
阅读量:0
为了解决特定问题而进行的学习是提高效率的最佳途径。这种方法能够使我们专注于最相关的知识和技能,从而更快地掌握解决问题所需的能力。
目录
支持向量机算法介绍
支持向量机(Support Vector Machine, SVM)是一种监督学习算法,主要用于分类和回归问题。它是一种非常强大的模型,因其在高维空间中进行线性和非线性分类的能力而受到广泛欢迎。以下是SVM的一些基本概念和特点:
线性可分性:SVM最初设计用于解决线性可分问题,即数据点可以通过一个超平面清晰地分开成不同的类别。
最大间隔:SVM试图找到一个超平面,使得它与最近的数据点(支持向量)之间的距离最大化。这个距离被称为间隔(margin),最大化间隔可以提高模型的泛化能力。
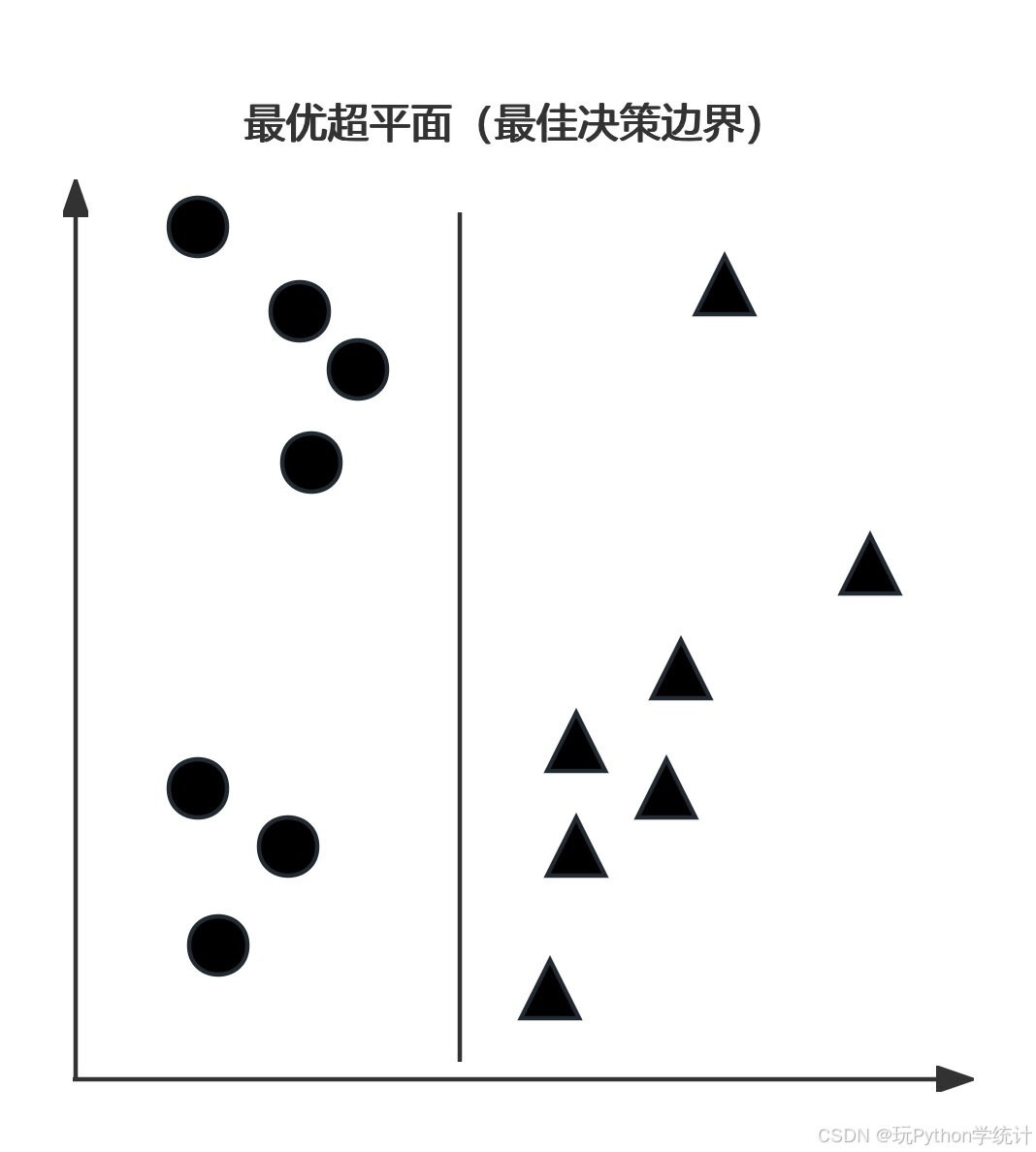
核技巧:SVM通过核函数将数据映射到更高维的空间,以解决非线性问题。常用的核函数包括线性核、多项式核、径向基函数(RBF)核等。
优化问题:SVM的训练过程可以看作是一个凸优化问题,目标是找到最大化间隔的同时最小化分类误差的解。这保证了找到的解是全局最优解。
软间隔和正则化:在实际应用中,数据可能不是完全线性可分的。SVM通过引入软间隔和正则化参数(如C)来允许一定量的误差,以避免过拟合。
多类分类:SVM最初是为二分类问题设计的,但可以通过多种策略扩展到多类分类问题,如一对一(OvR)、一对余(OvO)等。
回归问题:SVM也可以用于回归问题,称为支持向量回归(SVR),它尝试找到一条曲线,使得实际值和预测值之间的误差在一定阈值内。
模型评估:SVM模型的性能通常通过准确率、召回率、F1分数等指标来评估。
SVM是一种非常灵活且强大的算法,适用于许多不同的问题,但它也有一些局限性,比如对核函数和正则化参数的选择敏感,以及在处理大规模数据集时可能需要较长的训练时间。
练习题
对已标注出垃圾邮件和正常邮件的csv文件实现支持向量机算法分类。
Python代码与分析
前6步骤和我们在朴素贝叶斯分类算法介绍的过程一样,主要是数据处理部分。为了分析的完整性,我们将前6步骤再展示一遍。
1、加载必要的Python库。
此时要导入的是sklearn.svm库中的SVC类。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.svm import SVC # 导入支持向量机的类 from sklearn import metrics from sklearn.metrics import classification_report, confusion_matrix import matplotlib.pyplot as plt2、读取csv文件,把csv文件读入到一个pandas的DataFrame对象里。
然后对数据里面的NULL值,用空字符串(即'')代替。
df1 = pd.read_csv('spamham.csv') df = df1.where(pd.notnull(df1)) df.head() # 查看数据前5行3、对Category列进行变换,将取值ham和spam分别改成1或者0,以便进行后续机器学习的训练。
df.loc[df['Category'] == 'ham', 'Category'] = 1 df.loc[df['Category'] == 'spam', 'Category'] = 0 df.head()4、把Message列作为x,Category列作为y。
df_x = df['Message'] df_y = df['Category']5、划分数据集,80%用于训练模型,20%用于测试模型。
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, test_size = 0.2)6、把Message数据列(x列)转换成机器学习的特征值(关键步骤)。
在这里采用文本的TF-IDF特征。TF表示单个文档里的某个词项的频率,IDF表示整个文集中词项的逆文档频率。IDF把在很多文档中都出现的但对于文档的类别划分没有太多贡献的词项的重要性降低。
tfvec = TfidfVectorizer(min_df = 1, stop_words = 'english', lowercase = True) x_trainFeat = tfvec.fit_transform(x_train) x_testFeat = tfvec.transform(x_test)7、创建支持向量机分类模型,对其进行训练,并且利用模型对测试集进行预测。
在此之前,把训练集中的y转换成整数形式。
y_trainSvm = y_train.astype('int') classifierModel = SVC(kernel='linear', probability=True) classifierModel.fit(x_trainFeat, y_trainSvm) y_pred = classifierModel.predict(x_testFeat)8、把测试集的y转换成整数形式,对上述模型的预测值进行比较,显示分类器混淆矩阵和分类报告。
y_test = y_test.astype('int') print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred))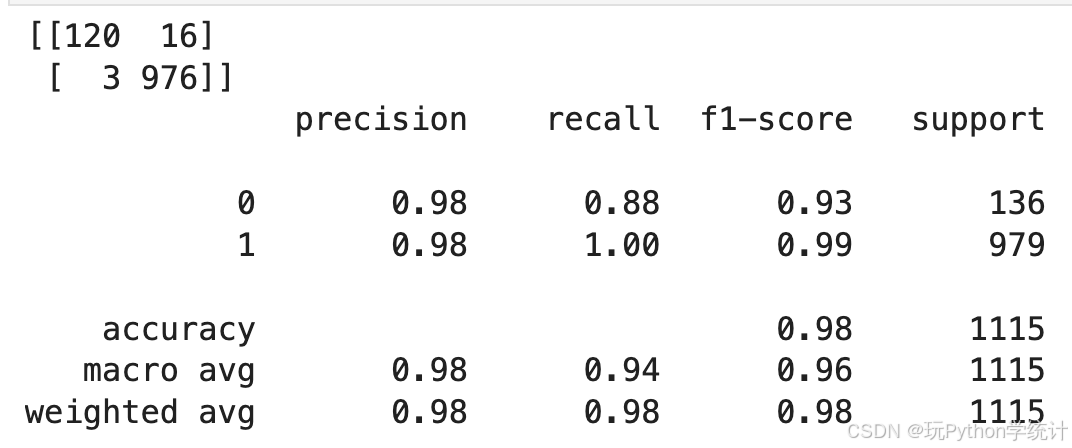
从以上混淆矩阵和分类报告中可以看出,该模型在类别0(垃圾邮件)和类别1(正常邮件)上的预测表现非常好,具有较高的精确度、召回率和F1分数。
总体而言,模型的准确度为98%,表明其在大多数情况下能够正确分类样本。
9、绘制ROC曲线
y_pred_prob = classifierModel.predict_proba(x_testFeat) fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred_prob[:,1]) auc = metrics.auc(fpr, tpr) print(auc)auc = 0.9897103887520279
plt.rcParams['font.sans-serif'] = ['Heiti TC'] plt.rcParams['axes.unicode_minus'] = False plt.plot(fpr, tpr, lw = 2, label = 'ROC曲线(面积 = {:.2f})'.format(auc)) plt.plot([0,1],[0,1],'r--') plt.xlabel('假正例率') # False Positive Rate plt.ylabel('真正例率') # True Positive Rate plt.title('ROC曲线示例') # Receiver operating characteristic example plt.legend(loc = 'lower right') plt.show()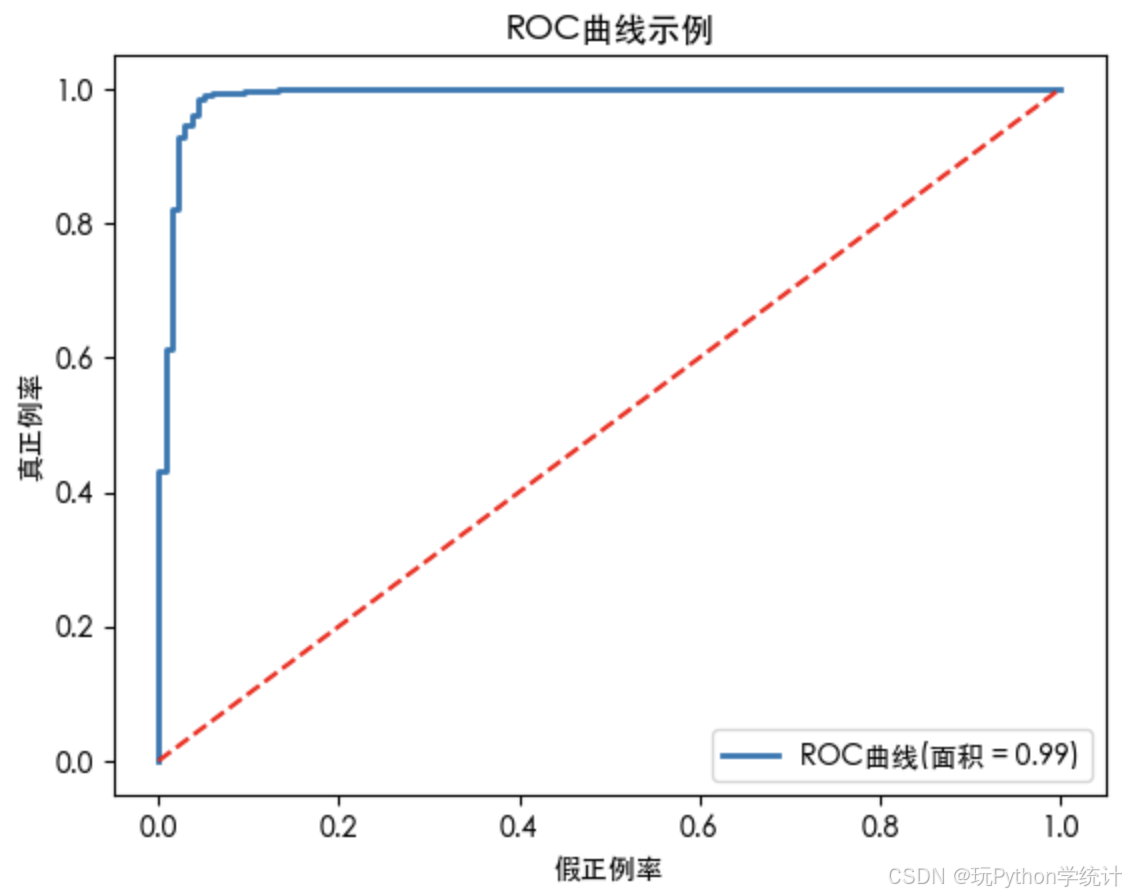
图片中的ROC曲线示例展示了一个具有较高AUC值的分类器的性能,表明该模型在区分正负类方面表现良好。
支持向量机和朴素贝叶斯的联系
监督学习:SVM和朴素贝叶斯都是监督学习算法,需要有标签的数据集进行训练。
分类问题:两者都可以用于分类问题,尽管它们的工作原理和适用场景不同。
模型评估:无论是SVM还是朴素贝叶斯,都可以使用相同的评估指标(如准确率、召回率、F1分数)来评价模型性能。
模型选择:在实际应用中,根据问题的特性和数据集的特点,可能会选择SVM或朴素贝叶斯,或者将它们与其他算法结合使用。
算法优化:两者都有对应的优化技术,如SVM的核函数选择和朴素贝叶斯的特征选择。
在选择算法时,需要根据具体问题的需求、数据的特性以及预期的性能来决定使用哪种算法。在某些情况下,可能会使用集成方法,结合SVM和朴素贝叶斯的优点,以提高整体的分类性能。
都读到这里了,不妨关注、点赞支持一下吧!
