阅读量:0
文章目录
艺术地掌控人物形象
在运用Stable Diffusion这一功能强大的AI绘图工具时,我们往往会发现自己对提示词的使用还不够充分。在这种情形下,我们应当如何调整自己的策略,以便更加精确、全面地塑造出理想的人物形象呢?
举例来说,假设我们输入的是:
a girl in dress walks down a country road,vision,front view,audience oriented, 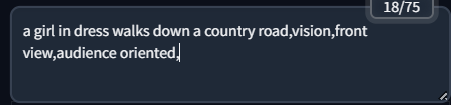
图片效果总是不尽人意
我们批量四个之后,除去背对的图片,我们可以看到其余三个的面部非常的奇怪
该如何快速处理呢?
好易智算
首先,我们可以通过好易智算平台迅速启动。在好易智算的平台上,它整合了多个AI应用程序——应用即达,AI轻启。这样的便捷性使得访问和使用这些先进技术变得前所未有地简单快捷。
我们这里选择Stable Diffusion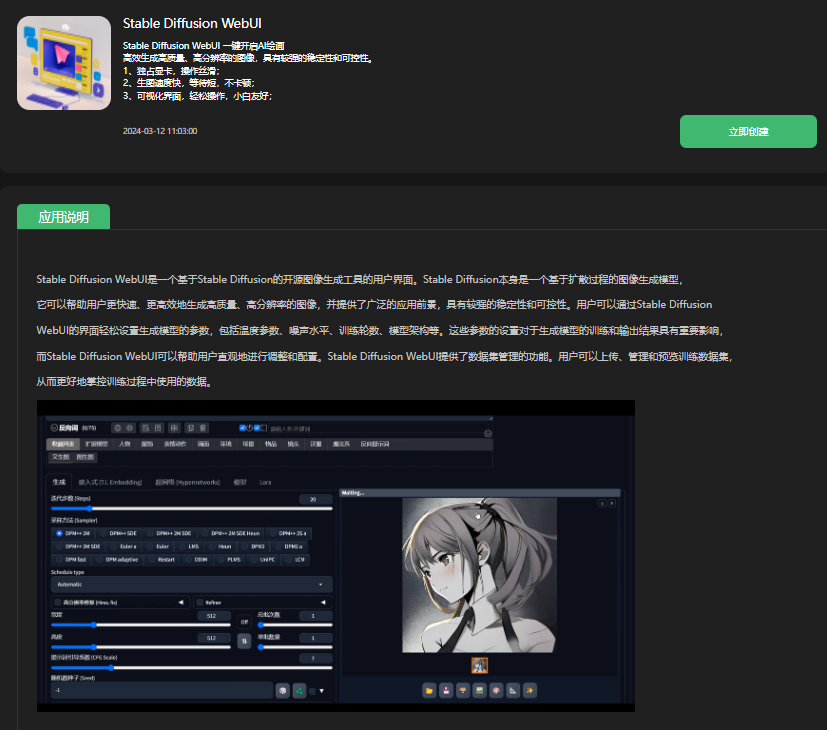
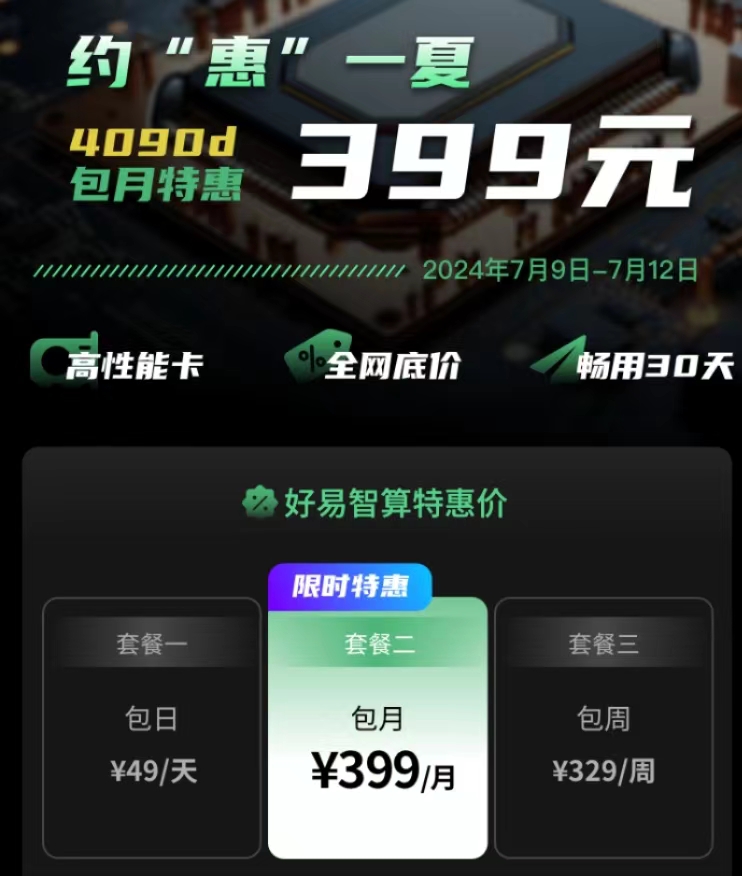
近期,好易智算平台7月9日上线推出了399包月,用户可在算力市场中自由选择心仪的算力资源,享受到前所未有的价格优惠。
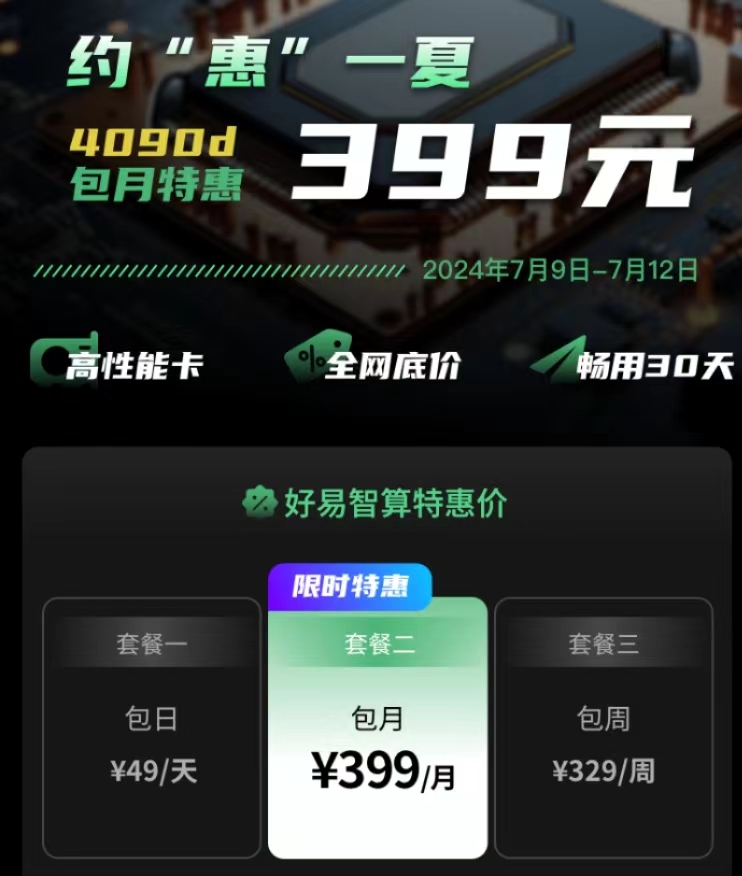
原因分析
首先我们要了解脸部崩坏的原因
为什么在使用Stable Diffusion生成全身图像时,脸部细节往往不够精细?
- 问题一:图像分辨率和细节处理
在生成全身图像的过程中,模型会将计算资源集中于整个身体的描绘,包括服装、姿势和背景等要素。脸部通常仅占整个图像的一小部分,相对地,分配给脸部细节处理的资源就显得有限。这导致在最终生成的全身图像中,脸部的细节可能不如半身图像那样清晰。 - 问题二:训练数据的偏差效应
如果您的数据集中包含了大量高清的半身像而非全身像,Stable Diffusion模型可能会倾向于专注于处理这些半身像。由于全身像包含更多的图像元素和更高的维度,模型在绘制时需要投入更多的计算能力。因此,它在半身像的处理上可能会更有优势。 - 问题三:生成算法的局限性
当前的生成算法在处理尺寸不同的对象时,可能存在一些限制。例如,脸部区域是一个复杂且细节丰富的部分,而当算法处理全身图像时,可能难以保持对脸部细节质量的关注。 - 问题四:计算资源的限制
要生成一个特定尺寸的图像(如320x240像素),模型需要进行一系列运算,包括模板提取、特征表示、搜索和匹配等。这些都需要计算资源,并且在有限的资源下,对图像不同部分的优化可能会增加计算成本。因此,对于全身图像,可能对脸部细节质量有所优化,或者简化了处理流程。
解决策略
利用更高分辨率图像进行训练
通过使用更高分辨率的图像来进行训练,模型可以学习更多细节,这对提升生成照片中脸部的细节是有益的。
但是更高的分辨率会导致人物拉长畸形,大大降低了质量使用更高的算力
提升GPU算力是提高计算机在图形处理、科学计算、深度学习等高性能计算任务中性能的关键。GPU,即图形处理单元,是一种高度并行的处理器,专门设计用来快速处理和渲染图像。
在今天的数字时代,我们可以通过一个简单快捷、功能强大的平台来迅速启动我们的服务。这个平台就是“好易智算”。在这个集成了无数AI应用程序的平台上,只需选择想要的应用,无需部署便会被轻松启用。这种前所未有地便捷体验极大地降低了访问这些前沿技术的门槛,让用户能够轻松而高效地利用这些技术,从而极大提升了工作效率和生活质量。并且提供了极高的资源选择
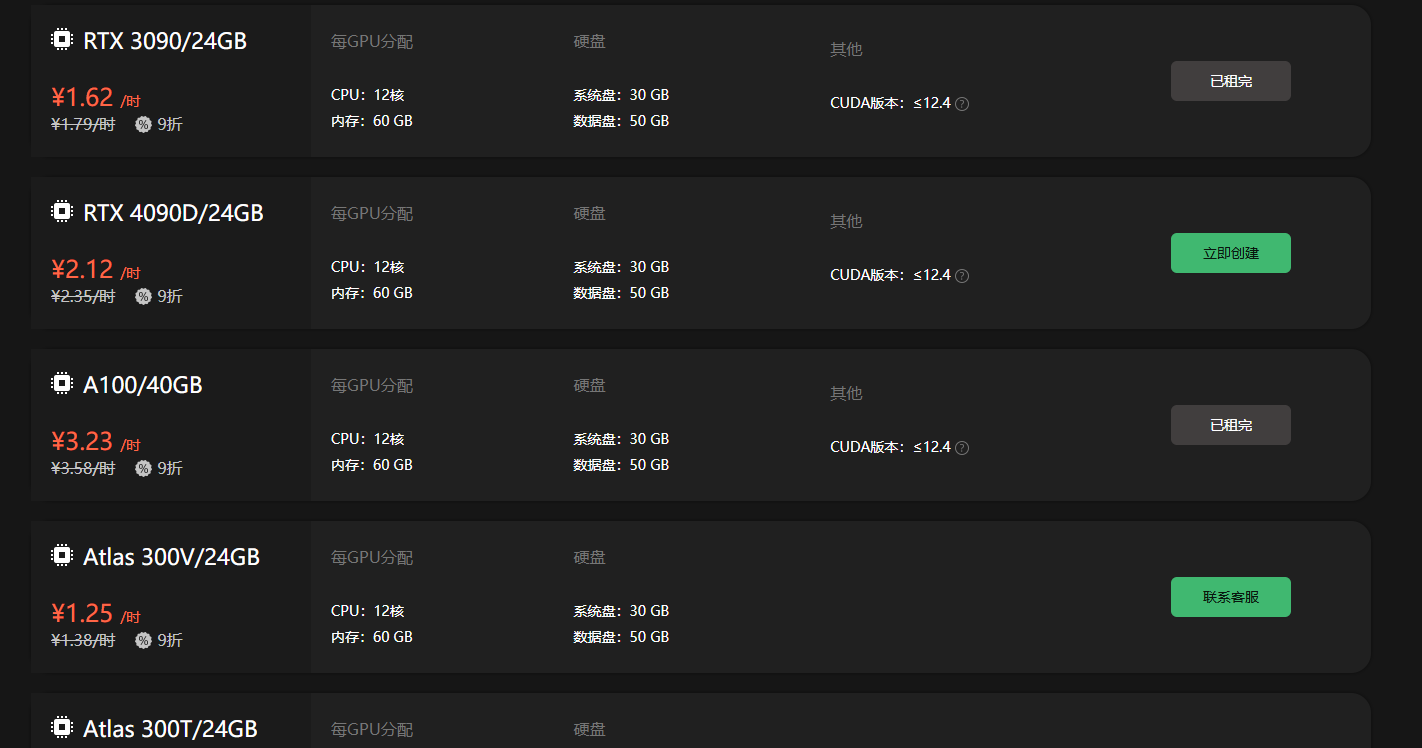
- 在生成全身图像时采用引导技术
在生成全身图像时,尝试应用引导技术(如注意力机制),这样可以让模型更加专注于脸部区域,从而提高对脸部细节的关注。
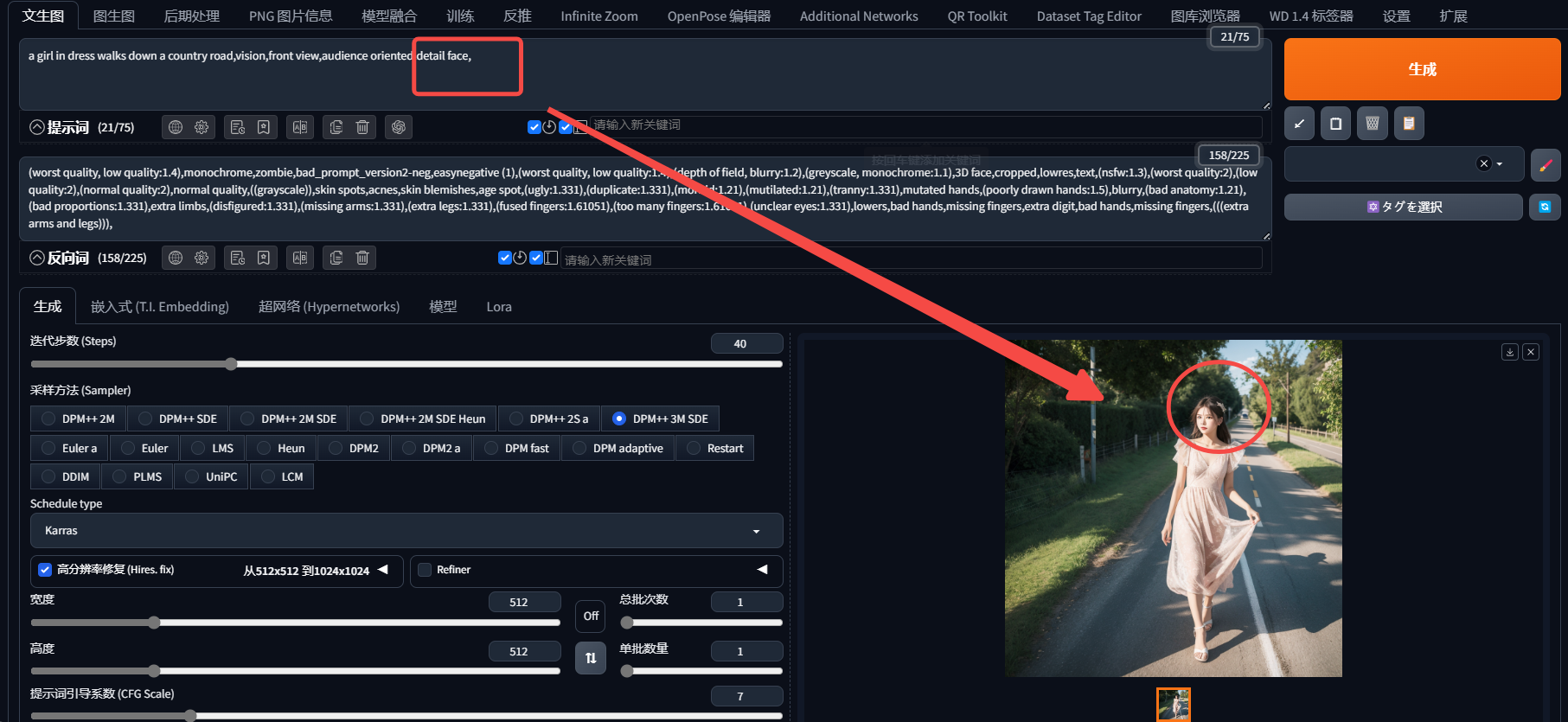
我们可以看到即使使用了prompt之后,Stable Diffusion似乎听不懂一样只是对面部加了一个渲染,但并没有达到预期的效果

局部重绘
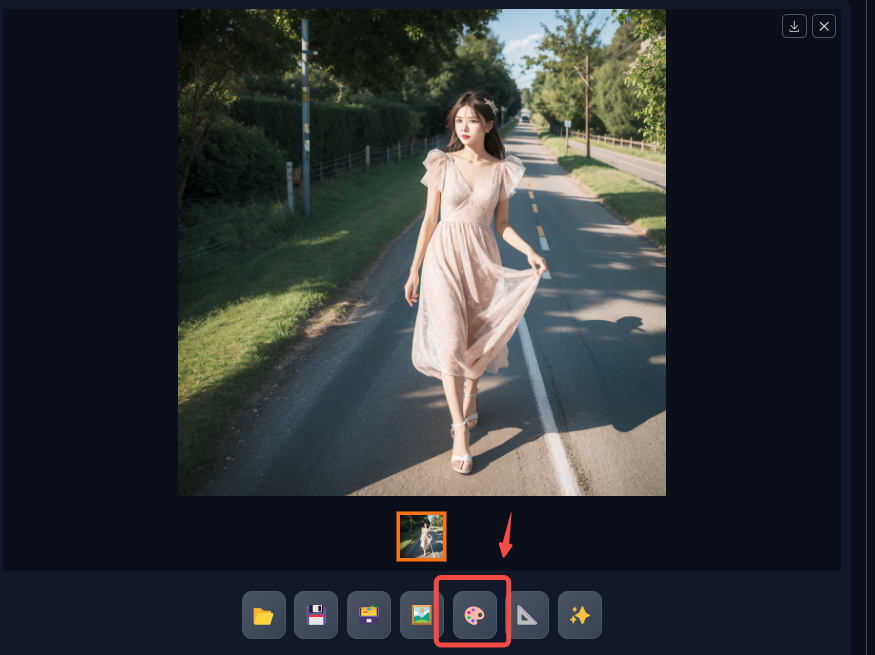
我们可以直接点击这里到局部重绘,在选择重绘内容之后,如下: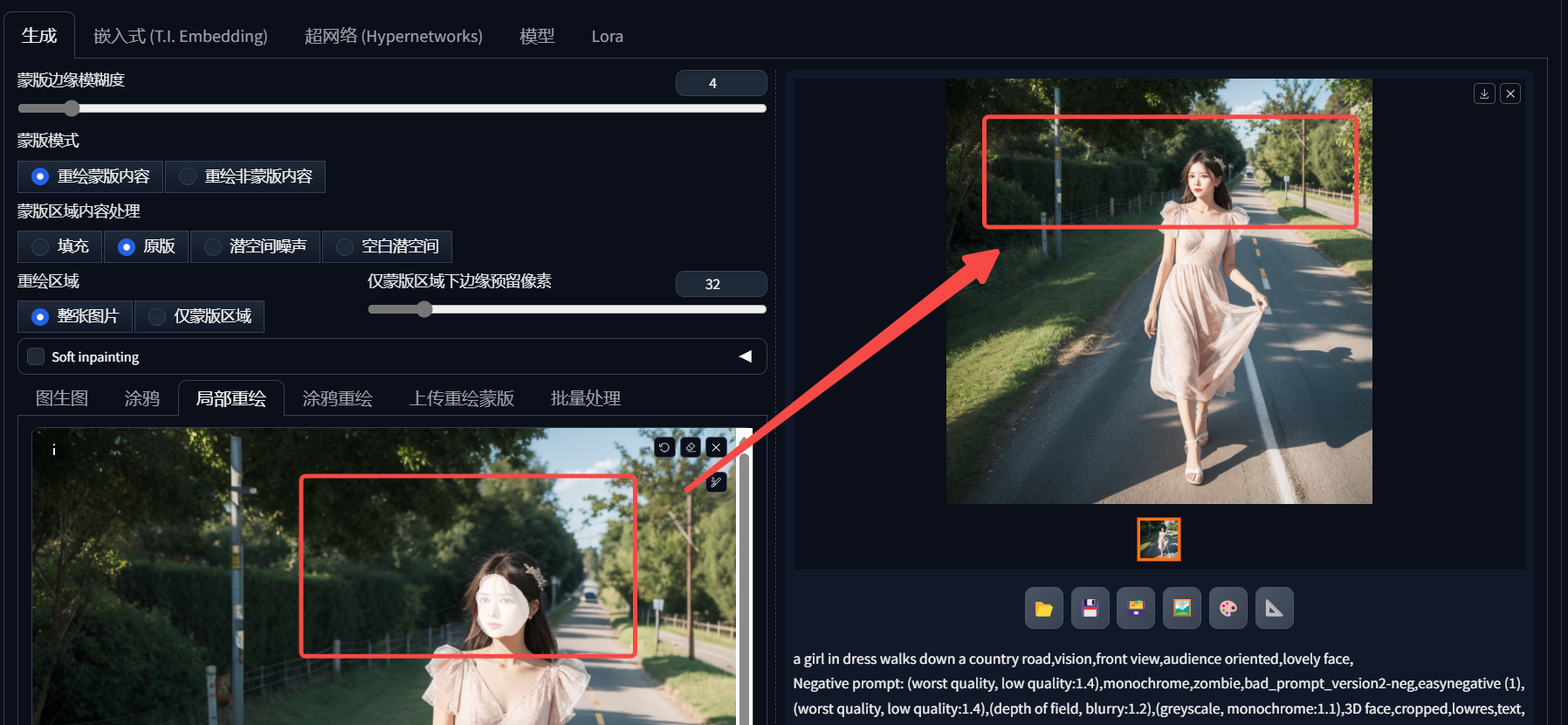
提示词都不用变化,只需要把负面词加上即可
(worst quality, low quality:1.4),monochrome,zombie,bad_prompt_version2-neg,easynegative (1),(worst quality, low quality:1.4),(depth of field, blurry:1.2),(greyscale, monochrome:1.1),3D face,cropped,lowres,text,(nsfw:1.3),(worst quality:2),(low quality:2),(normal quality:2),normal quality,((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))), - 调整参数设置
通过增加迭代次数或采用不同的采样方法,可以提高生成图像的质量,其中包括脸部细节。
我们借助一个简便快捷且功能完备的平台,迅速开启我们的各项服务。这便是“好易智算”平台。在这个集合了众多AI应用的平台,这些应用中还集成了丰富的采样器和采样方法,极大提升了生成高质量图片的能力。这种前所未有的便捷体验大幅降低了接触这些尖端技术的难度,使得用户能够轻而易举、高效地运用这些技术,进而显著提高了工作效率和生活品质。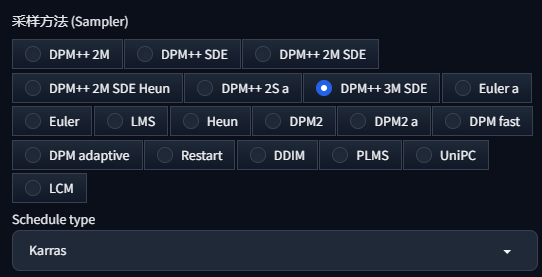
这款产品提供即时可用的云计算服务,无需配置,无需等待,随时启动,即刻享受预设配置,真正实现即开即用的便捷体验。
采样器
在探讨Stable Diffusion的核心技术中,采样器扮演着至关重要的角色。本文将深入分析几种主要的采样器,以及它们各自的特点和应用场景,为读者提供更全面的了解。
首先,我们来看Euler采样器。这是一个基础而简洁的工具,它采用欧拉方法来进行迭代操作。欧拉方法本质上是一种高效的数值积分技术,专门用于求解非线性常微分方程。当应用于图像生成时,Euler采样器通过迭代去噪,可以有效地去除图像中的噪声。尽管速度快,Euler采样器也可能导致一些图像细节受损,因为过度的去噪可能会丢失一些微妙的边缘信息。
接下来是Euler a采样器,作为Euler的改进版,它增加了额外的参数用于控制去噪过程。这些参数的引入使得用户能够在去噪过程中拥有更多的自主权,从而有望获得更高的图像质量。这种改进带来了一系列潜在的优势:如更平滑的采样体验、更精细的噪声控制以及更优的整体图像效果。
转向Heun采样器,它的设计理念源自Heun方法,这是一种结合了Euler和Midpoint方法的创新技术。Heun方法同样基于数值积分原理,专注于求解常微分方程,并在Stable Diffusion中用于迭代去噪过程。相较于Euler,Heun采样器展现出更加平滑细腻的采样过程,同时提供更为卓越的图像质量。
DPM2采样器则是一种基于物理模型的工具。它采用了“去噪扩散概率模型”(DPM)技术,这一模型能够在去噪过程中优化控制噪声水平,进而生成更高质量的图像。DPM2的强大之处在于它可以精确调整噪声水平,避免了传统去噪方法中常见的“过噪”问题。
DPM2 a是DPM2采样器的又一次重大升级,它继承了Euler a的特性,并引入了更多的参数来进一步控制去噪流程。这些新参数允许用户对去噪过程进行精细的控制,有助于提升最终图像的质量。
DPM fast是DPM系列的另一快速响应选项。它通过降低去噪迭代次数并简化过程的方式,牺牲了一定的图像质量以换取生成速度的提升。尽管如此,DPM fast仍然保留了许多吸引人的特点,包括快速的生成效率和更短的处理时间。
DPM adaptive是DPM2采样器的自适应变体。它具备动态调整采样策略的能力,能够根据图像的复杂度实时调整采样参数。这样做的目的是为了平衡高生成速度和高质量输出之间的关系,确保生成的图像既快又好。
Restart采样器是一种利用重启技术的新型采样器。当图像质量开始出现下降趋势时,Restart采样器会重新开始整个去噪过程,以恢复图像的原有质量,防止其进一步恶化。
DDIM采样器基于迭代去噪技术,使用“去噪扩散迭代模型”(DDIM)。这项技术能够生成非常高质量的图像,但由于它的迭代特性,生成速度相对较慢。
PLMS采样器是DDIM采样器的改良版,它采用了“预条件的Legendre多项式去噪”(PLMS)技术。这种方法不仅能提供更好的图像质量,还能在生成速度上略胜一筹,与DDIM形成鲜明对比。
UniPC采样器基于统一概率耦合,采用“统一概率耦合”技术实现高质量图像输出。UniPC虽然在图像质量方面表现出色,但其复杂性和迭代特性导致了较慢的生成速度。
LCM采样器则基于拉普拉斯耦合模型,运用“拉普拉斯耦合模型”技术。LCM同样能够产出非常高品质的图像,但由于其结构的复杂性及迭代特性,生成速度也相应受到影响。
DPM++ 2M采样器是DPM2的进一步改进版,它引入了许多额外的去噪步骤和参数,旨在提升图像质量。特别值得一提的是,DPM++ 2M在去噪概率模型方面做出了重要的更新。
DPM++ SDE采样器是DPM2的基于随机微分方程(SDE)的改进版本。SDE技术的引入为图像生成提供了更加稳定和高质的结果。
DPM++ 2M SDE采样器是DPM++ 2M与DPM++ SDE结合的产物。它融合了两种技术的优势,为用户带来了更佳的图像质量。
DPM++ 2M SDE Heun采样器是DPM++ 2M SDE的进一步升级,它使用Heun方法进行迭代,结合了去噪扩散概率模型和Heun方法的共同优点。
DPM++ 2S a采样器是DPM++ 2M的最新版本,它增加了额外参数来精细控制去噪过程。这些新增的控制参数允许用户在去噪过程中拥有更多选择,有望获得更加精细和高质量的图像。
最后,我们来看看DPM++ 3M SDE采样器。它是DPM++ 2M SDE采样器的第三代进化版,引入了更多的去噪步骤和参数以追求更高的图像质量。DPM++ 3M SDE的目标是在保持前两代产品优点的同时,进一步提升性能和图像质量,为用户提供更加流畅和精细的图像生成过程。
总结
在当今这个视觉至上的时代,无论是艺术创作、广告宣传还是社交媒体分享,高质量的图像都是吸引观众、传递信息的关键。通过上述介绍的解决策略和技术改进方法,我们不仅能够艺术地掌控人物形象,还能更好地运用Stable Diffusion采样器,这是图像生成领域的一大进步。
艺术地掌控人物形象,不仅需要我们有独到的审美眼光,还需要我们掌握相关的技术手段。从化妆造型、服饰搭配到光影效果、后期处理,每一个环节都至关重要。通过上述介绍,我们了解到如何通过细节的调整,让人物形象更加立体、生动。
而Stable Diffusion采样器的运用,则是图像生成技术的又一次飞跃。它通过算法模拟出自然、逼真的图像效果,大大提高了图像生成的质量和效率。通过上述介绍,我们了解到如何通过调整参数、优化算法,让Stable Diffusion采样器更好地为我们服务。
然而,无论是艺术地掌控人物形象,还是运用Stable Diffusion采样器,都离不开强大的算力支持。**好易智算平台**作为一个优秀的算力资源提供者,为我们的图像生成提供了强有力的保障。它不仅提供了高效的计算资源,还提供了便捷的操作界面和专业的技术支持,让我们的图像生成工作更加轻松、高效。
总的来说,通过上述介绍的解决策略和技术改进方法,我们不仅能够艺术地掌控人物形象,还能更好地运用Stable Diffusion采样器,让我们的图像生成工作更加高效、高质量。同时,好易智算平台此次399包月活动为用户带来了极大的实惠,7月9日上线让更多用户能够以优惠的价格轻松获取所需的算力资源,助力他们在各自领域取得更好的成果。