
阅读量:0
序言:
当谈到机器学习和人工智能的开发和部署时,Amazon SageMaker是一个非常强大和全面的平台。作为一项托管式的机器学习服务,Amazon SageMaker提供了一套完整的工具和功能,帮助开发者轻松构建、训练和部署机器学习模型。
首先,让我们谈谈我对Amazon SageMaker的看法。我认为它是一项令人印象深刻的服务,因为它将整个机器学习工作流程整合到一个统一的平台上。从数据准备和特征工程到模型训练和推理部署,Amazon SageMaker提供了一系列直观且易于使用的工具和界面,使机器学习变得更加简单和高效。
此外,Amazon SageMaker还提供了许多最佳实践,帮助开发者在机器学习项目中取得成功。其中一项关键功能是自动模型调优(AutoML),它利用强大的自动化技术,通过对比和优化不同的算法和超参数组合,自动找到最佳的模型配置。这大大减少了开发者在调试和优化模型上的时间和精力投入。
另一个重要的功能是Amazon SageMaker Notebook实例,它提供了一个交互式的开发环境,让开发者能够快速迭代和实验他们的机器学习模型。Notebook实例集成了常用的开发工具和库,如Jupyter Notebook和常见的机器学习库,使代码编写、可视化和调试变得非常方便。
对于模型的训练和部署,Amazon SageMaker提供了高度可扩展和高性能的计算资源,以及灵活的部署选项。你可以选择将模型部署为托管的终端节点,也可以选择在边缘设备上进行本地部署。这使得你能够根据项目需求选择最合适的部署方式。
文章目录
Amazon SageMaker由以下三大主要部分组成:
创作: 无需进行任何设置,使用Jupyter Notebook IDE就能进行数据探索、清洁与预处理。我们可以在常规实例类型或GPU驱动型实例当中运行此类工作负载。
模型训练: 一项分布式模型构建、训练与验证服务。我们可以利用其中的内置常规监督与无监督学习算法及框架,或者利用Docker容器创建属于自己的训练机制。其模型训练规模可囊括数十个实例,以支持模型构建加速。训练数据读取自S3,训练后的模型成果亦可存放在S3存储桶内。最终得出的模型结果为数据相关模型参数,而非模型当中进行推理的代码。
模型托管: 模型托管服务可配合HTTP端点以调用模型进行实时推理。这些端点可进行规模扩展,从而支持实际流量;我们也可以同时对多套模型进行A/B测试。此外,我们也可以使用内置的SDK构建这些端点,或者选择Docker镜像提供自己的配置选项。
上述组成部分皆可独立使用,这意味着Amazon SageMaker将能够轻松填补现有流程中的空白环节。换句话来说,当开发人员以端到端方式使用该服务时,将能够享受到由其提供的强大功能。那本文我们就来使用Amazon SageMaker快速实现高精度猫狗分类问题。
一、环境准备
登录Amazon SageMaker控制台,选择“笔记本实例”。
Amazon SageMaker提供了一个完全集成的机器学习开发环境,能有效提高我们构建模型的效率和能力。我们可以在一键式Jupyter Notebooks帮助下,以闪电般的速度进行构建和协作。Sagemaker还为这些Notebooks提供了一键式共享工具。整个编程的结构都会被自动捕获,同时我们可以毫无障碍地与其他人协同工作,分享我们的训练效果和新心得。
在“笔记本实例”页面上,单击“创建笔记本实例”。
在“创建笔记本实例”页面中,输入名称、选择实例类型和计算资源等配置信息,并新建安全组。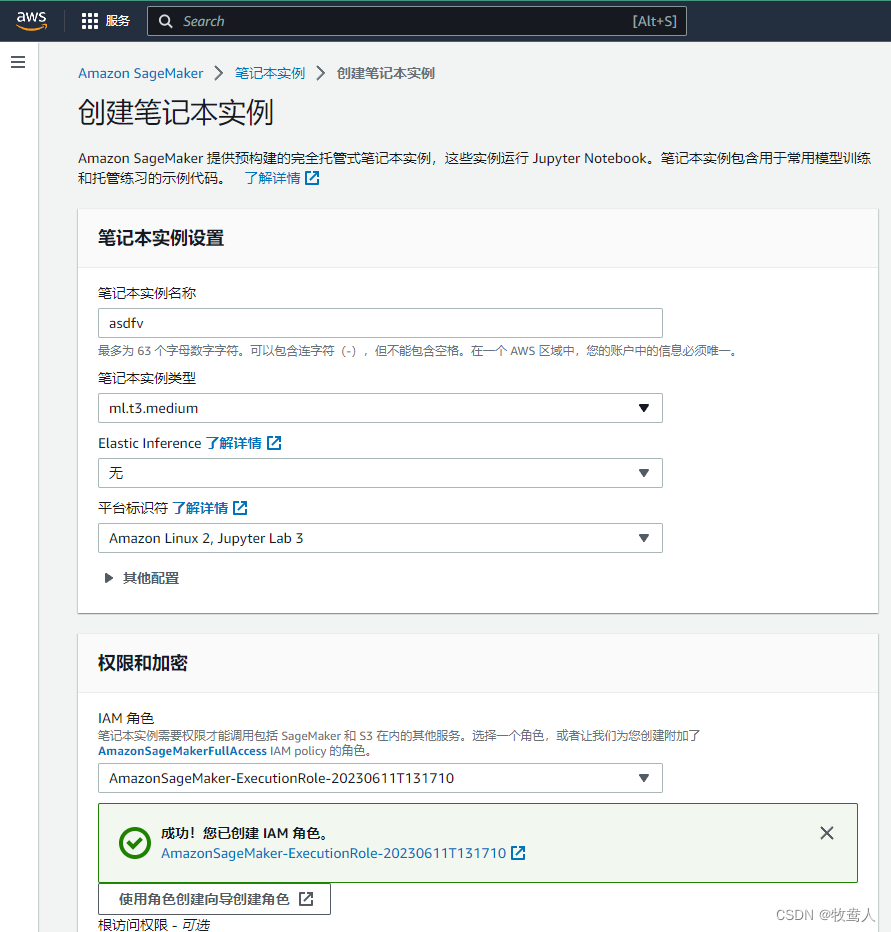
最后选择创建笔记本实例,SageMaker 就将创建该 Notebook 实例。在 笔记本实例 界面可以看当前的实例列表及其状态,如果状态为 InService,在操作列有 打开 Jupyter |打开 JupyterLab 的选项。
在机器学习中,Notebook 已经是常见的形式了,很多云平台都采用了这种编辑形式。因为可以与代码交互,用它来开发机器学习代码实在是再合适不过了。在 SageMaker Studio 中,除了 Notebook 传统擅长可视化,还额外加了一些可视化组件管理模型的实验过程。
本来用 Notebook 写轻量代码就非常方便,再加上 SageMaker 自己提供的大量精炼 API,它们之间的配合特别融洽。对于那些费时费力的底层资源管理繁杂过程,交给 SageMaker API 就行了,剩下的只要在 Notebook 写下算法逻辑,这才是机器学习开发者最高效的姿势。
点击 Open Jupyter,将自动弹出一个新的页面,加载完成后,出现我们熟悉的 Jupyter Notebook 界面。
其中在 SageMaker Examples 页面下,在右侧 New 下拉菜单中,您可以选择创建的开发环境,此处我们选择 conda_python3 以进行后面的内容。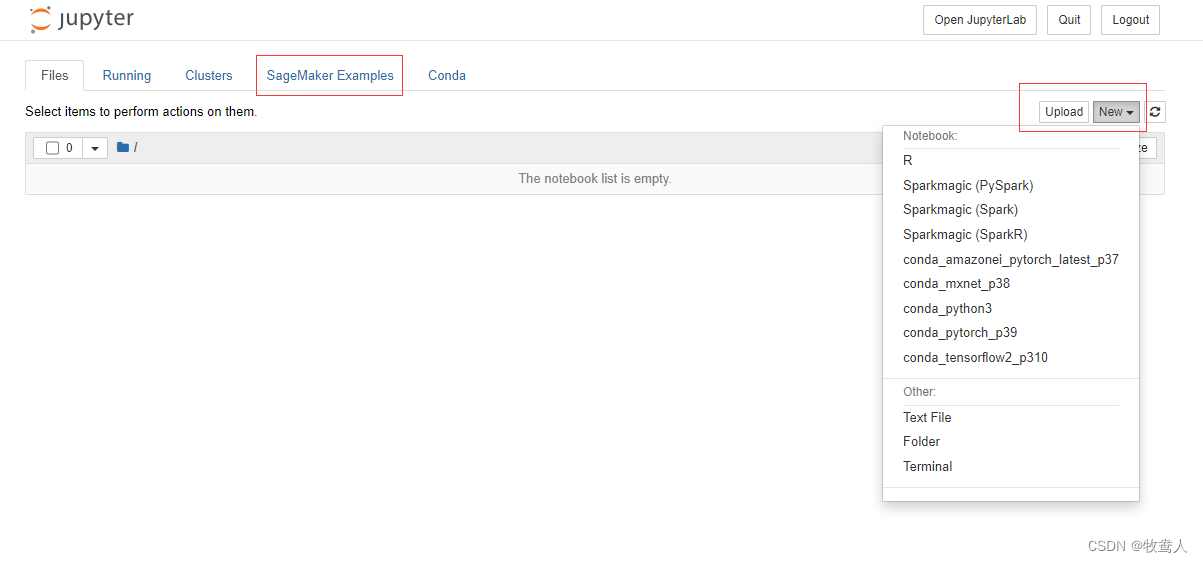
3.创建存储桶用来存放本次实验数据
猫狗数据集介绍:
猫狗数据集包括25000张训练图片,12500张测试图片,包括猫和狗两种图片。在此次实验中为了训练方便,我们取了一个较小的数据集。 数据解压之后会有两个文件夹,一个是 “train”,一个是 “test”,顾名思义一个是用来训练的,另一个是作为检验正确性的数据
在train文件夹里边是一些已经命名好的图像,有猫也有狗。而在test文件夹中是只有编号名的图像。
图片展示
下面是数据集中的图片展示:
class_names = [‘cats’, ‘dogs’]
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype(“uint8”))
plt.title(class_names[labels[i]])
plt.axis(“off”)
🌟🌟🌟 这里是输出的结果:✨✨✨
二、下载数据集并将其进行数据预处理
数据集加载,数据是通过这个网站下载的猫狗数据集:http://aimaksen.bslience.cn/cats_and_dogs_filtered.zip,实验中为了训练方便,我们取了一个较小的数据集。
path_to_zip = tf.keras.utils.get_file(
‘data.zip’,
origin=‘http://aimaksen.bslience.cn/cats_and_dogs_filtered.zip’,
extract=True,
)
PATH = os.path.join(os.path.dirname(path_to_zip), ‘cats_and_dogs_filtered’)
train_dir = os.path.join(PATH, ‘train’)
validation_dir = os.path.join(PATH, ‘validation’)
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
数据集管理
使用image_dataset_from_director进行数据集管理。
train_dataset = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
加载预训练模型:
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
三、构建、训练和部署您的模型。
在Jupyter Notebook中使用SageMaker Python SDK来构建、训练和部署模型。
- Stable Diffusion 模型介绍
在此次训练中,我们用到了亚马逊用于预测产品的需求和销售趋势的一种模型—Stable Diffusion 模型。
它基于随机漫步和稳定性假设,能够描述价格波动的实际情况。该模型认为价格变化由两个部分组成:一个稳定的长期趋势和一个随机的短期波动。
该模型有四个主要参数:稳定指数alpha、漂移参数beta、标准差sigma和时间间隔delta。其中Alpha表示价格波动的稳定程度,越大则波动越不稳定;Beta表示价格的长期趋势;Sigma表示价格离散度或者说波动大小,越大则价格波动越大;Delta表示时间间隔。
总体体验下来,该模型给我以下的感觉: - 可以处理缺失值: Stable Diffusion 模型可以有效地处理数据中的缺失值,这使其在面对现实中的不完整数据时更加可靠。
- 考虑市场饱和度: 该模型能够考虑市场饱和度对产品需求的影响,从而预测产品在市场上的销售情况。
- 能够灵活应用: 该模型十分灵活,可以根据不同类型的产品和市场需求进行调整和改进,因此适用范围广泛。
Stable Diffusion 模型在预测产品销售趋势方面具有较高的准确度和可靠性,是亚马逊在产品销售策略制定中的重要工具之一。 - 训练
做机器学习的朋友应该都了解,ML 中的数据预处理是最麻烦的,而在 IDE 处理数据需要特别好用的可视化,从而给我们关于数据最直观的理解。与此同时,手动调参也需要特别好的可视化,来帮助我们对比不同算法和超参训练出来的模型效果。
而Amazon SageMaker正好可以为我们提供很好的可视化效果,为我们的训练以及调参带俩极大的便利。作为一个完全托管的机器学习平台,SageMaker把软件技能抽象化,能让我们通过一组直观并且易于使用的工具,就能构建、训练想要的机器学习模型。
inital_input = tf.keras.applications.mobilenet_v2.preprocess_input
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights=‘imagenet’)
base_model.trainable = False
base_model.summary()
🌟🌟🌟 这里是输出的结果:✨✨✨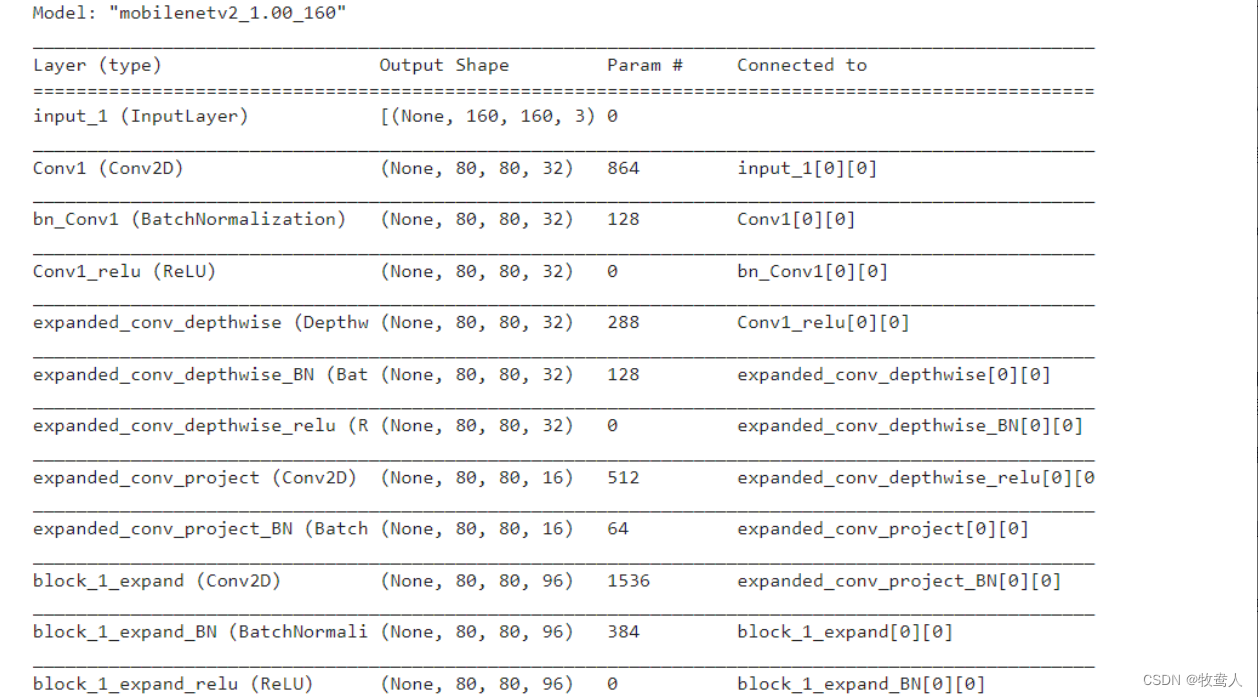
- 训练结果可视化
用图表显示准确率和损失函数
// 训练结果可视化,用图表显示准确率和损失函数
acc = history.history[‘accuracy’]
val_acc = history.history[‘val_accuracy’]
loss = history.history[‘loss’]
val_loss = history.history[‘val_loss’]
epochs_range=range(initial_epochs)
plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(epochs_range, acc, label=“Training Accuracy”)
plt.plot(epochs_range, val_acc,label=“Validation Accuracy”)
plt.legend()
plt.title(“Training and Validation Accuracy”)
plt.subplot(2,1,2)
plt.plot(epochs_range, loss, label=“Training Loss”)
plt.plot(epochs_range, val_loss,label=“Validation Loss”)
plt.legend()
plt.title(“Training and Validation Loss”)
plt.show()
🌟🌟🌟 这里是输出的结果:✨✨✨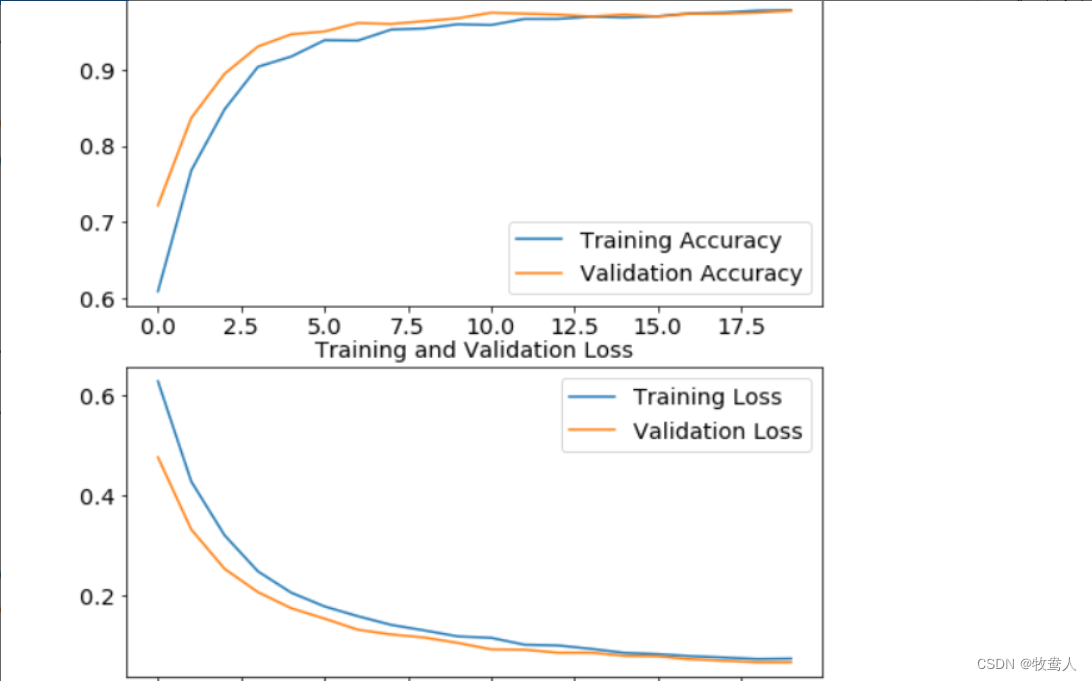
托管与实时推断现在我们的模型已经完成了训练,并可用于进行实际预测!利用之前提到的代码,这里创建并启动一个端点。
predictor = m.deploy(initial_instance_count=1, instance_type=‘ml.c4.xlarge’)
而后运行以下命令调用该端点: predictor.predict(img_input)!
就这么简单,只需要不足100行代码,我们的端到端机器学习流程即构建完成。
四、 运行文件,查看模型的训练和评估结果
Amazon Tensorflow Optimization通过其庞大的256 GPU,可以提高最多90%的扩展性。这样,在很短的时间内,我们就可以体验到精确、复杂的训练模型。而且,Amazon Sagemaker附带的Managed Spot Training,还可以降低培训成本的90%。因为在本地总会因为配置问题使的运行速度非常缓慢甚至中途报废,所以说对运行的结果以及速度我还是非常期待的。
- 输出训练的准确率
// 输出训练的准确率
test_loss, test_accuracy = model.evaluate(test_dataset)
print(‘test accuracy: {:.2f}’.format(test_accuracy))
然后我们借用cnn工具可视化一批数据的预测结果
label_dict = {
0: ‘cat’,
1: ‘dog’
}
test_image_batch, test_label_batch = test_dataset.as_numpy_iterator().next()
//编码成uint8 以图片形式输出
test_image_batch = test_image_batch.astype(‘uint8’)
cnn_utils.plot_predictions(model, test_image_batch, test_label_batch, label_dict, 32, 5, 5)
🌟🌟🌟 这里是输出的结果: ✨✨✨
- 数据输出
// 数据输出,数字化特征图
test_image_batch, test_label_batch = train_dataset.as_numpy_iterator().next()
img_idx = 0
random_batch = np.random.permutation(np.arange(0,len(test_image_batch)))[:BATCH_SIZE]
image_activation = test_image_batch[random_batch[img_idx]:random_batch[img_idx]+1]
cnn_utils.get_activations(base_model, image_activation[0])
🌟🌟🌟 这里是输出的结果: ✨✨✨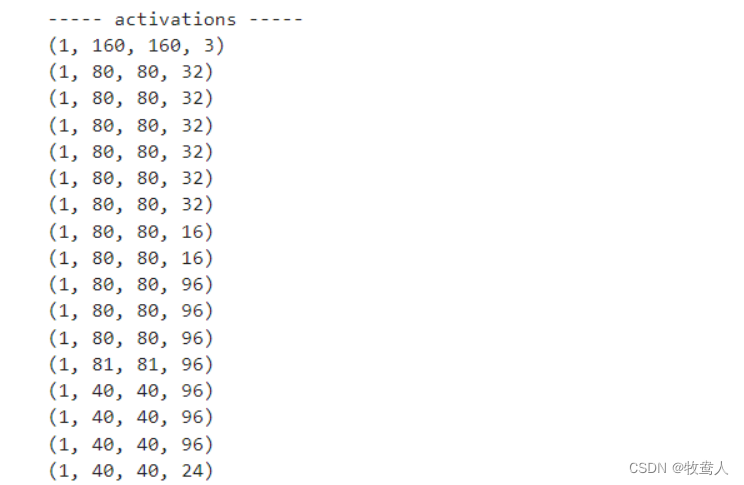
Amazon SageMaker 在数据导入,输出方面具有明显优势,易用性方面国内部分厂商也同样优秀。同时对于 TensorFlow 和 PyTorch的支持度都比较好。
- 图像结果输出
🌟🌟🌟 这里是输出的结果:✨✨✨

运行之后,我们发现计算结果准确性高达了0.97,可以说是准确度相当之高了,经过可视化之后输出的图像也是肉眼可见的准确!而且相比于在本地运行其简便性十分突出,这次技术体验比我想象的好太多,技术体验耗时不到 10 分钟,解决了最头疼的配置和调优问题,简化了开发流程,提升了开发效率,可以快速帮助我们构建、训练和评估模型。并且训练速度极快,0.1s内就可以将所有项目输出结果全盘脱出!
五、使用体验总结
Amazon SageMaker 的优势在于不必安装,也不需要手动扩展,只要保证网络畅通,有兼容的浏览器保证运行即可。它提供了一个完整的机器学习套件,其中包括 IDE,API,调试、监控工具等,可以在机器学习建模的各个流程环节处理好关键事项。
相对于传统的机器学习开发,使用 Amazon SageMaker 可以带来以下几个方面的优势:
- 快速构建和测试: Amazon SageMaker 提供了内置算法和模型模板,可以快速构建、训练和评估模型。此外,您还可以使用 Amazon SageMaker Studio 和 Amazon SageMaker Notebook Instance 进行交互式开发和调试。
- 易于部署和扩展: 使用 Amazon SageMaker,您可以轻松地将训练好的模型部署到实时终端节点或批处理推理作业中。您还可以根据需要自动缩放模型推理容量。
- 成本效益: Amazon SageMaker 提供了灵活的定价模型,使您的机器学习应用程序能够按需缩放,从而节约成本。
- 安全性和合规性: Amazon SageMaker 采用多层安全措施来保护您的数据和模型。此外,Amazon SageMaker 还符合多种合规标准,如 HIPAA、PCI、SOC 1/2/3 等。
- 强大的生态系统: Amazon SageMaker 集成了许多其他 Amazon 服务,例如 Amazon S3、Amazon Redshift、Amazon Athena 等,让您的机器学习工作流程更加无缝。
- 按使用量付费: Amazon SageMaker的付费方式是按使用量付费,您只需支付您使用的资源和服务,这使得使用Amazon SageMaker非常灵活和经济。
总之,Amazon SageMaker 为您提供了一个全面的、高度托管的机器学习平台, 可以使用大规模分布式计算集群,使得我们的模型训练速度更快,能够应对大规模数据和复杂模型训练,对于那些想要利用机器学习技术但不想花费大量时间和资源来构建自己的环境的用户来说,是一个非常有价值的工具。而且SageMaker 提供了自动模型调优工具,根据我们提供的数据和模型类型,自动找到最佳的超参数组合,从而提高模型的准确率,使得机器学习建模变得更加简单和高效。
SageMaker 的强大不仅来自于 Amazon 多年积累的技术,也源于这家公司与众多使用者、合作伙伴共同建立起的生态。通过云上探索实验室,开发者可以学习实践云上技术,同时将自己的技术心得分享给其他开发者小伙伴。一同创造分享,互助启发,玩转云上技术。云上探索实验室不仅是体验的空间,更是分享的平台!
免费福利
欢迎大家一起参与云上探索实验室,用技术实验、产品体验、案例应用等方式,亲身感受最新、最热门的亚马逊云科技开发者工具与服务。发挥您的想象和创造,以文章、视频、代码 Demo 等形式分享见解。如果你对机器学习感兴趣,我强烈推荐你在2023你6月27-28日访问以下链接了解更多关于Amazon SageMaker的信息和功能:PC端亚马逊云科技中国峰会,移动端亚马逊云科技中国峰会。与全球的开发者共同探索机器学习可能性!
为了更好地参与亚马逊云科技开发者工具与服务的体验,可以前往链接免费报名,并在现场参与各种活动领取官方礼品。希望您能够获得愉快且有意义的体验!
