
目录
一、缓存穿透
1、问题描述
缓存穿透指的是⼤量请求的 key根本不存在于缓存中,每次针对此key的请求从缓存获取不到,请求都会到压到数据库,从而可能压垮数据源
简而言之:用户访问的数据既不在缓存当中,也不在数据库中
比如:一个不存在的用户id,获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能会压垮数据库

2、解决方案
一个key不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且处于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据请求都要存储层去查询,失去了缓存的意义
-
设置
空缓存(null)或默认值:如果一个查询返回的数据为空(不管是数据是否不存在),仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过5分钟
public Object getObjectInclNullById(Integer id) { // 从缓存中获取数据 Object cacheValue = cache.get(id); // 缓存为空 if (cacheValue == null) { // 从数据库中获取 Object storageValue = storage.get(key); // 缓存空对象 cache.set(key, storageValue); // 如果存储数据为空,需要设置一个过期时间5分钟(300秒) if (storageValue == null) { // 必须设置过期时间,否则有被攻击的风险 cache.expire(key, 60 * 5); } return storageValue; } return cacheValue; } 2.使用布隆过滤器过滤请求:
布隆过滤器可以非常方便地判断一个给定的key数据是否存在海量数据中,是由二进制向量(位数组)和随机映射函数(Hash函数),比平时使用的List、Map、Set等数据结构占用少,不容易删除,但是返回的结果是概率性的
布隆过滤器,就是一种数据结构,它是由一个长度为m个bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0
在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中了
例如:一共有3个key,我们对这3个key分别进行3次hash运算,key1经过三次hash运算后的结果分别为2/6/10,那么就把布隆过滤器中下标为2/6/10的元素值更新为1,然后再分别对key2和key3做同样操作,结果如下图:

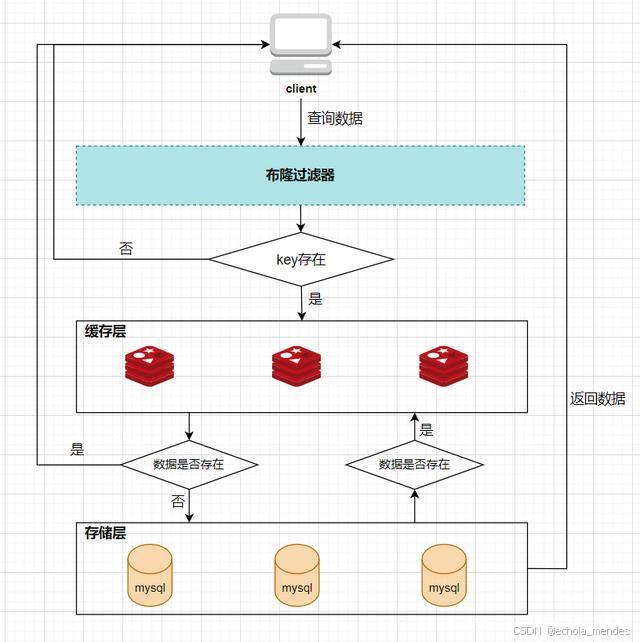
这样,当客户端查询时,也对查询的key做3次hash运算得到3个位置,然后看布隆过滤器中对应位置元素的值是否为1,如果所有对应位置元素的值都为1,就证明key在库中存在,则继续向下查询;如果3个位置中有任意一个位置的值不为1,那么就证明key在库中不存在,直接返回客户端空即可

当客户端查询key4时,key4的3次hash运算中,有一个位置8的值为0,就说明key4在库中不存在,直接返回客户端空即可
所以,布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在,加入布隆过滤器之后的缓存处理流程图如下:
3.接口限流:根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单
也可以使用布隆过滤器的bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
二、缓存击穿
1、问题描述
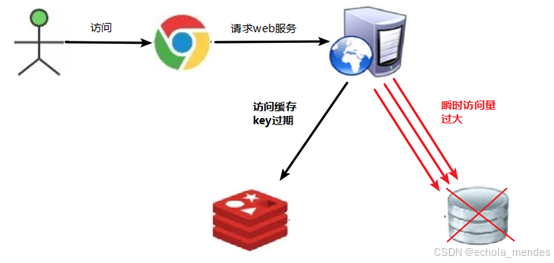
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期,一般都会从后端DB中加载数据并回设到缓存,这个时候并发的请求可能会瞬间把后端DB压垮
简而言之:用户访问的数据存在于数据库中,但不存在缓存中(通常是因为缓存中的数据已经过期)
2、解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
缓存击穿中,请求的 key 对应的是 热点数据
解决问题:
-
设置热点数据永不过期或者过期时间比较长:热点数据不设置过期时间,后台异步更新缓存,适用于不严格要求缓存一致性的场景
-
预先设置热点数据:在Redis高峰访问之前,把热门数据提前存入缓存并设置合理的过期时间。比如秒杀场景下的数据在秒杀结束之前不过期 -
互斥锁:
请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力-
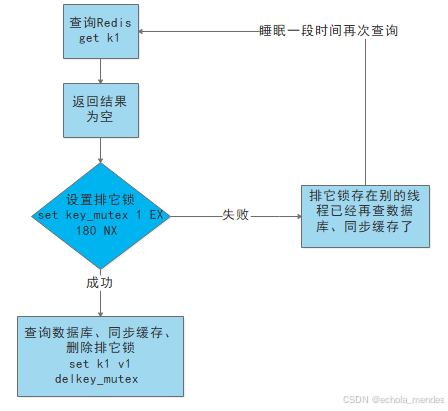
就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
-
先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key。
-
当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
-
当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
-
三、缓存雪崩
1、问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
简而言之:缓存在同一时间大面积的失效,无法在Redis缓存中进行处理,导致大量的请求都直接落到了数据库上,对数据库压力激增
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key
正常访问:
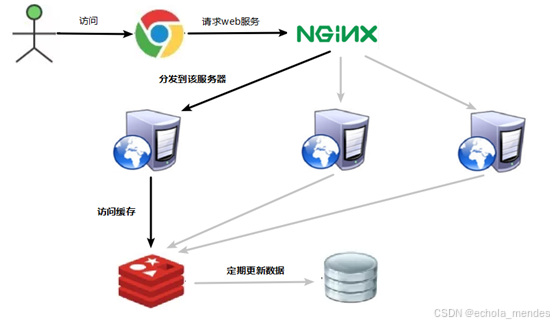
缓存失效:

2、解决方案
产生缓存雪崩的两种情况:
-
大量数据同时失效
-
Redis服务故障宕机
对于Redis服务不可用的解决方案:
-
采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
-
限流,避免同时处理大量的请求。
-
多级缓存,例如本地缓存+Redis 缓存的组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据
对于热点缓存失效的解决方案:
-
设置不同的失效时间比如随机设置缓存的失效时间。
-
缓存永不失效(不太推荐,实用性太差)。
-
缓存预热,也就是在程序启动后或运行过程中,主动将热点数据加载到缓存中
缓存预热如何实现?
常见的缓存预热方式有两种:
-
使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
-
使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存
3、雪崩案例
问题:在一次商品抢购活动中,23:00上架商品,写入缓存中,开始预热,商品的缓存时间都设置为2小时过期,那么在1:00后所有的商品在同一个时间点全部失效,瞬间所有的请求都落在数据库上,导致数据库扛不住压力崩溃,用户所有的请求都超时报错,实际上所有的请求都直接落到数据库
解决:首先通过API Gateway(网关)限制大部分流量进来,接着将宕机的数据库服务重启,再重新预热缓存(缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!) ,确认缓存和数据库服务正常后将网关流量正常放开,大约01:30 抢购活动恢复正常