
阅读量:0
1. 创建code源文件的文件夹
终端中输入如下命令
cd /usr/local/spark/mycode mkdir streaming cd streaming mkdir -p src/main/scala cd src/main/scala 注意:这一步需要提前创建mycode文件夹,否则如果直接全文复制之后回车会导致后面的指令全部无效!
2. 编写WordCount的scala代码
用vim打开一个scala文件:
vim TestStructuredStreaming.scala 在该文件输入以下内容:
import org.apache.spark.sql.functions._ import org.apache.spark.sql.SparkSession object WordCountStructuredStreaming{ def main(args: Array[String]){ val spark = SparkSession.builder.appName("StructuredNetworkWordCount"). getOrCreate() import spark.implicits._ val lines = spark.readStream.format("socket").option("host","localhost"). option("port",9999).load() val words = lines.as[String].flatMap(_.split(" ")) val wordCounts = words.groupBy("value").count() val query = wordCounts.writeStream.outputMode("complete"). format("console").start() query.awaitTermination() } } 以上是WordCount的scala代码,阅读代码可以知道这里用的端口是9999,记住它,后面要用。
3. 安装sbt
sbt是用来打包scala的工具。由于前文并没有讲解sbt 的用法(甚至没教怎么安装orz,感觉是任务书被阉割导致的,实验一的spark安装中包含了这一部分,但很容易被忽略),先补充一下sbt的配置步骤(参考了大数据原理与应用 第十六章 Spark 学习指南 (xmu.edu.cn))
官网下载地址:Download | sbt (scala-sbt.org) 我在这里下载了1.10的tgz版本,方便在linux中解压和安装。
下载完成之后,将压缩包解压。利用以下指令直接解压到/usr/local/文件夹中(这样做的前提是命令行在压缩包所在的文件夹处):
tar -zxvf sbt-1.10.0.tgz -C /usr/local # 解压到/usr/local中在 /usr/local/sbt 中创建 sbt 脚本(
vim ./sbt),添加如下内容(记得路径要改成自己的路径):#!/bin/bash SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" java $SBT_OPTS -jar /usr/local/sbt/bin/sbt-launch.jar "$@"保存退出后,为./bat文件增加读写权限(注意在对应目录下完成该步骤):
chmod u+x ./sbt最后运行如下命令,检查sbt是否可用:
./sbt sbtVersion若结果如下,则可用。

4. 创建bat文件,编辑编译相关内容
在/usr/lcoal/spark/mycode/streaming目录下创建simple.sbt文件:
cd /usr/local/spark/mycode/streaming vim simple.sbt输入以下内容:
name := "Simple Project" version := "1.0" scalaVersion := "2.12.17" libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.3"
注意,这里需要指定scala和spark的版本,这是需要和你安装的版本统一的。在上面的配置信息中,scalaVersion用来指定scala的版本,sparkcore用来指定spark的版本,这两个版本信息都可以在之前的启动 Spark shell 的过程中,从屏幕的显示信息中找到。示例如下:
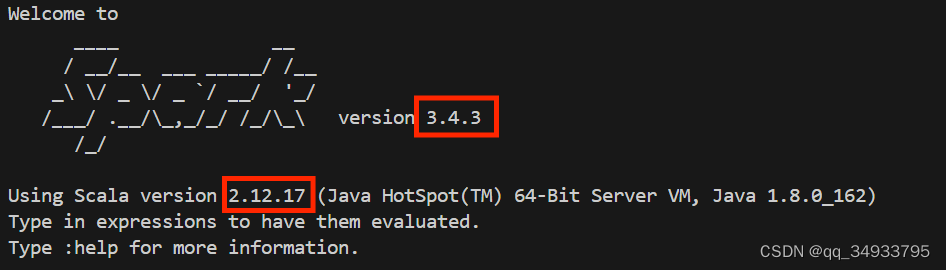
执行sbt打包编译:
cd /usr/local/spark/mycode/streaming /usr/local/sbt/sbt package
如果打包编译成功,会显示如下信息:

5. 启动程序
- 启动程序的shell指令(这里也有要注意的,不要直接跟着任务书抄,这里的文件目录和名称是和scala版本有关系的,需要检查你的文件的具体情况):
cd /usr/local/spark/mycode/streaming /usr/local/spark/bin/spark-submit --class "WordCountStructuredStreaming" ./target/scala-2.12/simple-project_2.12-1.0.jar 然而如果直接这样执行,会发现出现报错后直接退出。报错信息大致如下:

这是因为没有启动端口。还记得前文要记住的9999端口吗?现在它有用了。你需要在另外一个命令行(终端)窗口执行下面的指令:
nc -lk 9999 通过这条指令,你成功启动了9999号端口,也就可以在终端输入相关的信息让你的程序来读取和实现功能了。两个终端都不要关闭,接下来回到streaming目录的终端,重新执行启动程序的shell指令:
/usr/local/spark/bin/spark-submit --class "WordCountStructuredStreaming" ./target/scala-2.12/simple-project_2.12-1.0.jar >out.txt “>out.txt"是为了将输出单独放到out.txt文件夹中,方便查看。执行完这条指令后等待命令行的输出显示不再更新,切换到9999端口的终端输入你想检测的内容(以任务书中的”hello world, hello Beijing, hello world“为例),等再一次命令行输出显示不再更新,程序就进行完成了,输出的结果就可以在out.txt中查看了。终端输入待检测内容可以重复进行,直到按下Ctrl+C结束程序。示例输出如下:
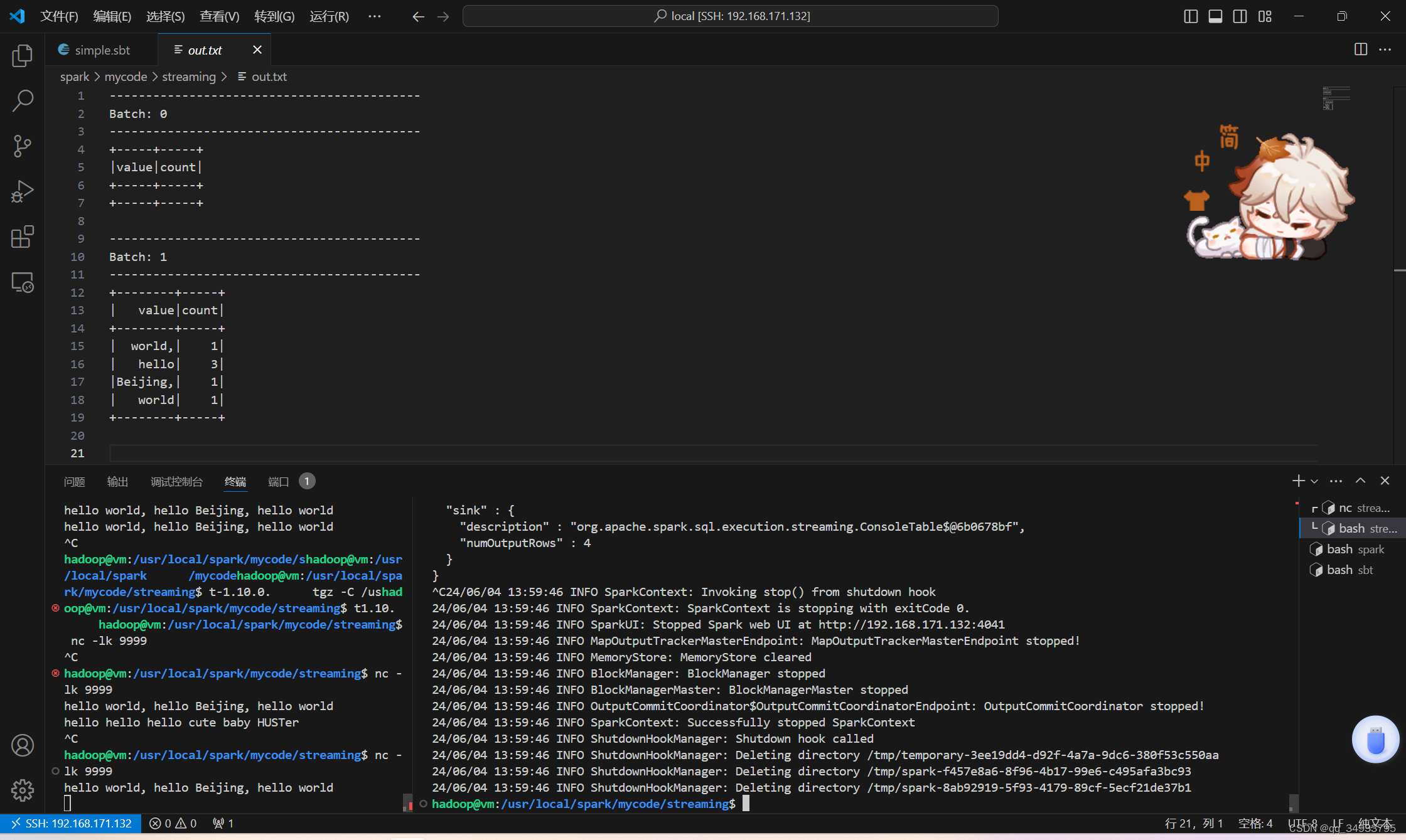
至此,实验二完成:)
