
阅读量:0
前言
2013 ILSVRC 冠军
ZFNet(Zeiler & Fergus Net)是由Matthew D. Zeiler和Rob Fergus在2013年提出的卷积神经网络模型,它是基于AlexNet进行改进而来的。ZFNet在当年的ImageNet Large Scale Visual Recognition Challenge (ILSVRC)中取得了冠军,尤其在分类和定位任务上表现突出。
论文:
https://cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
csdn译文:
https://download.csdn.net/download/p731heminyang/89567205
其实zfNet相比于alexNet网络架构没有太大的改变,只是做了少量的优化而已,不过他提出的模型的可视化,用于观察和理解卷积神经网络内部的工作机制,这不仅加深了对模型行为的理解,也为模型的优化提供了指导。
ZFNet 解析
网络架构一样,只是这里通过他的 模型可视化,对齐网络结构进行了优化,具体如下:
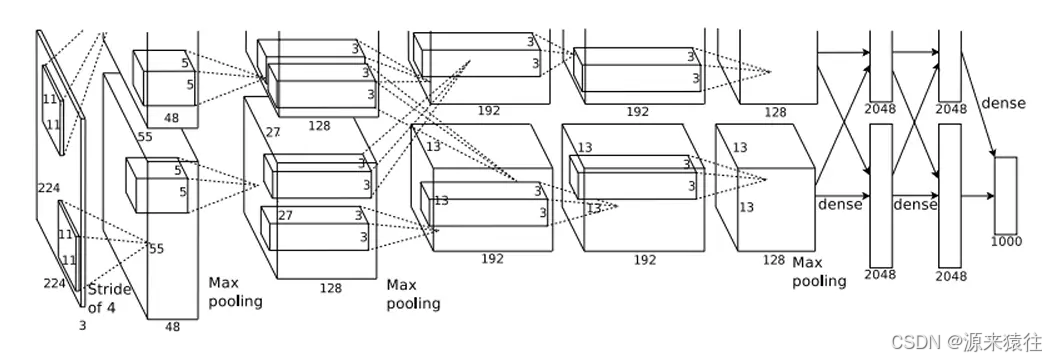
alexNet
论文里面描述修改过程:
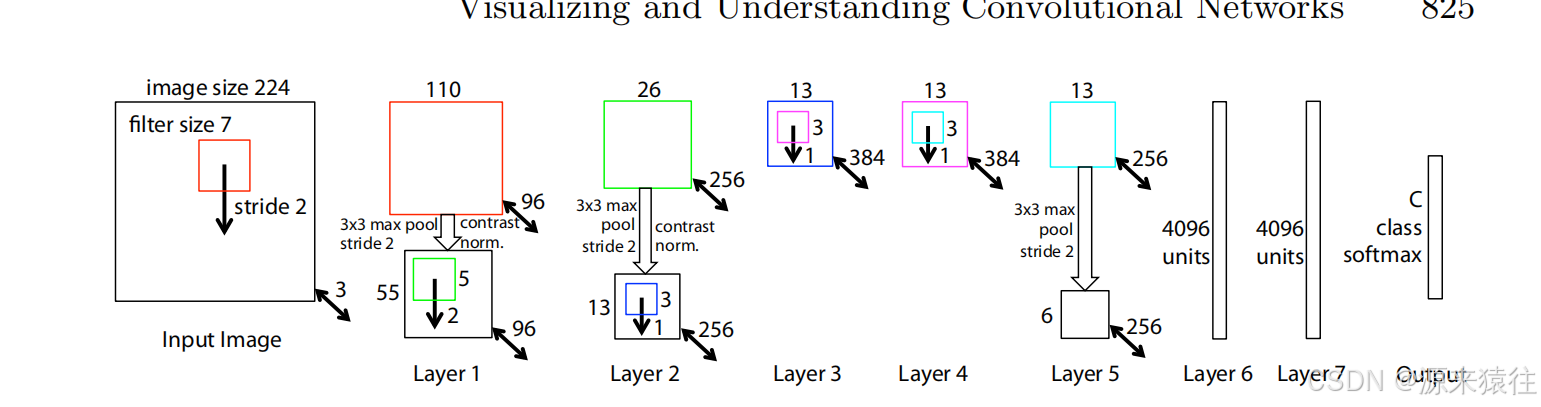
通过比对知道,修改点:
第一层卷积层:从11x11步长3 变为了7x7 步长为2
第3/4/5层卷积层: 参数个数从之前的384、384、256修改为512,1024,512
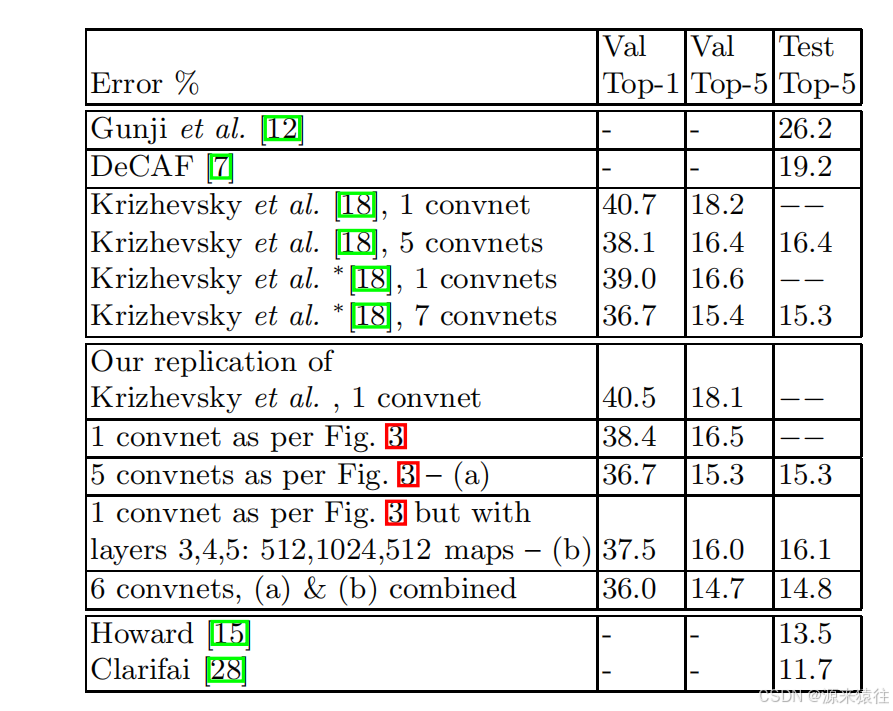
ZFNet在ImageNet数据集上的top-5错误率从AlexNet的16.4%降低到了11.7%。
网络层对比:
输入都是224x224x3
| 网络层 | AlexNet | ZFNet | |||
| 序号 | 层数 | 参数 | 输出 | 参数 | 输出 |
| 1 | C1卷积层 | 个数:96 卷积核:11x11 步长:4 激活函数:ReLU | 96x55x55 | 个数:96 卷积核:7x7 步长:2 | 96x110x110 |
| 2 | P1池化层 | 滤波器:3x3 步长:2 | 96x27x27 | 滤波器:3x3 步长:2 | 96x55x55 |
| 3 | C2卷积层 | 个数:256 卷积核:5x5 步长:1 填充:2 激活函数:ReLU | 256x27x27 | 个数:256 卷积核:5x5 步长:1 填充:0 激活函数:ReLU | 256x26x26 |
| 4 | P2池化层 | 滤波器:3x3 步长:2 | 256x13x13 | 滤波器:3x3 步长:2 | 256x13x13 |
| 5 | C3卷积层 | 个数:384 卷积核:3×3 步长:1 填充:1 激活函数:ReLU | 384x13x13 | 个数:512 卷积核:3×3 步长:1 填充:1 激活函数:ReLU | 512x13x13 |
| 6 | C4卷积层 | 个数:384 卷积核:3×3 步长:1 填充:1 激活函数:ReLU | 384x13x13 | 个数:1024 卷积核:3×3 步长:1 填充:1 激活函数:ReLU | 1024x13x13 |
| 7 | C5卷积层 | 个数:256 卷积核:3×3 步长:1 填充:1 激活函数:ReLU | 256x13x13 | 个数:512 卷积核:3×3 步长:1 填充:1 激活函数:ReLU | 512x13x13 |
| 8 | P3池化层 | 滤波器:3x3 步长:2 | 256x6x6 | 滤波器:3x3 步长:2 | 512x6x6 |
| 9 | F1全连接层 | 4096 | 4096 | 4096 | 4096 |
| 10 | D1 Dropout | 丢失率:0.5 | 4096 | 丢失率:0.5 | 4096 |
| 11 | F2全连接层 | 4096 | 4096 | 4096 | 4096 |
| 12 | D2 Dropout | 丢失率:0.5 | 4096 | 丢失率:0.5 | 4096 |
| 13 | F3全连接层 | 1000 激活参数:Softmax | 1000 | 1000 激活参数:Softmax | 1000 |
网络可视化:
这部分内容不涉及训练,只是训练之后查询训练过程中进行网络可视化。
论文里面提出了一个 反卷积网络(deconvnet),可以在卷积层后进行反卷积化,大概看了下文章,理解了下意思,就是把特征点卷积之后,然后再通过反卷积的方式映射到像素空间进行展示。
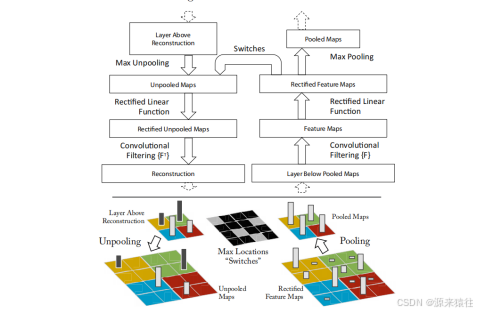
通过上图可以看出,是在池化层做出了拦截然后处理,我们的步骤为:map-》卷积-》relu-》池化,拦截后反向操作就需要:反池化-》反relu-》反卷积-》像素图片
上图左边是反卷积化,右边卷积化操作,通过中间的switch(开关)记录最大值在原始像素空间的位置(黑白图展示)。
- 反池化:最大池化操作是不可逆的,根据上述图片,就是选取的最大值隐射到像素空间的相应位置,周边位置都是填充同样的值或者填0。
- 反激活函数Relu:y=max(0,x),由于小于0的被丢掉了,那么就是不重要的特征,那么直接相当于x=y,直接选取原有数据就行。
- 反卷积:论文里面介绍了一个反卷积网络(deconvnet),使用反卷积网络可以把卷积网络隐射到像素空间进行展示,这个论文没有详细解释如何求取,只是说通过原有的卷积网络反向求出,应该也会丢失部分精度。
通过上述的技术可以可视化每层的特征值,我们看看他们这几层特征的可视化图

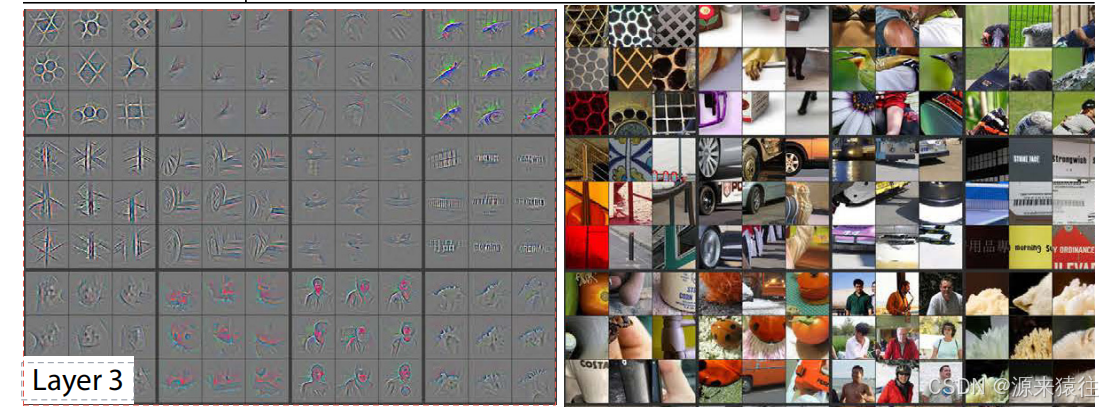
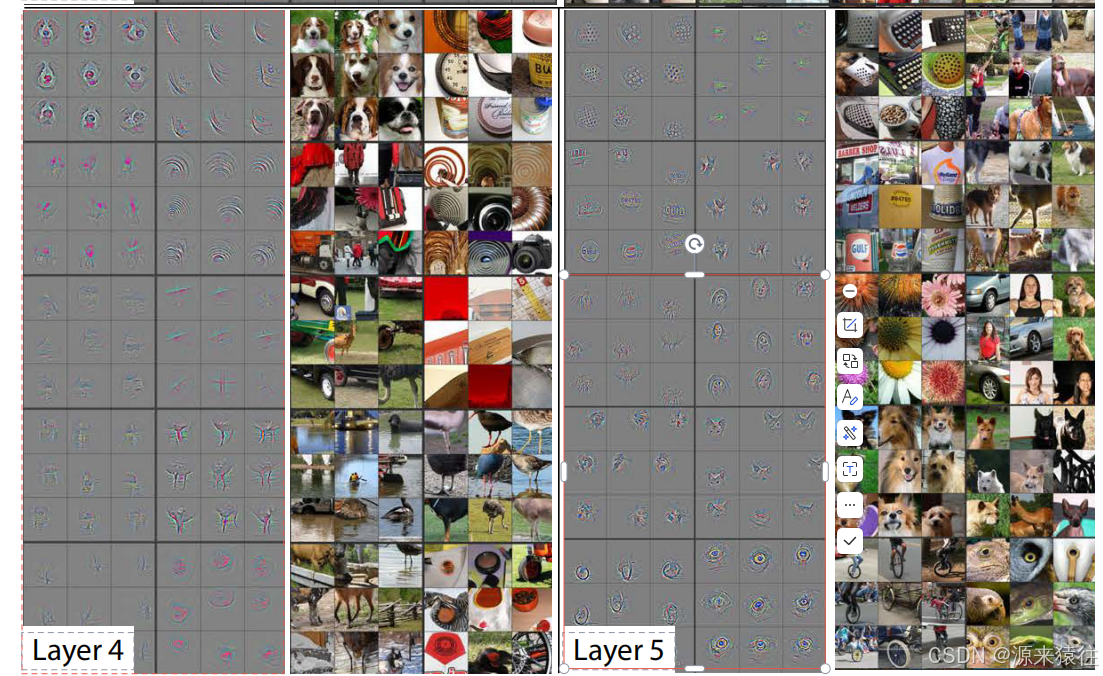
1. 第一层(Layer 1)
- 特征:主要学习图像的边缘、颜色和角点等低级特征。
- 可视化效果:通过反卷积(deconvnet)技术,可以看到每个卷积核对应的激活在原图上的位置,这些位置通常对应于图像的边缘、颜色块等。
- 特点:这一层的特征图相对简单,主要是图像的基本组成元素。
2. 第二层(Layer 2)
- 特征:开始捕捉到一些更加复杂的特征,如纹理、简单的形状等。
- 可视化效果:反卷积重构后的图像显示了更加复杂的结构,如条纹、斑点等纹理特征。
- 特点:相比第一层,这一层的特征图更加丰富,开始具备了一定的不变性。
3. 第三层(Layer 3)
- 特征:具有更强的不变性,能够捕捉到一些复杂的纹理和形状特征。
- 可视化效果:反卷积重构的图像显示了更加精细的纹理和形状,如网格、纹理图案等。
- 特点:这一层的特征图开始显示出类别的基本差异,但尚未形成具体的物体轮廓。
4. 第四层(Layer 4)
- 特征:开始关注到具有类别区分性的特征,如动物的脸部、四肢等。
- 可视化效果:反卷积重构的图像中,可以清晰地看到某些类别的关键特征,如狗的脸部、鸟的翅膀等。
- 特点:这一层的特征图已经能够很好地表示不同类别之间的差异。
5. 第五层(Layer 5)
- 特征:关注到整体的目标对象,开始形成完整的物体轮廓。
- 可视化效果:反卷积重构的图像中,可以看到完整的物体形状,如狗的整体轮廓、汽车的形状等。
- 特点:这一层的特征图已经具备了很强的类别区分能力,能够很好地表示整个目标对象。
从上述可以看出来特征从简单的边缘、颜色到复杂的纹理、形状,再到完整的物体轮廓,浅层通常负责提取图像的低级特征,如边缘、角点和纹理等,而深层则负责提取更高级别的抽象特征,如物体的部分、整体形状和类别(越高层可以表达的越抽象,比如一张图表达各种复杂的意思和逻辑啥的,所以我们现在的大模型动不动就是上百亿的参数,层级也比较深,表达的内容各种各样),此论文让我们深入理解卷积网络工作原理作出了重大贡献。
结论:
论文提出了网络可视化、遮挡测试、图片平移、缩放翻转旋转测试,得出的结论,如下:
- 特征可视化:浅层提取的颜色纹理部件等(比较容易发生变化),越高层提取结构、语义信息(越稳定不容易发生变化)。如:浅层的换种颜色 或者换个皮肤就会随之发生变化,高层的形状你换表面很难改变除非遮挡特征去影响变化,通过可视化可以理解卷积网络是如何进行学习特征的;通过特征可视化可以判断修改网络参数对特征的影响,从而改进网络结构提升性能和准确性(如把第一层从11x11变为7x7就是通过可视化判断出来特征丢失过多,减小卷积核会获取更多的有效数据,但是相应的性能也会下降,找平衡)
- 特征不变性:样本在一定范围内缩放、平移不影响特征,但是旋转会影响特征的改变。
- 迁移学习:使用训练的特征模型参数及部分结构迁移到新的数据集或者任务上面,这样可以达到快速收敛和减少训练时间,还可以冻结一部分的参数进行微调。
- 特征消融:通过遮挡测试来发现哪些特征对于网络识别特征重要(就是遮挡了重要特征之后,要不识别率低,要不就是识别不出来)。
