
阅读量:0
数据仓库【5】:项目实战
1、项目概述
1.1、项目背景
- 某电商企业,因数据积存、分析需要,筹划搭建数据仓库,提供数据分析访问接口
- 项目一期需要完成数仓建设,并完成用户复购率的分析计算,支持业务查询需求
1.2、复购率计算
- 复购率是指在一段时间间隔内,多次重复购买产品的用户,占全部人数的比率
- 统计各个一级品类下,品牌月单次复购率,和多次复购率

2、数据描述




3、架构设计
3.1、数据仓库架构图
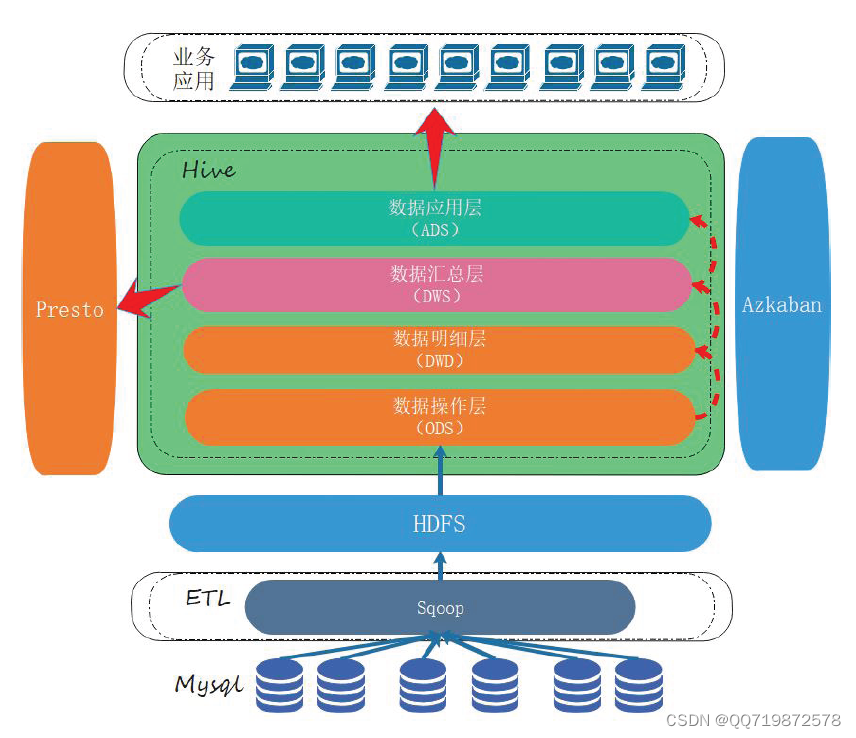
4、环境搭建
4.1、环境说明
- 操作系统及组件版本
| Centos | Hadoop | Hive | Tez | Mysql | Sqoop | Azkaban | Presto | |
|---|---|---|---|---|---|---|---|---|
| 版本 | 7 | 2.7.7 | 1.2.1 | 0.9.1 | 5.7.28 | 1.4.6 | 2.5.0 | 0.196 |
4.2、集群规划
- 使用3台虚拟机进行搭建
| Hadoop | Hive&Tez | Mysql | Sqoop | Azkaban | Presto | |
|---|---|---|---|---|---|---|
| node01 | √ | √ | √ | |||
| node02 | √ | √ | √ | √ | ||
| node03 | √ | √ | √ | √ | √ |
4.3、搭建流程
1、安装并准备3台CentOS7.2虚拟机,主机名命名为node01、node02、node03
2、上传自动化安装脚本automaticDeploy.zip到虚拟机node01中
3、解压automaticDeploy.zip到/home/hadoop/目录下
unzip automaticDeploy.zip -d /home/hadoop/ 4、更改frames.txt文件,配置组件的安装节点信息
# 通用环境 jdk-8u144-linux-x64.tar.gz true azkaban-sql-script-2.5.0.tar.gz true # Node01 hadoop-2.7.7.tar.gz true node01 # Node02 mysql-rpm-pack-5.7.28 true node02 azkaban-executor-server-2.5.0.tar.gz true node02 azkaban-web-server-2.5.0.tar.gz true node02 presto-server-0.196.tar.gz true node02 # Node03 apache-hive-1.2.1-bin.tar.gz true node03 apache-tez-0.9.1-bin.tar.gz true node03 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz true node03 yanagishima-18.0.zip true node03 # Muti apache-flume-1.7.0-bin.tar.gz true node01,node02,node03 zookeeper-3.4.10.tar.gz true node01,node02,node03 kafka_2.11-0.11.0.2.tgz true node01,node02,node03 5、编辑configs.txt文件,配置mysql、keystore密码信息
# Mysql相关配置 mysql-root-password DBa2020* END mysql-hive-password DBa2020* END mysql-drive mysql-connector-java-5.1.26-bin.jar END # azkaban相关配置 azkaban-mysql-user root END azkaban-mysql-password DBa2020* END azkaban-keystore-password 123456 END 6、编辑host_ip.txt文件,添加3个虚拟机节点信息
192.168.0.200 node01 root 123456 192.168.0.201 node02 root 123456 192.168.0.202 node03 root 123456 7、对/home/hadoop/automaticDeploy/下的hadoop、systems所有脚本添加执行权限
chmod +x /home/hadoop/automaticDeploy/hadoop/* /home/hadoop/automaticDeploy/systems/* 8、执行systems/batchOperate.sh脚本,完成环境初始化
/home/hadoop/automaticDeploy/systems/batchOperate.sh 9、根据安装需要,执行hadoop目录下对应的组件安装脚本
/home/hadoop/automaticDeploy/hadoop/installHadoop.sh 10、将自动化脚本分发到其他两个节点,并分别执行batchOperate.sh和组件安装脚本
scp -r automaticDeploy root@192.168.0.201:/home/hadoop/ scp -r automaticDeploy root@192.168.0.202:/home/hadoop/ 11、在所有虚拟机节点source环境变量文件
source /etc/profile 12、启动hadoop环境,并检查是否启动成功
hadoop namenode -format start-all.sh 5、项目开发
整体开发流程
1、业务数据生成
2、ETL数据导入
3、创建ODS层,并完成HDFS数据接入
4、创建DWD层,并完成ODS层数据导入
5、创建DWS层,导入DWD层数据
6、创建ADS层,完成复购率计算
7、编写脚本,将ADS层的数据导出到Mysql中,供业务查询
8、使用Azkaban调度器,实现脚本自动化运行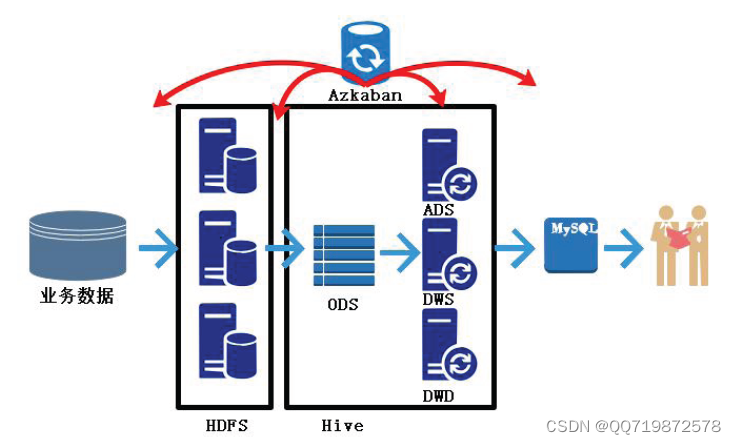
5.1、业务数据生成
- 进入Mysql,创建数据库Mall
export MYSQL_PWD=DBa2020* mysql -uroot -e "create database mall;" - 上传数据生成sql脚本到Mysql安装节点
- 使用命令方式,将数据生成sql脚本导入到Mysql中
mysql -uroot mall < {pathToSQL} - 进入Mysql,生成数据
use mall; #生成日期2020-06-10日数据、订单300个、用户200个、商品sku300个、不删除数据 CALL init_data('2020-06-10',300,200,300,FALSE); 5.2、ETL数据导入
- 进入Sqoop安装节点,创建/home/warehouse/shell目录
mkdir –p /home/warehouse/shell - 编写Sqoop数据导入脚本,脚本内容见材料
cd /home/warehouse/shell vim sqoop_import.sh - 赋予脚本执行权限,并运行脚本
chmod +x /home/warehouse/shell/sqoop_import.sh ./sqoop_import.sh all 2020-06-10 - 通过Web界面查看HDFS的/origin_data/mall/db/目录下是否存在导入数据
5.3、ODS层创建&数据接入
- 进入Hive安装节点,启动Hive元数据服务
hive --service hiveserver2 & hive --service metastore & - 在/home/warehouse/sql目录下编写ods_ddl.sql,创建与业务数据库一致的数据表
vim /home/warehouse/sql/ods_ddl.sql - 将ods_ddl.sql导入到Hive中
hive -f /home/warehouse/sql/ods_ddl.sql - 在/home/warehouse/shell/目录下编写ods_db.sh脚本,完成数据导入操作
vim /home/warehouse/shell/ods_db.sh - 为脚本赋权,并执行
chmod +x /home/shell/warehouse/ods_db.sh ods_db.sh 2020-06-10 5.4、DWD层创建&数据接入
DWD层分析
- 对ODS层数据进行清洗、维度退化
- 因业务库数据质量高,所以只需要去空数据即可
- 分类表可以进行维度退化,维度合并到商品表中

- 在/home/warehouse/sql目录下编写dwd_ddl.sql,创建DWD层数据表
vim /home/warehouse/sql/dwd_ddl.sql - 将dwd_ddl.sql导入到Hive中
hive -f /home/warehouse/sql/dwd_ddl.sql - 在/home/warehouse/shell目录下编写dwd_db.sh脚本,完成数据导入操作
vim /home/warehouse/shell/dwd_db.sh - 为脚本赋权,并执行
chmod +x /home/warehouse/shell/dwd_db.sh ./dwd_db.sh 2020-06-10 - 查看是否执行成功
select * from dwd_sku_info where dt='2020-06-10' limit 2; 5.5、DWS层创建&数据接入
DWS层分析
- 将具有相同分析主题的DWD层数据,聚合成宽表模型,便于数据分析与计算
- 主题的归纳具有通用性,后续也可能会随着分析业务的增加而扩展
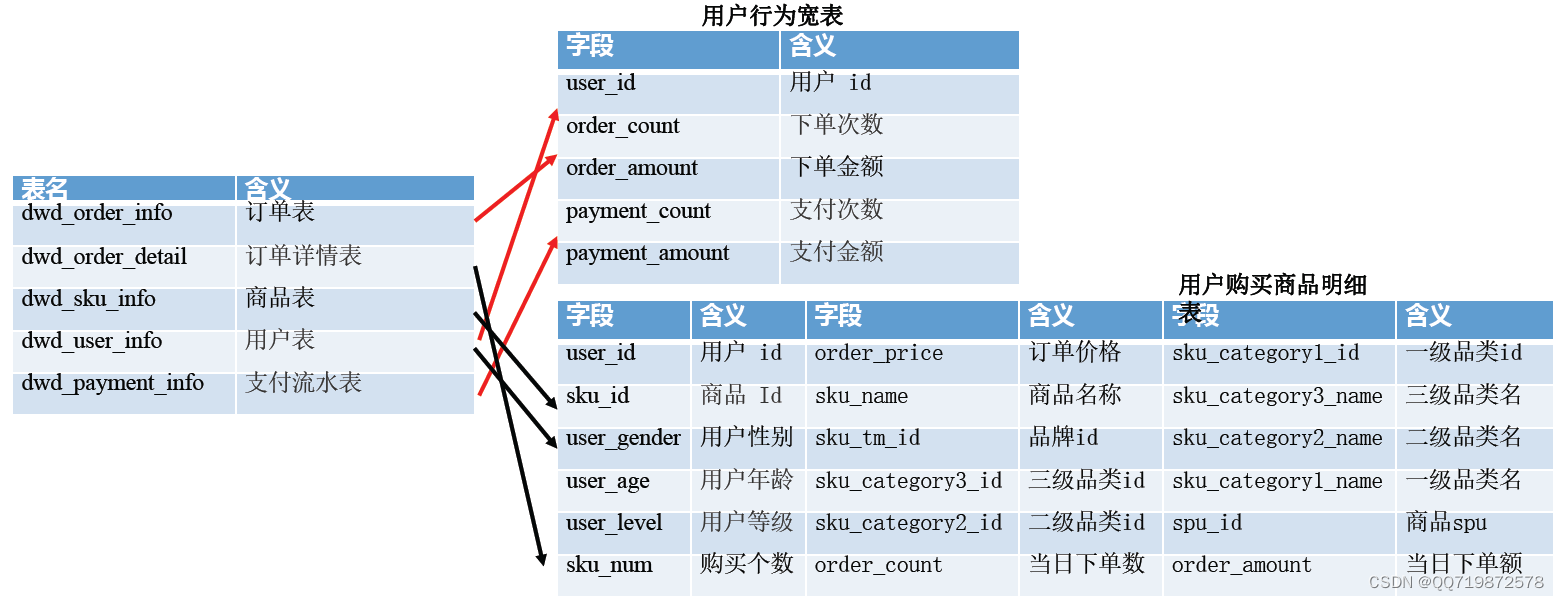
- 在/home/warehouse/sql目录下编写dws_ddl.sql,创建DWS层数据表
vim /home/warehouse/sql/dws_ddl.sql - 将dws_ddl.sql导入到Hive中
hive -f /home/warehouse/sql/dws_ddl.sql - 在/home/warehouse/shell目录下编写dws_db.sh脚本,完成数据导入操作
vim /home/warehouse/shell/dws_db.sh - 为脚本赋权,并执行
chmod +x /home/warehouse/shell/dws_db.sh ./dws_db.sh 2020-06-10 - 查看是否执行成功
select * from dws_user_action where dt='2020-06-10' limit 2; select * from dws_sale_detail_daycount where dt='2020-06-10' limit 2; 5.6、ADS层创建&数据接入
ADS层分析
- 统计各个一级品类下,品牌月单次复购率,和多次复购率
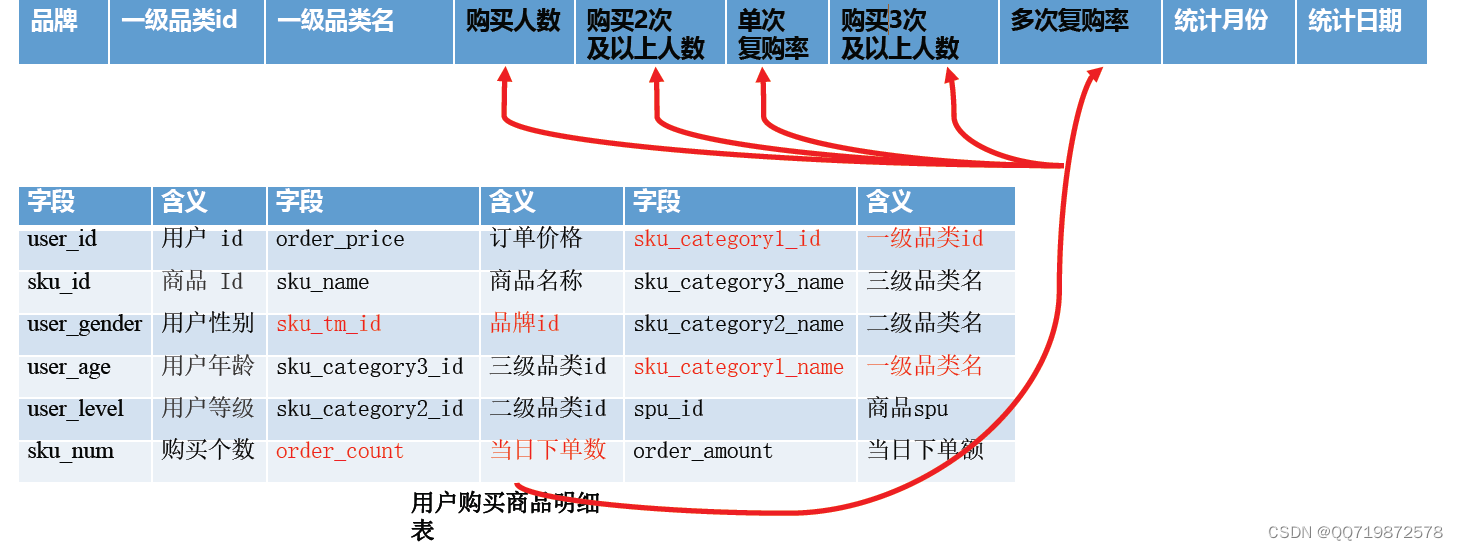
- 在/home/warehouse/sql目录下编写ads_sale_ddl.sql,创建DWS层数据表
vim /home/warehouse/sql/ads_sale_ddl.sql - 将ads_sale_ddl.sql导入到Hive中
hive -f /home/warehouse/sql/ads_sale_ddl.sql - 在/home/warehouse/shell目录下编写ads_sale.sh脚本,完成数据导入操作
vim /home/warehouse/shell/ads_sale.sh - 为脚本赋权,并执行
chmod +x /home/warehouse/shell/ads_sale.sh /home/warehouse/shell/ads_sale.sh 2020-06-10 - 查看是否执行成功
select * from ads_sale_tm_category1_stat_mn limit 2; 5.7、ADS层数据导出
- 在Mysql节点的/home/warehouse/sql目录下编写mysql_sale_ddl.sql,创建数据表
vim /home/warehouse/sql/mysql_sale_ddl.sql - 将mysql_sale_ddl.sql导入到Mysql中
export MYSQL_PWD=DBa2020* mysql -uroot mall < /home/warehouse/sql/mysql_sale_ddl.sql - 在Sqoop节点的/home/warehouse/shell目录下编写sqoop导出脚本,完成数据导入操作
vim /home/warehouse/shell/sqoop_export.sh - 为脚本赋权,并执行
chmod +x /home/warehouse/shell/sqoop_export.sh /home/warehouse/shell/sqoop_export.sh all - 在Mysql中查看是否执行成功
SELECT * FROM ads_sale_tm_category1_stat_mn; 5.8、Azkaban自动化调度
- 在Mysql中执行SQL,生成数据
CALL init_data('2020-06-12',300,200,300,FALSE); - 编写azkaban运行job,并打包成mall-job.zip文件
- 在3台虚拟机中同时启动Azkaban
azkaban-executor-start.sh - 在存放shell脚本的虚拟机上启动Azkaban Web服务器
cd /opt/app/azkaban/server azkaban-web-start.sh - 访问Azkaban Web界面,端口8443
- 上传并运行job,运行时指定executor为shell脚本存放的服务器,并配置脚本参数
useExecutor node03 dt 2020-06-12 6、课后练习
计算GMV(成交总额),包含付款和未付款部分,导出到Mysql

编写为Shell脚本,使用Azkaban进行自动化调度
提示:依赖的表为dws_user_action
6.1、ADS层分析
- 计算GMV(成交总额),包含付款和未付款部分

6.2、ADS层创建&数据接入
- 在/home/warehouse/sql目录下编写ads_gmv_ddl.sql,创建DWS层数据表
vim /home/warehouse/sql/ads_gmv_ddl.sql - 将ads_gmv_ddl.sql导入到Hive中
hive -f /home/warehouse/sql/ads_gmv_ddl.sql - 在/home/warehouse/shell目录下编写ads_gmv.sh脚本,完成数据导入操作
vim /home/warehouse/shell/ads_gmv.sh - 为脚本赋权,并执行
chmod +x /home/warehouse/shell/ads_gmv.sh /home/warehouse/shell/ads_gmv.sh 2020-06-10 - 查看是否执行成功
select * from ads_gmv_sum_day; 6.3、Azkaban自动化调度
- 在Mysql中执行SQL,生成数据
CALL init_data('2020-06-12',300,200,300,FALSE); - 编写azkaban运行job,并打包成mall-job.zip文件
- 在3台虚拟机中同时启动Azkaban
azkaban-executor-start.sh - 在存放shell脚本的虚拟机上启动Azkaban Web服务器
cd /opt/app/azkaban/server azkaban-web-start.sh - 访问Azkaban Web界面,端口8443
- 上传并运行job,运行时指定executor为shell脚本存放的服务器,并配置脚本参数
useExecutor node03 dt 2020-06-12 参考资料
阿里云:https://www.alipan.com/s/zuK576wnz2n
