
阅读量:0
一、用不同url头利用python访问一个网站,并把返回的东西保存为
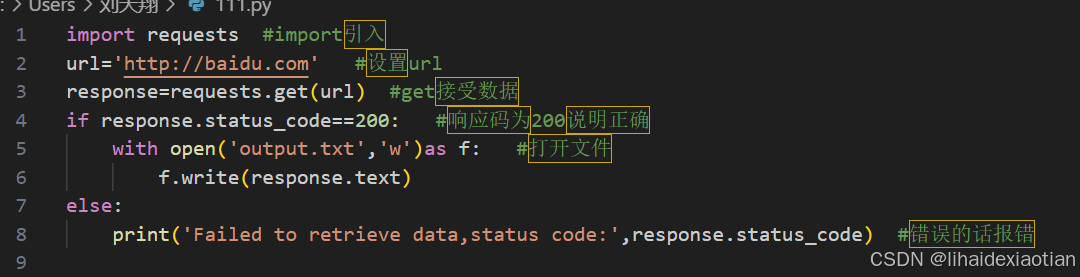
requests库
主要用于http发送请求和处理响应
1.发送get和post请求
requests.get(目标网址)
requests.post(url,data)
post于get不同的是get一般用来请求获取数据,而post相当于带着数据去更新一下
get也可以向后台传数据,在url中;而post的数据放在request body中,所以我们使用post的时候就要放data哦,也可以不放,度数一般使用post更新数据什么的
2.设置请求头和请求体
请求头用headers={}
请求头告诉服务器一些额外信息
比如
User-Agent用于指定用户代理
Authorization用于进行身份验证
用法加单引号,
请求体用data
请求体用于向服务器提交数据
3.处理响应
status_code 获取状态码
headers 用于获取响应头
text 用于获取文本内容
content 用于获取二进制内容
json 用于解析为python字典
session用于创建一个会话
auuth 用于指定身份
proxies 用于设置代理
ConnectionError 这个指网络连接错误
HTTPError 指服务器错误
Timeout 请求超时
二、python的正则表达式
正则表达式用于匹配、替换、查找
正则表达式在python中用re模块
匹配
把符号放在匹配的字母或者数组字后面就代表
| + | +号代表1.2.3.4.5.6... 不可以0 |
| * | *代表可以是0.1.2.3.4.5.6...个该字符 ab*c可以匹配的是ac abc abbc abbbc... |
| {} | 如果要指定有多少个 ab{6}c ab{2,6}c代表2到6 ab{2,}这个指直接2以后 如果想要多个字符直接用大括号括起来 {ab}+c |
| ? | ?代表出现0个或者1个 |
| ( | ) | 或逻辑 a(cat|dog)acat adog |
| [ ] | 匹配的字符都取于其中一个 |
| ^ | 代表除.....以外 |
元字符
| \D | 非数字字符 |
| \d | 数字字符 |
| \w | 单词符(数字,字母,下划线) |
\W | 非单词符 |
| \s | 空白符(包含tab和换行符) |
| \S | 非空白符 |
| . | 任意字符(不包括换行符) |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
.+ 默认贪婪匹配,会匹配尽可能多的字符串
.+? 加问号后就是懒惰匹配啦
.* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
(.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
相当于贪婪的时候在满足正则的情况下尽可能多的取
非贪婪就尽可能少的取
内部制约关系可以先分成几个组用小括号
\的作用:引用分组。\1表示引用第一组,\是转义字符,转义后代表一个
()表示分组,()代表一个分组
^俩个用处
1.表示在行首
2.如果反复在[]里面[^ ]表示取反
这样的话我们就可以合起来一起用
^\w{4,20}@163\.com$ 匹配163邮箱
我们可以观察其中的规律,我们就可以匹配
这里在网络上有很多,然后看起来也是非常的繁多,就记住一个一个符号看,
1.如果在没有大括号的情况下一个符号只代表他前面一位的字,然后慢慢分析
2.记得\反斜杠有时候用来转义
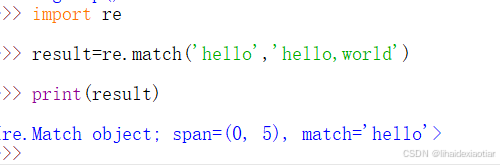
re模块
re.match与re.search都是用于匹配
re.match('正则表达式','要匹配的字符串‘,'其他设置’)
1.re.match
match从头开始匹配,如果第一个匹配不上的话就直接返NONE,匹配成功返回一个对象,它只能返回一个,并不能把所有情况都匹配出来
2.re.search
扫描整个字符串并返回第一个成功的匹配,
匹配成功re.search方法返回一个匹配的对象,否则返回None
3.re.findall
也是用于匹配,返回所有匹配结果
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
4.re.sub
用于替换
re.sub('正则表达式‘,'要替换的部分','原字符串',‘替换次数,默认为0’,‘其他设置’)
其中要替换的部分可以是一个函数,如果是一个函数,就直接执行该函数的功能,替换该函数改变的地方,其他不变
默认为0是全部替换
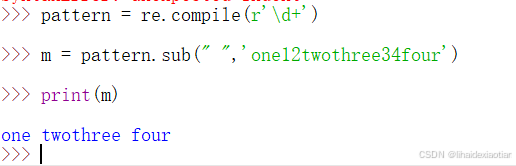
5.re.compile
该函数是一个用于生成编译正则表达式对象
pattern = re.compile(r'\d+') # 用于匹配至少一个数字
m = pattern.match('one12twothree34four',2, 10)
直接将正则表达式转换为一个对象,就可以与我们的目标字符串进行匹配啦
可以直接匹配或者我们可以限制一下字符串的起始位置
其他的match ,search,findall
我试了试sub也可以用
就是用了compile生成对象以后,其他函数一个可以正常使用,只要咱们符号人家的格式
- 如果没有任何指定返回
- group()返回被re匹配的字符串
- start()返回匹配开始的位置
- end()返回匹配结束的位置
- span()返回一个元组包含匹配(开始,结束)的位置
| re.IGNORECASE 或 re.I | 使匹配对大小写不敏感 | |
| re.MULTILINE 或 re.M | 多行匹配,影响 ^ 和 $,使它们匹配字符串的每一行的开头和结尾。 | |
| re.DOTALL 或 re.S: | 使 . 匹配包括换行符在内的任意字符。 | |
| re.ASCII | 使 \w, \W, \b, \B, \d, \D, \s, \S 仅匹配 ASCII 字符。 | |
| re.VERBOSE 或 re.X | 忽略空格和注释,可以更清晰地组织复杂的正则表达式。 |
三、信息收集
他们说渗透的本质就是信息收集,我们也是要开始了解渗透啦,加油加油啊
首先咱们可以先来了解一些网站的一些概念叭,一些有文化的名称(咱们也是文化仁)
1.网站(Website)是指在因特网上根据一定的规则,使用Html等工具制作的用于展示特定内容相关网页的集合。总之就是网站是在互联网上拥有域名或地址并提供一定网络服务的主机,是存储文件的空间,以服务器为载体。就是大体这么个意思,还有网站与网页的区别,网站由网页组成。网站一定要有域名。
2.服务器是计算机的一种,但是它比普通计算机运行更快、负载更高。而且服务器是用于存储、处理、传输大量数据。
3.ip地址是IP协议提供的一种统一的地址格式,用来访问每一台主机。
IPV4实际上是一个32位的二进制,被分为4部分,实际上是32进制,但是我们一般用十进制里表示
(202.196.80.211),实际上是32位二进制数(11001010.11000100.01010000.11010011)
当然每一部分为0到255的数字组成
还可以分为公有地址和私有地址
我们这里了解一些特殊地址
1.(0.0.0.0)对应于当前主机
2.IP地址中不能以十进制“127”作为开头,该类地址(127.0.0.1~127 .255.255.255)用于回路测试,如:127.0.0.1可以代表本机IP地址,用“http://127.0.0.1”就可以测试本机中配置的Web服务器
3.网络ID的第一个6位组也不能全置为“0”,全“0”表示本地网络
4.IP地址中凡是以“11110”开头的E类IP地址都保留用于将来和实验使用
4.域名是人们因为ip地址太难记所以就发明了域名,是字符型地址
域名一般由俩个或俩个以上的组成,为 三级域名.二级域名.顶级域名,从后往前控制下一级域名的分配。
顶级域名
国家顶级域名:中国是cn,美国是us,日本是jp
国际顶级域名:工商企业的.com,表示网络提供商的.net,表示非盈利组织的.org
二级域名
国家顶级域名下,它是表示注册企业类别的符号,中国的二级域名又分为
类别域名:用于科研机构的ac;用于工商金融企业的com;用于教育机构的edu;用于政府部门的gov
和行政区域名两类:有34个,分别对应于中国各省、自治区和直辖市
三级域名
用字母(A~Z,a~z,大小写等)、数。。字(0~9)和连接符(-)组成,各级域名之间用实点(.)连接,三级域名的长度不能超过20个字符
5.dns(域名系统),作为可以将域名和IP地址相互映射的一个分布式数据库,是进行域名和与之相对应的IP地址转换的系统
域名和IP地址是一对多的关系,一台服务器只能有一个IP地址,但是却可以有多个域名
6.url
域名不可以直接访问网站,只有通过解析变成url才能访问,一个url对应web
7.端口
端口是用来区分不同的网络服务的,比如
21端口:FTP 文件传输服务(ftp就是专门传输文件的)
22端口:ssh协议(用于计算机直接加密登录,可远程登录)
53端口:DNS 域名解析服务
80端口:HTTP 超文本传输服务
443端口:HTTPS 加密的超文本传输服务
3306端口:MYSQL 默认端口号
8.静态网站和动态网站
静态网站是指全部由HTML代码格式页面组成的网站,所有的内容包含在网页文件中
动态网站指网站内容可根据不同情况动态变更的网站,一般情况下动态网站通过数据库进行架构。 动态网站除了要设计网页外,还要通过数据库和编写程序来使网站具有更多自动的和高级的功能
8.cdn
内容分发网络,基本思路是尽可能避开互联网上有可能影响数据传输和稳定性的瓶颈和环节,使内容传输得更快、更稳定
提高用户访问网站的响应速度
9.cms
内容管理系统,
我们认为内容管理系统是一种位于WEB前端(Web 服务器)和后端办公系统或流程(内容创作、编辑)之间的软件系统
1.whios查询
whios查询可以查到注册商以及一些联系方式,注册时间,过期时间等
域名,dns等
通过反查注册人和邮箱得多更多得域名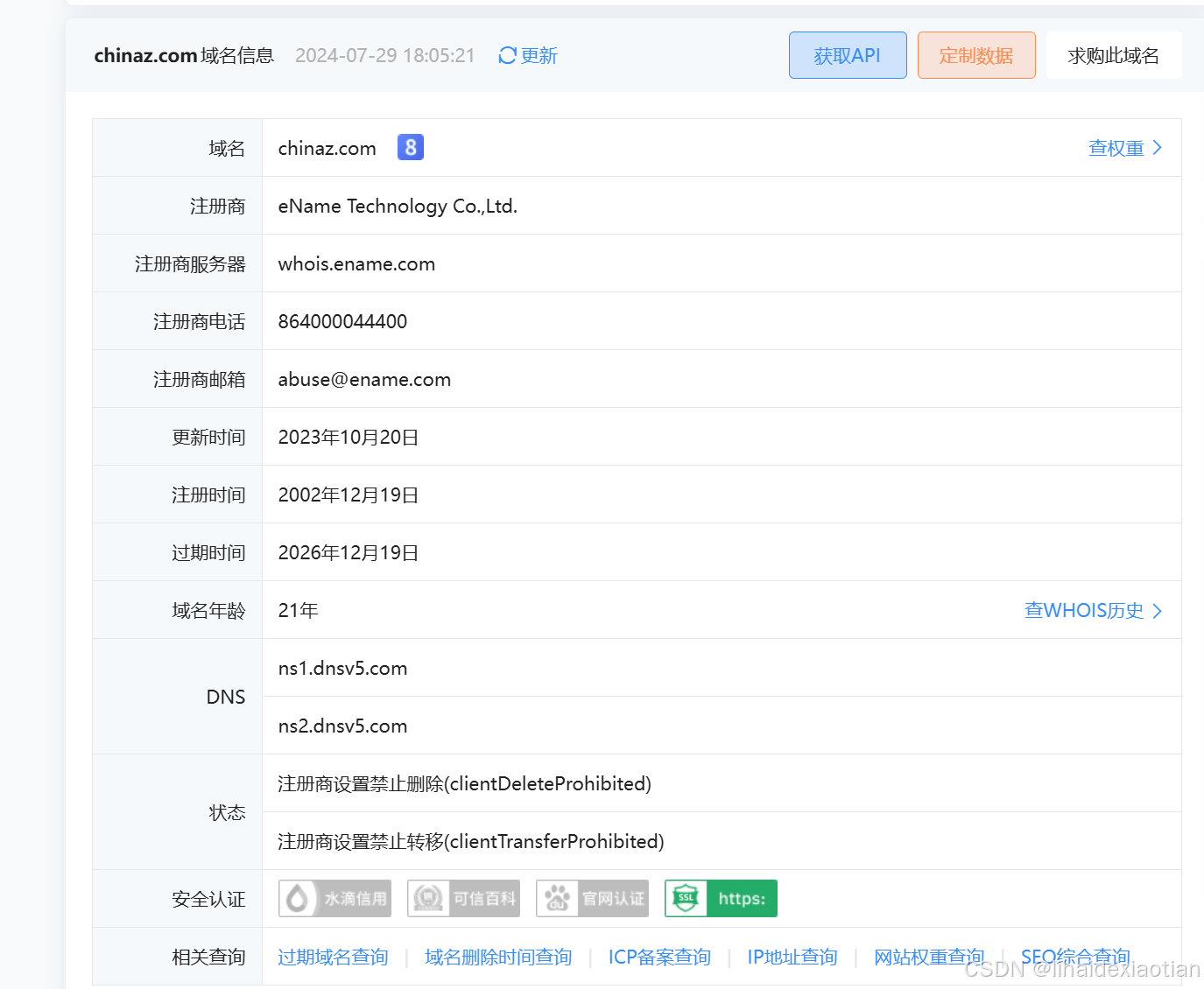
好多好多搜索的东西,啊,应该都差不多
Shodan:https://www.shodan.io/
站长之家域名WHOIS信息查询地址 http://whois.chinaz.com/
爱站网域名WHOIS信息查询地址 https://whois.aizhan.com/
腾讯云域名WHOIS信息查询地址 https://whois.cloud.tencent.com/
中国万网域名WHOIS信息查询地址 https://whois.aliyun.com/
国外WHOIS信息查询地址 https://who.is/
网站备案信息是根据国家法律法规规定,由网站所有者向国家有关部门申请的备案,如果需要查询企业备案信息(单位名称、备案编号、网站负责人、电子邮箱、联系电话、法人等)
天眼查
邮箱可进行钓鱼
2.子域名查询
子域名指顶级域名的下一级
(1)Layer子域收集

输入我们的域名就可以直接开始啦(已下载,勿辜负)
(2)fofa搜索

在网站里就直接有查询语法,所以非常的方便,想查什么就直接查询
也可以通过与或等逻辑把他们组合查询
可以进行端口检索,域名检索,主机检索等等
3.后台登录
尝试看看可不可以直接登录他们的后台
4.旁站和c段信息收集
旁站是和目标网站在同一台服务器但开放在其他端口的网站
C段是指同一内网段内的其他服务器或主机。每个IP有ABCD四个段,如192.168.0.1,A段就是192,B段是168,C段是0,D段是1。则和这个IP地址位于同一C段的IP地址有 192.168.0.0 ~~ 192.168.0.255
旁站:与攻击目标在同一服务器的不同网站,在攻击目标没有漏洞的情况下,可以通过查找旁站的漏洞攻击旁站,然后再通过提权拿到服务器的最高权限,拿到服务器的最高权限后攻击目标
可以通过站长之家来搜索
5.真实ip收集
这个是指寻找真实的地址
通过查询DNS与IP绑定的历史记录就有可能发现之前的真实IP信息
部分存在cdn
通过子域名查询,很多站点只对主站做了CDN加速,子域名并未做CDN加速。而子域名和主站可能在同一服务器或同一C段中,因此得到主站信息
6.端口
nNmap: the Network Mapper - Free Security Scanner
直接用nmap
还有在线扫描工具
http://www.all-tool.cn/Tools/portblast/?&rand=5e5fd89ade531f6304b4e76fd3a10f90
22 端口(SSH)
安全攻击:弱口令、暴力猜解、用户名枚举
利用方式:
1、通过用户名枚举可以判断某个用户名是否存在于目标主机中
2、利用弱口令/暴力破解,获取目标主机权限。
23 端口(Telnet)
安全漏洞:弱口令、明文传输
利用方式:1、通过弱口令或暴力破解,获取目标主机权限。
2、嗅探抓取telnet明文账户密码。
3389 端口(RDP)
安全漏洞:暴力破解
利用方式:通过弱口令或暴力破解,获取目标主机权限。
5632 端口(Pcanywhere)
安全漏洞:弱口令、暴力破解
利用方式:通过弱口令或暴力破解,获取目标主机权限
5900 端口(VNC)
安全漏洞:弱口令、暴力破解
利用方式:通过弱口令或暴力破解,获取目标主机权限。
不行,这个实在是太多了,而且没有实例好难了解,以后慢慢来吧,有点痛苦啦

