
阅读量:0

👨🎓博主简介
🏅CSDN博客专家
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
脚本式流水线
学习脚本式流水线,我们先学
groovy语法;脚本式流水线都是运行在script中的。
groovy语法
注释
和java、python一样的,(使用//)、多行(/* */)和文档注释(使用/** */)。
标识符
标识符也称为变量名;以字母、美元符号$或下划线_开始,不能以数字开始。
以下是可用的标识符:
- def name
- def name_age
- def $name
- def name2
以下是不可用的标识符:
- def name+age
- def name#age
- def 1name
字符串
在Groovy中字符串有两种类型,一种是Java原生的java.lang.String;另一种是groovy.lang.GString,又叫插值字符串(interpolated strings)。
单引号字符串(Single quoted string)
在Groovy中,使用单引号括住的字符串就是java.lang.String,不支持插值:
def name = 'dancs' println name.class # class java.lang.String 三单引号字符串(Triple single quoted string)
使用三单引号括住字符串支持多行,也是java.lang.String实例,在第一个’‘’起始处加一个反斜杠\可以在新一行开始文本:
def strippedFirstNewline = '''line one line two line three ''' // 可以写成下面这种形式,可读性更好 def strippedFirstNewline = '''\ line one line two line three ''' 双引号字符串(Double quoted string)
如果双引号括住的字符串中没有插值表达式(interpolated expression),那它就是java.lang.String;如是有插值表达式,那它就是groovy.lang.GString:
def normalStr = "yjiyjige" // 这是一个java.lang.String def interpolatedStr = "my name is ${normalStr}" // 这是一个groovy.lang.GString 字符串插值(String interpolation)
在Groovy语法中,所有的字符串字面量表示中,除了单引号字符串和三单引号字符串之外,其他形式都支持字符串插值。字符串插值,也即将占位表达式中的结果最终替换到字符串相应的位置中:
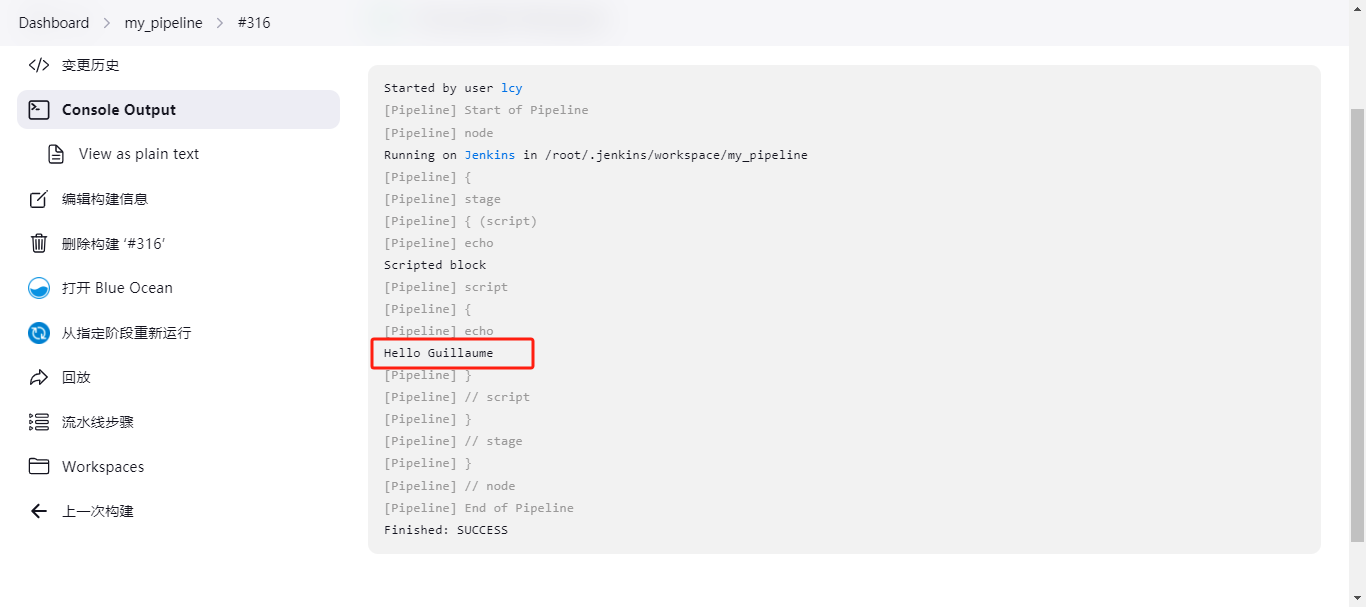
def name = 'Guillaume' // 单引号不支持插值,定义一个变量值 def greeting = "Hello ${name}" // name变量的值会被替换进去 print greeting.toString() == 'Hello Guillaume' 在Jenkins流水线中的script中使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def name = 'Guillaume' def greeting = "Hello ${name}" print greeting.toString() } } } } } 输出结果为:
当使用点号表达式时,可以只用$代替${}:
点号表达式为:
变量名.字典key
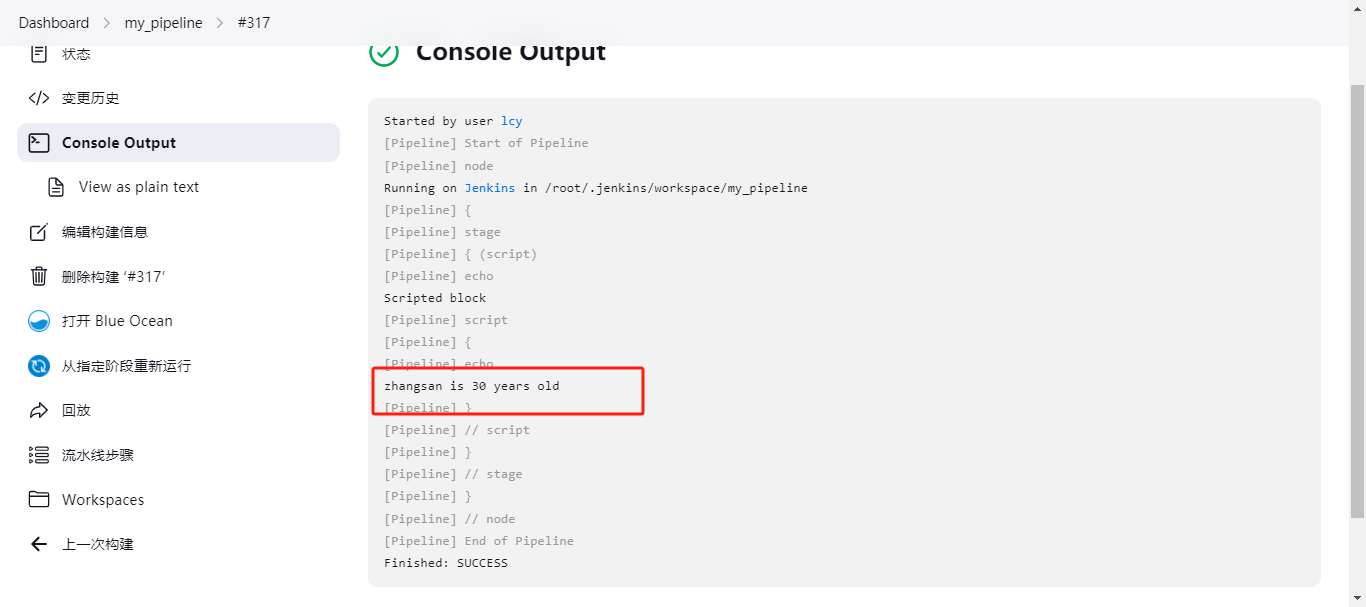
//定义变量字典 def person = [name: 'Guillaume', age: 36] // 输出信息,调用变量 println "$person.name is $person.age years old" 在Jenkins流水线中的script中使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def person = [name: 'zhangsan', age: 30] println "$person.name is $person.age years old" } } } } } 输出结果为:zhangsan is 30 years old
// 注意还有一种小数点值输出的方式 def number = 3.14 println "$number.toString()" // 这里会报异常,因为相当于"${number.toString}()" println "${number.toString()}" // 这样就正常了 // 或者直接使用变量,就不会有小数点的报错了 println "$number" 列表
默认情况下Groovy的列表使用的是java.util.ArrayList,用中括号[]括住,使用逗号分隔:
def number = [1,2,3,4] 查看指定列表值
列表值是从0开始算的,输出第1个内容的时候为0;
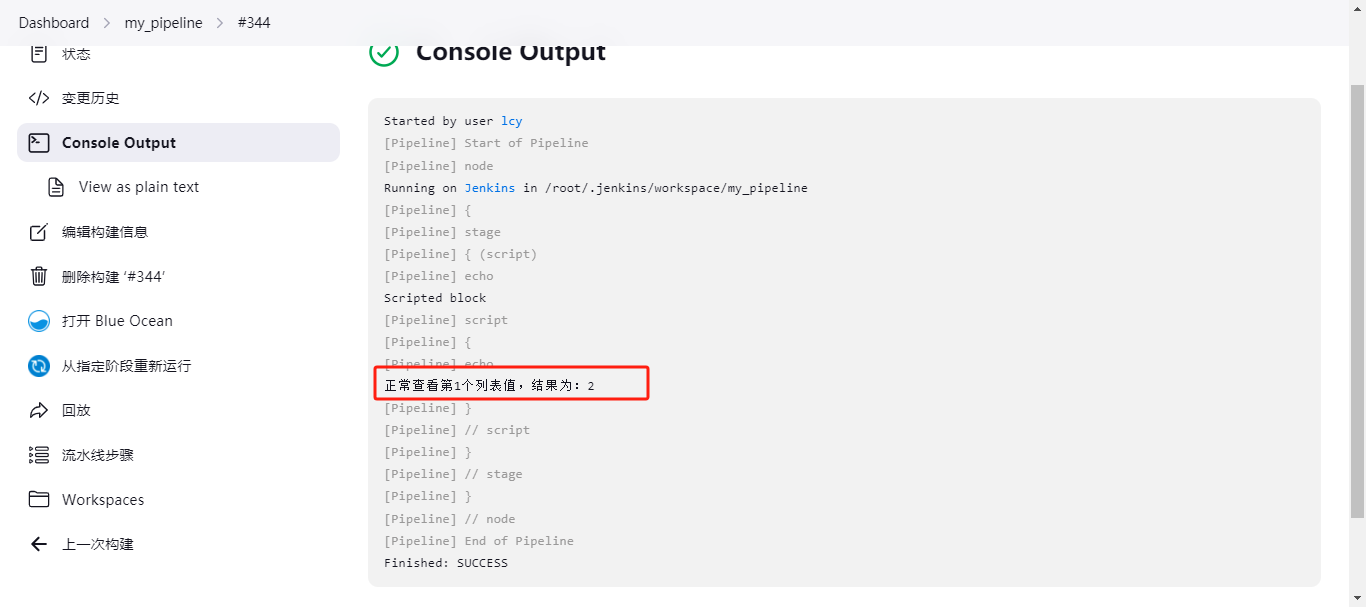
def number1 = [1,2,3,4] print "${number1[1]}" // 返回的就是:2,如果[中写的0]返回的就是1;以此类推; // 如果[中写的是4]超过了列表值,那么就返回的null。 下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def number1 = [1,2,3,4] print "正常查看第1个列表值,结果为:${number1[1]}" } } } } } 结果为:2
注意:如果
print "$number[1]"不是用{}输出,那么输出的内容将是:[1, 2, 3, 4][1];
查看列表值从前往后找
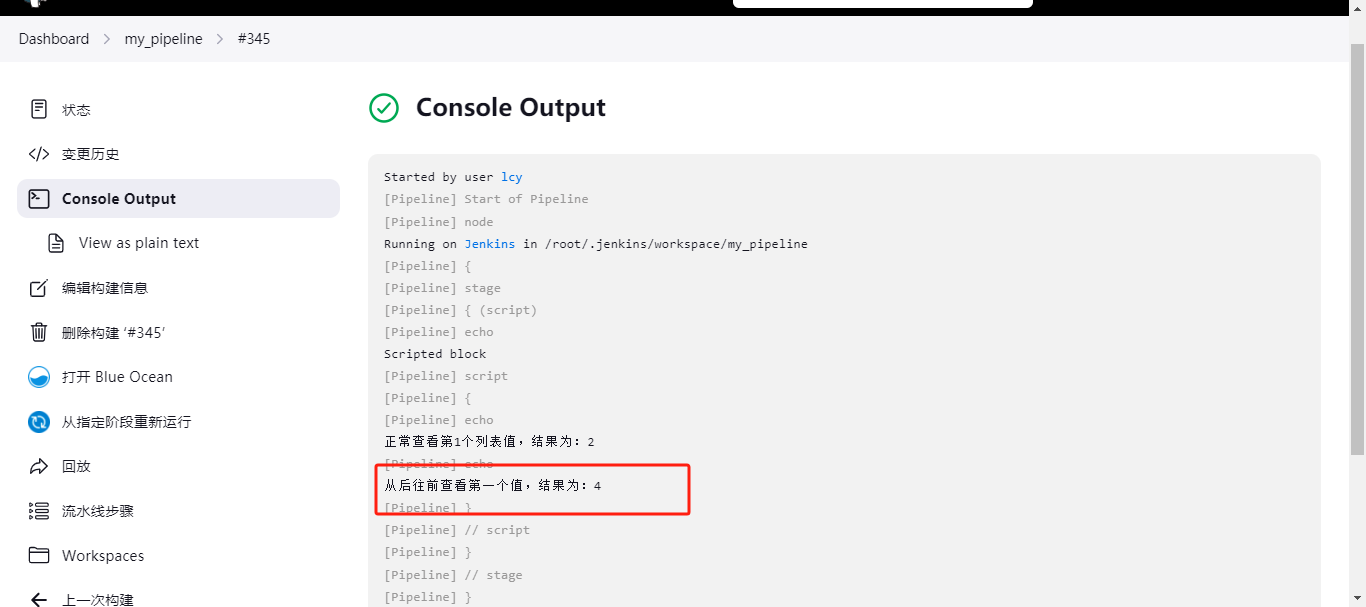
def number2 = [1,2,3,4] print "${number2[-1]}" // 结果为:4;[-2]就是3;以此类推。 下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def number1 = [1,2,3,4] print "正常查看第1个列表值,结果为:${number1[1]}" def number2 = [1,2,3,4] print "从后往前查看第一个值,结果为:${number2[-1]}" } } } } } 执行结果为:4
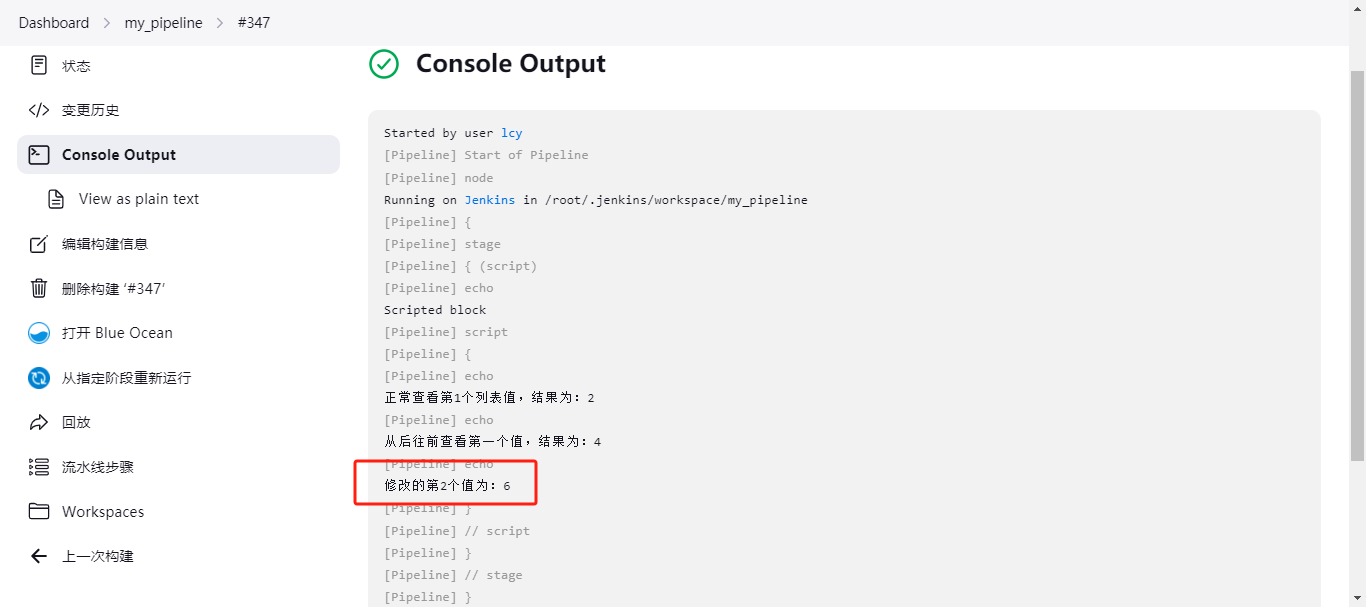
直接修改列表值
def number3 = [1,2,3,4] number3[2] = 6 print "${number3[2]}" // 输出结果为:6,如果选择[1]的话,那么输出的结果就还是2。 下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def number1 = [1,2,3,4] print "正常查看第1个列表值,结果为:${number1[1]}" def number2 = [1,2,3,4] print "从后往前查看第一个值,结果为:${number2[-1]}" def number3 = [1,2,3,4] number3[2] = 6 print "修改的第2个值为:${number3[2]}" } } } } } 结果为:6
在列表中往后面添加一个值
def number4 = [1,2,3,4] number4[4] = 5 print "在最后添加一个值,结果为:${number4[4]}" // 结果为:5 print "此列表中现在所有的结果为:$number4" // 结果为:[1,2,3,4,5] 下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def number1 = [1,2,3,4] print "正常查看第1个列表值,结果为:${number1[1]}" def number2 = [1,2,3,4] print "从后往前查看第一个值,结果为:${number2[-1]}" def number3 = [1,2,3,4] number3[2] = 6 print "修改的第2个值为:${number3[2]}" def number4 = [1,2,3,4] number4[4] = 5 print "在最后添加一个值,结果为:${number4[4]}" print "此列表中现在所有的结果为:$number4" } } } } } 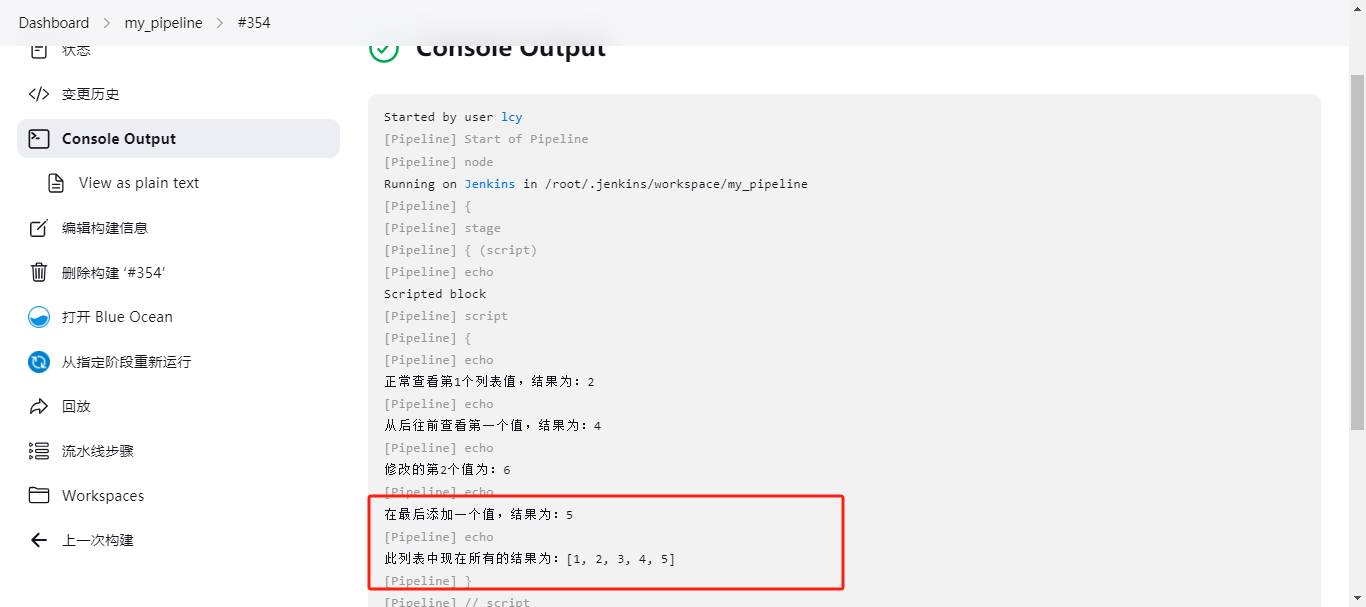
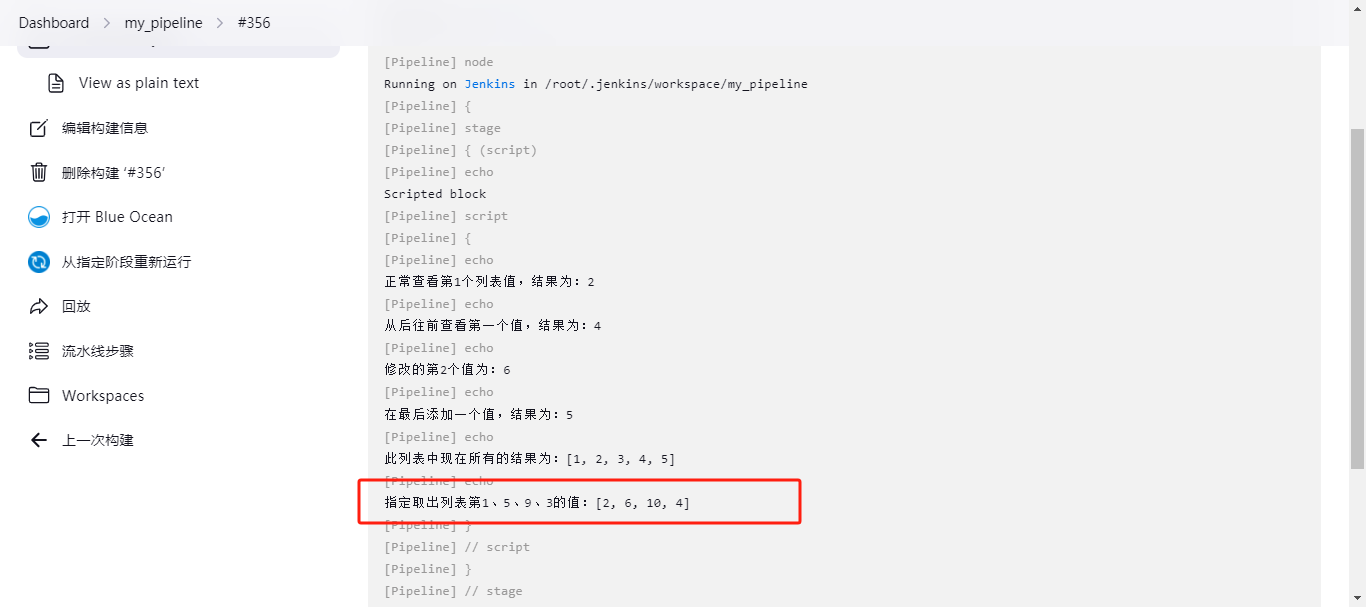
指定输出列表值
def number5 = [1,2,3,4,5,6,7,8,9,10] print "指定取出列表第1、5、9、3的值:${number5[1,5,9,3]}" 下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def number1 = [1,2,3,4] print "正常查看第1个列表值,结果为:${number1[1]}" def number2 = [1,2,3,4] print "从后往前查看第一个值,结果为:${number2[-1]}" def number3 = [1,2,3,4] number3[2] = 6 print "修改的第2个值为:${number3[2]}" def number4 = [1,2,3,4] number4[4] = 5 print "在最后添加一个值,结果为:${number4[4]}" print "此列表中现在所有的结果为:$number4" def number5 = [1,2,3,4,5,6,7,8,9,10] print "指定取出列表第1、5、9、3的值:${number5[1,5,9,3]}" } } } } } 结果为:[2, 6, 10, 4]
二维列表
在Groovy(以及许多其他编程语言中)中,二维列表(或称为列表的列表)是一个列表,其中的每个元素也是一个列表。换句话说,它是一个列表的嵌套结构。下面是个例子:
def twoDimensionalList = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] 简单来说,在列表的基础上;用一个大的中括号,套多个中括号列表,称为二维列表。
下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script') { steps { echo "Scripted block" script { def number1 = [1,2,3,4] print "正常查看第1个列表值,结果为:${number1[1]}" def number2 = [1,2,3,4] print "从后往前查看第一个值,结果为:${number2[-1]}" def number3 = [1,2,3,4] number3[2] = 6 print "修改的第2个值为:${number3[2]}" def number4 = [1,2,3,4] number4[4] = 5 print "在最后添加一个值,结果为:${number4[4]}" print "此列表中现在所有的结果为:$number4" def number5 = [1,2,3,4,5,6,7,8,9,10] print "指定取出列表第1、5、9、3的值:${number5[1,5,9,3]}" def number6 = [[0, 1], ['壹', '叁'],['a','c','d','f']] print "二维列表中,指定输出的值为:${number6[2][3]}" } } } } } 输出的结果为:f

解析:
二维列表 列表值可以多写,但是输出的内容只能是两个值,多的话就会报错;
输出的内容列表[ ] :第一个是子列表的意思;第二个是子列表中的内容的意思;
所以,第一个值是2,那我们找的就是第三个子列表,因为从0开始计算嘛;第二个值是3,那我们找的是第三个子列表中的第4个值,当然也是从0开始计算的,所以结果是f。
字典(Maps)
在Groovy语法中,使用中括号[]来定义字典,和列表一样,都是使用中括号[],但区别为列表[]里是具体的值,而字典里是需要包含key和value,key和value之间使用冒号分隔,元素与元素之间用逗号分隔;
下面一个基本的例子:
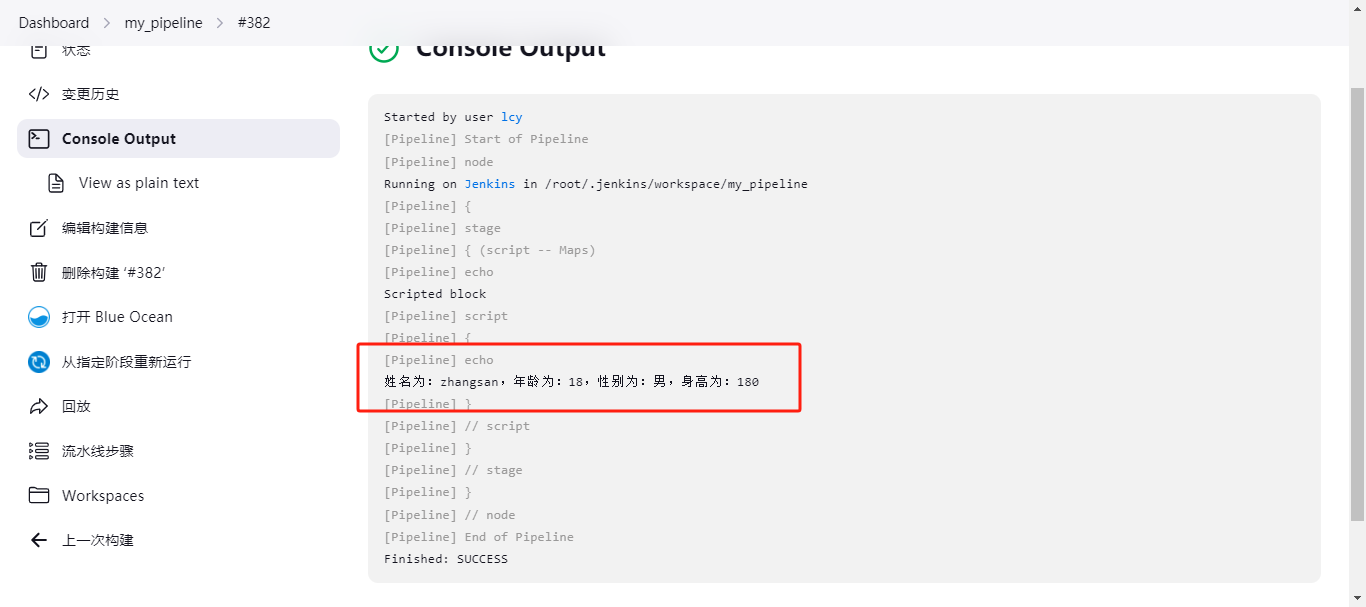
def people = [name:'zhangsan',age:'18',sex:'男',height:'180'] print "姓名为:${people.name},年龄为:${people.age},性别为:${people.sex},身高为:${people.height}" 下面是在Jenkins流水线的script下使用:
pipeline { agent any stages { stage('script -- Maps') { steps { echo "Scripted block" script { def people = [name:'zhangsan',age:'18',sex:'男',height:'180'] print "姓名为:${people.name},年龄为:${people.age},性别为:${people.sex},身高为:${people.height}" } } } } } 输出的结果为:
条件语句 if/else判断
pipeline脚本同其它脚本语言一样,从上至下顺序执行,它的流程控制取决于Groovy表达式,如if/else条件语句:
- 语法:
if (条件) { echo "要输出的值" }else{ echo "要输出的值2" } script 示例:
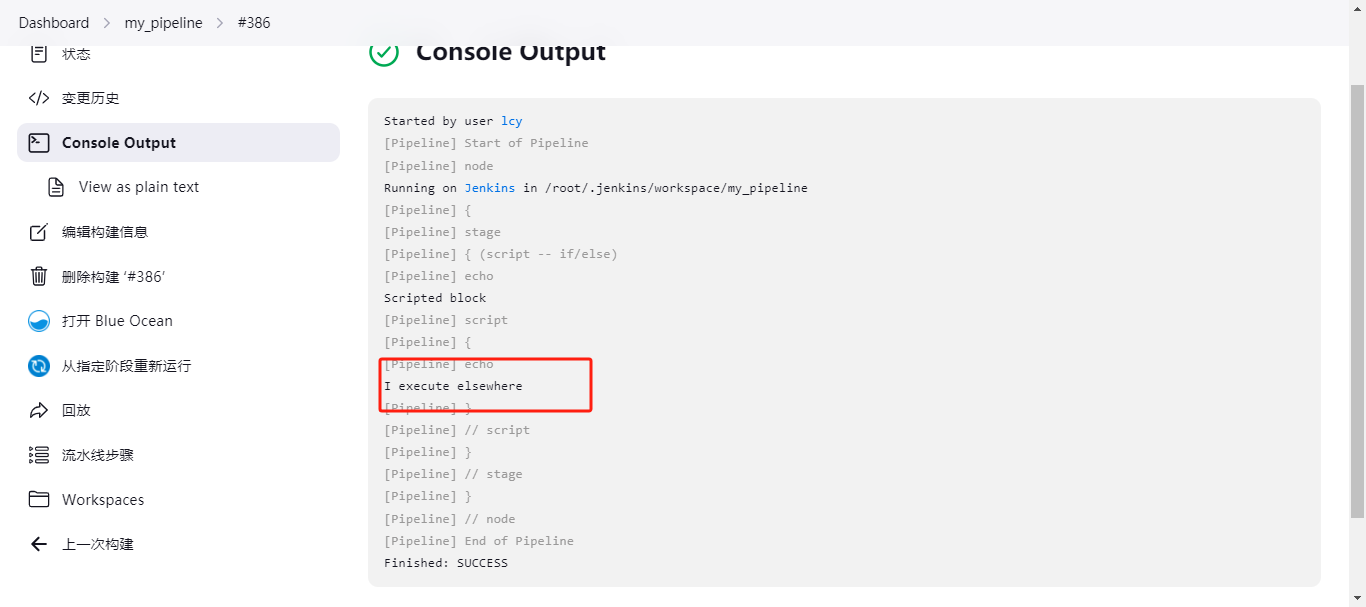
pipeline { agent any stages { stage('script -- if/else') { steps { echo "Scripted block" script { if(env.BRANCH_NAME == 'master'){ echo 'I only execute on the master branch' }else{ echo 'I execute elsewhere' } } } } } } 判断,如果是在master分支上执行的那么就输出:I only execute on the master branch,否则就输出:I execute elsewhere;
env.BRANCH_NAME是流水线语法中的全局变量,可在此查看全局变量都有什么:http://ip:port/job/my_pipeline/pipeline-syntax/globals
注:ip:port 替换为自己的ip和端口
执行结果为:I execute elsewhere,因为我们没有开启多分支所以没有分支的说法,所以是false判断;
for循环
for 循环用于遍历一组值。用法和JAVA是一样的;
- for循环语法:
for(int i = 1;i<=5;i++) { println "循环第${i}次"; } - 在Jenkins的
script中使用:
pipeline { agent any stages { stage('script -- for') { steps { echo "Scripted block" script { for(int i = 1;i<=5;i++) { println "循环第${i}次"; } } } } } } 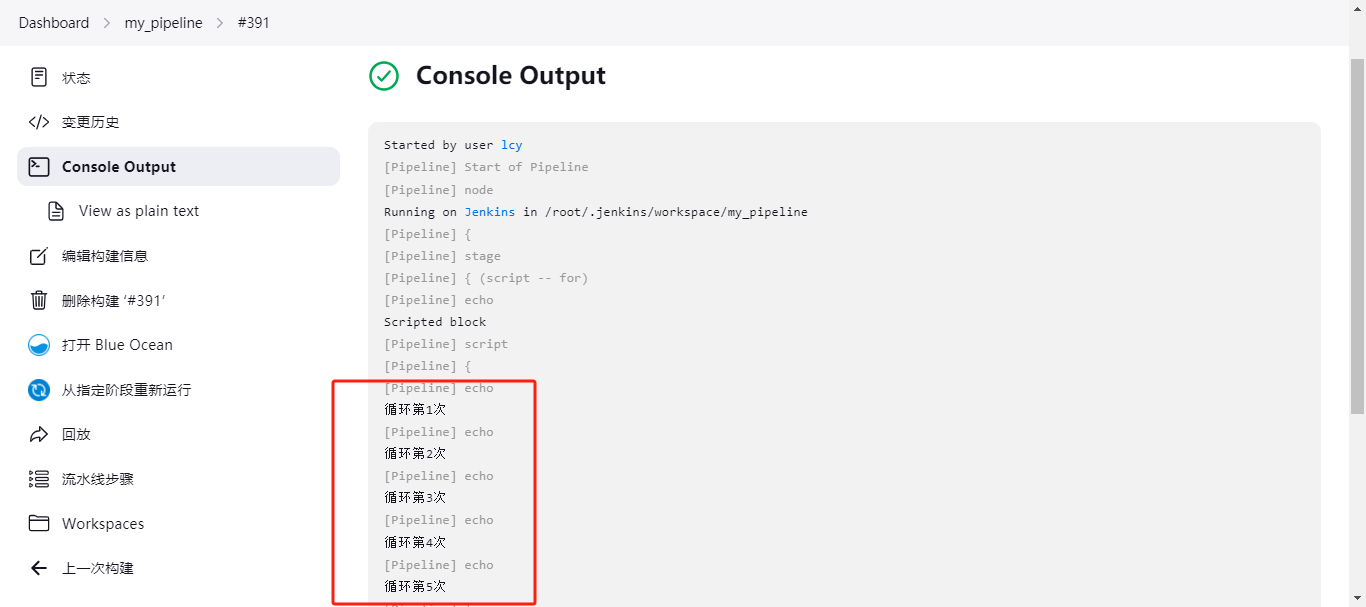
- 进阶for循环,在Jenkins的
script中使用:
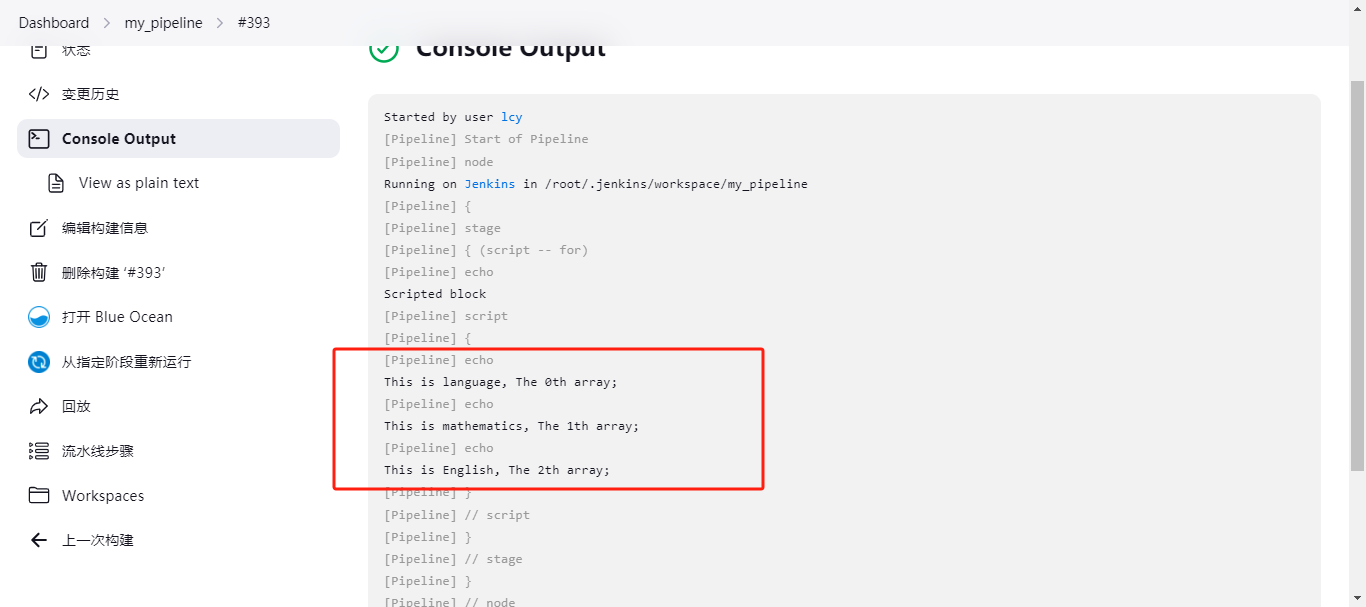
pipeline { agent any stages { stage('script -- for') { steps { echo "Scripted block" script { def array = ['language','mathematics','English'] for (i = 0;i < array.size();i++) { echo "This is ${array[i]}, The ${i}th array;" } } } } } } 执行结果:
异常处理try/catch/finally
pipeline脚本流程控制的另一种方式是Groovy的异常处理机制。当任何一个步骤因各种原因而出现异常时,都必须在Groovy中使用try/catch/finally语句块进行处理
pipeline { agent any stages { stage('Example Stage with Exception Handling') { steps { script { try { // 尝试执行的代码块 echo "Trying to execute some code..." // 这里可以调用其他函数或执行可能抛出异常的步骤 // 例如,模拟一个异常: throw new Exception("Something went wrong!") } catch (Exception e) { // 捕获并处理异常 echo "Caught an exception: ${e.getMessage()}" // 可以选择标记构建为失败,或者进行其他错误处理 currentBuild.result = 'FAILURE' } finally { // 无论是否发生异常,都会执行的代码块 echo "This will always be executed, regardless of exceptions." // 可以在这里执行清理操作或其他必要的步骤 } } } } } } 在这个例子中,try 块包含可能会抛出异常的代码。如果 try 块中的代码抛出了异常,那么控制流会立即跳转到与异常类型匹配的 catch 块(在这个例子中是 Exception 类型)。在 catch 块中,你可以处理异常,比如记录错误消息或者设置构建的状态。
无论 try 块中的代码是否抛出异常,finally 块中的代码都会被执行。这通常用于执行清理操作,比如关闭文件句柄、释放资源等。
请注意,在 Jenkins Pipeline 脚本中,使用 currentBuild.result = 'FAILURE' 可以将构建状态标记为失败。这通常在捕获到异常并希望停止构建流程时非常有用。如果 finally 块中的代码也可能失败,你可能还需要在 finally 块中进一步处理异常,以确保所有的清理工作都能正确完成。
总结
这一节,基本上对
jenkins的pipeline脚本式流水线及groovy语法做了比较完整的介绍,在以后再看pipeline脚本时,可能还会接触到许多插件提供的函数或更多的指令,但是它们都逃不开pipeline脚本的基本结构,掌握了基础语法,后面才能更上一层楼。
参考文献:
文章参考与:
相关专栏
相关文章
| 文章名称 | 文章链接 |
|---|---|
| 【Jenkins】Pipeline流水线语法解析全集 – 声明式流水线 | https://liucy.blog.csdn.net/article/details/136528857 |
| 【Jenkins】Pipeline流水线语法解析全集 – 脚本式流水线、groovy语法 | https://liucy.blog.csdn.net/article/details/136567517 |
