阅读量:0
Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
摘要: 我们提出了一种基于立体视觉的方法,用于在动态自动驾驶场景中跟踪相机自我运动和 3D 语义对象。我们建议使用易于标记的 2D 检测和离散视点分类以及轻量级语义推理方法来获得粗略的 3D 对象测量,而不是使用端到端方法直接回归 3D 边界框。基于在动态环境中具有鲁棒性的对象感知辅助相机姿态跟踪,结合我们新颖的动态对象束调整(BA)方法来融合时间稀疏特征关联和语义3D测量模型,我们获得了3D对象姿态,具有实例精度和时间一致性的速度和锚定动态点云估计。我们提出的方法的性能在不同的场景中得到了证明。自我运动估计和对象定位都与最先进的解决方案进行了比较。
引言:
主要贡献:
- 一种仅使用 2D 对象检测和所提出的视点分类的轻量级 3D 框推理方法,为对象特征提取提供对象重投影轮廓和遮挡掩模。也作为后续优化的语义度量模型。
- 一种新颖的动态对象束调整方法,它将语义和特征测量紧密结合起来,以持续跟踪具有实例准确性和时间一致性的对象状态。
方法
语义跟踪系统主要由三个模块组成
1)执行 2D 对象检测和视点分类,利用这两个输出并借助2D检测框的边与3D检测框上的点之间的约束粗略的推断物体的位姿。
2)特征提取和匹配。它将所有推断的 3D 框投影到 2D 图像,以获得对象轮廓和遮挡蒙版。然后应用引导特征匹配来获得立体图像和时间图像的鲁棒特征关联。
3)所有的语义测量和特征测量被紧耦合到一个优化方法中,用于相机和物体位姿的求解。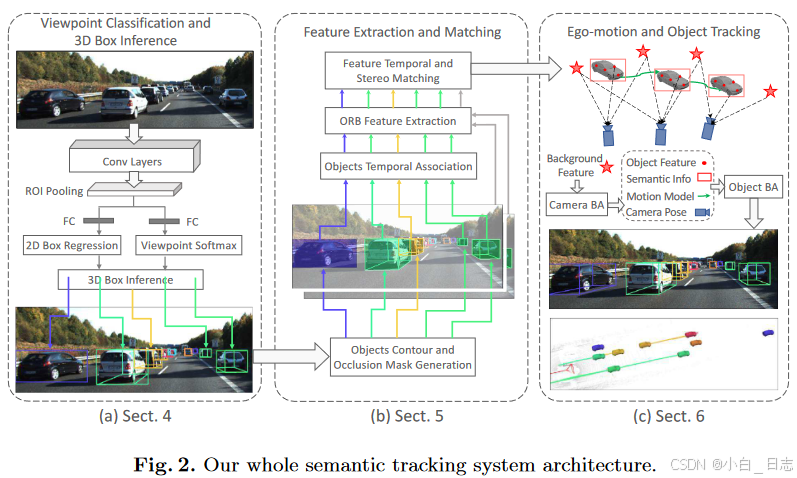
视点分类和 3D 框推理
视点分类:使用Fast-RCNN机型2d物体检测,在最后的FC层添加子类别分类,而不是原始视线中的纯对象分类,它表示对象水平和垂直离散视点。
对于水平和垂直观测点的解释:其实就是16个类别的区分过程,作者认为水平方向连续的8个观测位置和垂直方向的两个位置的16种组合足以包括目标在相机中的状态。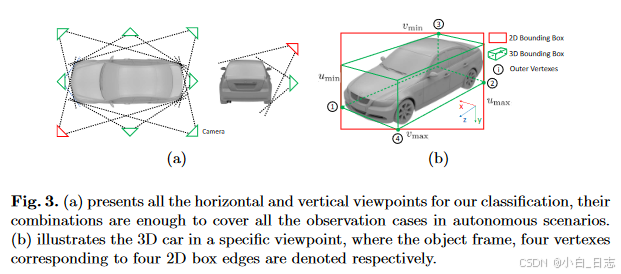
通过水平和垂直视点分类的总共16种组合,可以基于3D边界框的重投影将紧密贴合2D边界框的假设,生成2D框中的边缘与3D框中的顶点之间的关联。
基于视点的3D box推理:给定了归一化平面上的2D检测框 [umin, vmin, umax, vmax]和观测点,基于2D 框边缘和 3D 框顶点之间的四个约束来推断物体姿态。物体的3D检测框中心点位置 p = [ p x , p y , p z ] T p = [p_x, p_y, p_z]^T p=[px,py,pz]T,物体相对于相机的水平方向 θ,物体的先验尺寸 d = [ d x , d y , d z ] T d = [d_x, d_y, d_z]^T d=[dx,dy,dz]T。其中,前两个变量 p, θ 用于表示物体的4自由度位姿。为了推断物体的3D检测框或者说物体的位姿,我们可以在图2(b)中得到4个约束关系,即3D检测框的四个点被投影到2D检测框边界上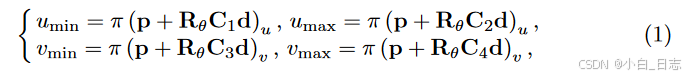
π是从相机坐标系到归一化平面的投影矩阵, R θ R_θ Rθ表示从物体坐标系转化到相机坐标系,由θ参数化的旋转。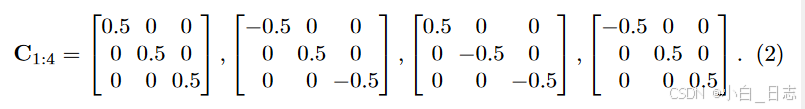
C1:4表示对角选择矩阵描述3D检测框中心点和与2D检测框边界相交的4个点①②③④之间的位置关系。当全卷积层输出了观测点,我们也就得到了对应的C1:4。例如上面给出的C1:4即为图2(b)中观测点下对应的选择矩阵。公式(1)中,第一个解释为以中心点为起点,向xyz三个方向的正方向各增加对应维度先验尺寸的一半得到点①,第二个解释为以中心点为起点,向x, z的反方向增加先验尺寸dx, dz的一半,向y的正方向增加先验尺寸dy的一半得到点②,这其中包含着由Rθ决定的从物体坐标系向相机坐标系的转换,再将点①②从相机坐标系转化到归一化平面正好和2D检测框边界相交,其余两个同理。这样,我们就得到了公式(1),用这四个等式就可以求解物体的4自由度位姿,同时也得到了3D检测框。
通过这四个方程,可以在给定先验尺寸的情况下直观地求解 4 DoF 物体位姿。我们将复杂的 3D 对象检测问题转换为 2D 检测、视点分类和简单的封闭式计算。诚然,解决的姿势是一个近似估计,它以 2D 边界框的实例“紧密度”和先验的对象尺寸为条件。另外,对于某些顶视图情况,3D 框的重投影并不严格适合 2D 框,这可以从图 3(b)中的顶部边缘观察到。然而,对于自动驾驶场景中几乎水平或轻微俯视的视点,这个假设可以合理地成立。请注意,我们的实例姿态推断仅用于生成用于特征提取的对象投影轮廓和遮挡掩模,并作为后续最大后验(MAP)估计的初始值,其中 3D 对象轨迹将通过基于滑动窗口的特征相关性和对象点云对齐来进一步优化。
特征提取和匹配:
我们将推断的 3D 对象框投影到立体图像以生成有效的 2D 轮廓。如图 2 (b) 所示,使用不同颜色的蒙版来表示每个对象的可见部分(灰色为背景)。对于遮挡对象,我们根据对象 2D 重叠和 3D 深度关系将被遮挡部分屏蔽为不可见。因此,对于具有少于四个有效边缘测量值的截断对象,无法通过第 4.2 节中的方法进行推断。我们直接将左图中检测到的2D框投影到右图中。我们为每个对象和背景的可见区域中的左图像和右图像提取 ORB 特征。立体匹配是通过极线搜索来执行的。物体特征的深度范围是从推断的物体姿态中得知的,因此我们将搜索区域限制在一个小范围内以实现鲁棒的特征匹配。对于时间匹配,我们首先通过 2D 框相似性得分投票来关联连续帧的对象。相似度得分是通过补偿相机旋转后连续图像之间的 2D 框的中心距离和形状相似度来加权的。
如果该对象与前一帧中所有对象的最大相似度得分小于阈值,则该对象被视为丢失。我们注意到,有更复杂的关联方案,例如概率数据关联,但它更适合避免重新访问静态对象场景时的硬决策,而不是自动驾驶的高度动态和非重复场景。随后,我们将相关对象和背景的 ORB 特征与前一帧进行匹配。 RANSAC 通过对每个对象和背景独立进行局部基本矩阵测试来拒绝异常值。
自我运动和物体跟踪: 具体详细部分可参考原文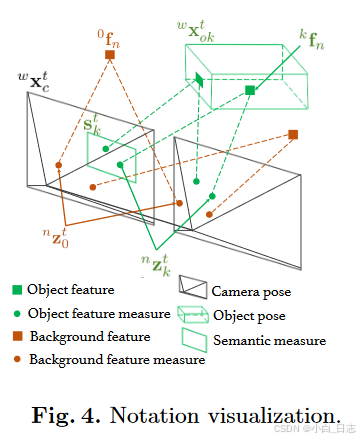
在一个通常的自动驾驶场景中,我们的目标有三个:
(1) 连续估计相机的运动
(2) 连续追踪3D物体的位置
(3) 恢复动态稀疏特征点的3D位置
在这里,k表示物体序号,k=0表示背景;n表示第k个物体上的特征点序号;t表示时间或者帧的序号。
首先针对目标(1),利用背景特征点的重投影误差来构建优化的最小二乘。由于没有先验信息可以利用,我们直接计算目标函数的最大似然,并假设观测模型服从高斯分布,将最大似然问题转化为马氏距离的BA问题。在这里,我们要求解的是相机的位姿和背景特征点的位置。
自我运动追踪:给定静态背景特征观察,自我运动可以通过最大似然估计(MLE)来解决: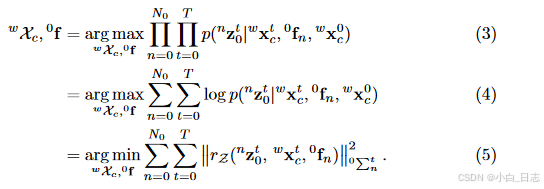 语义对象跟踪:在我们求解出相机位姿之后,可以根据先验维度和实例语义测量来求解每个时间 t 的对象状态。我们假设该对象是一个刚体,这意味着锚定到它的特征相对于对象框架是固定的。因此,如果我们有连续的对象特征观察,则对象的时间状态是相关的。给定相机姿态,不同对象的状态是有条件独立的,因此我们可以并行且独立地跟踪所有对象。对于第 k 个对象,我们有每个类标签的维度先验分布 p(dk)。我们假设每个对象每次的检测结果和特征测量都是独立的并且呈高斯分布。根据贝叶斯规则,我们有以下最大后验(MAP)估计:
语义对象跟踪:在我们求解出相机位姿之后,可以根据先验维度和实例语义测量来求解每个时间 t 的对象状态。我们假设该对象是一个刚体,这意味着锚定到它的特征相对于对象框架是固定的。因此,如果我们有连续的对象特征观察,则对象的时间状态是相关的。给定相机姿态,不同对象的状态是有条件独立的,因此我们可以并行且独立地跟踪所有对象。对于第 k 个对象,我们有每个类标签的维度先验分布 p(dk)。我们假设每个对象每次的检测结果和特征测量都是独立的并且呈高斯分布。根据贝叶斯规则,我们有以下最大后验(MAP)估计: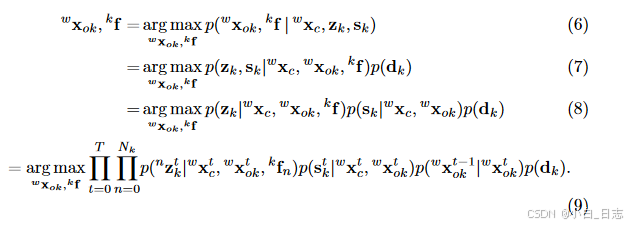
类似于等式3,我们将MAP转化为非线性优化问题: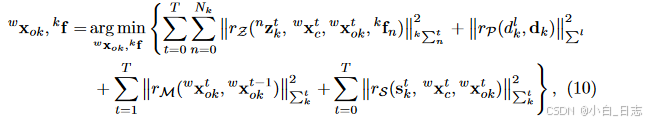
稀疏特征观察:我们将静态特征和相机姿态之间的射影几何扩展到动态特征和物体姿态。基于相对于对象框架的锚定相对静态特征,共享特征观察的对象姿势可以通过因子图连接。对于每个特征观测,残差可以由预测特征位置和左右图像上的实际特征观测的重投影误差来表示: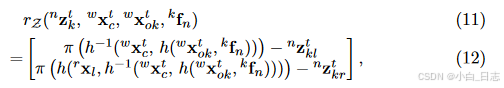
语义 3D 对象测量:受益于视点分类,我们可以知道 2D 边界框的边和 3D 边界框的顶点之间的关系。假设 2D 边界框紧密贴合到对象边界,则每条边都与重新投影的 3D 顶点相交。这些关系可以被确定为每个 2D 边缘的四个选择矩阵。语义残差可以通过预测的 3D 框顶点与检测到的 2D 框边缘的重投影误差来表示: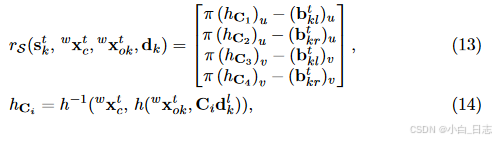
车辆运动模型:过该运动模型能够从t-1时刻车的状态推断k时刻车的状态,还能连续追踪车的速度和方向。该项误差定义为通过运动模型预测的t时刻状态减去估计的t时刻状态: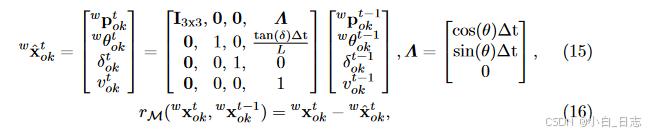
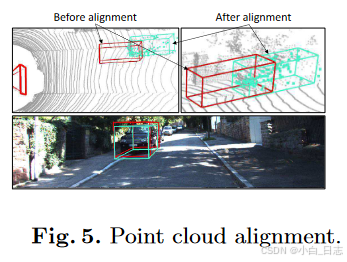
点云对齐在最小化所有残差后,我们根据先验维度获得物体位姿的MAP估计。然而,由于物体大小差异,姿势估计可能会出现偏差(见图 5)。因此,我们将 3D 框与恢复的点云对齐,由于精确的立体外部校准,这是无偏差的。我们最小化所有 3D 点与其锚定 3D 框表面的距离: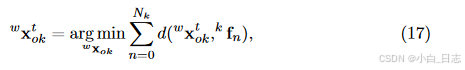
实验
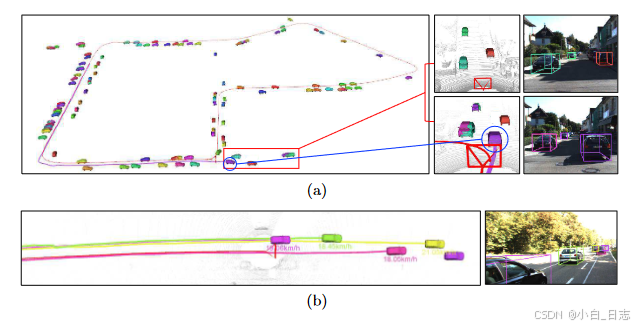
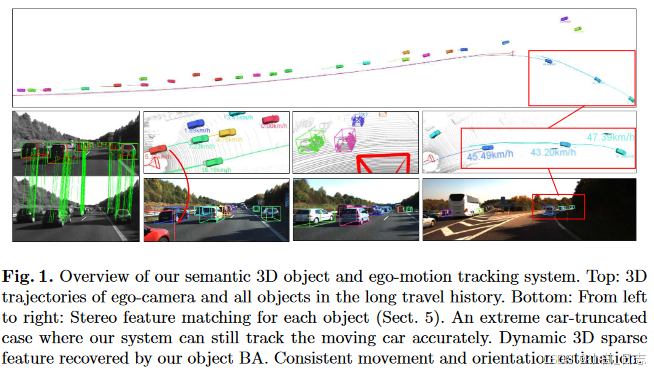
长轨迹的连续跟踪结果。 (a) 显示了大约 700 m 的闭环轨迹,包括静态汽车和动态汽车。右上和右下分别是放大的开始视图和结束视图。蓝色圆圈内的汽车被跟踪超过200米,其轨迹可以在左上视图中找到。 (b) 显示了一个主要包含动态和截断汽车的场景。估计的轨迹、速度和重新投影的二维图像分别显示在左侧和右侧。请注意,LiDAR 点云仅供所有俯视图中参考。后续的非线性优化是与数据无关的。因此,我们的系统能够在不同的数据集上执行一致的结果。定量评估表明,我们的语义 3D 对象和自我运动跟踪系统比孤立的最先进解决方案具有更好的性能。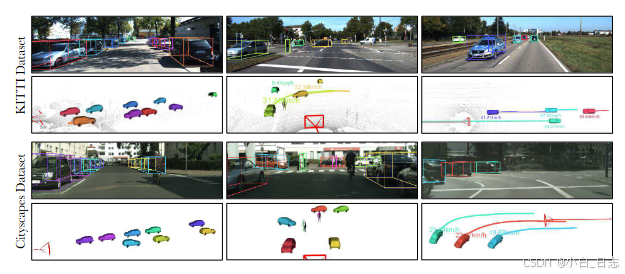
不同场景的定性示例。从左到右:车辆集中。包括汽车和行人的十字路口(请注意,我们不解决行人的方向问题),动态汽车。顶部两行是 KITTI 数据集上的结果,底部两行显示 Cityscapes 数据集上的结果。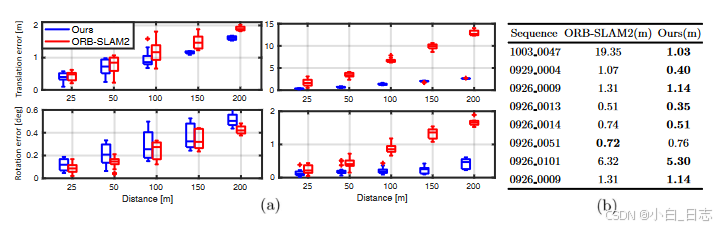
(a) RPE比较。左、右分别是来自 KITTI 原始数据集的 0929 0004 和 1003 0047 序列的结果。 (b) 十个长 KITTI 原始序列的 ATE 比较的 RMSE。
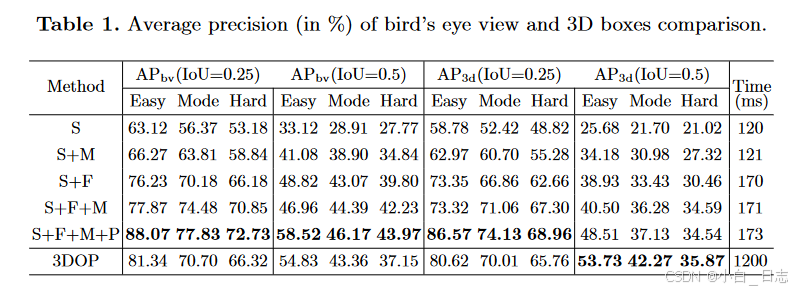
鸟瞰图和 3D 框比较的平均精度。