
阅读量:0
使用selenium库模拟操作edge浏览器
安装前准备
selenium是一个用于Web应用程序测试的工具,可以模拟成真实用户操作。由于可以控制浏览器发送请求,并获得网页数据,所以可以用于爬虫领域。但是selenium不包括浏览器,需要于浏览器结合在一起使用。
优缺点:(模拟用户手动打开,所以显然)
- 优点:适合爬取反爬能力强的网站或者需要提交的网站。
- 缺点:速度慢。
安装selenium库
可以使用pip安装:
pip install selenium

当然也可以在pycharm解释器中按加号搜索selenium安装
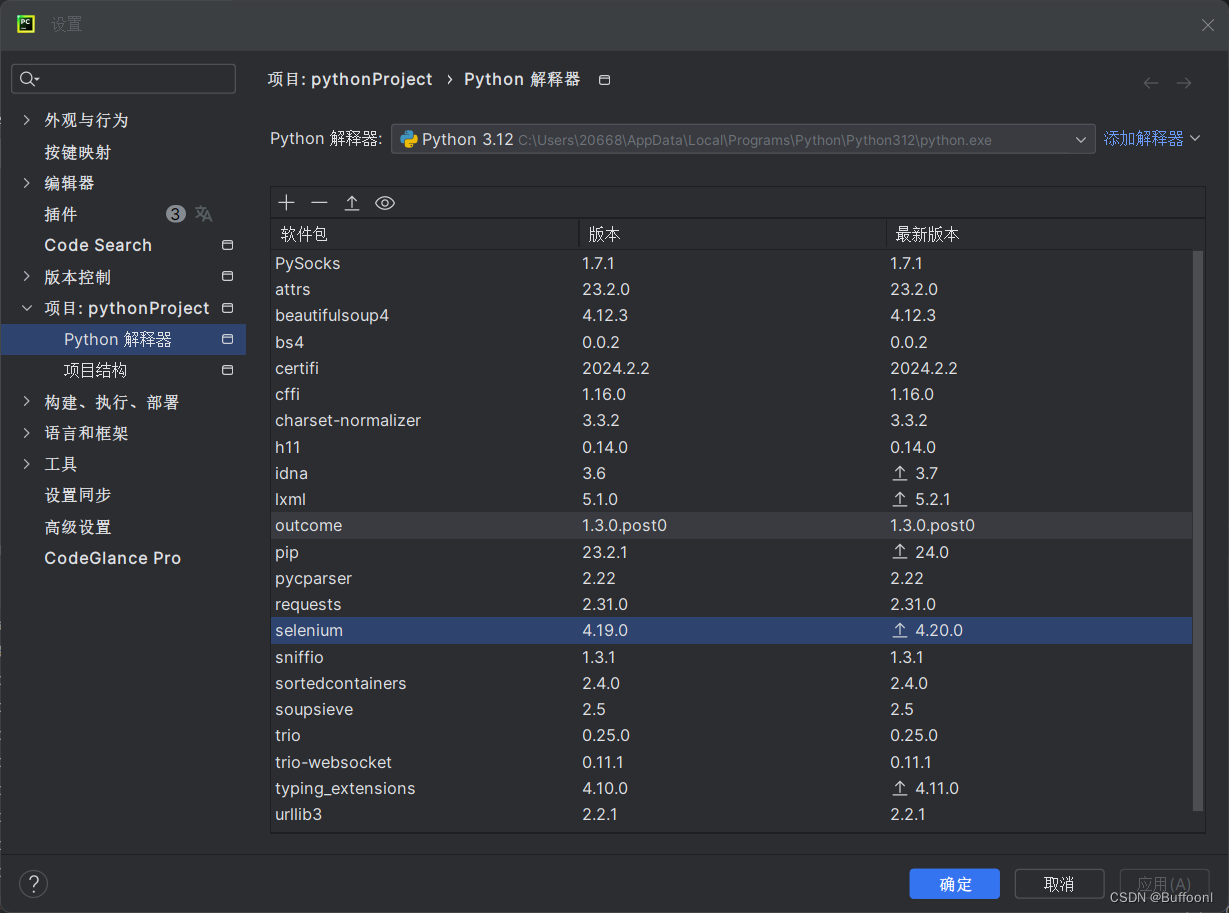
安装浏览器驱动(Edge为例)
这里具体步骤可以进入官方文档使用 WebDriver 自动执行 Microsoft Edge - Microsoft Edge Developer documentation | Microsoft Learn查看。下面为大致步骤。
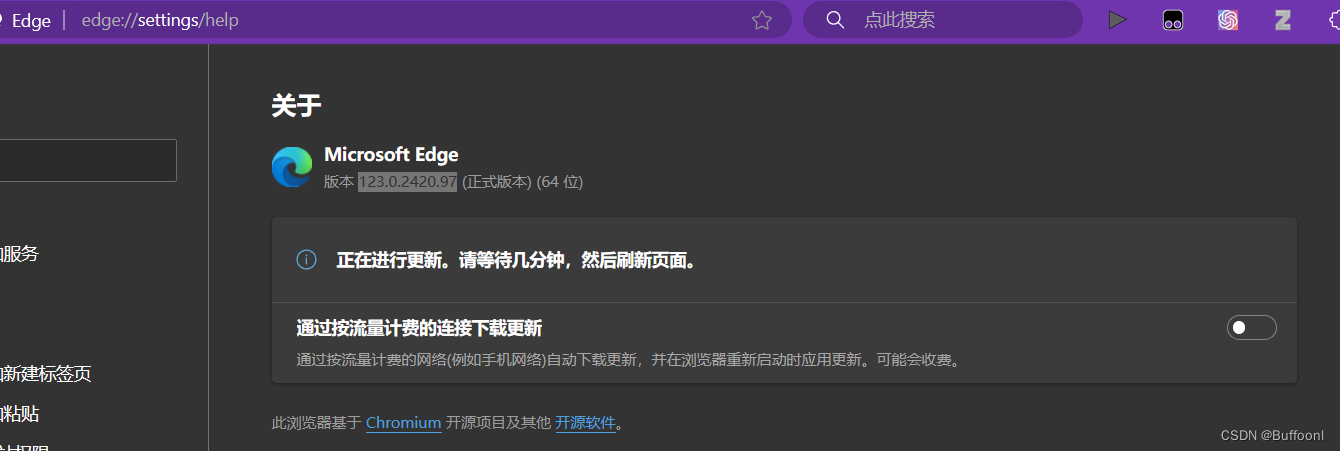
先要确定当前浏览器版本
可以在edge://settings/help网站查看。
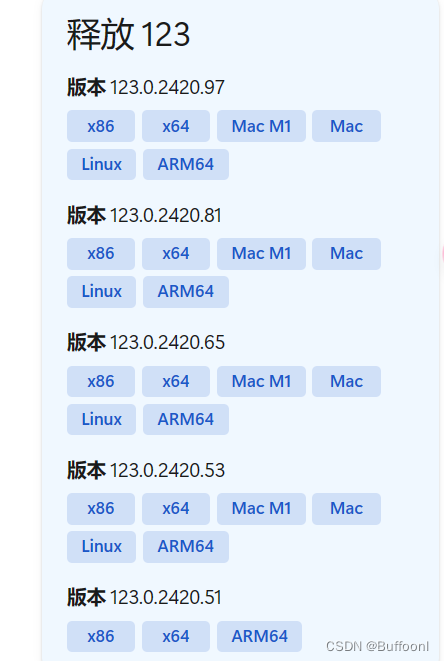
下载浏览器驱动
在Microsoft Edge WebDriver |Microsoft Edge 开发人员可以下载。我的版本为123.0.2420.97,进入界面后下滑找到对应版本。x64是64位,x86是32位。
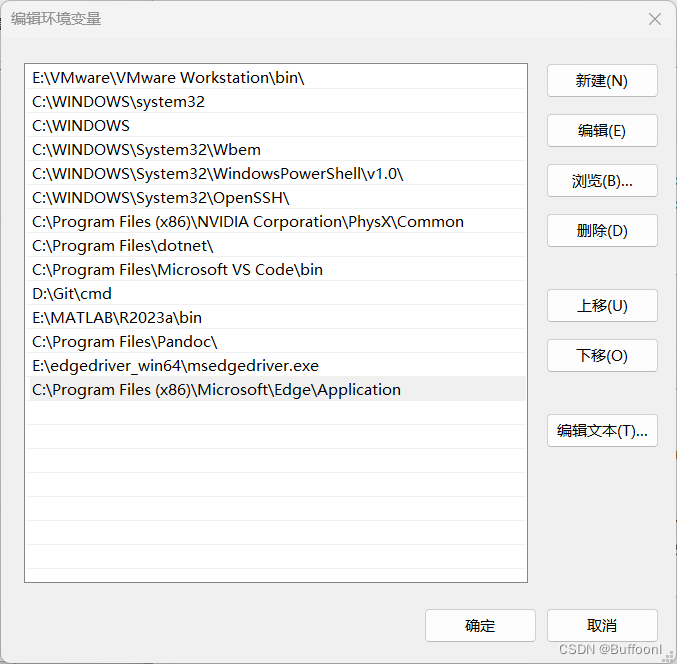
编辑环境变量
先找到浏览器安装位置
右键桌面快捷方式查看属性,可以得到文件安装位置,我的位置是C:\Program Files (x86)\Microsoft\Edge\Application。
解压浏览器驱动安装包,同样右键解压后的exe文件得到位置。
我是windows系统,打开环境变量,在系统变量找到‘PATH’,添加上面得到的位置。如图。
测试环境变量是否配置成功。
win+R打开cmd,输入msedge.exe能打开浏览器就算成功。
简单示例代码
爬取百度搜索页面案例
from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep # 百度搜索内容 # 初始化浏览器 driver = webdriver.Edge() # 用get打开百度页面 driver.get('https://www.baidu.com') # 找到百度的输入框,并输入“美少女战士” driver.find_element(By.ID, 'kw').send_keys('美少女战士') sleep(2) # 点击搜索按钮 driver.find_element(By.ID, 'su').click() sleep(5) content = driver.find_element(By.ID, 'content_left').text print(content) driver.quit()部分结果如下:

爬取豆瓣电影top250(图片多,加载较慢)
from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep from bs4 import BeautifulSoup # 爬取豆瓣电影数据 movies_total = [] # 初始化浏览器 driver = webdriver.Edge() # 用get打开豆瓣电影页面 base_url = "https://movie.douban.com/top250" for i in range(0, 10): url = base_url + "?start=" + str(i * 25) # 发送请求 driver.get(url) sleep(2) html = driver.page_source soup=BeautifulSoup(html, "lxml") # 解析数据 title_list = soup.select('.grid_view>li a>.title') for title in title_list: movies = '《'+ title.text + '》' if '/' not in movies: movies_total.append(movies) print('第%d至%d部电影已爬取' % (i * 25 + 1, (i + 1) * 25)) #持久化存储 with open('./douban_bs.doc', 'w', encoding='utf-8') as f: for movie in movies_total: f.write(movie) print('爬取完毕') driver.quit()输出结果如下图:

总结selenium的一些常用方法
# 访问url driver.get("https://www.example.com") # 关闭当前浏览器窗口 driver.close() # 退出浏览器进程,关闭所有相关窗口 driver.quit() # 后退 driver.back() # 前进 driver.forward() # 刷新窗口 driver.refresh() # 获取整张页面资源 driver.page_source交互操作
# 点击元素 element = driver.find_element(By.ID, 'button_id') element.click() # 输入文本 textbox = driver.find_element(By.NAME, 'textbox_name') textbox.send_keys('Hello, Selenium!') #清除文本框内容 textbox.clear()# 输入文本 textbox = driver.find_element(By.NAME, 'textbox_name') textbox.send_keys('Hello, Selenium!') #清除文本框内容 textbox.clear()
