
阅读量:0
目录


专栏:机器学习笔记
第一步:准备工作
1.1 安装必要的库
小李的理解:
在开始之前,需要安装一些工具,类似于做饭前要准备好各种食材。这里,需要安装pandas、scikit-learn和matplotlib,它们分别用于数据处理、机器学习和数据可视化。
在Pycharm中打开终端,并运行以下命令:
pip install pandas scikit-learn matplotlib 这些库的作用如下:
pandas:用于数据处理和分析,就像厨房里的切菜板和刀。scikit-learn:用于机器学习模型的构建和评估,相当于厨房里的锅和炉灶。matplotlib:用于数据可视化,类似于摆盘和装饰菜肴。
1.2 导入库
小李的理解:
在新的Python文件中,导入这些库。就像准备好工具后,把它们放在桌子上随时可以使用。
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt 第二步:生成和准备数据
2.1 生成随机股票数据
小李的理解:
现在要生成一些模拟的股票数据。想象在创建一个虚拟的股票市场,这些数据包括日期、开盘价、最高价、最低价、收盘价和成交量。就像在做一顿虚拟的大餐,需要各种食材和调料。
# 设置随机种子以确保结果可重复 np.random.seed(42) # 生成99个交易日期(工作日) dates = pd.date_range(start='2023-01-01', periods=99, freq='B') # 随机生成股票价格数据 open_prices = np.random.uniform(low=100, high=200, size=len(dates)) high_prices = open_prices * np.random.uniform(low=1, high=1.1, size=len(dates)) low_prices = open_prices * np.random.uniform(low=0.9, high=1, size=len(dates)) close_prices = np.random.uniform(low=100, high=200, size=len(dates)) volumes = np.random.randint(low=1000, high=10000, size=len(dates)) # 创建数据框 stock_data = pd.DataFrame({ '日期': dates, '开盘价': open_prices, '最高价': high_prices, '最低价': low_prices, '收盘价': close_prices, '成交量': volumes }) # 将数据保存到CSV文件中 stock_data.to_csv('data.csv', index=False, encoding='utf-8-sig') print("数据已保存到data.csv文件中") 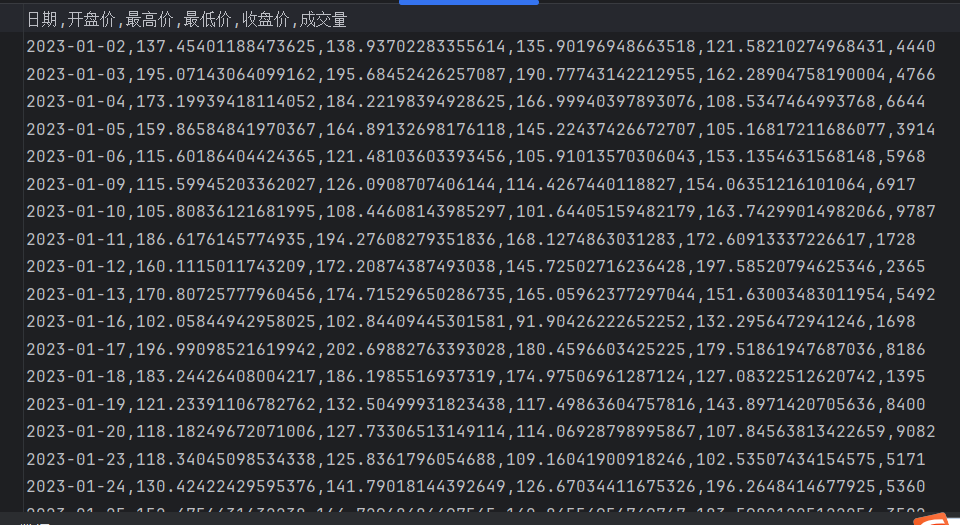
2.2 数据探索与可视化
小李的理解:
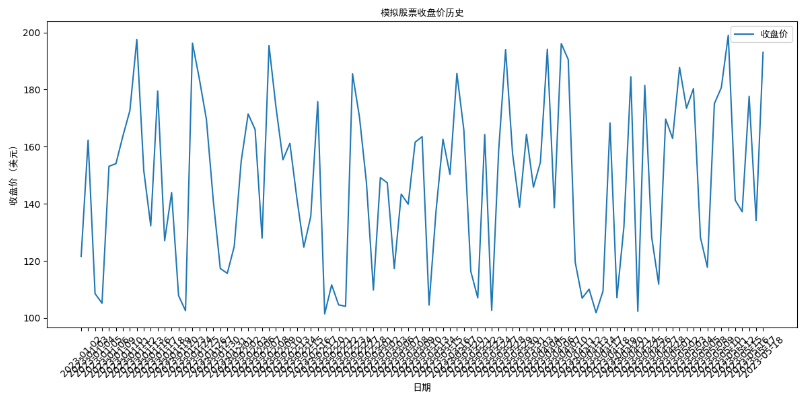
为了更好地理解我们的数据,可以绘制收盘价的时间序列图。这就像是把做好的菜摆盘后拍张照片,看看颜色和外观怎么样。
# 绘制收盘价的时间序列图 plt.figure(figsize=(12, 6)) plt.plot(stock_data['收盘价'], label='收盘价') plt.title('模拟股票收盘价历史') plt.xlabel('日期') plt.ylabel('收盘价 (美元)') plt.legend() plt.show() 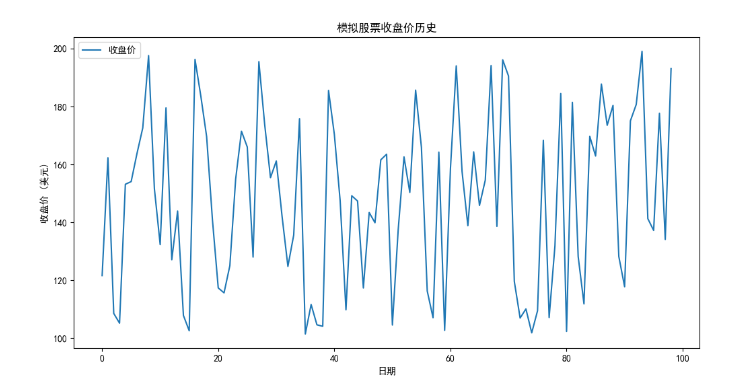
这段代码将显示模拟股票收盘价随时间变化的图表。
2.3 数据处理
小李的理解:
为了进行预测,需要创建一些特征和标签。用今天的数据来预测明天的情况。具体来说,会看看今天的收盘价,并判断明天的收盘价是否会上涨。就像是根据今天的天气预测明天是否会下雨。
# 创建新的特征和标签 stock_data['次日收盘价'] = stock_data['收盘价'].shift(-1) stock_data['价格上涨'] = (stock_data['次日收盘价'] > stock_data['收盘价']).astype(int) stock_data.dropna(inplace=True) print(stock_data.head()) 
在这段代码中:
- 创建了一个新的列
次日收盘价,表示下一天的收盘价。- 创建了标签列
价格上涨,如果第二天的收盘价高于当天,则标签为1,否则为0。- 删除了包含空值的行。
2.4 选择特征和标签
小李的理解:
选择一些关键数据作为特征,用它们来预测明天的情况。这些特征包括收盘价、开盘价、最高价、最低价和成交量。就像是选择了一些重要的天气指标(如温度、湿度、风速等)来预测明天的天气。
# 选择特征和标签 features = stock_data[['收盘价', '开盘价', '最高价', '最低价', '成交量']] labels = stock_data['价格上涨'] 在这段代码中,选择了特征列和标签列,用于后续的模型训练和评估。
第三步:拆分数据集
小李的理解:
为了评估模型,需要把数据分成两部分:一部分用来训练模型,另一部分用来测试模型的准确性。就像是用一些数据来训练一个预测模型,然后用其他数据来验证它的预测能力。
from sklearn.model_selection import train_test_split # 拆分数据集 X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
在这段代码中,将数据集的80%用作训练集,20%用作测试集。还设置了random_state参数,以确保每次运行代码时拆分方式相同。
第四步:训练决策树模型

小李的理解:
可以用训练数据来训练我们的模型了。决策树是一种机器学习算法,就像是一个聪明的机器人,它可以学习数据中的模式,并根据这些模式做出预测。
from sklearn.tree import DecisionTreeClassifier # 训练决策树模型 clf = DecisionTreeClassifier() clf.fit(X_train, y_train) 在这段代码中,首先创建了一个DecisionTreeClassifier对象,然后使用训练数据X_train和y_train来训练模型。
第五步:模型预测与评估
小李的理解:
训练完成后,可以用测试数据来评估模型的表现。让模型对测试数据做出预测,并计算预测的准确性。就像是测试一个天气预报模型,看看它预测的准确性有多高。
from sklearn.metrics import accuracy_score # 模型预测与评估 y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(f"准确率: {accuracy:.2f}") 
在这段代码中,我们使用clf.predict方法来预测测试数据的标签,然后使用accuracy_score函数来计算模型的准确性。
结果
| 日期 开盘价 最高价 最低价 收盘价 成交量 0 2023-01-02 137.454012 138.937023 135.901969 121.582103 4440 1 2023-01-03 195.071431 195.684524 190.777431 162.289048 4766 2 2023-01-04 173.199394 184.221984 166.999404 108.534746 6644 3 2023-01-05 159.865848 164.891327 145.224374 105.168172 3914 4 2023-01-06 115.601864 121.481036 105.910136 153.135463 5968 | |||||
| 日期 开盘价 最高价 ... 成交量 次日收盘价 价格上涨 0 2023-01-02 137.454012 138.937023 ... 4440 162.289048 1 1 2023-01-03 195.071431 195.684524 ... 4766 108.534746 0 2 2023-01-04 173.199394 184.221984 ... 6644 105.168172 0 3 2023-01-05 159.865848 164.891327 ... 3914 153.135463 1 4 2023-01-06 115.601864 121.481036 ... 5968 154.063512 1 | ||||||
| [5 rows x 8 columns] 准确率: 0.50 | |
完整代码
为了方便你查看和运行,以下是完整的代码:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties # 设置随机种子以确保结果可重复 np.random.seed(42) # 生成99个交易日期(工作日) dates = pd.date_range(start='2023-01-01', periods=99, freq='B') # 随机生成股票价格数据 open_prices = np.random.uniform(low=100, high=200, size=len(dates)) high_prices = open_prices * np.random.uniform(low=1, high=1.1, size=len(dates)) low_prices = open_prices * np.random.uniform(low=0.9, high=1, size=len(dates)) close_prices = np.random.uniform(low=100, high=200, size=len(dates)) volumes = np.random.randint(low=1000, high=10000, size=len(dates)) # 创建数据框 stock_data = pd.DataFrame({ '日期': dates, '开盘价': open_prices, '最高价': high_prices, '最低价': low_prices, '收盘价': close_prices, '成交量': volumes }) # 将数据保存到CSV文件中 stock_data.to_csv('data.csv', index=False, encoding='utf-8-sig') print("数据已保存到data.csv文件中") # 读取CSV文件中的数据 stock_data = pd.read_csv('data.csv') print(stock_data.head()) # 设置字体属性,确保能显示中文 font = FontProperties(fname='C:/Windows/Fonts/simhei.ttf') # 这里使用黑体,可以根据需要更改 # 绘制收盘价的时间序列图 plt.figure(figsize=(12, 6)) plt.plot(stock_data['日期'], stock_data['收盘价'], label='收盘价') plt.title('模拟股票收盘价历史', fontproperties=font) plt.xlabel('日期', fontproperties=font) plt.ylabel('收盘价 (美元)', fontproperties=font) plt.legend(prop=font) plt.xticks(rotation=45) plt.tight_layout() plt.show() # 创建新的特征和标签 stock_data['次日收盘价'] = stock_data['收盘价'].shift(-1) stock_data['价格上涨'] = (stock_data['次日收盘价'] > stock_data['收盘价']).astype(int) stock_data.dropna(inplace=True) print(stock_data.head()) # 选择特征和标签 features = stock_data[['收盘价', '开盘价', '最高价', '最低价', '成交量']] labels = stock_data['价格上涨'] # 拆分数据集 X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42) # 训练决策树模型 clf = DecisionTreeClassifier() clf.fit(X_train, y_train) # 模型预测与评估 y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(f"准确率: {accuracy:.2f}") 总结
生成随机股票数据,保存为 CSV 文件,并使用决策树进行预测和评估。
安装必要的库:
使用pip install pandas numpy scikit-learn matplotlib安装库。生成并保存随机数据:
生成 99 个交易日(工作日)的随机股票数据,包括日期、开盘价、最高价、最低价、收盘价和成交量。使用pandas将数据保存到data.csv文件中。读取并准备数据:
- 从 CSV 文件中读取数据。
- 创建新的特征(次日收盘价)和标签(价格上涨)。
数据可视化:
- 使用
matplotlib绘制收盘价的时间序列图。 - 设置字体属性以确保图表中能正确显示中文。
- 使用
拆分数据集:
将数据集拆分为训练集和测试集。训练决策树模型:
使用DecisionTreeClassifier训练模型。模型预测与评估:
使用测试集对模型进行评估,计算模型的准确性。
