
阅读量:0
目录
步骤2:添加回归线(Regression Analysis)
步骤3:分类变量分析(Categorical Variables)
5. 分类变量分析(Categorical Variables)


专栏:数学建模学习笔记
在数据科学和数学建模的过程中,数据可视化是非常重要的一环。通过可视化,我们能够更直观地理解数据的分布和关系,从而为后续的分析和建模打下坚实的基础。本篇文章将围绕一个具体的实例,详细讲解如何使用Seaborn库进行数据可视化。我们将使用Seaborn内置的数据集tips,该数据集包含了一些餐馆的小费数据。我们的目标是通过数据可视化,探索影响小费金额的因素,并尝试建立一个数学模型。
已知数据集 tips
tips 数据集包含以下几个主要字段:
total_bill: 总账单金额tip: 小费金额sex: 性别smoker: 是否吸烟day: 就餐日期time: 就餐时间(午餐或晚餐)size: 就餐人数
生成数据集并保存为CSV文件
import pandas as pd import numpy as np # 设置随机种子 np.random.seed(0) # 生成数据 n = 1000 total_bill = np.round(np.random.uniform(5, 50, n), 2) tip = np.round(total_bill * np.random.uniform(0.1, 0.3, n), 2) sex = np.random.choice(['Male', 'Female'], n) smoker = np.random.choice(['Yes', 'No'], n) day = np.random.choice(['Thur', 'Fri', 'Sat', 'Sun'], n) time = np.random.choice(['Lunch', 'Dinner'], n) size = np.random.randint(1, 6, n) # 创建DataFrame tips = pd.DataFrame({ 'total_bill': total_bill, 'tip': tip, 'sex': sex, 'smoker': smoker, 'day': day, 'time': time, 'size': size }) # 保存数据集到CSV文件 tips.to_csv('tips.csv', index=False) # 显示数据集的前几行 print(tips.head()) 数据预览:
| total_bill | tip | sex | smoker | day | time | size |
|---|---|---|---|---|---|---|
| 29.70 | 6.49 | Female | No | Fri | Lunch | 5 |
| 37.18 | 3.79 | Female | Yes | Thur | Lunch | 2 |
| 32.12 | 6.27 | Female | No | Thur | Lunch | 4 |
| 29.52 | 7.14 | Female | No | Fri | Lunch | 5 |
| 24.06 | 2.62 | Female | Yes | Sun | Dinner | 5 |
导入和预览数据
在生成数据后,我们导入必要的可视化库,并预览数据。
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # 读取本地示例数据集 tips = pd.read_csv('tips.csv') # 显示数据集的前几行 print(tips.head()) 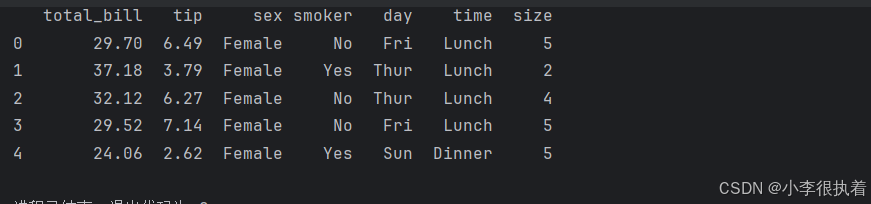
详解:
导入必要的库:
seaborn: 用于数据可视化的主要库。matplotlib.pyplot: Seaborn是基于Matplotlib构建的,所以我们需要同时导入Matplotlib来进行图表的展示。读取数据:
- 使用
pandas.read_csv函数从CSV文件中读取数据。预览数据:
- 使用
print(tips.head())函数来显示数据集的前几行,帮助我们快速了解数据的结构和内容。
步骤1:绘制散点图(Scatter Plot)
我们首先绘制一个散点图,展示总账单(total_bill)与小费(tip)之间的关系。
# 绘制散点图 sns.scatterplot(data=tips, x='total_bill', y='tip') plt.title('Scatter plot of Total Bill vs Tip') plt.xlabel('Total Bill') plt.ylabel('Tip') plt.show() 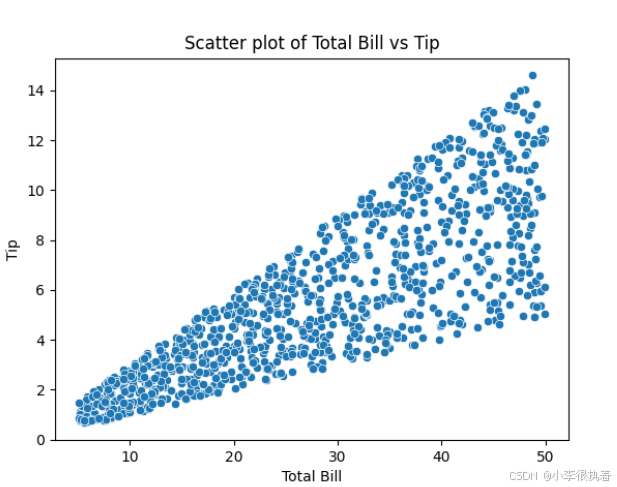
绘制散点图:
- 使用
seaborn.scatterplot函数,其中data参数指定数据集,x和y参数分别指定横轴和纵轴的数据字段。设置图表标题和标签:
- 使用
plt.title设置图表标题。- 使用
plt.xlabel和plt.ylabel分别设置横轴和纵轴的标签。显示图表:
- 使用
plt.show()函数来显示图表。
散点图是一种常用的图表类型,用于展示两个变量之间的关系。在这个例子中,使用seaborn.scatterplot函数绘制总账单(total_bill)与小费(tip)之间的散点图。通过散点图,可以直观地看到总账单和小费之间的关系。从图中可以看出,小费随总账单的增加而增加,但这种关系是否是线性的还需要进一步分析。
步骤2:添加回归线(Regression Analysis)
为了更好地了解总账单和小费之间的关系,我们可以使用Seaborn的 lmplot 函数来添加一条回归线。
# 绘制带回归线的散点图 sns.lmplot(data=tips, x='total_bill', y='tip') plt.title('Total Bill vs Tip with Regression Line') plt.xlabel('Total Bill') plt.ylabel('Tip') plt.show() 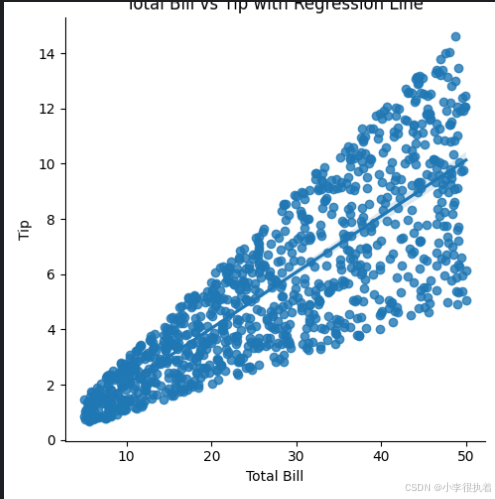
绘制带回归线的散点图:
- 使用
seaborn.lmplot函数,其中data参数指定数据集,x和y参数分别指定横轴和纵轴的数据字段。lmplot函数不仅绘制散点图,还会自动添加一条回归线,用于展示两个变量之间的线性关系。设置图表标题和标签:
- 同样使用
plt.title、plt.xlabel和plt.ylabel设置图表的标题和轴标签。显示图表:
- 使用
plt.show()函数来显示图表。
回归分析是一种统计方法,用于研究两个变量之间的关系。在这个例子中,使用Seaborn的lmplot函数来绘制带有回归线的散点图。通过添加回归线,可以更清楚地看到总账单和小费之间的线性关系。这条回归线表示小费随总账单增加的趋势,图中还会显示回归线的置信区间。
步骤3:分类变量分析(Categorical Variables)
接下来,我们分析性别、吸烟情况等分类变量对小费的影响。
# 使用hue参数根据性别绘制不同颜色的散点图 sns.scatterplot(data=tips, x='total_bill', y='tip', hue='sex') plt.title('Total Bill vs Tip by Gender') plt.xlabel('Total Bill') plt.ylabel('Tip') plt.show() 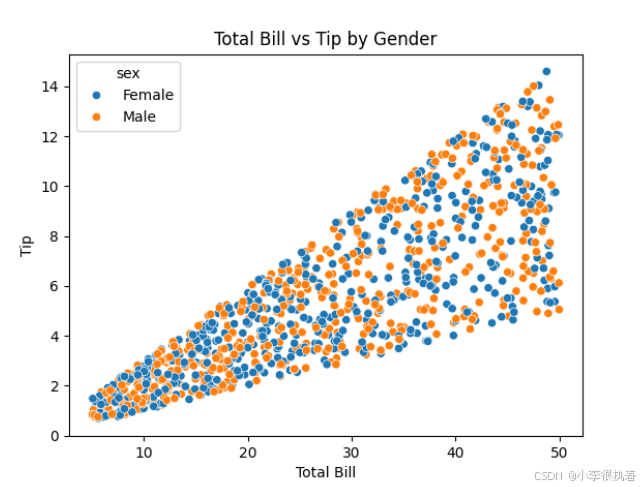
根据分类变量绘制散点图:
- 使用
seaborn.scatterplot函数,通过hue参数指定分类变量(例如性别),从而根据不同类别绘制不同颜色的点。设置图表标题和标签:
- 使用
plt.title、plt.xlabel和plt.ylabel设置图表的标题和轴标签。显示图表:
- 使用
plt.show()函数来显示图表。
分类变量(如性别、吸烟情况等)在数据分析中非常重要,因为它们能够提供关于数据分布的更多信息。在这个例子中,使用seaborn.scatterplot函数,根据性别绘制不同颜色的散点图。通过这种方式,可以看到性别对总账单和小费关系的影响。例如,可以观察到男性和女性在小费上的差异。
步骤4:箱线图(Box Plot)
箱线图可以帮助我们了解数据的分布及其异常值。
# 绘制箱线图展示不同日期的总账单分布 sns.boxplot(data=tips, x='day', y='total_bill') plt.title('Box plot of Total Bill by Day') plt.xlabel('Day') plt.ylabel('Total Bill') plt.show() 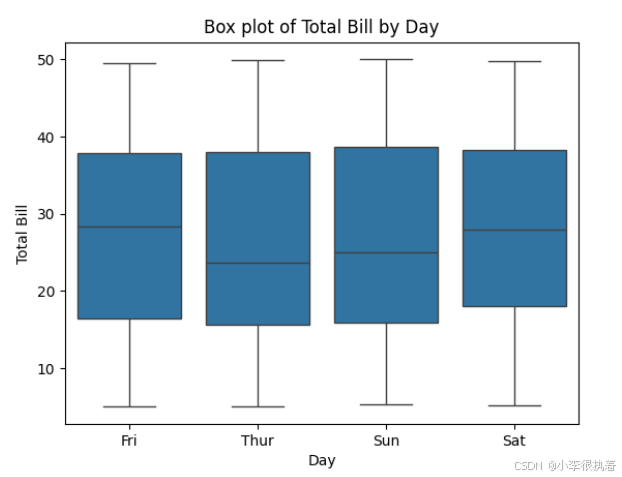
绘制箱线图:
- 使用
seaborn.boxplot函数,其中data参数指定数据集,x和y参数分别指定分类变量和连续变量。- 箱线图可以展示数据的中位数、四分位数及其异常值。
设置图表标题和标签:
- 使用
plt.title、plt.xlabel和plt.ylabel设置图表的标题和轴标签。显示图表:
- 使用
plt.show()函数来显示图表。
箱线图是一种统计图表,用于展示数据分布的五个统计量:最小值、第一四分位数、中位数、第三四分位数和最大值。箱线图还可以展示异常值。在这个例子中,使用seaborn.boxplot函数绘制不同日期(day)的总账单(total_bill)分布。通过箱线图,可以看到不同日期的总账单分布情况,并识别出哪些数据点是异常值。例如,可以观察到在某些日期,总账单的分布范围较广,而在另一些日期,分布范围较窄。
步骤5:小提琴图(Violin Plot)
小提琴图结合了箱线图和核密度图,可以提供关于数据分布的更多信息。
# 绘制小提琴图展示不同日期的小费分布 sns.violinplot(data=tips, x='day', y='tip') plt.title('Violin plot of Tip by Day') plt.xlabel('Day') plt.ylabel('Tip') plt.show() 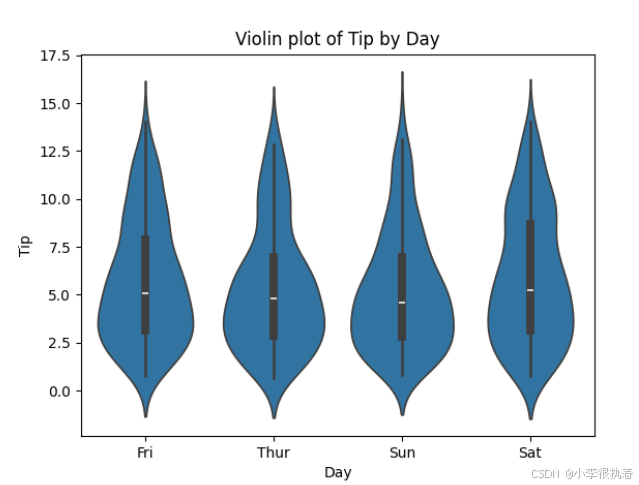
绘制小提琴图:
- 使用
seaborn.violinplot函数,其中data参数指定数据集,x和y参数分别指定分类变量和连续变量。- 小提琴图展示了数据分布的核密度估计,并结合了箱线图的元素。
设置图表标题和标签:
- 使用
plt.title、plt.xlabel和plt.ylabel设置图表的标题和轴标签。显示图表:
- 使用
plt.show()函数来显示图表。
小提琴图结合了箱线图和核密度图的优点,可以更详细地展示数据分布的特征。在这个例子中,使用seaborn.violinplot函数绘制不同日期(day)的小费(tip)分布。通过小提琴图,可以看到不同日期的小费分布情况,并识别出数据分布的密度和异常值。例如,可以观察到在某些日期,小费的分布较为集中,而在另一些日期,分布较为分散。
步骤6:绘制热力图(Heatmap)
热力图适合展示矩阵数据,比如相关矩阵。例如,绘制数据集的相关矩阵:
# 选择数值列 numeric_tips = tips.select_dtypes(include='number') # 计算相关矩阵并绘制热力图 corr = numeric_tips.corr() plt.figure(figsize=(10, 8)) sns.heatmap(corr, annot=True, cmap='coolwarm', linewidths=0.5) plt.title('Heatmap of Correlation Matrix') plt.show() 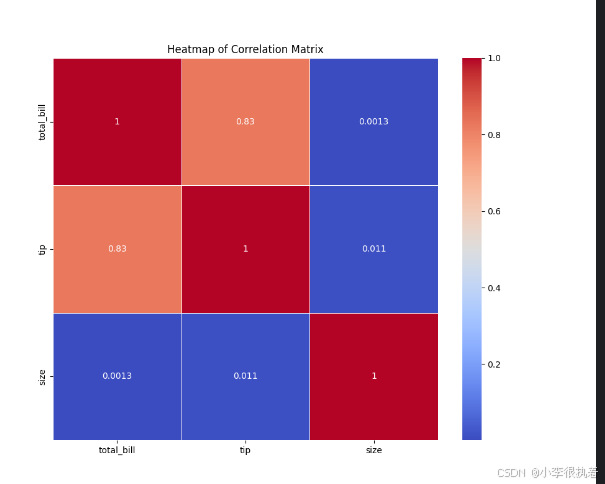
计算相关矩阵:
- 使用
DataFrame.corr()函数计算数据集中数值变量之间的相关系数。绘制热力图:
- 使用
seaborn.heatmap函数绘制热力图。corr:相关矩阵,作为热力图的数据输入。annot=True:在每个单元格中显示相关系数的数值。cmap='coolwarm':设置热力图的颜色映射,coolwarm颜色映射使得正相关和负相关的数据点能够通过颜色区分开来。linewidths=0.5:设置每个单元格之间的间隔线宽度。设置图表大小:使用
plt.figure(figsize=(10, 8))设置图表的大小,确保图表清晰可读。设置图表标题:使用
plt.title设置图表的标题。显示图表:使用
plt.show()函数来显示热力图。
相关矩阵热力图解释:
- 对角线:热力图的对角线上的值都是1,因为每个变量与自身的相关系数都是1。
- 变量之间的相关性:热力图的非对角线单元格显示了不同变量之间的相关系数。颜色的深浅表示相关性强弱,颜色的方向(冷暖)表示正相关或负相关。
通过这些详细的步骤,我们能够全面地分析和可视化餐馆小费数据,深入了解影响小费的各种因素,为进一步的数学建模和决策提供有力的支持。

总结
1. 生成数据集并保存为CSV文件
首先,我们生成了一个包含餐馆小费信息的模拟数据集,并将其保存为CSV文件。数据集包含以下字段:total_bill、tip、sex、smoker、day、time和size。
2. 导入和预览数据
使用Pandas库读取本地CSV文件,并预览数据集的前几行,以了解数据的结构和内容。
3. 绘制散点图(Scatter Plot)
使用Seaborn的scatterplot函数绘制散点图,展示总账单(total_bill)与小费(tip)之间的关系。
4. 添加回归线(Regression Analysis)
使用Seaborn的lmplot函数在散点图上添加回归线,以更清晰地展示总账单和小费之间的线性关系。
5. 分类变量分析(Categorical Variables)
使用scatterplot函数的hue参数,根据性别绘制不同颜色的散点图,分析性别对总账单和小费关系的影响。
6. 绘制箱线图(Box Plot)
使用Seaborn的boxplot函数绘制箱线图,展示不同日期的总账单分布,帮助识别数据的中位数、四分位数及其异常值。
7. 绘制小提琴图(Violin Plot)
使用Seaborn的violinplot函数绘制小提琴图,结合箱线图和核密度图,提供更多关于数据分布的信息。
8. 绘制热力图(Heatmap)
计算数据集中数值变量之间的相关矩阵,使用Seaborn的heatmap函数绘制热力图,直观地展示各变量之间的相关性。
通过这些步骤,可以全面地分析和可视化餐馆小费数据,深入了解影响小费的各种因素,为进一步的数学建模和决策提供有力的支持。
