
阅读量:0
- 入门基础
- 简介
Elasticsearch是一个基于Lucene的搜索和分析引擎,它提供了一个分布式、多租户能力的全文搜索引擎,具有HTTP Web界面和无模式JSON文档。
- 使用场景
- 什么是全文检索
全文检索 是一种信息检索技术,它允许用户通过输入查询关键词来搜索存储在计算机中的文本数据,并返回包含这些关键词的文档或文本片段。全文检索与传统的基于关键词或元数据的检索不同,它能够对文档的内容进行深度分析,并基于文档中的词项、短语、句子等进行检索。
全文检索的核心是倒排索引(Inverted Index)。在倒排索引中,每个词项(term)都与一个包含该词项的文档列表相关联。这些文档列表通常包含词项在文档中的位置信息,以及文档的一些其他元数据(如文档ID、分数等)。当用户输入查询时,全文检索系统会在倒排索引中查找与查询词项相关的文档列表,并根据一定的排序算法(如基于词频、文档频率、逆文档频率等)对这些文档进行排序,最终返回给用户。
全文检索系统通常包括以下几个组成部分:
- 文档预处理:将原始文档转换为适合全文检索的格式,并进行必要的清洗、分词、去除停用词等处理。
- 索引构建:根据预处理后的文档构建倒排索引,以便快速响应用户的查询请求。
- 查询处理:接收用户的查询请求,对查询进行分词、去除停用词等处理,并在倒排索引中查找与查询相关的文档。
- 结果排序:根据一定的排序算法对检索到的文档进行排序,以便将最相关的文档优先返回给用户。
- 结果展示:将排序后的文档以用户友好的方式展示给用户,如列表、摘要、高亮等。
全文检索技术广泛应用于搜索引擎、企业内部文档管理、数字图书馆等领域,帮助用户快速找到他们需要的信息。
- 什么是倒排索引
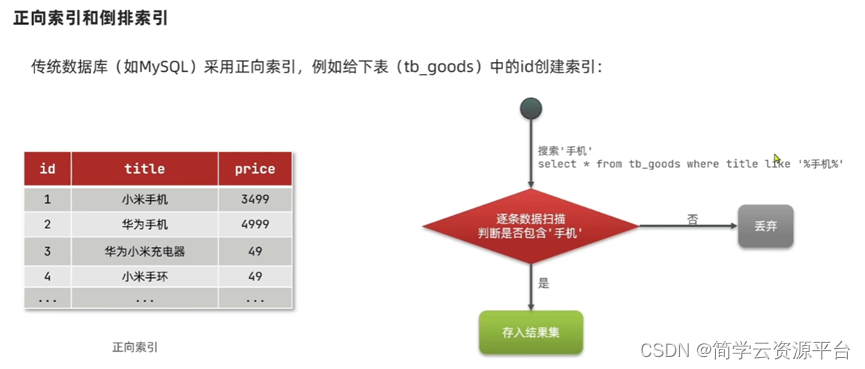
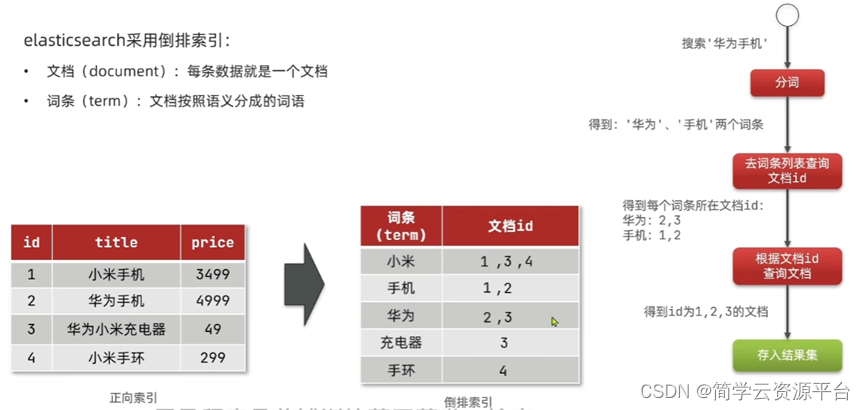
- ES的核心概念
- 节点(Node):一个运行中的Elasticsearch实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name配置的节点组成,它们共同承担数据和负载的压力。ES集群中的节点有三种不同的类型,包括主节点、数据节点等。
- 索引(Index):索引就是一个拥有几分相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。例如,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
- 分片(Shard):一个索引中的数据保存在多个分片中,相当于水平分表。这样设计使得索引可以存储超出单个节点硬件限制的大量数据。
- 映射(Mapping):mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。
- 类型(Type):在早期的Elasticsearch版本中,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。但需要注意的是,从Elasticsearch 7.x版本开始,类型(Type)的概念已经被弃用,每个索引只能包含一种类型的文档。
- ES和Mysql数据库对比
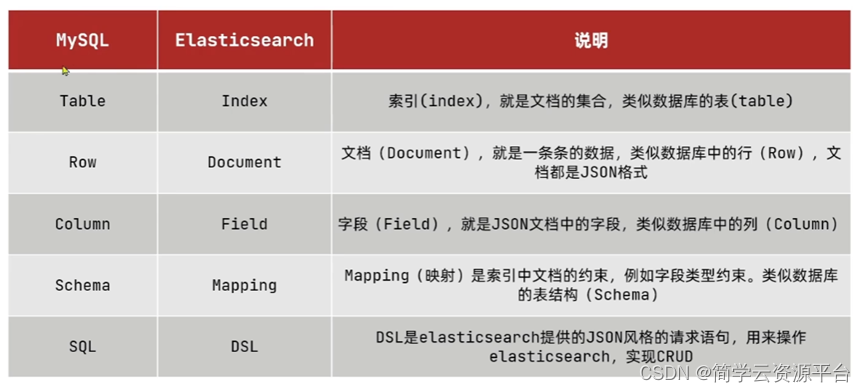
- ES分词器
- 分词器的选择
- ES分词器
- Standard Analyzer:默认分词器,按词进行切分,进行小写处理,但对停用词(如“the”、“a”、“is”等)不做处理。
- Simple Analyzer:简单分词器,按照非字母进行切分,非字母字符将被过滤,同样进行小写处理。
- Stop Analyzer:除了进行小写处理外,还会过滤掉停用词。
- Whitespace Analyzer:按照空格进行切分,不做大小写处理。
- Keyword Analyzer:不分词,直接将输入当作输出。
对于中文分词,由于ES默认将每个中文字符当作一个词来处理,这可能导致分词效果不理想。因此,你可能需要选择专门的中文分词器。以下是一些常用的中文分词器:
- IK Analyzer:支持中英文单词的切分,可自定义词库,支持热更新分词词典。IK分词器有两种分词模式:ik_max_word(最细粒度的查询,分出的词条最多)和ik_smart(最粗粒度的查询,大体切分一下,分出的词条比较少)。
- Ansj:基于n-Gram+CRF+HMM的中文分词的Java实现,免费开源,支持应用自然语言处理。
- HanLP:同样是免费开源的中文分词器,基于自然语言处理,分词准确度高。
在选择中文分词器时,你可以考虑以下因素:
- 分词准确性:这是选择分词器时最重要的因素之一。你可以通过比较不同分词器的分词结果来选择最准确的分词器。
- 活跃度:选择活跃度高、持续更新的分词器可以确保你能够获得最新的功能和性能优化。
- 自定义性:如果你需要自定义词库或调整分词策略,那么选择一个支持这些功能的分词器会更有帮助。
- 学习成本和使用教程:选择一个学习成本低、使用教程多的分词器可以更快地掌握使用方法。
- 分词器的底层实现原理
- 基于规则的分词:
- 字典匹配法:这是最简单也是最常用的分词方法。分词器会预先构建一个词典,然后将待分词的文本与词典中的词进行匹配。匹配成功则识别出一个词,然后继续进行下一个词的匹配。
- 最大匹配法:从待分词的文本中取出一个字符串,如果该字符串在词典中存在,则将其作为一个词切分出来;如果词典中不存在,则去掉该字符串的最后一个字符,再进行匹配,直到匹配成功或字符串长度减少到1为止。
- 最小匹配法:与最大匹配法相反,从待分词的文本中取出一个较短的字符串进行匹配,然后逐渐增加字符串长度,直到无法匹配为止。
- 基于统计的分词:
- 隐马尔可夫模型(HMM):HMM是一种统计模型,用于描述一个系统隐藏状态的转移概率和隐藏状态到输出状态的转移概率。在分词中,可以将每个字或词看作是一个状态,通过训练模型得到状态转移概率和输出概率,然后利用这些概率进行分词。
- 条件随机场(CRF):CRF是一种判别式概率无向图模型,可以用于序列标注问题。在分词中,可以将每个字或词看作是一个标注,通过训练模型得到标注序列的概率分布,然后利用这个分布进行分词。
- 基于深度学习的分词:
- 随着深度学习技术的发展,越来越多的分词器开始采用深度学习模型。这些模型通常使用大量的标注数据进行训练,通过神经网络自动学习文本中的特征和规律,从而进行分词。
- 常见的深度学习模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)和Transformer等。这些模型可以处理更复杂的文本结构和语义关系,提高分词的准确性和效率。
的
- Mapping的详解

- ES常用的操作
- 创建索引:
- 使用PUT命令来创建索引,例如:PUT /my_index。这将创建一个名为“my_index”的索引。索引定义了数据的结构和属性。
- 添加文档:
- 使用PUT命令将数据作为文档添加到索引中,例如:PUT /my_index/_doc/1 { "name": "John", "age": 30, "gender": "male" }。这将在“my_index”索引中添加一个名为“1”的文档,其中包含名字、年龄和性别属性。
- 查询文档:
- 使用GET命令从Elasticsearch中检索数据,例如:GET /my_index/_doc/1。这将检索名为“1”的文档。Elasticsearch还支持各种复杂的查询语句,如Match查询、Term查询等,以满足不同的搜索需求。
- 更新文档:
- 使用POST或PUT命令修改已有数据。具体命令取决于文档是否已经存在以及是否需要完全替换文档。
- 删除文档:
- 使用DELETE命令从Elasticsearch中删除数据,例如:DELETE /my_index/_doc/1。这将删除名为“1”的文档。
- 删除所有数据:
- 如果需要删除索引中的所有数据,可以使用DELETE命令配合通配符或_all参数,例如:curl -XDELETE 'http://localhost:9200/my_index/_all'(注意,这个命令在不同的Elasticsearch版本中可能有所不同,而且通常不建议在生产环境中使用,因为它会删除整个索引)。
- 使用_cat命令:
- _cat命令是Elasticsearch提供的用于获取集群状态、节点信息、索引状态等信息的命令行接口。例如,curl 'localhost:9200/_cat/nodes?v' 可以显示集群中所有节点的详细信息。
- 配置和管理:
- 除了基本的CRUD操作外,Elasticsearch还支持丰富的配置和管理命令,如设置索引映射、优化索引、监控集群状态等。这些命令通常通过RESTful API进行调用,并可以使用curl或其他HTTP客户端工具来执行。
