
阅读量:0
为了解决特定问题而进行的学习是提高效率的最佳途径。这种方法能够使我们专注于最相关的知识和技能,从而更快地掌握解决问题所需的能力。
目录
朴素贝叶斯算法介绍
朴素贝叶斯(Naive Bayes)是一类基于贝叶斯定理的简单概率分类器。"朴素"这个词指的是这些模型在特征之间独立性的假设上非常"天真"。尽管这个假设在现实世界中往往不成立,但朴素贝叶斯分类器在很多情况下表现出了令人惊讶的有效性,尤其是在文本分类和垃圾邮件过滤等任务中。
工作原理
朴素贝叶斯分类器的核心是贝叶斯定理,它描述了两个条件概率之间的关系:
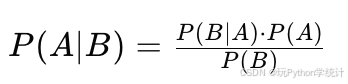
在分类问题中,我们通常想要计算给定观测数据 X 下,某个类别 Ck 的后验概率 P(Ck|X)。根据贝叶斯定理,我们可以将其表示为:

其中:
- P(Ck) 是类别 Ck 的先验概率。
- P(X|Ck) 是给定类别 Ck 下观测数据 X 的似然概率。
- P(X) 是观测数据 X 的边缘概率。
算法类型
- 多项式朴素贝叶斯:适用于文本数据,使用多项式分布来建模特征。
- 伯努利朴素贝叶斯:适用于二元特征,如布尔值。
- 高斯朴素贝叶斯:适用于具有高斯分布的数据,常用于连续特征。
优点
- 简单快速:实现简单,训练速度快,尤其是在特征数量很大时。
- 易于理解和解释:模型的参数和概率解释直观。
- 对缺失数据具有鲁棒性:在计算后验概率时,缺失的特征不会影响其他特征的计算。
缺点
- 特征独立性假设:在现实世界中,特征往往是相关的,这可能影响模型的准确性。
- 对类别不平衡敏感:如果类别分布极不均匀,模型的性能可能会受到影响。
应用
- 文本分类
- 垃圾邮件过滤
- 情感分析
- 推荐系统
尽管朴素贝叶斯的假设很理想化,但在许多实际应用中,它仍然是一个非常有效的工具,特别是在数据集很大且特征数量很多的情况下。
练习题
对已标注出垃圾邮件和正常邮件的csv文件实现朴素贝叶斯算法分类。
Python代码与分析
1、加载必要的Python库。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn import metrics from sklearn.metrics import classification_report, confusion_matrix import matplotlib.pyplot as plt2、读取csv文件,把csv文件读入到一个pandas的DataFrame对象里。
然后对数据里面的NULL值,用空字符串(即'')代替。
df1 = pd.read_csv('spamham.csv') df = df1.where(pd.notnull(df1)) df.head() # 查看数据前5行
3、对Category列进行变换,将取值ham和spam分别改成1或者0,以便进行后续机器学习的训练。
df.loc[df['Category'] == 'ham', 'Category'] = 1 df.loc[df['Category'] == 'spam', 'Category'] = 0 df.head()
4、把Message列作为x,Category列作为y。
df_x = df['Message'] df_y = df['Category']5、划分数据集,80%用于训练模型,20%用于测试模型。
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, test_size = 0.2)6、把Message数据列(x列)转换成机器学习的特征值(关键步骤)。
在这里采用文本的TF-IDF特征。TF表示单个文档里的某个词项的频率,IDF表示整个文集中词项的逆文档频率。IDF把在很多文档中都出现的但对于文档的类别划分没有太多贡献的词项的重要性降低。
tfvec = TfidfVectorizer(min_df = 1, stop_words = 'english', lowercase = True) x_trainFeat = tfvec.fit_transform(x_train) x_testFeat = tfvec.transform(x_test)7、创建朴素贝叶斯分类模型,对其进行训练,并且利用模型对测试集进行预测。
在此之前,把训练集的y转换成整数形式。
y_trainGnb = y_train.astype('int') classifierModel = MultinomialNB() classifierModel.fit(x_trainFeat, y_trainGnb) y_pred = classifierModel.predict(x_testFeat)8、把测试集的y转换成整数形式,对上述模型的预测值进行比较,显示分类器混淆矩阵和分类报告。
y_test = y_test.astype('int') print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred))
从以上混淆矩阵和分类报告中可以看出,该模型在类别0(垃圾邮件)和类别1(正常邮件)上的预测表现非常好,具有较高的精确度、召回率和F1分数。
总体而言,模型的准确度为98%,表明其在大多数情况下能够正确分类样本。
9、绘制ROC曲线
y_pred_prob = classifierModel.predict_proba(x_testFeat) fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred_prob[:,1]) auc = metrics.auc(fpr, tpr) print(auc)auc = 0.9865808571819801
plt.rcParams['font.sans-serif'] = ['Heiti TC'] plt.rcParams['axes.unicode_minus'] = False plt.plot(fpr, tpr, lw = 2, label = 'ROC曲线(面积 = {:.2f})'.format(auc)) plt.plot([0,1],[0,1],'r--') plt.xlabel('假正例率') # False Positive Rate plt.ylabel('真正例率') # True Positive Rate plt.title('ROC曲线示例') # Receiver operating characteristic example plt.legend(loc = 'lower right') plt.show()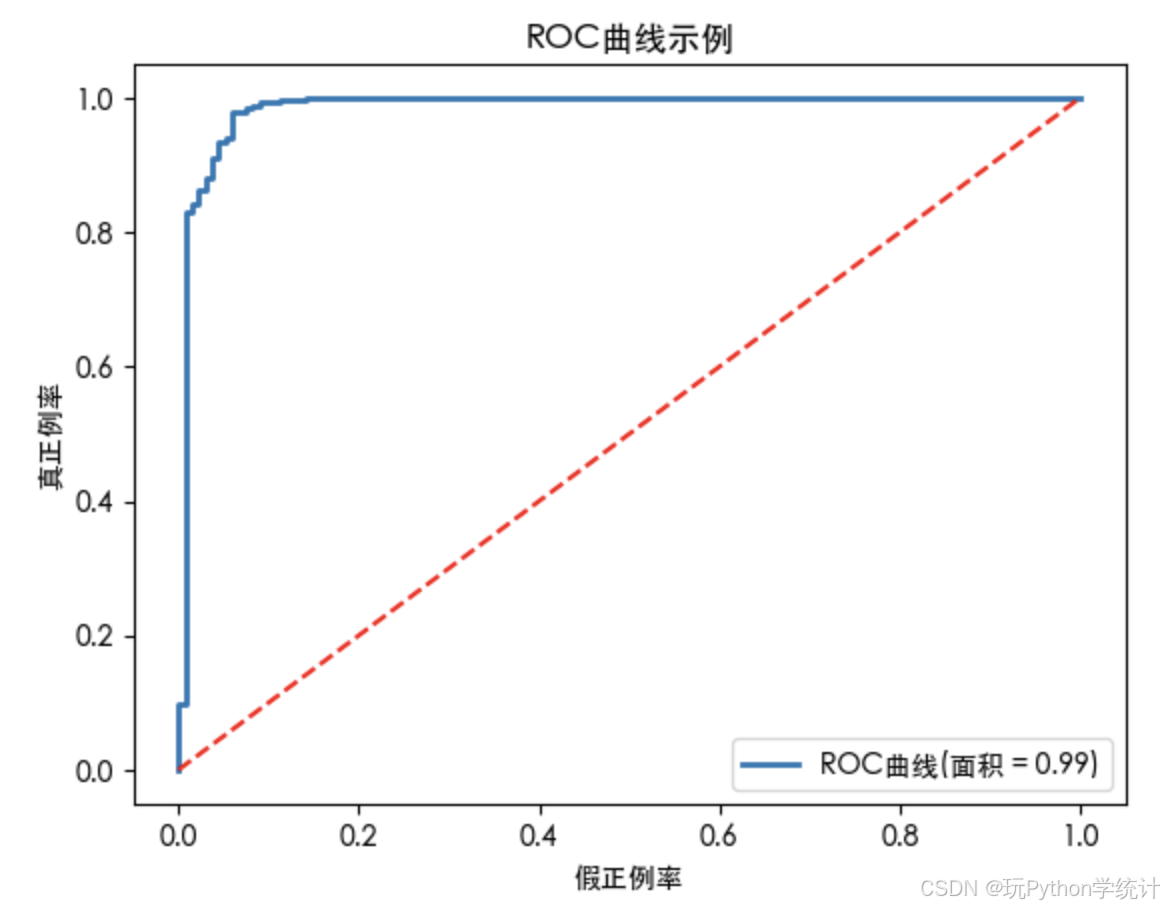
图片中的ROC曲线示例展示了一个具有较高AUC值的分类器的性能,表明该模型在区分正负类方面表现良好。
都读到这里了,不妨关注、点赞一下吧!
