
阅读量:0
百亿级存储架构: ElasticSearch+HBase 海量存储架构与实现
尼恩:百亿级数据存储架构起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
这些机会的来源,主要是尼恩给小伙伴 改造了简历,植入了亮点项目、黄金项目。
尼恩的 亮点项目、黄金项目 需要持续迭代。下一个亮点项目、黄金项目是:百亿级数据存储架构。
同时,小伙伴在面试时,经常遇到这个面试难题。比如,前几天一个小伙伴面试字节,就遇到了这道题
阿里面试:百亿级数据存储,怎么设计?
字节面试:百亿级数据存储,只是分库分表吗?
于是,尼恩组织小伙伴开始研究和 设计 《百亿级数据存储架构》,帮助大家打造一个新的黄金项目,实现大厂的梦想。
已经发布的文章包括:
100亿级任务调度篇:从0到1, 从入门到 XXLJOB 工业级使用
高并发搜索ES圣经:从0到1, 从入门到 ElasticSearch 工业级使用
超级底层:10WQPS/PB级海量存储HBase/RocksDB,底层LSM结构是什么?
一:百亿级 海量存储数据服务的业务背景
很多公司的业务数据规模庞大,在百亿级以上, 而且通过多年的业务积累和业务迭代,各个业务线错综复杂,接口调用杂乱无章,如同密密麻麻的蛛网,形成了难以理清的API Call蜘蛛网。
API 调用蜘蛛网 如图 所示:
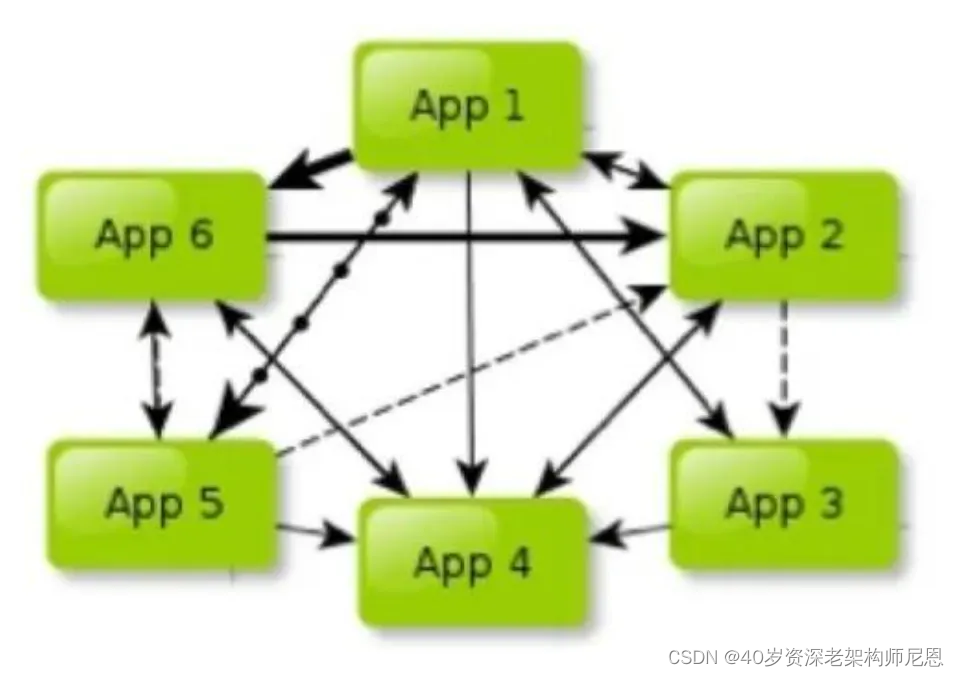
这种API 调用蜘蛛网的特点是:
第一,各个业务线互相依赖。A向B要数据,B向C请求接口,C向A需求服务,循环往复,令人目不暇接。
第二,各自为政,独立发展。各业务线各有财产,各自为营,宛如诸侯割据,拥兵自重。各自一滩、烟囱化非常严重。
第三,无休止的跑腿成本、无休止的会议沟通成本,沟通和协调成本让人望而生畏。
如何降低成本,降本增效, 迫切需要进行各个业务线的资源的整合、数据的整合、形成统一的海量数据服务,这里成为为数智枢纽(Data Intelligence Hub)服务/ 或者百亿级 数据中心服务,通过 统一的 数智枢纽(Data Intelligence Hub)服务 将这错综复杂的蜘蛛网变成简明的直线班车。
数智枢纽(Data Intelligence Hub)服务 / 或者百亿级 数据中心服务 如下图 所示:
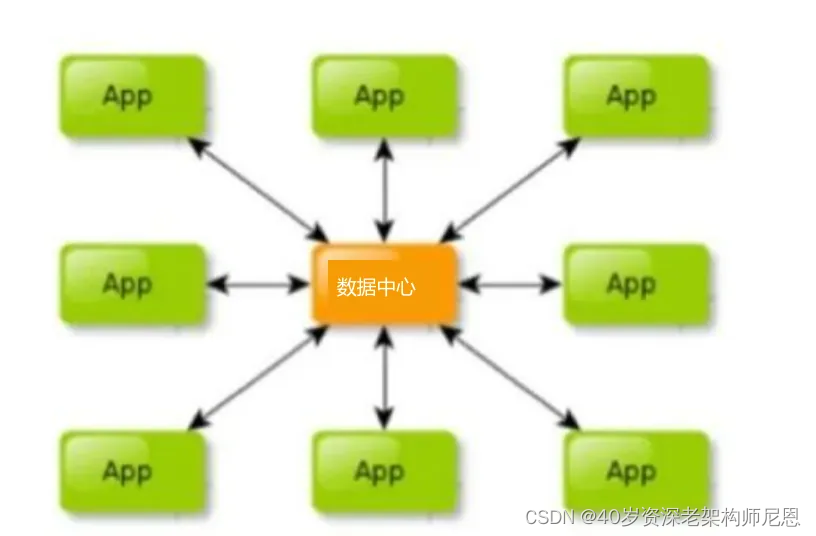
数智枢纽(Data Intelligence Hub)服务/ 或者百亿级 数据中心服务带来的几个优势:
第一,将省去不必要的接口调用。业务穿插不再混乱,减少无休止的会议沟通,解决数据难以获取、速度缓慢的问题。
第二,统一数据中心将大大节省产品和开发人员的时间,提升整体工作效率。各个业务线在新的系统下将协同作战,资源高效利用,真正实现事半功倍。
第三,进行统一的高可用优化、高并发优化,确保:稳如泰山,快如闪电。
总而言之,数智枢纽(Data Intelligence Hub)服务 的出现,将从根本上改变我们的统一数据存储和数据访问的工作方式,实现资源整合和效率提升。最终实现了: 稳如泰山,快如闪电,大气磅礴,节约成本,清晰明了。
二:架构设计与模块介绍
先看一下整体架构,整个数智枢纽(Data Intelligence Hub)服务 核心主要分为:
数据统一接入层
数据统一查询层
元数据管理
索引建立
平台监控
在线与离线数据存储层
先看一下整体架构图,如下图: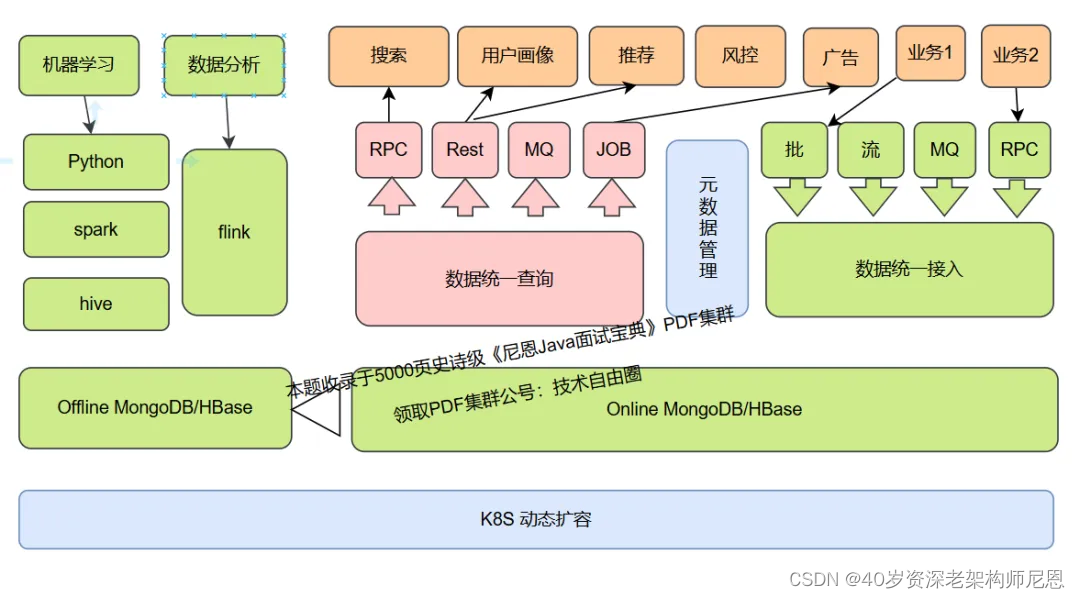
下面将分别对其进行介绍。
尼恩提示: 以上内容比较复杂, 如果需要深入了解, 请参见尼恩后续的《百亿级海量数据存储架构和实操》配套视频。
三:数据统一查询层的业务梳理
一般来说,数据统一查询层,大同小异,可以总结出以下几大常见的数据查询类型:
Key-Value查询,最简单的kv查询,并发量可能很高,速度要求快。比如风控。
Key-Map查询,定向输出,比如常见的通过文章id获取文章详情数据,kv查询升级版。
MultiKey-Map批量查询,比如常见的推荐Feed流展示,Key-Map查询升级版。
C-List多维查询查询,指定多个条件进行数据过滤,条件可能很灵活,分页输出满足条件的数据。这是非常常见的,比如筛选指定标签或打分的商品进行推荐、获取指定用户过去某段时间买过的商品等等。
G-Count统计分析查询,数仓统计分析型需求。如数据分组后的数据统计。
G-Top统计排行查询,根据某些维度分组,展示排行。如数据分组后的最高Top10帖子。
四:海量数据存储层的技术选型
解决海量数据的存储,并且能够实现海量数据的秒级查询, 首先要进行海量数据存储层的技术选型.
一般来说,有两种:
- HBase
- MongoDB
Mongodb用于存储非结构化数据,尤其擅长存储json格式的数据或者是一些很难建索引的文本数据,。
Mongodb 存储的量大概在10亿级别,再往上性能就下降了,除非另外分库。
Hbase是架构在hdfs上的列式存储,擅长rowkey的快速查询,但不擅长模糊匹配查询(其实是前模糊或全模糊),
Hbase的优势是:存储的量可以达到百亿甚至以上,比mongodb的存储量大多了。
在于写入的速度上,hbase由于只维护一个主键,写入的速度要比mongodb这种要维护所有索引的数据库快多了。
在于服务器的数量上,hbase占用两台机器能完成的事情,mongodb要占用更多的机器,每台机器按一年20000的费用,几百台下来就是一笔很大的费用。
总之:
MongoDB更擅长存储需要在线访问的NOSQL文档,并且通过索引,更善于做查询,存储能力弱。
Hbase更偏向非关系型数据库,扩展储存能力强。
所以,现在很多公司都选用HBASE,而 不选用Mongodb,因为一旦数据量过大,再去改结构很复杂。
五:数据统一查询层的架构设计
Hbase是典型的nosql,是一种构建在HDFS之上的分布式、面向列的存储系统,在需要的时候可以进行实时的大规模数据集的读写操作;
前面讲到,Hbase是架构在hdfs上的列式存储,擅长rowkey的快速查询,但不擅长模糊匹配查询(其实是前模糊或全模糊),
注意:Hbase 不擅长模糊匹配查询。
如何实现 数据统一查询层?
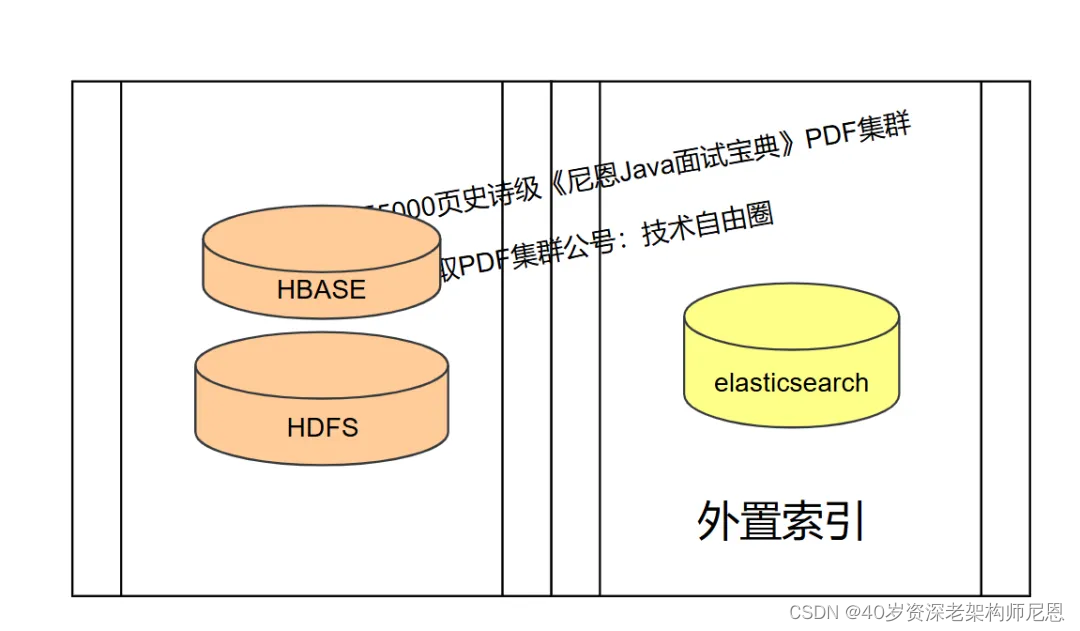
这个时候,我们就是用elasticsearch架构在hbase之上;
数据统一查询层的架构,是elasticsearch + hbase结合:
- 海量的数据存储使用hbase
- 数据的即席查询(快速检索)使用elasticsearch
最终,通过elasticsearch+hbase就可以做到海量数据的复杂查询;
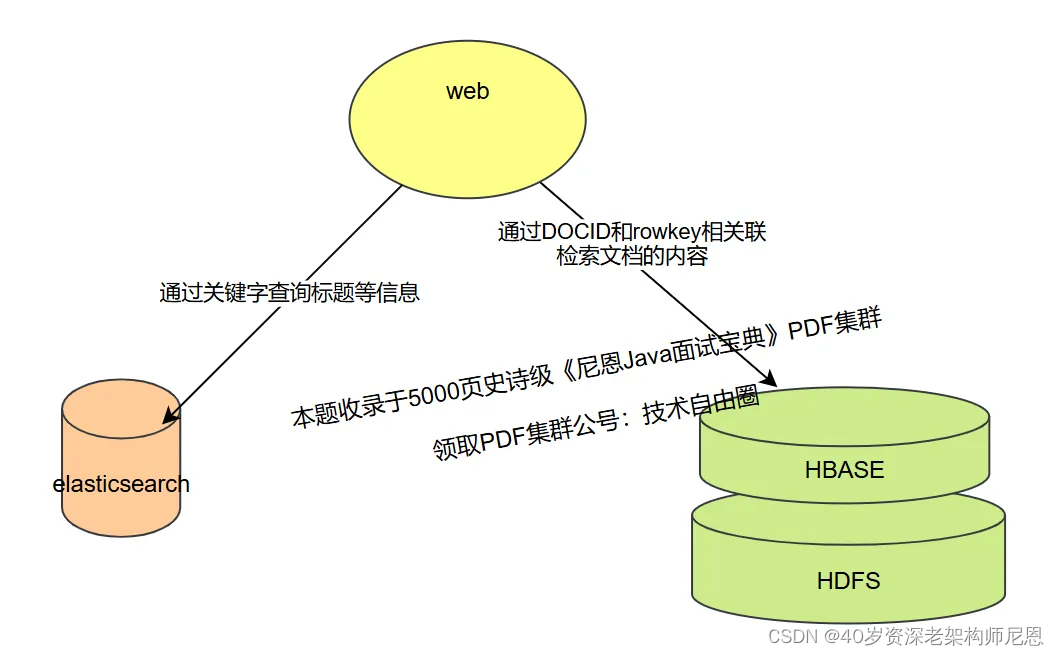
尼恩提示: 以上内容比较复杂, 如果需要深入了解, 请参见尼恩后续的《百亿级海量数据存储架构和实操》配套视频。
elasticsearch+hbase 的基本原理
很简单,将Elasticsearch的DOC ID和Hbase的rowkey相关联。
在数据接入的时候,通过构建统一的、全局唯一 ID, 既当做Elasticsearch的DOC ID, 也当做Hbase的rowkey。
在统一数据服务,构建ID,然后先写入 hbase,再发送kafka 消息, 异步写入ES。
将源数据根据业务特点划分为索引数据和原始数据:
索引数据:指需要被检索的字段,存储在Elasticsearch集群中;
原始数据:指不需要被ES检索的字段,包括某些超长的文本数据等,存储在Hbase集群中。
当然,在操作之前,我们还要考虑:
- 一批数据在elasticsearch中构建索引的时候,针对每一个字段要分析是否存储和是否构建索引;
这个就需要根据元数据进行有效的控制。
实际查询的过程是:
- 先ES根据条件查询到分页数据,或者是list里面封装的是那个所有实体类、然后遍历,
- 通过遍历到的id去查hbase,之后就可以封装Dto,然后返回List
将HBase的rowkey设定为ES的文档ID,搜索时根据业务条件先从ES里面全文检索出相对应的文档,从而获取出文档ID,即拿到了rowkey,再从HBase里面抽取数据。
elasticsearch+hbase 的优点
- 发挥了Elasticsearch的全文检索的优势,能够快速根据关键字检索出相关度最高的结果;
- 同时减少了Elasticsearch的存储压力,这种场景下不需要存储检索无关的内容,甚至可以禁用_source,节约一半的存储空间,同时提升最少30%的写入速度;
- 避免了Elasticsearch大数据量下查询返回慢的问题,大数据量下Hbase的抽取速度明显优于Elasticsearch;
- 各取所长,发挥两个组件各自的优势。
好像ES天生跟HBase是一家人,HBase支持动态列,ES也支持动态列,这使得两者结合在一起很融洽。
而ES强大的索引功能正好是HBase所不具备的,如果只是将业务索引字段存入ES中,体量其实并不大;
甚至很多情况下,业务索引字段60%以上都是Term类型,根本不需要分词。
总之, ES天生 就是hbase 的外置索引:
尼恩提示: 以上内容比较复杂, 如果需要深入了解, 请参见尼恩后续的《百亿级海量数据存储架构和实操》配套视频。
elasticsearch+hbase 的 缺点
1、两个组件之间存在时效不一致的问题
相对而言,Elasticsearch的入库速度肯定是要快于Hbase的,这是需要业务容忍一定的时效性,对业务的要求会比较高。
2、同时管理两个组件增加了管理成本
显而易见,同时维护两套组件的成本肯定是更大的。 当然,既然是百亿级数据,这点维护人员还是要有的。
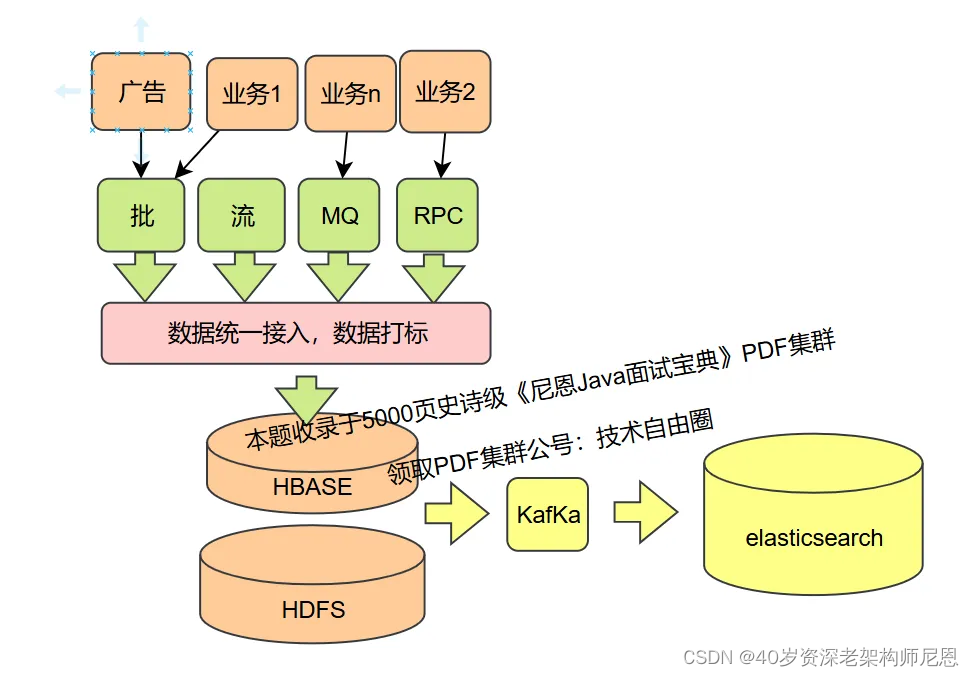
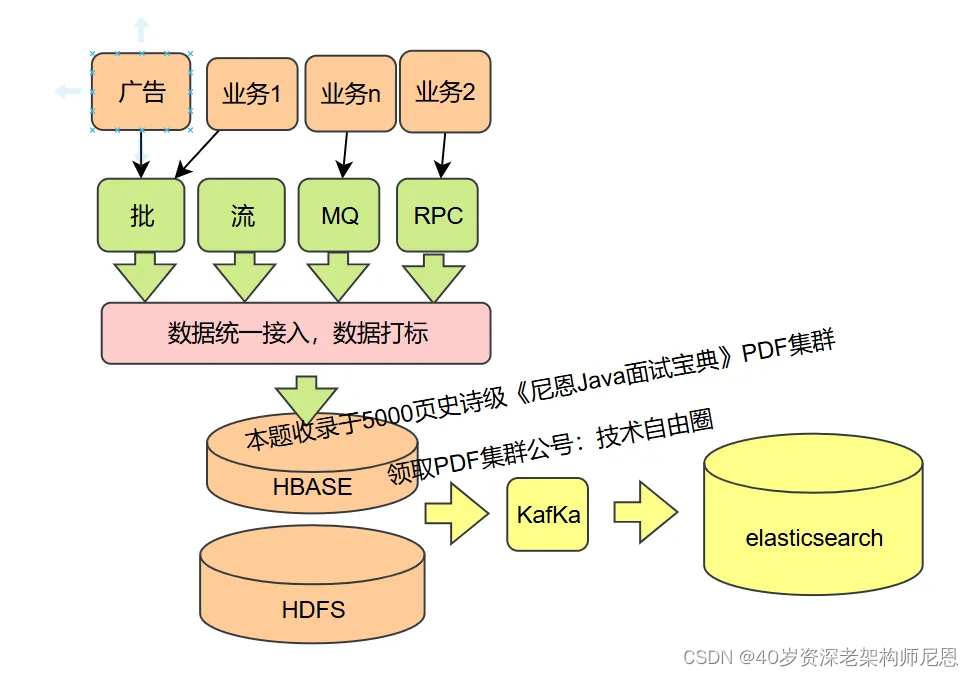
六:数据统一接入服务介绍
数据统一接入服务,在springboot中,通过HBase-Client API进行了二次轻封装,支持在线RESTFUL服务接口和离线SDK包两种主要方式对外提供服务。
为了提升吞吐量,数据统一接入服务可以兼容HBase原生API和HBase BulkLoad大批量数据写入。
当然,数据统一接入服务需要做很多工作,比如
- 统一id的生成
- 权限管理
- 负载均衡
- 失败恢复
- 动态扩缩容
- 数据接口监控
- 等等。
在数据统一接入服务中,为了适应不同的数据源和业务需求,主要涉及三种接入模式:
- 定时拉取
- REST实时推送
- 消息队列(MQ)推送。
以下是对这三种模式的详细介绍:
1. 定时拉取
- 定时任务: 系统按照预设的时间间隔,定时从数据源拉取数据。
- 数据同步: 适用于数据变化不频繁、实时性要求不高的场景,如批量数据同步和周期性报告生成。
- 任务调度: 使用调度器(如Quartz)来管理和执行定时任务。
定时拉取实现方式,大致如下:
- 配置定时任务: 设置任务调度器的时间间隔和拉取频率。
- 数据拉取: 编写数据拉取逻辑,通过API、数据库查询等方式从数据源获取数据。
- 数据处理: 对拉取的数据进行清洗、转换和存储。
- 日志和监控: 记录拉取过程的日志,监控任务执行情况。
2. REST实时推送
- 实时推送: 数据源在数据产生或变化时,立即通过REST API推送数据到接入服务。
- 事件驱动: 适用于数据变化频繁、实时性要求高的场景,如实时监控和即时通知。
- API接口: 提供统一的REST API接口,供数据源调用进行数据推送。
REST实时推送的实现方式主要如下:
- 定义API接口: 设计和实现数据接收的REST API。
- 数据接收: 编写接收数据的逻辑,处理并存储推送的数据。
- 数据验证: 对接收的数据进行验证,确保数据完整性和正确性。
- 响应处理: 返回接收结果,处理异常情况。
3. MQ异步推送
- 消息队列: 使用消息队列(如RabbitMQ、Kafka)进行数据推送,保证数据传输的可靠性和可扩展性。
- 异步处理: 适用于高并发、大数据量的接入场景。
- 解耦设计: 生产者和消费者解耦,提升系统的灵活性和可维护性。
MQ异步推送的实现方式主要如下:
- 配置消息队列: 设置消息队列服务器和相关配置。
- 消息生产者: 数据源作为消息生产者,将数据发送到消息队列。
- 消息消费者: 接入服务作为消息消费者,从消息队列中获取并处理数据。
- 数据处理: 对获取的数据进行清洗、转换和存储。
这三种接入模式各有优劣,选择合适的模式需要根据具体的业务需求和场景进行评估:
- 定时拉取:适用于数据变化不频繁、实时性要求不高的场景,实施简单、易于管理。
- REST实时推送:适用于数据变化频繁、实时性要求高的场景,适合事件驱动的系统设计。
- MQ推送:适用于高并发、大数据量的场景,通过异步处理和解耦设计,提升系统的扩展性和可靠性。
综合使用这三种模式,可以构建一个高效、灵活、可扩展的数据统一接入服务。
七:元数据管理服务的架构设计
元数据管理服务 主要就是对接我们上文业务梳理模块归纳的各种业务需求,都由此模块提供服务。
顾名思义,元数据管理服务 提供两个方面的元数据管理:
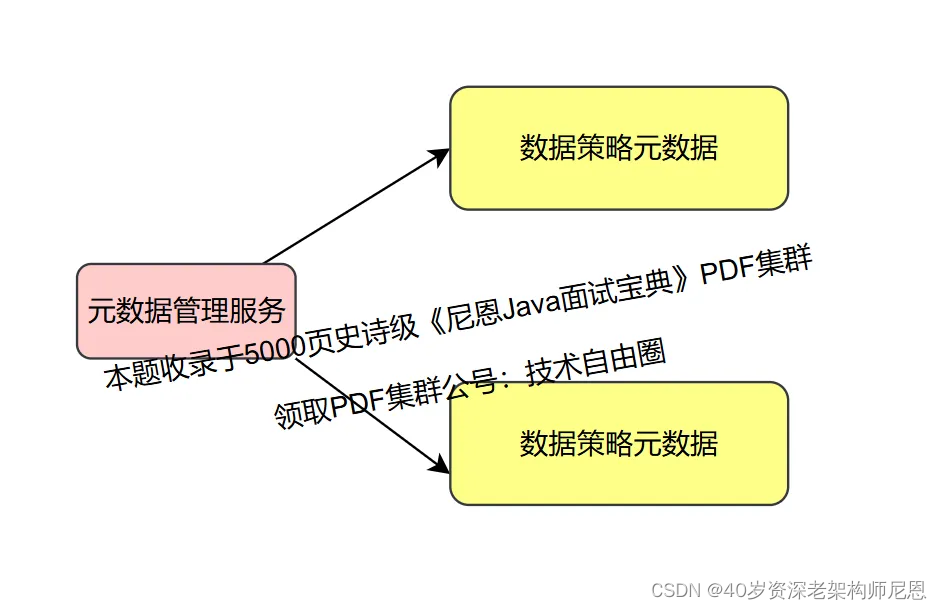
无论是存储策略元数据还是查询策略元数据,主要用于为用户配置策略,或用户自己配置策略,最终基于策略生成策略ID。
虽然 HBase和ES一样,也是No-Schema模型,是可以动态创建字段的,但是元数据管理服务 还是 为其HBase和ES做一个显示的 Schema管理,同时去动态控制哪些字段要建索引。
无论是存储策略元数据还是查询策略元数据,主要是对ElasticSearch和HBase的meta data/表结构的一些抽象/封装,然后在创建 hbase Table /ES document 结构的时候,或者读取 hbase Table /ES document 的时候进行动态映射 。
另外,在查询ES的时候,会通过动态模板将用户请求转化为ElasticSearch DSL语句,而后对ES进行查询,直接返回数据或是获取到rowkey进而查询HBase进行结果返回。
通过元数据管理中心,我们可以判断出用户所需字段是否被索引字段覆盖,是否有必要二次查询HBase返回结果。而这整个查询过程,用户并不会感知,他们只需要一个PolicyID即可。
当然,我们也在不断普及用户如何通过后台自己配置生成策略。
合作较多的业务方,甚至可以自己在测试环境配置好一切,完成数据的自助获取工作。而我们需要做的,只是一键同步测试环境的策略到线上环境,并通知他们线上已可用。
通过元数据管理服务的架构设计,可以快速的配置各种数据查询接口,整个过程5~10分钟,一个新的接口就诞生了。
其次,由于ES抗压能力并不是太强,这里可以引入redis 缓存,策略接口也会根据业务需求决定是否开启 redis 缓存。
事实上,大部分接口是可以接受短时间内数据缓存的。
当然,像简单KV、Key-Map 这种是直接走HBase的,并不需要缓存。
为啥? 因为Hbase的吞吐量很高,有关HBase的吞吐量,具体可以参考尼恩的《Hbase学习圣经》。
总之,由于ES的DSL功能丰富,通过元数据管理服务的策略配置,可以动态支持分词查询、分桶查询、多表联合查询、TopN、聚合查询等多种复合查询等等。
通过元数据管理服务 ,维护一套元数据方便我们做一些简单的页面指标监控,并对ES和HBase有一个总的控制(如建表删表等)。
其次,,可以在数据接入的时候,我们会通过元数据中心判断数据是否符合表和索引的规则;在数据输出的时候,我们控制哪些策略需要走缓存,哪些策略不需要走HBase等等。
尼恩提示: 以上内容比较复杂, 如果需要深入了解, 请参见尼恩后续的《百亿级海量数据存储架构和实操》配套视频。
八. HBase 和 ES 的数据一致性架构
HBase 和 ES 的数据一致性,有两种方案:
- HBase + WAL + ES
- HBase + Kafka + ES
方式一:HBase + WAL + ES 实现数据一致性
Hbase在底层是以K-V类型存储的。
每条数据的每个属性都会保存一条记录,由于HDFS不支持随机写操作,所以当修改属性时,不会修改记录,而是插入一条新的记录,每条记录除了包含数据的属性外,还包含一个[时间戳(TimeStamp)表示数据更新时的时间,一个数据类型(Type)表示数据时修改还是删除或者是插入等。如:
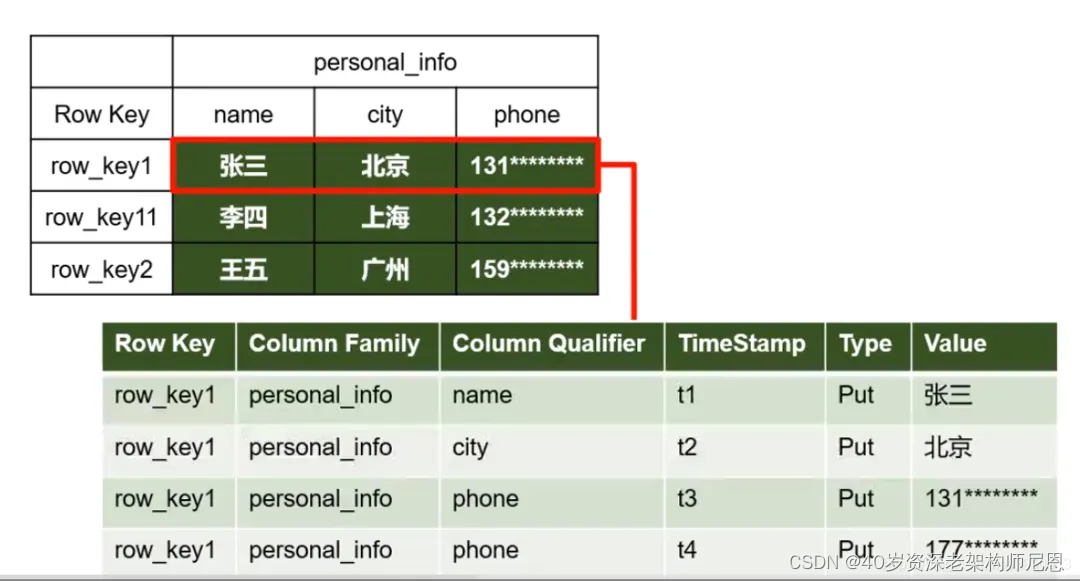
row key为row_key1的这条数据,初始情况下在底层实际上存储了三条记录,分别记录了这条数据的name、city、phone属性,当要修改数据的phone属性时,则再插入一条记录表示新的phone属性,根据时间戳判断最新的那条记录有效。
预写日志WAL
WAL(Write-Ahead Log)预写日志是一个保险机制。
当向Hbase写入一条数据时,Hbase首先会将数据写入WAL,然后再把数据放入内存中(Memstore),而不会立即落盘。
当查询时也是先在内存中查询,如果内存中没有查询到,才会在磁盘中进行查询。
当Memstore中的数据达到一定的量时,才刷写(flush)到最终存储的HFile内。
而如果在这个过程中服务器宕机或者断电了,那么数据就丢失了。
但是有了WAL机制,在Hbase将数据写入Memstore前就先写入了WAL,这样当发生故障后,就可以通过WAL将丢失的数据恢复回来。
WAL是一个环状的滚动日志结构,这种结构写入效果最高,而且可以保证空间不会持续变大。
WAL的检查间隔由hbase.regionserver.logroll.period定义,默认值为1小时。
检查的内容是把当前WAL中的操作跟实际持久化到HDFS上的操作比较,看哪些操作已经被持久化了,被持久化的操作就会被移动到.oldlogs文件夹内(这个文件夹也是在HDFS上的)。
一个WAL实例包含有多个WAL文件。WAL文件的最大数量通过hbase.regionserver.maxlogs(默认是32)参数来定义。
WAL是默认开启的,也可以选择关闭或延迟(异步)同步写入WAL。
HBase + WAL + ES 实现数据一致性 实现步骤
设置 HBase 的 WAL 日志位置: 在 HBase 的配置文件
hbase-site.xml中配置 WAL 日志路径。xml复制代码<property> <name>hbase.regionserver.hlog.dir</name> <value>/hbase/wal</value> </property>编写 WAL 日志解析服务: 编写一个独立的服务,定期读取 WAL 日志文件,解析其中的写操作,并同步到 Elasticsearch。
同步到 Elasticsearch: 在解析服务中,将提取的数据变更信息写入到 Elasticsearch。
HBase + WAL + ES 实现数据一致性 方案的问题:
- WAL层不太好控制和监控,
- ES消费WAL的存在效率问题
- 总之,WAL层数据一致性不好维护。
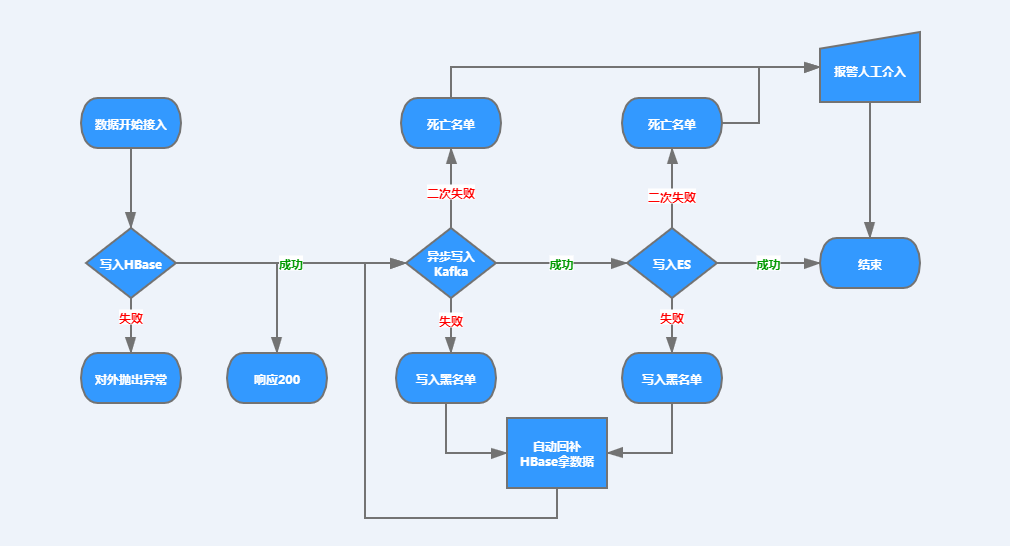
方式二:HBase + kafka+ ES 实现数据一致性
HBase + kafka+ ES 实现数据一致性 方案,如下图:
数据接入层在数据写完HBase之后,即对外响应Success,并异步将数据推至Kafak队列中等待ES去二次消费;写入ES失败则对外抛出异常
这里,首先要保证的是,写入HBase要么成功,要么失败。
在ES消费层,我们是可以动态指定消费线程数量的。当Kafka Lag堆积超过一定阈值(阈值可进行Group级调节和监控),会进行警报,并动态调整消费线程数。
由于使用了异步架构,只保证数据最终一致性。
当数据写入HBase成功之后,会对写Kafka和写ES进行链路追踪,任何一个环节一旦写入失败,即将Failed Key写入黑名单(Redis存储)。
对于进入黑名单的数据,我们会起定时调度线程去扫描这些Key并进行自动回补索引。
回补方式是:到HBase中拿最新的数据再次写入队列中去。
如果此时又失败,会把这些Key放入终极死亡名单(Redis存储),并通过定时调度线程去扫描这个死亡名单,如果有尸体,则报警,此时人力介入。
方便大家理解,简单画了一下这个流程,见下图:
九:hbase集群间数据同步replication
先看一下整体架构图,咱们有两个hbase集群, 如下图: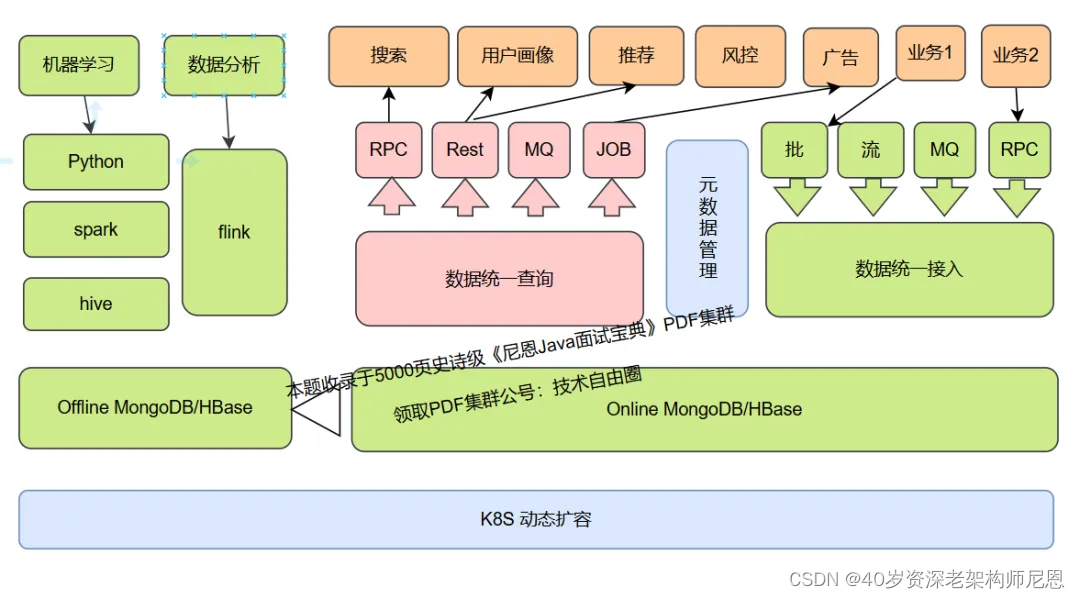
一个是 在线计算,一个负责离线计算,两个集群之间,需要数据复制。
HBase 提供了内置的复制机制,可以在不同的 HBase 集群之间同步数据。这种机制称为 HBase Replication,它允许将数据从一个 HBase 集群复制到另一个 HBase 集群,通常用于数据备份、灾难恢复、多数据中心部署等场景。
Replication: 复制,指的是持续的将同一份数据拷贝到多个地方进行存储,是各种存储系统中常见而又重要的一个概念,
可以指数据库中主库和从库的复制,也可以指分布式集群中多个集群之间的复制,还可以指分布式系统中多个副本之间的复制。
它的难点在于数据通常是不断变化的,需要持续的将变化也反映到多个数据拷贝上,并保证这些拷贝是完全一致的。
HBase 的复制机制基于 WAL(Write-Ahead Log)。当数据写入到主集群(Master Cluster)时,写操作首先被记录到 WAL 中,然后这些 WAL 日志被传输到从集群(Slave Cluster),从集群再根据这些日志进行数据重放,从而实现数据同步。
通常来说,数据复制到多个拷贝上有如下好处:
- 多个备份提高了数据的可靠性
- 通过主从数据库/主备集群之间的复制,来分离OLTP和OLAP请求
- 提高可用性,即使在单副本挂掉的情况下,依然可以有其他副本来提供读写服务
- 可扩展,通过增加副本来服务更多的读写请求
- 跨地域数据中心之间的复制,Client通过读写最近的数据中心来降低请求延迟
HBase中的Replication指的是主备集群间的复制,用于将主集群的写入记录复制到备集群。HBase目前共支持3种Replication:
- 异步Replication
- 串行Replication
- 同步Replication
此篇文章介绍的是:第一种,异步Replication。
首先看下官方的一张图:
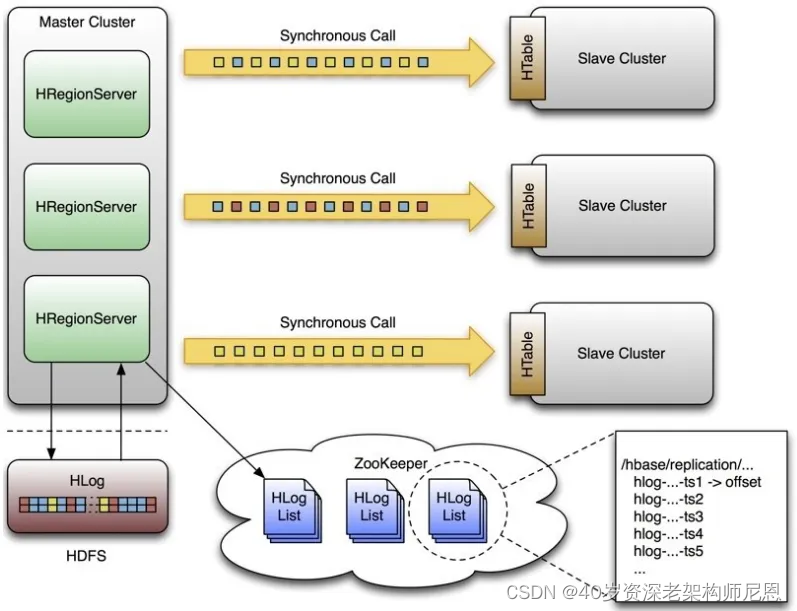
需要声明的是,HBase的replication是以Column Family为单位的,每个Column Family都可以设置是否进行replication。
上图中,一个Master对应了3个Slave,Master上每个RegionServer都有一份HLog,在开启Replication的情况下,
每个RegionServer都会开启一个线程用于读取该RegionServer上的HLog,并且发送到各个Slave,Zookeeper用于保存当前已经发送的HLog的位置。
Master与Slave之间采用异步通信的方式,保障Master上的性能不会受到Slave的影响。
用Zookeeper保存已经发送HLog的位置,主要考虑在Slave复制过程中如果出现问题后重新建立复制,可以找到上次复制的位置。
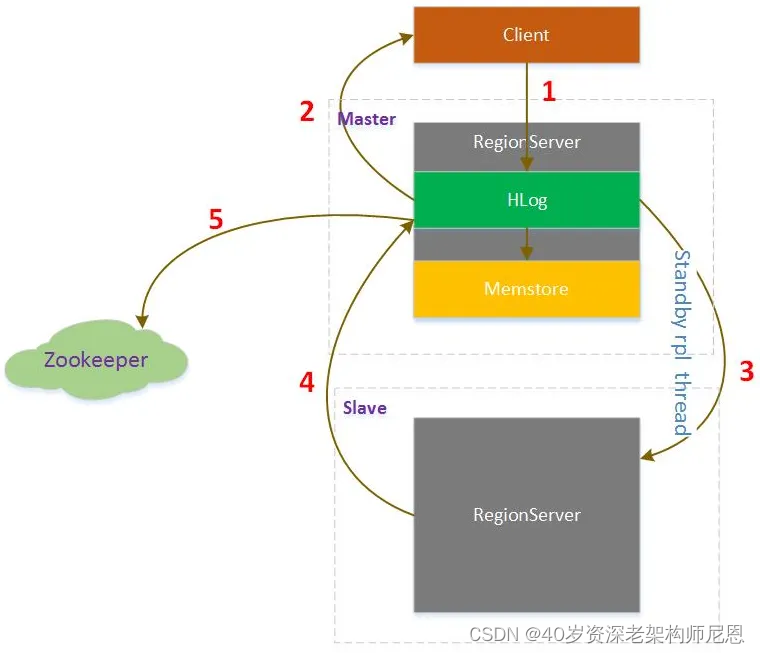
HBase Replication步骤:
- HBase Client向Master写入数据
- 对应RegionServer写完HLog后返回Client请求
- 同时replication线程轮询HLog发现有新的数据,发送给Slave
- Slave处理完数据后返回给Master
- Master收到Slave的返回信息,在Zookeeper中标记已经发送到Slave的HLog位置
注: 在进行replication时,Master与Slave的配置并不一定相同,比如Master上可以有3台RegionServer,Slave上并不一定是3台,Slave上的RegionServer数量可以不一样,数据如何分布这个HBase内部会处理。
十: 平台监控模块介绍
平台监控模块,主要包括基础平台的监控 ,应用平台监控。
基础平台的监控 包括 Hadoop集群、HBase集群的监控,外加K8S平台监控。
应用平台监控 包括数据 配置/ 数据统一接入 / 数据统一存储 /数据统一服务 的监控。
应用平台监控 主要基于Prometheus+Grafana+ Alertmananger 实现, 具体请参见尼恩的 《Prometheus 学习圣经》 pdf。
从0到1, 百亿级数据存储架构,怎么设计?
从0到1, 百亿级数据存储架构,40岁老架构尼恩团队,计划用一个系列的文章帮大家实现这个架构难题,这个系列还会录成视频,并辅导大家写入简历。
这个系列包括:
- 高并发搜索ES圣经:从0到1, 从入门到 ElasticSearch 工业级使用
- 100亿级任务调度篇:从0到1, 从入门到 XXLJOB 工业级使用(已经发布)
- 100亿级海量存储篇:从0到1, 从入门到 HABSE 工业级使用
- 100亿级离线计算篇:从0到1, 从入门到 Flink 工业级使用
已经发布的文章包括:
100亿级任务调度篇:从0到1, 从入门到 XXLJOB 工业级使用
高并发搜索ES圣经:从0到1, 从入门到 ElasticSearch 工业级使用
超级底层:10WQPS/PB级海量存储HBase/RocksDB,底层LSM结构是什么?
参考文献
https://developer.aliyun.com/article/1335139
https://blog.csdn.net/wudingmei1023/article/details/103914052
https://blog.csdn.net/sdksdk0/article/details/53966430
http://www.infocomm-journal.com/bdr/article/2017/2096-0271/2096-0271-3-1-00080.shtml
https://www.cnblogs.com/gaoxing/p/5267512.html
另外,尼恩也给一线企业提供 《DDD 的架构落地》企业内部培训,目前给不少企业做过内部的咨询和培训,效果非常好。

尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓
