阅读量:0
由于篇幅限制,无法展示完整代码,我直接将代码打包上传,安全无毒,100%免费,在评论区发已关+评论即可领取!

背 景
学编程是为啥?偷懒呗~有时候去豆瓣看到比较感兴趣的或者想看朋友文字推荐的电影,就得打开电影网站获取电影的下载链接,然后用迅雷下载观看,我觉得挺麻烦的。当然要是在线观看就是另外一回事了。我喜欢下载下来看,不会卡不会有广告,贼舒服~
知 识 点
requests:属于第三方模块,是一个关于网络请求的对象,通过方法 get() 或者 post() 模拟浏览器向服务器获取数据
pyperclip:也是第三方模块,有 copy() 和 paste() 两个函数。前者是复制内容到计算机的剪切板上,那后者就是将剪切板的内容粘贴到计算机上
quote:将数据转换为网址格式的函数,需从 urllib.request 模块中导入
BeautifulSoup:是一个用于解析网页和提取数据的对象,使用前需安装 beautifulsoup4 模块,但导入该模块时使用 bs4 代替。该对象需要输入两个参数:一是文本格式的网页源代码,二是解析网页需要用到的解析器(比较常用的:html.parser 或者 lxml)。该对象可以用方法 find() 或者 findall() 获取网页标签对象(tag), 提取标签的数据可以在 tag 后使用 text 或 ['标签内代表链接的属性'] 两个属性
encode:将unicode 编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将 unicode 编码的字符串 str2 转换成 gb2312 编码
decode:将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码
try...except...:用于异常处理。try 从句中包含程序运行过程中可能会出错的语句,except 从句中是当 try 从句中发生错误后所要执行的语句
确 定 目 标
本次爬取的网站是:阳光电影(‘ http://s.ygdy8.com ’),原因是它没有反爬措施,容易抓取数据,资源相对丰富,关键是资源免费,适合练手
我们要实现的效果是:通过复制一个电影名,运行程序后会自动复制并输出该电影的下载链接或其他的反馈信息,达到快速下载电影的效果
分 析 目 标
首先打开网站,进入到如下界面:
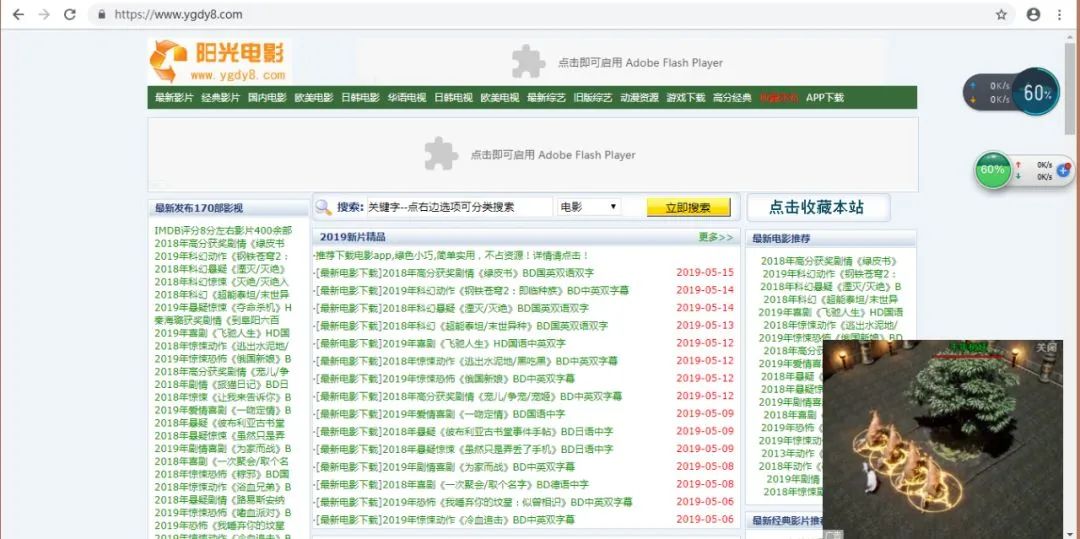
然后我们在搜索框中输入并搜索 ‘ 飞驰人生 ’ 这部电影,看看网址会有什么变化
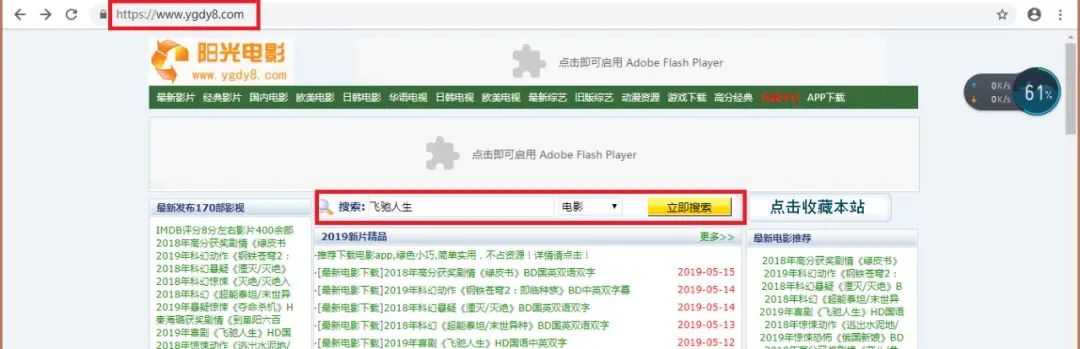
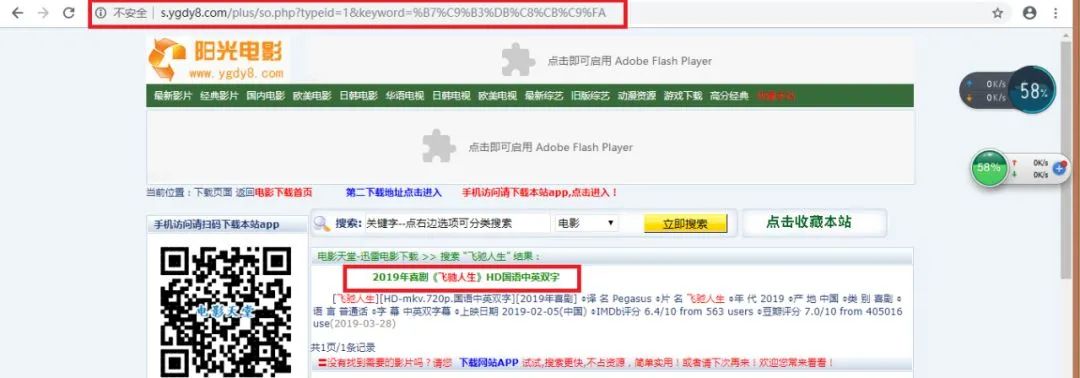
通过两张图的对比,可以发现原网址 ‘ http://s.ygdy8.com ’ 变成了 ‘ http://s.ygdy8.com/plus/so.php?typeid=1&keyword=%B7%C9%B3%DB%C8%CB%C9%FA ’
现在我们可以知道,要向服务器请求该界面的前提是需要提交 typeid 和 leyword 的值
那我们来找找这两个参数有神马规律
再搜索个 ‘兄弟班 ’ 试试?
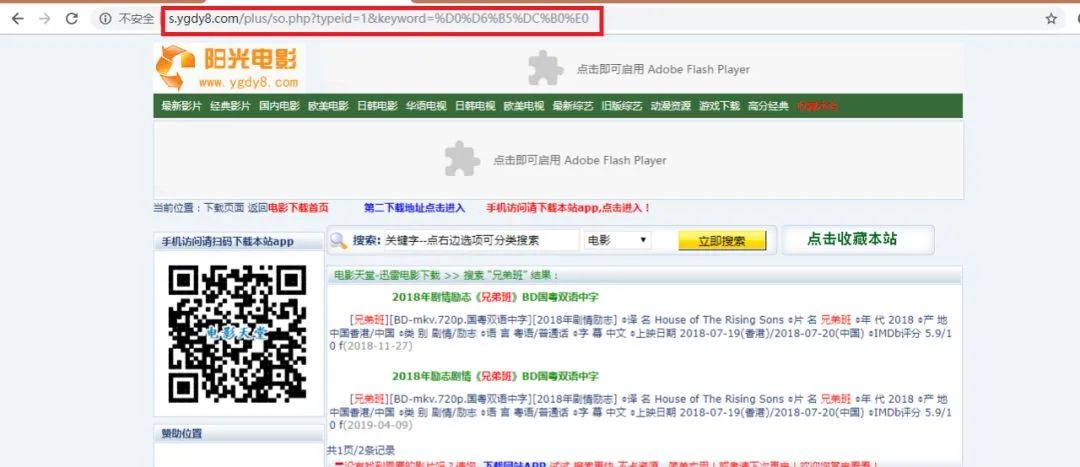
网址是:‘ http://s.ygdy8.com/plus/so.php?typeid=1&keyword=%D0%D6%B5%DC%B0%E0’
通过两个网址的对比,可以知道参数 typeid 的值是不变的,keyword 是关键字的意思,那应该就是我们搜索的电影名,不过是十六进制的网址格式,所以待会需要用函数 quote() 转换一下
继续~
我们知道这个网址的规律后,就可以用 requests 模块下载这个网页来获取我们需要的第二个网址--进入电影信息界面的跳转网址。但也有可能在这里没有这个电影资源,那肯定找不到这个网址,所以待会写代码的时候就要有个提示信息。
刚好 ‘ 飞驰人生 ’这部是有的 ,所以现在一起来提取数据吧~
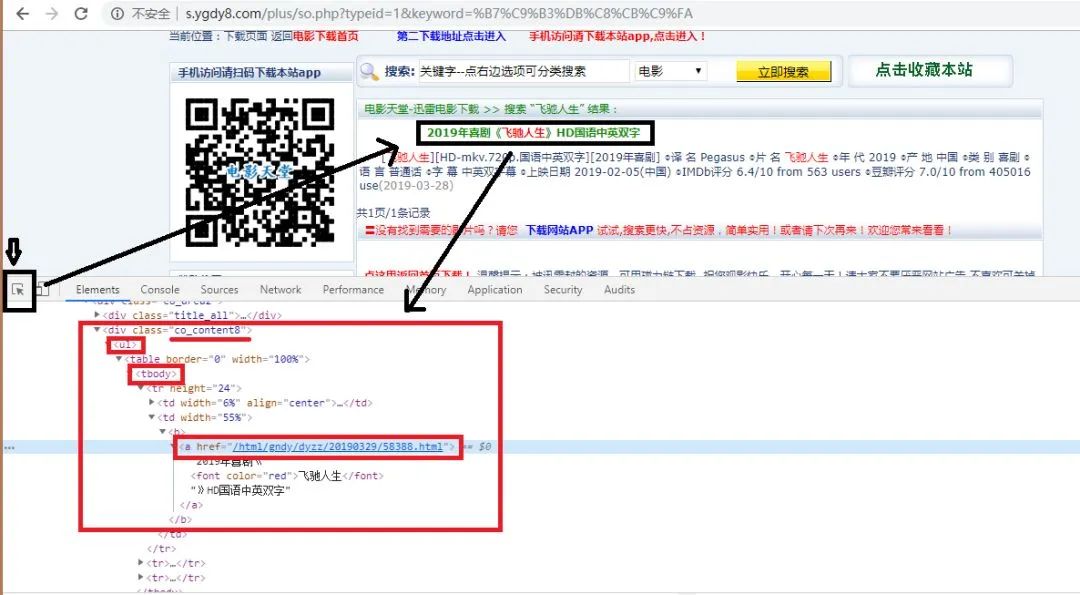
按 f12 打开我们的开发者工具,按照我上图中的步骤操作,找到数据在网页源代码中的位置。
我们发现我们需要的数据被包含在一个标签为 div ,属性 class 的值为‘ co_content8 ’下的 a 标签中,并且是属性为 ‘ href ’ 的值。不过为了防止还有其他 a 标签,我们还是先获取 ul 标签,再获取 a 标签,因为里面只包含一个 a 标签(我怎么知道?因为我傻傻的检查过了。。)
通过代码获取到该链接后,再用 requests 下载该链接,获取到的网页的界面如下:
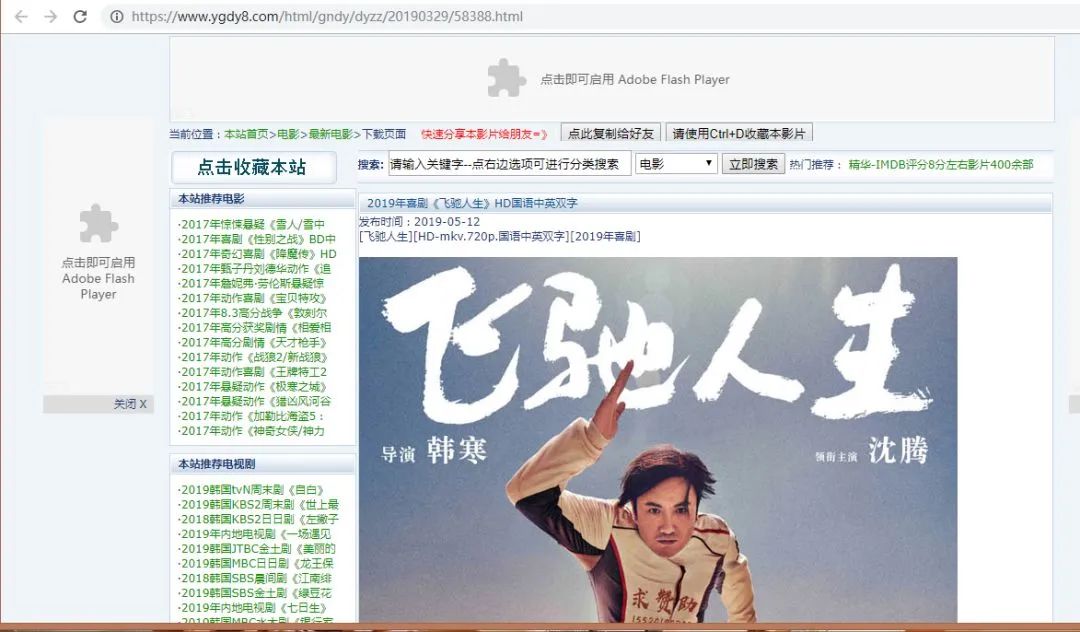
拉到下图位置,并再次打开开发者工具,重复之前在网页源代码中寻找数据的步骤
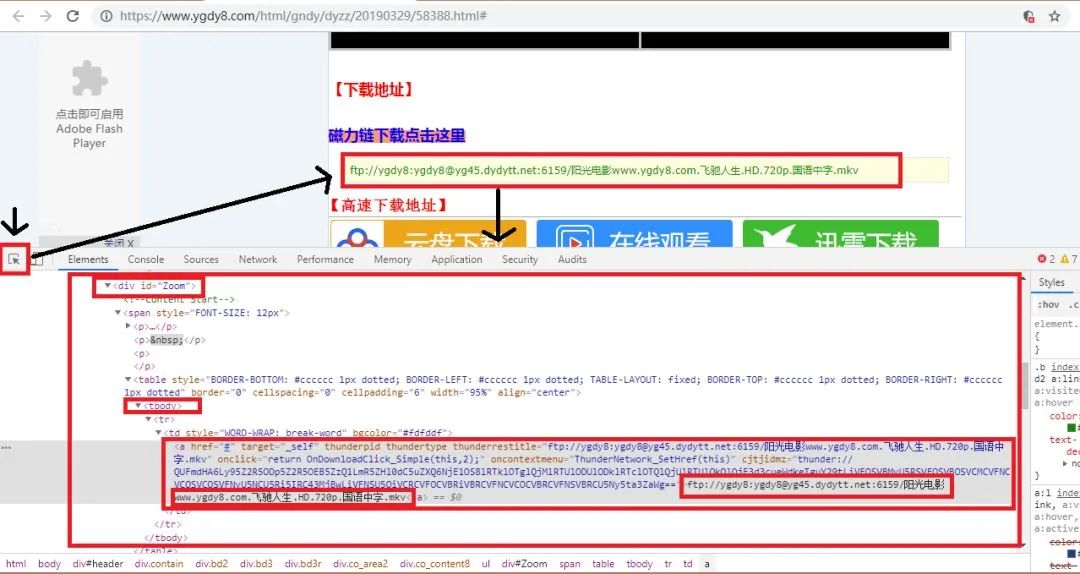
我们发现我们需要的数据被包含在一个标签为 div 且 id 属性为 ‘ zoom’ 的节点内,具体是标签为 'a' 内。这里的 tbody 也是为了防止受到其他 ‘ a ’ 标签的影响。最后通过代码提取这个下载链接就可以了。
好,分析过程已经结束了,现在开始写代码吧~
代 码 实 操
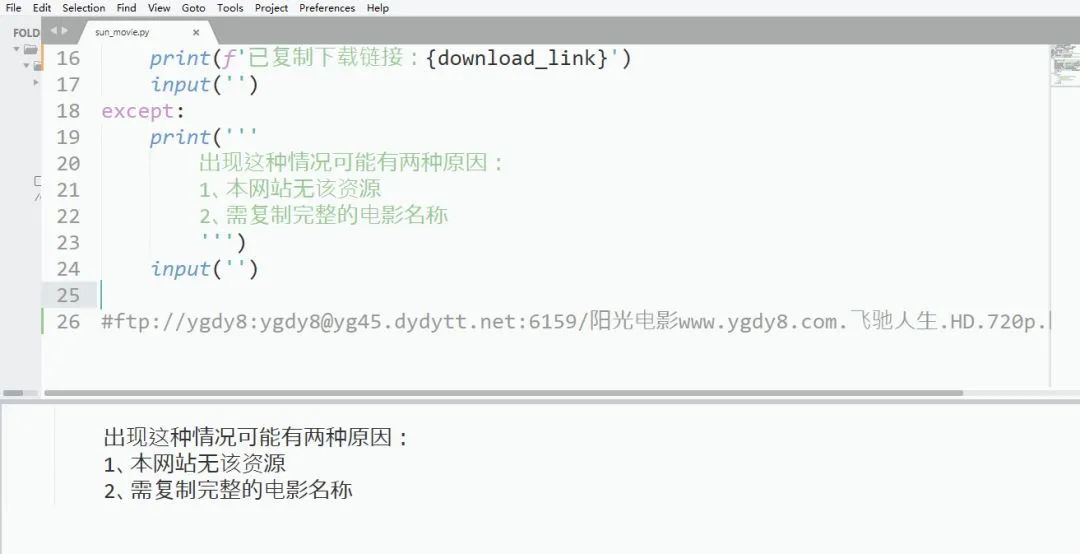
ort requests,pyperclipfrom urllib.request import quotefrom bs4 import BeautifulSoupname= pyperclip.paste()gbk_name= name.encode('gbk')find_url= f'http://s.ygdy8.com/plus/so.php?typeid=1&keyword={quote(gbk_name)}'req= requests.get(find_url)bs= BeautifulSoup(req.text,'html.parser')try:tag= bs.find('div',class_='co_content8')link= 'https://www.ygdy8.com'+tag.find('ul').find('a')['href']req_download= requests.get(link).content.decode('gbk')bs_download= BeautifulSoup(req_download,'html.parser')download_link= bs_download.find('div',id='Zoom').find('tbody').find('a').textpyperclip.copy(download_link)print(f'已复制下载链接:{download_link}')input('')except:print('''出现这种情况可能有两种原因:1、本网站无该资源2、需复制完整的电影名称''')input('') #可以解决运行程序一闪而过的问题
如果运行程序前先打开迅雷,会更快哦~~
检 验 效 果
复制图中的 ‘飞驰人生’,运行程序后复制并输出了该电影的下载链接
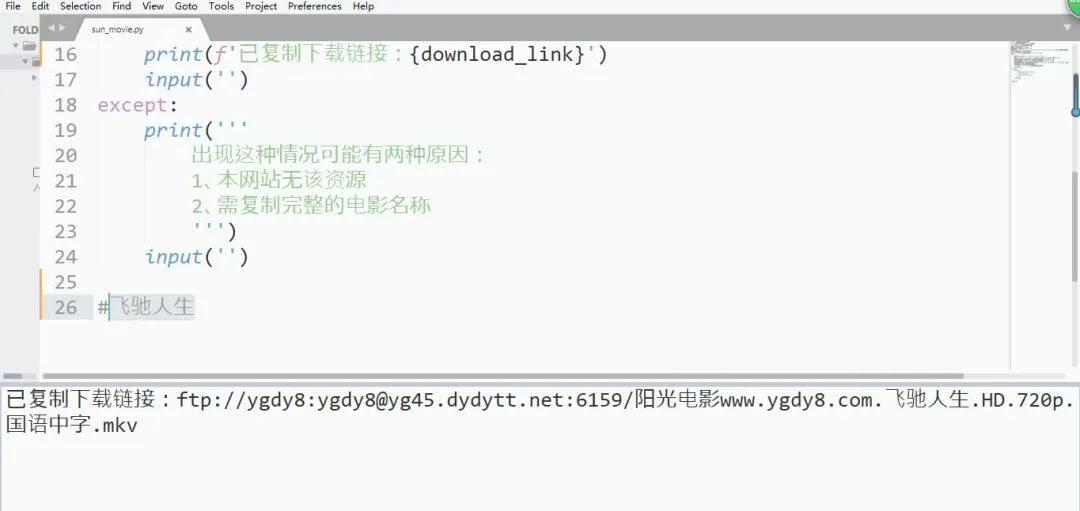
接下来是复制了刚才的链接,这肯定是找不到的对不对,找不到程序就会提示以下信息