL:" + sql_query) res = input('是否确认并继续执行(1),或者退出本次运行过程(2)') if res == '2': print("终止运行") return None else: print("正在执行代码,请稍后...") function_response = function_to_call(**function_args) messages.append( { "tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": function_response, } ) ## 第二次调用模型 second_response = client.chat.completions.create( model=model, messages=messages, ) # 获取最终结果 final_response = second_response.choices[0].message.content else: final_response = response_message.content del messages ################################## if code: substrings = ['plt.', 'matplotlib.pyplot.', 'sns.', 'seaborn.','plot'] if any(substring in code for substring in substrings): global fig append_img_in_doc(project_name, doc_name, img=fig) print("图片保存成功!") ################################ return final_response 3、多轮对话函数定义
import tiktoken def chat_with_inter(functions_list=None, prompt="你好呀", model="gpt-3.5-turbo", system_message=[{"role": "system", "content": "你是一个智能助手。"}], auto_run = True): print("正在初始化外部函数库") # 创建函数列表对应的参数解释列表 functions = auto_functions(functions_list) #print(functions) print("外部函数库初始化完成") project_name = input("请输入当前分析项目名称:") folder_name = create_directory(project_name) print("已完成数据分析文件创建") doc_name = input("请输入当前分析阶段,如数据探索阶段和理解、数据清洗阶段等:") doc_name += '问答' print("好的,即将进入交互式分析流程") # 多轮对话阈值 if 'gpt-4' in model: tokens_thr = 6000 elif '16k' in model: tokens_thr = 14000 else: tokens_thr = 3000 messages = system_message ## 完成给用户输入的问题赋值 user_input = prompt messages.append({"role": "user", "content": prompt}) ## 计算token大小 embedding_model = "text-embedding-ada-002" # 模型对应的分词器(TOKENIZER) embedding_encoding = "cl100k_base" encoding = tiktoken.get_encoding(embedding_encoding) tokens_count = len(encoding.encode((prompt + system_message[0]["content"]))) while True: answer = check_code_run(messages, project_name=project_name, doc_name = doc_name, functions_list=functions_list, tools=functions, model=model, auto_run = auto_run) print(f"模型回答: {answer}") #####################判断是否记录文档 start####################### while True: record = input('是否记录本次回答(1),还是再次输入问题并生成该问题答案(2)') if record == '1': Q_temp = 'Q:' + user_input A_temp = 'A:' + answer append_in_doc(folder_name=project_name, doc_name=doc_name, qa_string=Q_temp) append_in_doc(folder_name=project_name, doc_name=doc_name, qa_string=A_temp) # 记录本轮问题答案 messages.append({"role": "assistant", "content": answer}) break else: print('好的,请再次输入问题') user_input = input() messages[-1]["content"] = user_input answer = check_code_run(messages, project_name=project_name, doc_name = doc_name, functions_list=functions_list, tools=functions, model=model, auto_run = auto_run) print(f"模型回答: {answer}") ########################判断是否记录文档 stop ####################### # 询问用户是否还有其他问题 user_input = input("您还有其他问题吗?(输入退出以结束对话): ") if user_input == "退出": del messages break # 记录新一轮问答 messages.append({"role": "assistant", "content": answer}) messages.append({"role": "user", "content": user_input}) # 计算当前总token数 tokens_count += len(encoding.encode((answer + user_input))) # 删除超出token阈值的对话内容 while tokens_count >= tokens_thr: tokens_count -= len(encoding.encode(messages.pop(1)["content"])) 4、定义工具列表
#sql_inter, functions_list = [extract_data, python_inter] 5、多轮对话测试
from IPython.display import display, Markdown, Code chat_with_inter(functions_list=functions_list, prompt="请将iquery数据库中的user_demographics表保存到本地Python环境中,并命名为user_demographics_df", model="gpt-3.5-turbo", system_message=[{"role": "system", "content": md_content}], auto_run = False) 对话效果
正在初始化外部函数库 [{'type': 'function', 'function': {'name': 'extract_data', 'description': '用于借助pymysql,将MySQL中的iquery数据库中的表读取并保存到本地Python环境中。', 'parameters': {'type': 'object', 'properties': {'sql_query': {'type': 'string', 'description': '字符串形式的SQL查询语句,用于提取MySQL中iquery数据库中的某张表。'}, 'df_name': {'type': 'string', 'description': '将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。'}}, 'required': ['sql_query', 'df_name']}}}, {'type': 'function', 'function': {'name': 'python_inter', 'description': '用于对chatbi数据库中各张数据表进行查询和处理,并获取最终查询或处理结果。', 'parameters': {'type': 'object', 'properties': {'py_code': {'type': 'string', 'description': '字符串形式的Python代码,用于执行对chatbi数据库中各张数据表进行操作'}}, 'required': ['py_code']}}}] 外部函数库初始化完成 请输入当前分析项目名称: 电信用户行为分析目录 电信用户行为分析 已存在 已完成数据分析文件创建 请输入当前分析阶段,如数据探索阶段和理解、数据清洗阶段等: 数据可视化 好的,即将进入交互式分析流程 已将问题转化为如下代码准备运行: 是否确认并继续执行(1),或者退出本次运行过程(2) 1 正在执行代码,请稍后... /tmp/ipykernel_150812/966933623.py:20: UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy. globals()[df_name] = pd.read_sql(sql_query, connection) 模型回答: 已将iquery数据库中的user_demographics数据表保存到本地Python环境中,并命名为user_demographics_df。您可以使用该变量进行进一步的数据分析和处理了。 是否记录本次回答(1),还是再次输入问题并生成该问题答案(2) 1 内容已追加到 数据可视化问答 内容已追加到 数据可视化问答 您还有其他问题吗?(输入退出以结束对话): 用可视化的方式展示user_demographics_df数据集中gender字段不同取值的占比情况 已将问题转化为如下代码准备运行: 是否确认并继续执行(1),或者退出本次运行过程(2) 1 正在执行代码,请稍后... 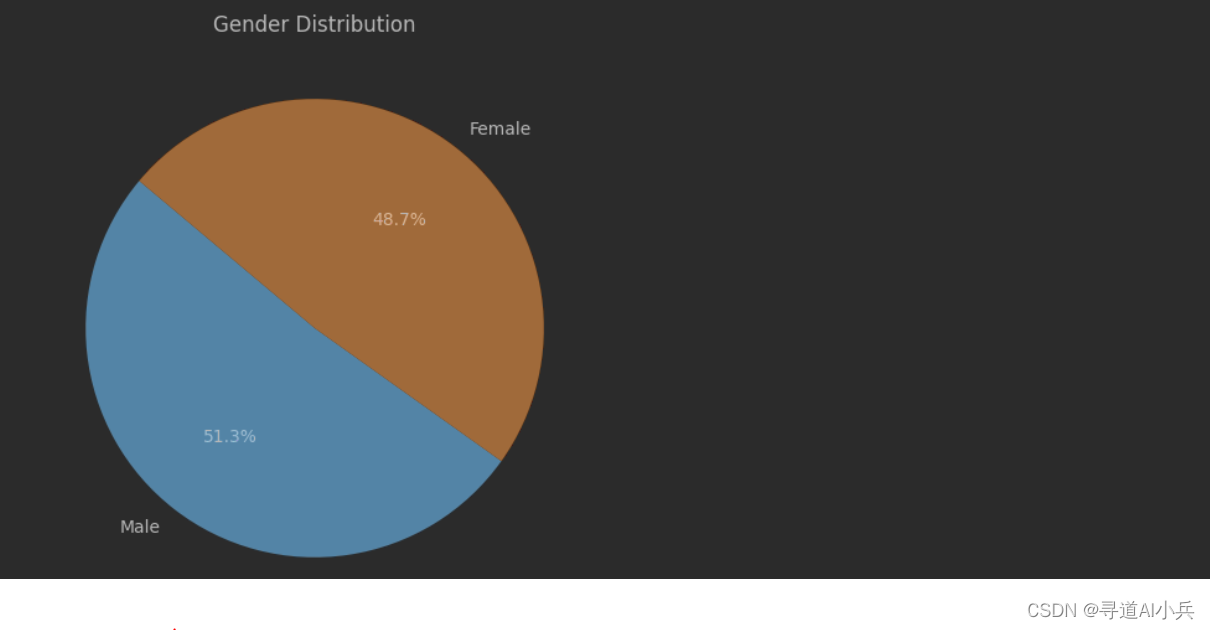
七、结语
通过上述步骤的实践应用,我们已经成功将本地python代码解释器整合进入了Agent智能数据分析平台,到此,智能数据分析平台同时兼容了我们调研项目中的DB-GPT和Open Interpreter两者的优势特点。相当于给平台装上了两个翅膀,一个用于SQL解析、一个用于代码解释;从而让平台的数据处理能力更上一层楼。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
