阅读量:0
运算符:
算术运算符:
+ 加
- 减
* 乘
/ 除
// 整除
% 取余
** 求平方
除法计算得出的结果都是小数
赋值运算符:
标准赋值: =
复合赋值: += 、 -= 、 *= 、 /= 、//= 、 **=
字符串:
字符串拓展内容:
字符串在Python中有多种定义形式:
单引号定义法:name = ‘黑马程序员’
双引号定义法:name = ”黑马程序员”
三引号定义法:name = “””黑马程序员”””
在字符串内包含引号:使用转义字符 \ 解除引号的效用
name = “ \”黑马程序员\” ”字符串拼接:
通过 +号 直接拼接
Name = “小王” Address = “北京” Print(“我的名字是”+name+”,我住在”+address)注意:无法和非字符串类型进行拼接
字符串格式化:
“ %占位符 ” % 变量
Name = “黑马程序员” Message = “学IT来:%s” % name Print(message)%s : 将内容转换成字符串,放入占位位置
%d : 将内容转换为整数,放入占位位置
%f : 将内容转换为浮点型,放入占位位置
Name = “传智播客” Setup_year = 2006 Stock_price = 19.99 Message = “%s , 成立于:%d , 我今天的股价是:%f” % (name , setup_year , stock_price)字符串的数字精度控制:
使用辅助符号”m.n”来控制数据的宽度和精度,如%5d、%5.2f、%.2f,m和.n均可省略
如果m比数字本身宽度还小,m不生效
.n对小数部分做精度限制的同时,还会对小数部分做四舍五入
Num1 = 11 Num2 = 11.345 Print(“数字11宽度限制5,结果是:%5d” % num1) Print(“数字11.345宽度限制7,小数精度2,结果是:% 7.2f” % num2) Print(“数字11.345不限制,小数精度2,结果是:% .2f” % num2)字符串格式化的快速写法:
f” {变量} {变量} ”
Name = “传智播客” Setup_year = 2006 Stock_price = 19.99 Print(f”我是{name},我成立于:{setup_year}年,我今天的股价是{stock_price}”)对表达式进行格式化:
在无需使用变量进行数据存储的时候,可以直接格式化表达式,简化代码
Print(“1+1的结果是: %d” % (1+1)) Print(f”1*2的结果是:{1*2}”) Print(“字符串在Python中的类型名是:%s” % type(“字符串”))获取键盘输入的数据:
Input(“提示语句”)
默认接收类型都是字符串
Name = str(input(”请输入姓名”)) Age = int(input(“请输入年龄”)) 小数 = float(input(“请输入一个小数”))布尔类型和比较运算符:

比较运算符的使用:
== 、 != 、 > 、< 、>= 、<=
If语句的基本格式:
If-else语句:
If-elif-else语句:
判断语句的嵌套:
通过如下代码,可以定义一个变量num,变量内存储随机数字
Import random Num = random.randint(1,10)while循环的基础语法:
While循环的嵌套:
同判断语句的嵌套一样,循环语句的嵌套,要注意空格缩进
多层循环,基于空格缩进来决定层次关系
注意条件的设置,避免出现无限循环(除非真的需要无限循环)
For循环的基础语法:
For 临时变量 in 待处理数据集(序列):
循环满足条件时执行的代码
同while循环不同,for循环是无法定义循环条件的
只能从被处理的数据集中,依次取出内容进行处理
所以,for循环无法构建无限循环(被处理的数据集不可能无限大)
Range语句:
待处理数据集,严格来说,称之为:序列类型
序列类型指,其内容可以一个个依次取出的一种类型,包括:
字符串、列表、元组
Range语句的语法格式:
Range(num) Range(num1,num2) Range(num1,num2,step),#step指数字之间的步长For循环临时变量作用域:
作用域限定为循环内,如需访问临时变量,可以预先在循环外定义它
For循环的嵌套运用:
Continue和break:
Continue 中断本次循环,直接进入下一次循环
Break 直接结束所在循环
函数:
函数是组织好哒,可重复使用的,用来实现特定功能的代码段
提高了程序的复用性,减少重复性代码,提高开发效率
无返回值的语法:
Def 函数名():
函数体
函数名()
Def 函数名(x,y):
函数定义中,提供的x和y,称为:形式参数(形参),表示函数声明将要使用2个参数
函数调用中,提供的参数称为实际参数(实参),表示函数执行时真正使用的参数值
返回值的语法:
Def 函数名(参数...):
函数体
Return 返回值
变量 = 函数名(参数)
Return后的代码不会执行
如果函数没有使用return语句返回数据,函数返回None
None类型的应用场景:
①用在函数无返回值上
②用在if判断上
在if判断中,None等同于False
一般用于在函数中主动返回None,配合 if 判断做相关处理
③用于声明无内容的变量上
定义变量,但暂时不需要变量有具体值,可以用None来代替
函数的嵌套调用:
在一个函数中,调用另外一个函数
函数A中执行到调用函数B的语句,会将函数B全部执行完成后,继续执行函数A的剩余内容
变量在函数中的作用域:
变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用)
主要分为两类:局部变量和全局变量
局部变量:定义在函数体内部的变量,即只在函数体内部生效
全局变量:在函数体内、外都能生效的变量
Global关键字,可以在函数内部声明变量为全局变量
数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素
每一个元素,可以是任意类型的数据,如字符串、数字、布尔
数据容器根据特点的不同,如:
是否支持重复元素
是否可以修改
是否有序等
分为五类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
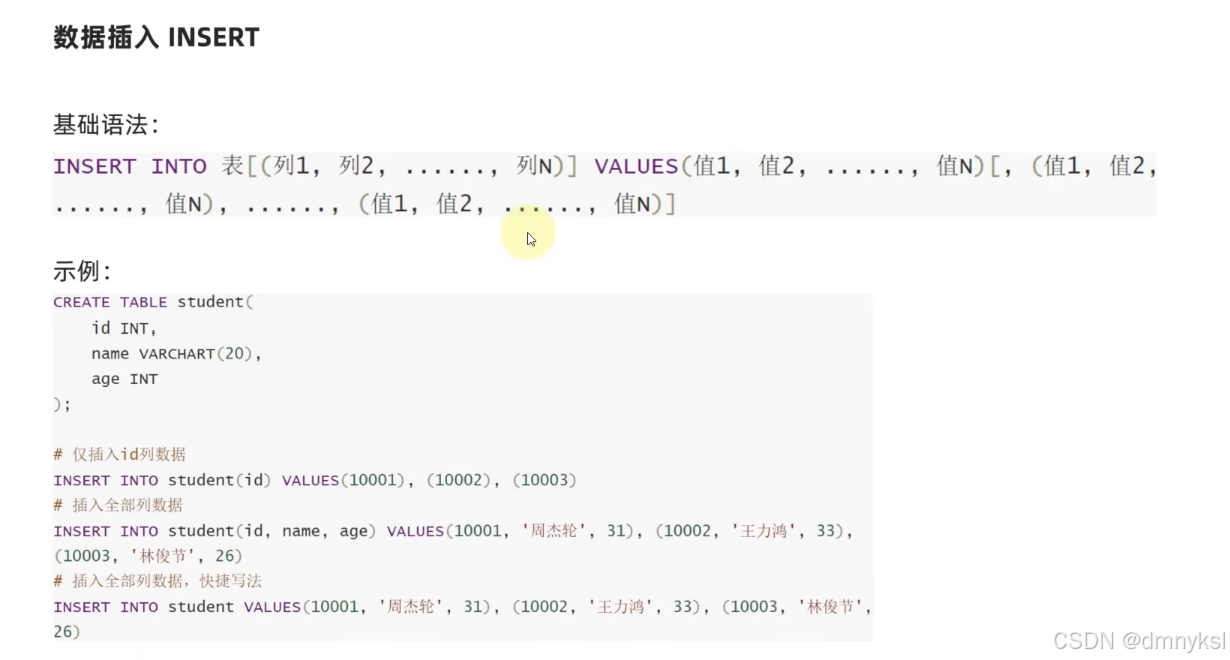
列表:

列表的数据类型没有任何限制,甚至元素也可以是列表,这样就定义了嵌套列表
从列表中取出特点位置的数据可以使用:下标索引
要注意下标索引的取值范围,超出范围无法取出元素,并且会报错
取出列表元素:
List[0,1,2...]
取出嵌套列表的元素:
List[1][2]
列表的方法:
查询某元素的下标: 列表.index(元素)
修改特点下标索引的值: 列表[下标] = 值
插入元素: 列表.insert(下标,元素)
在列表尾部追加”单个”元素: 列表.append(元素)
在列表尾部追加”一批”元素: 列表.extend(其他数据容器) 将其他数据内容取出,依次追加到列表尾部
删除元素: Del 列表[下标] 列表.pop(下标)
删除某元素在列表中的第一个匹配项: 列表.remove(元素)
清空列表: 列表.clear()
统计某元素在列表内的数量: 列表.count(元素)
统计列表中全部的元素数量: Len(列表)
列表的遍历: While循环 、For循环




元组:
Tuple = ()
元组一旦定义完成,就不能修改
元组只有一个数据,这个数据后面要添加逗号,否则是字符串类型
元组可以嵌套,和列表一样,支持下标索引
如果元组里面嵌套了list,那么list里面的元素可以修改
支持for循环和while循环

再识字符串:
支持下标(索引)
同元组一样,字符串是一个:无法修改的数据容器
查找元素的下标: Index()
字符串的替换: 字符串.replace(字符串1,字符串2)
将字符串中的全部字符串1替换为字符串2,不是修改字符串本身,而是得到了一个新字符串
字符串的分割: `` 字符串.split(分隔字符串)
按照指定的分割符字符串,将字符串划分为多个字符串,并存入列表对象中,字符串本身不变,而是得到一个列表对象
字符串的规整操作(去前后空格): 字符串.strip()
字符串的规整操作(去前后指定字符串): 字符串.strip(字符串)
注意:传入的是”ab”,其实就是:”a”和”b”都会移除,是按照单个字符
统计字符串中某字符的出现次数: Count()
统计字符串的长度: Len()

数据容器(序列)的切片:
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以视为序列
切片: 序列[起始下标:结束下标:步长]
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
从头到尾: 序列[ : ]
将序列反转: 序列[ : :-1]
字符串大小比较的方式:
ASCLL码表:
字符串是按位比较,也就是一位位进行对比
小写字母>大写字母>数字
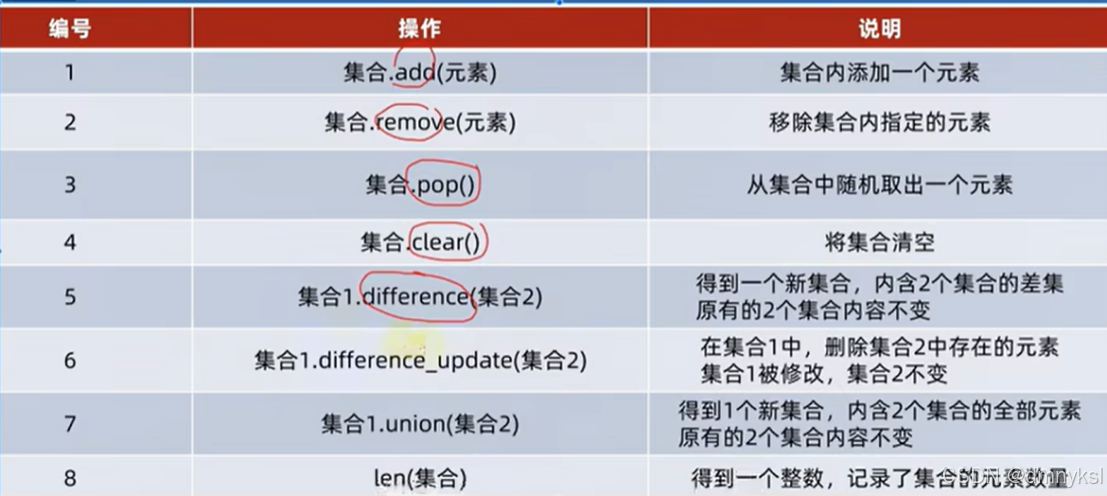
集合(set):
集合是无序的,所以集合不支持下标索引,不能用while遍历
定义空集合: 变量名称 = set()
添加新元素: 变量名称.add()
移除元素: 变量名称.remove()
从集合中随机取出元素: 集合.pop()
从集合中随机取出一个元素,结果:会得到一个元素的结果。集合本身被修改,元素被移除
清空集合: 集合.clear()
取两个集合的差集: 集合1.difference(集合2)
取出集合1有,集合2没有的,结果:得到一个新集合,集合1和集合2不变
消除两个集合的差集: 集合1.difference_update(集合2)
对比集合1和集合2,在集合1内,删除和集合2相同的元素,结果:集合1被修改,集合2不变
两个集合合并: 集合1.union(集合2)
将集合1和集合2组合成新集合,结果:得到新集合,集合1和集合2不变
字典:
定义:同样使用{},不过存储的元素,是一个个的键值对
字典的嵌套:
字典的key和value可以是任意数据(key不能是字典)。
字典内key不能重复,重复天剑等同于覆盖原有数据
字典不可以通过下标索引,而是通过key去获取value,不能使用while循环
从嵌套字典中获得信息: Dict[key1][key2]
新增或更新元素: 字典[key] = value
删除元素: 字典.pop(key)
清空字典: 字典.clear()
获取全部的key: 字典.keys()
遍历: ①通过获取到全部的key来完成遍历
②直接对字典进行for循环,每一次循环都是直接得到key
统计字典的元素数量: Len()函数

数据容器对比:
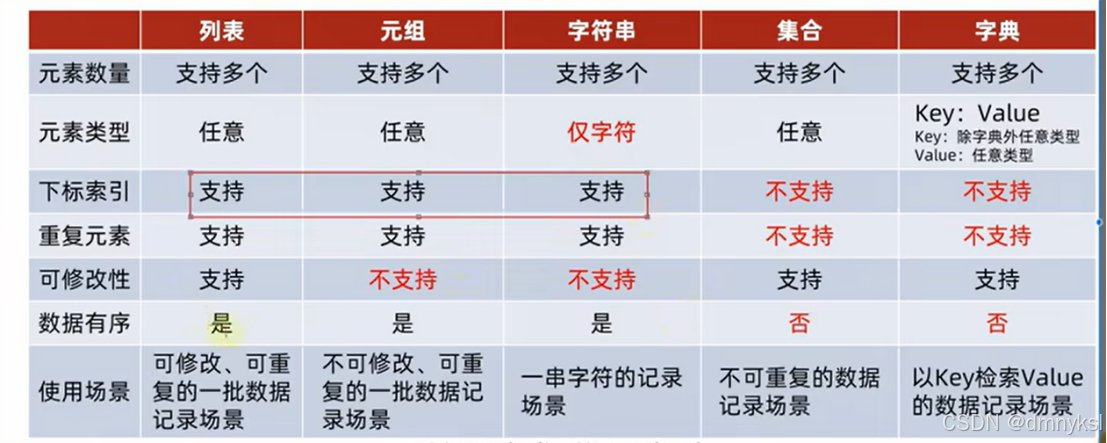
数据容器的通用统计功能:
首先,在遍历上:
5类数据容器都支持for循环遍历
列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
Len(容器) 统计容器的元素个数
Max(容器) 统计容器的最大元素
Min(容器) 统计容器的最小元素
通用类型转换:
List(容器) 将给定容器转换为列表
Str(容器) 将给定容器转换为字符串
Tuple(容器) 将给定容器转换为元组
Set(容器) 将给定容器转换为集合
字典可以转换为其他类型
容器的通用排序功能:
Sorted(容器,[reverse = True]) 降序
Sorted(容器),Sorted(容器,[reverse = False]) 升序
排序的结果通通变成列表对象

函数进阶:
函数多返回值:
如果一个函数出现两个return,程序只执行第一个return,原因是因为return可以退出当前函数,导致return下方的代码不执行

函数的多种传参方式:
函数有四种常见的参数使用方式:
位置参数:

关键字参数:

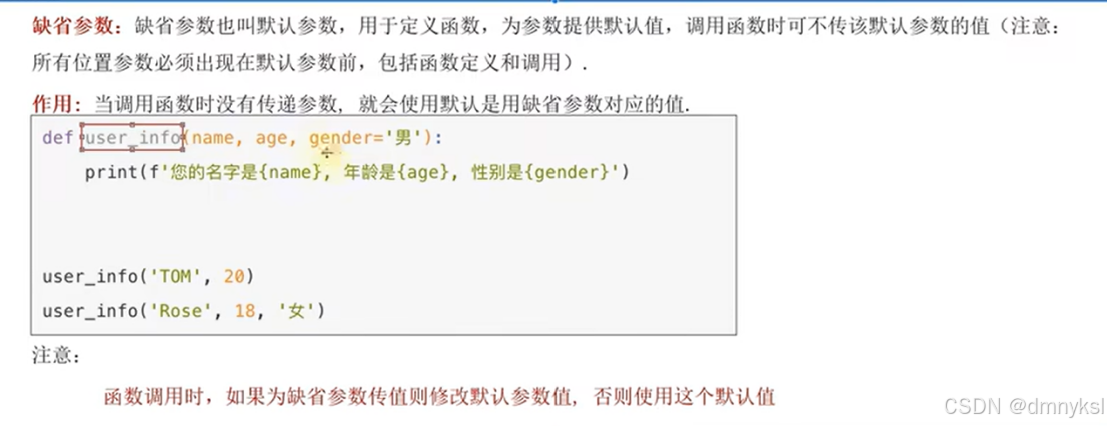
缺省参数:
设置默认值统一的都在最后,否则会报错
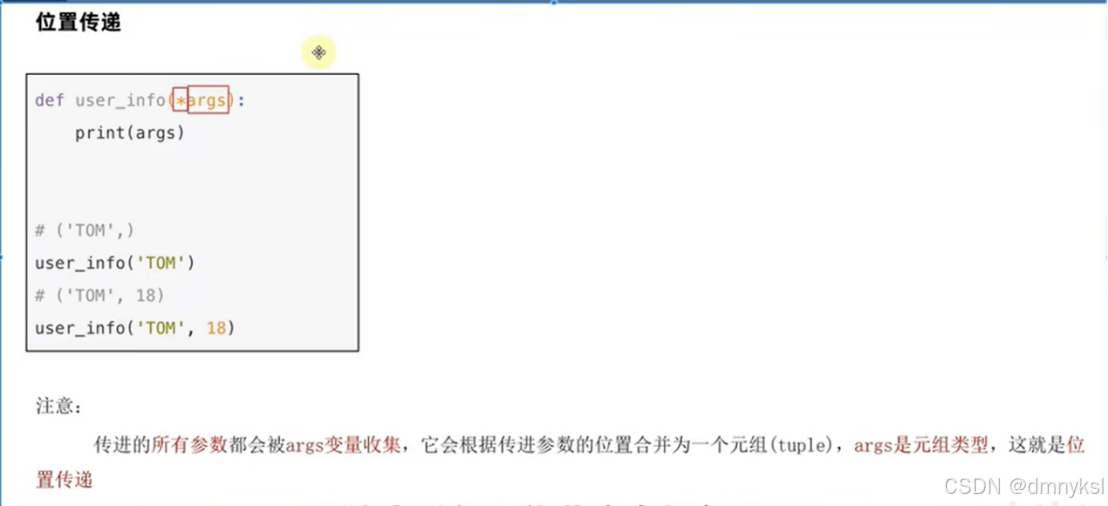
不定长参数:

位置传递的数据形式是元组
关键字传递的数据形式是字典


匿名函数:
函数作为参数传递:
函数本身是可以作为参数,传入另一个函数中进行使用的
将函数传入的作用在于:传入计算逻辑,而非传入数据
Lambda匿名函数:

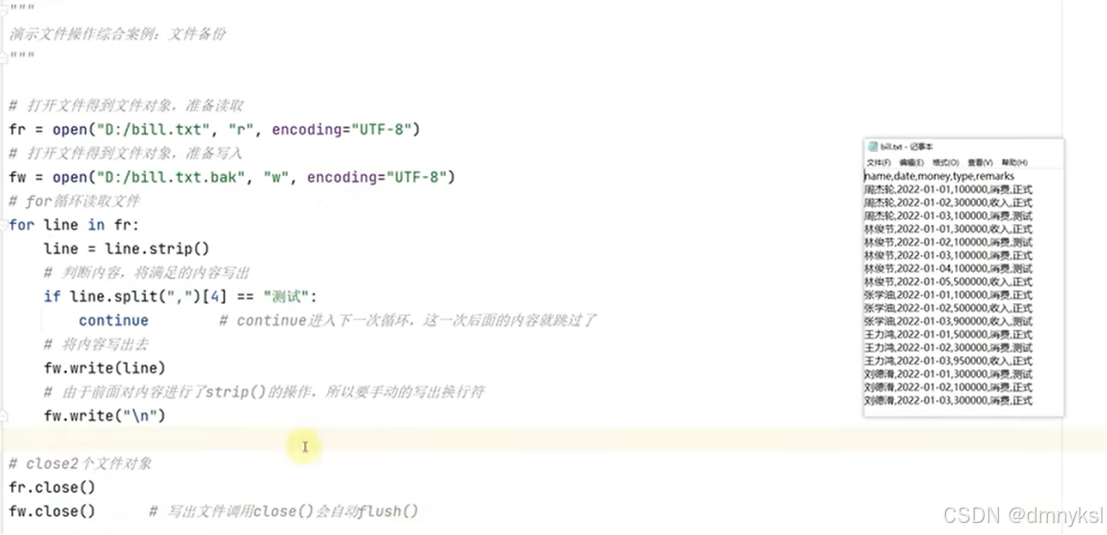
Python的文件操作:
编码有许多,所以要使用正确的编码,才能对文件进行正确的读写操作
UTF-8是目前全球通用的编码格式
除非有特殊需求,否则,一律以UTF-8格式进行文件编码即可
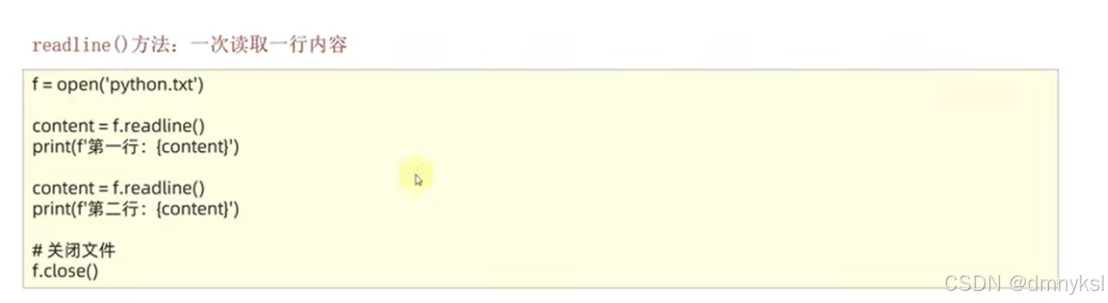
文件的读取操作:
文件的操作步骤:
打开文件
读写文件
关闭文件



如果在程序中多次调用read(),那么下一个read,会在上一个read的结尾处接着读取的

文件的关闭:
f.close()
最后通过close,关闭文件对象,也就是关闭对文件的占用
如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用


文件的写出操作:

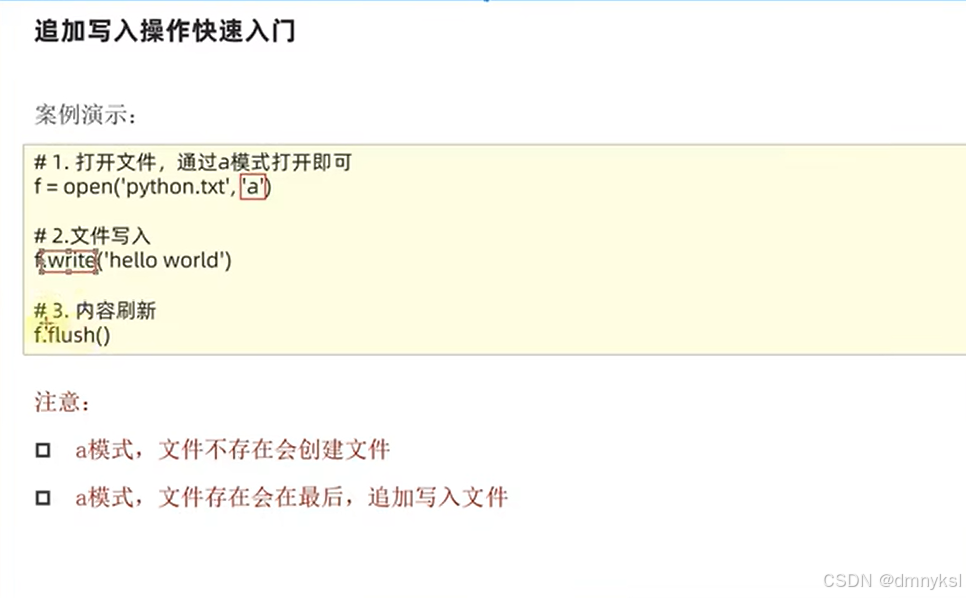
Close方法内置了flush的功能,如果不调用flush,但是调用close,同样文件也会写入内容
w模式,文件不存在,w会创建文件;文件存在,w会清空原有内容
文件的追加:
可以使用”\n”来写出换行符
异常:
在可能发生异常的地方进行捕获,当异常出现时,提供解决方式,避免程序无法运行

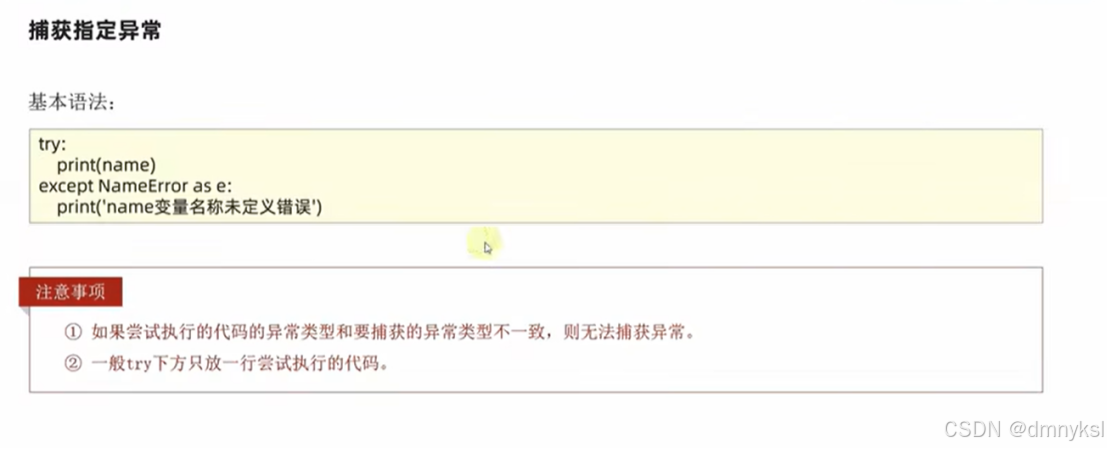

捕获所有异常:
Try: Except Exception as e: Print(e)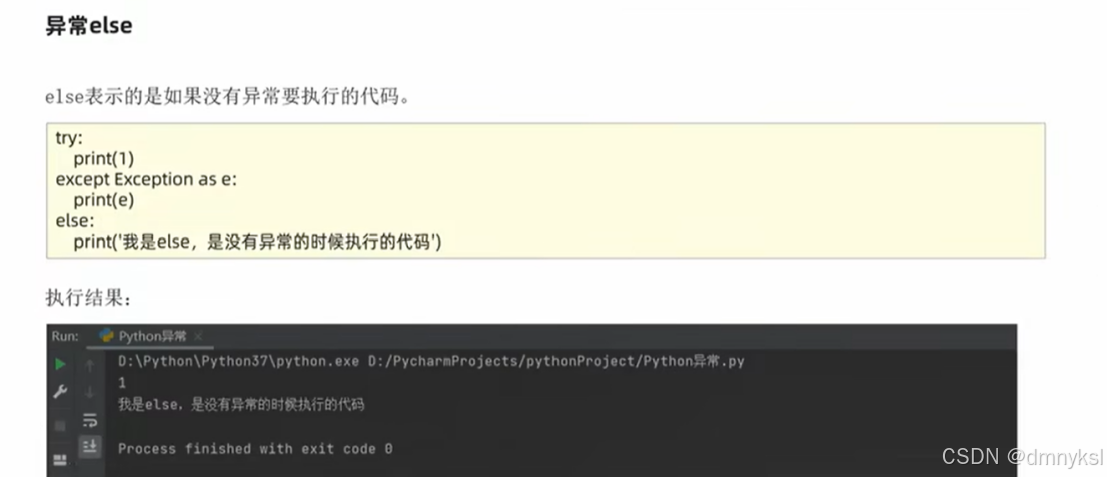


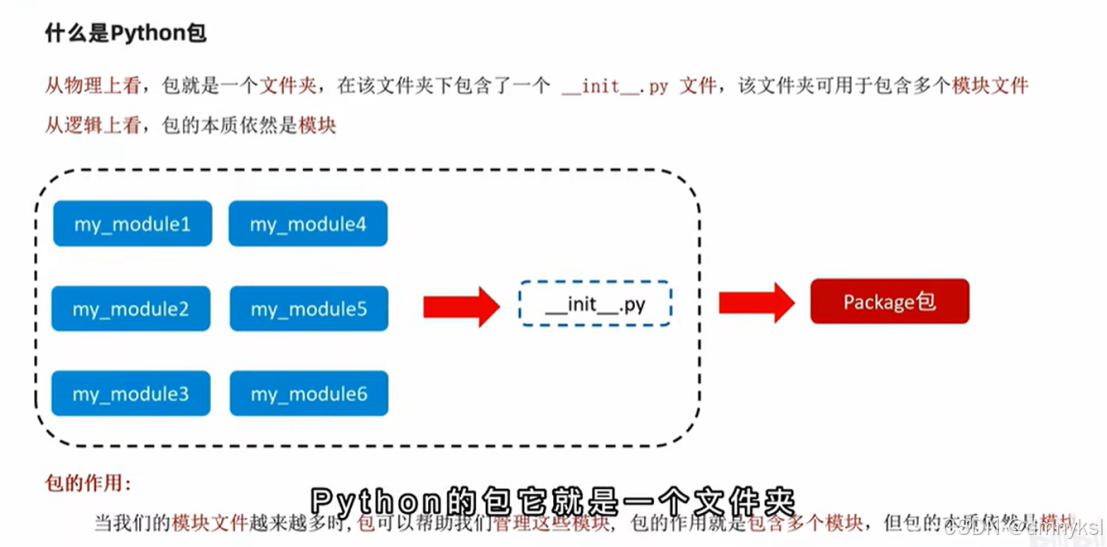
Python的模块:
模块(module)的导入:





自定义模块:


不同模块,同名的功能,如果都被导入,按照调用顺序,后导入的会覆盖先导入的

__main__变量的功能:
if __name__ == ‘__main__’:表示,只有当程序是直接执行的才会进入if内部,如果是被导入的,则if无法进入
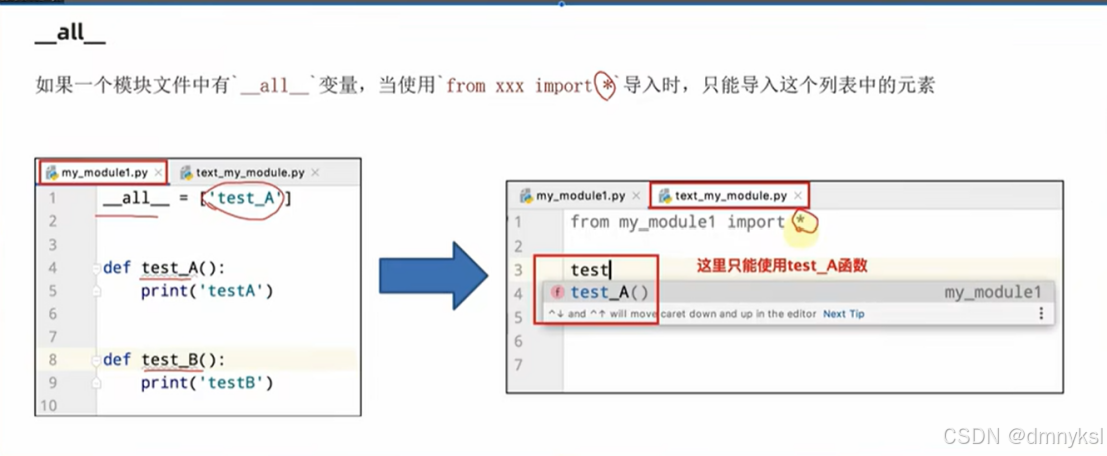
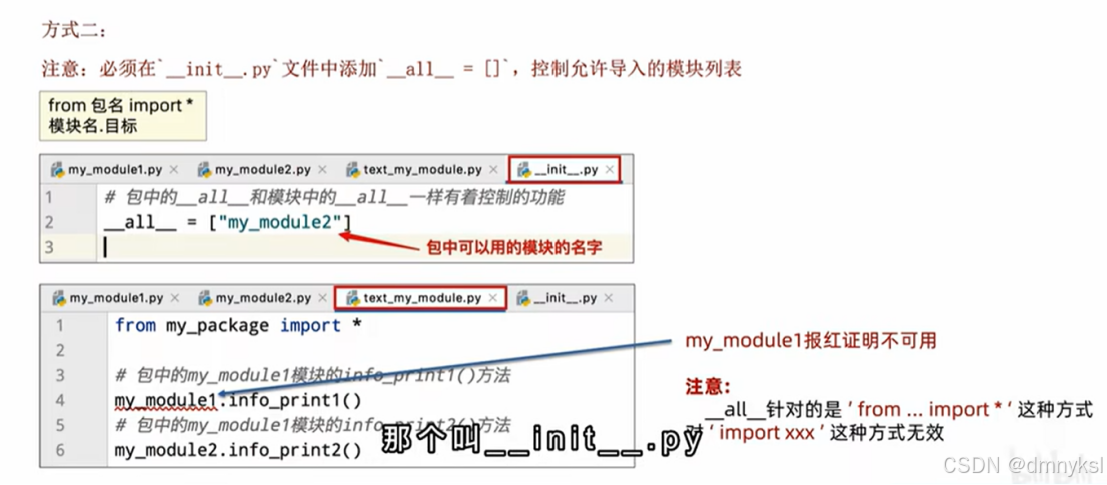
_all_变量的功能:
_all_变量是一个列表,可以控制import*的时候,哪些功能可以被导入
自定义Python包(package):

安装第三方包:


可视化案例:
Json数据格式:
json的类型是字符串


Json_str = json.dumps(data,ensure_ascii = False)
如果有中文的话,传入ensure_ascii = False参数,来确保中文正常转换
Pyecharts模块介绍:

Pyecharts快速入门:

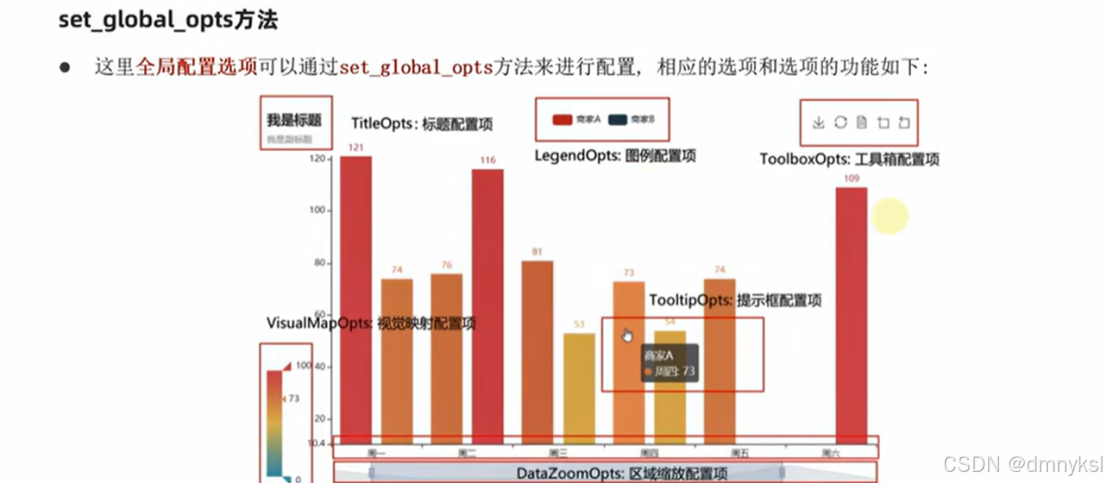
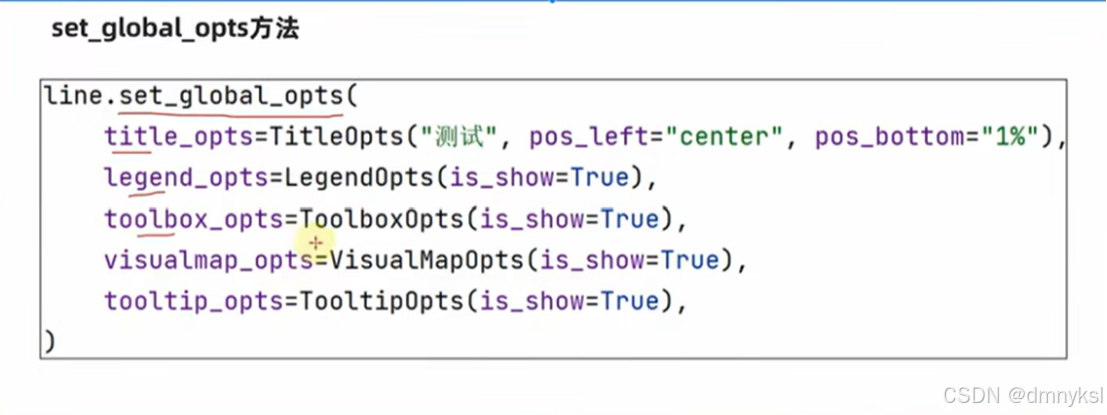
配置选项:
Pyecharts模块中有很多的配置选项,常用到2个类别的选项:
全局配置选项
系列配置选项
数据处理:



from pyecharts.charts import Line import json from pyecharts.options import * # 处理数据 f_us = open("D:/美国.txt", "r", encoding="UTF-8") us_data = f_us.read() # 美国的全部内容 f_jp = open("D:/美国.txt", "r", encoding="UTF-8") jp_data = f_us.read() # 日本的全部内容 f_in = open("D:/美国.txt", "r", encoding="UTF-8") in_data = f_us.read() # 印度的全部内容 # 去掉不合JSON规范的开头 us_data = us_data.replace("jsonp_1629344292311_69436", "") jp_data = jp_data.replace("jsonp_1629350871167_29498", "") in_data = in_data.replace("jsonp_1629350745930_63180", "") # 去掉不合JSON规范的结尾 us_data = us_data[::-2] jp_data = jp_data[::-2] in_data = in_data[::-2] # JSON转Python字典 us_dict = json.loads(us_data) jp_dict = json.loads(jp_data) in_dict = json.loads(in_data) # 获取trend key us_trend_data = us_dict['data'][0]['trend'] jp_trend_data = jp_dict['data'][0]['trend'] in_trend_data = in_dict['data'][0]['trend'] # 获取日期数据,用于x轴,取2020年(到314下标结束) us_x_data = us_trend_data['updateDate'][:314] jp_x_data = jp_trend_data['updateDate'][:314] in_x_data = in_trend_data['updateDate'][:314] # 获取确认数据,用于y轴,取2020年(到314下标结束) us_y_data = us_trend_data['list'][0]['data'][:314] jp_y_data = jp_trend_data['list'][0]['data'][:314] in_y_data = in_trend_data['list'][0]['data'][:314] # 创建一个折线图对象 line = Line() # 给折线图对象添加x轴的数据 line.add_xaxis(us_x_data) # 给折线图对象添加y轴的数据 line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=True)) line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=True)) line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=True)) # 设置全局选项 line.set_global_opts( title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%"), legend_opts=LegendOpts(is_show=True), toolbox_opts=ToolboxOpts(is_show=True), visualmap_opts=VisualMapOpts(is_show=True) ) # 通过render方法,将代码生成为图像 line.render() # 关闭文件对象 f_us.close() f_jp.close() f_in.close() 
数据可视化案例:
基础地图演示:
from pyecharts.charts import Map from pyecharts.options import VisualMapOpts map = Map() data = [ ("北京", 99), ("上海", 199), ("湖南", 299), ("台湾", 199), ("安徽", 299), ("广州", 399), ("湖北", 599) ] map.add("地图", data, "china") # 设置全局配置,定制分段的视觉映射 map.set_global_opts( visualmap_opts=VisualMapOpts( is_show=True, #是否显示 is_piecewise=True,#是否分段 pieces=[ {"min": 1, "max": 9, "label": "1-9", "color": "#CCFFFF"}, {"min": 10, "max": 99, "label": "1-9", "color": "#FF6666"}, {"min": 100, "max": 500, "label": "100-500", "color": "#990033"}, ] ) ) # 绘图 map.render("基础地图演示.html") 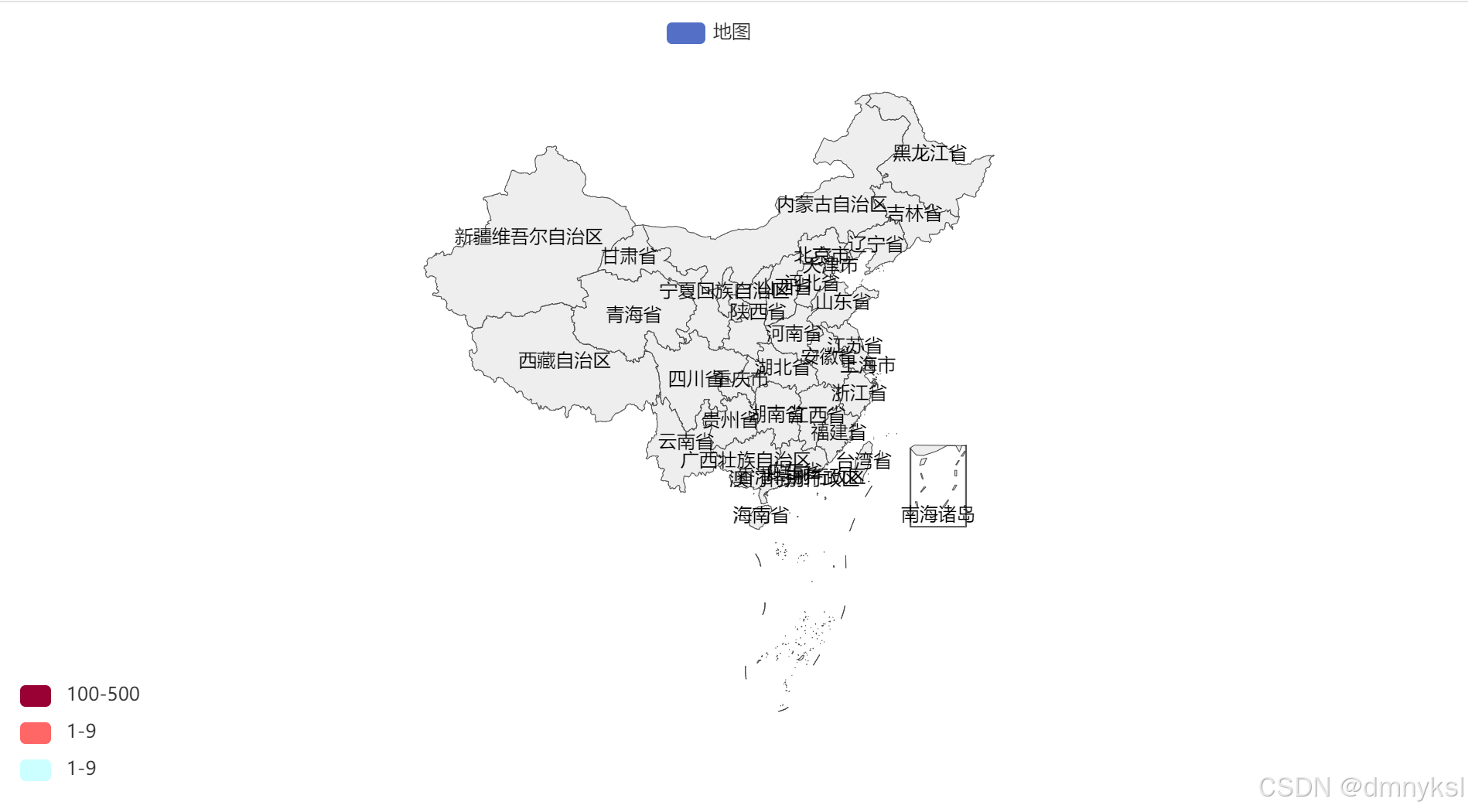
河南省地图疫情绘制:
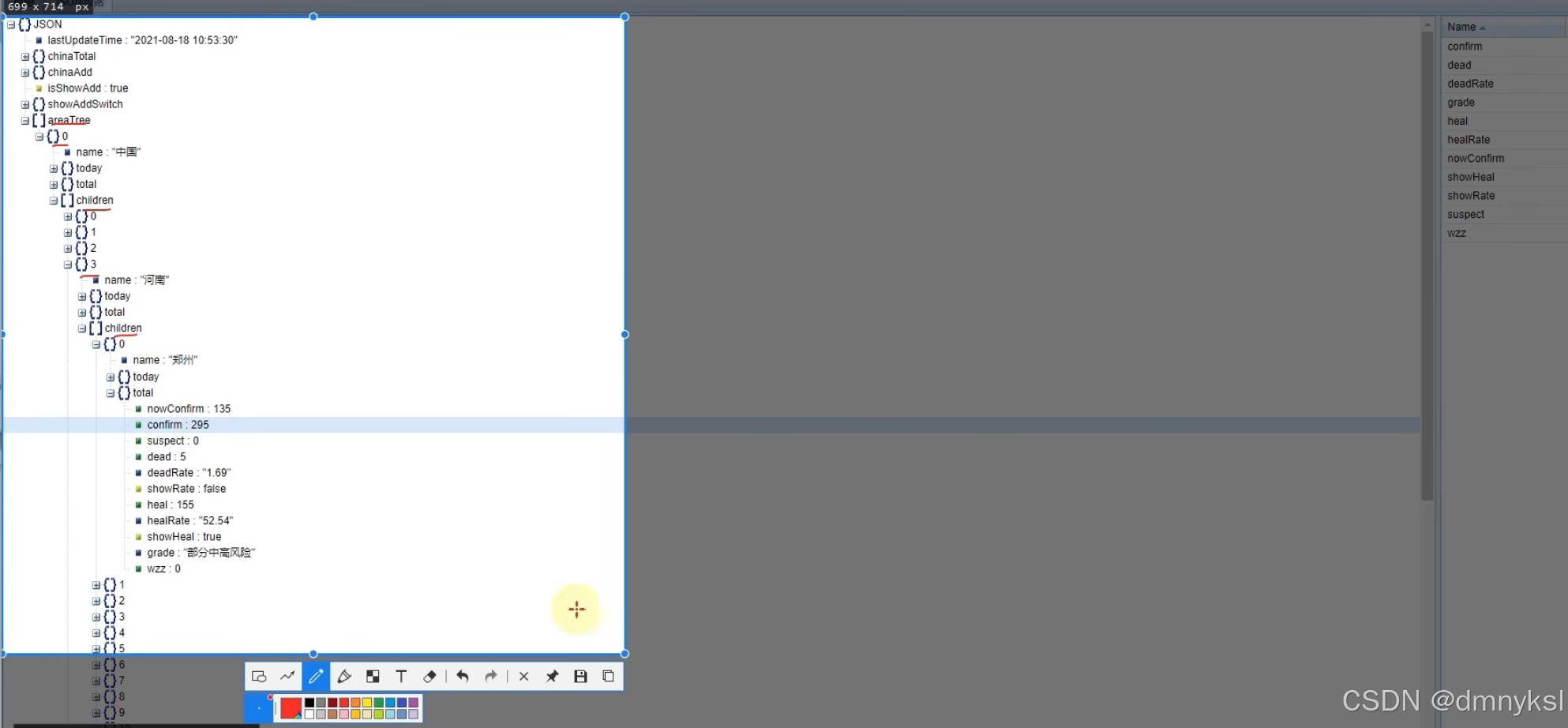
import json from pyecharts.charts import Map from pyecharts.options import * # 读取文件 f = open("D:/疫情.txt", "r", encoding="UTF-8") data = f.read() # 关闭文件 f.close() # 获取河南省数据 # json数据转换为python字典 data_dict = json.loads(data) # 取到河南省数据 cities_data = data_dict['areaTree'][0]['children'][3]['children'] # 准备数据为元组并放入list data_list = [] for city_data in cities_data: city_name = city_data['name'] + '市' city_confirm = city_data['total']['confirm'] data_list.append((city_name, city_confirm)) # 手动添加济源市的数据 data_list.append(("济源市", 5)) # 构建地图 map = Map() map.add("河南省疫情分布地图", data_list, "河南") # 设置全局选项 map.set_global_opts( title_opts=TitleOpts(title="河南省疫情地图"), visualmap_opts=VisualMapOpts( is_show=True, # 是否显示 is_piecewise=True, # 是否分段 pieces=[ {"min": 1, "max": 9, "label": "1-99", "color": "#CCFFFF"}, {"min": 100, "max": 999, "label": "100-999", "color": "#FF6666"}, {"min": 1000, "max": 4999, "label": "1000-4999", "color": "#990033"}, {"min": 5000, "max": 9999, "label": "5000-9999", "color": "#CC3333"}, {"min": 10000, "max": 99999, "label": "10000-99999", "color": "#FF9966"}, {"min": 100000, "label": "100000+", "color": "#FFFF99"} ] ) ) # 绘图 map.render("河南省疫情地图.html") 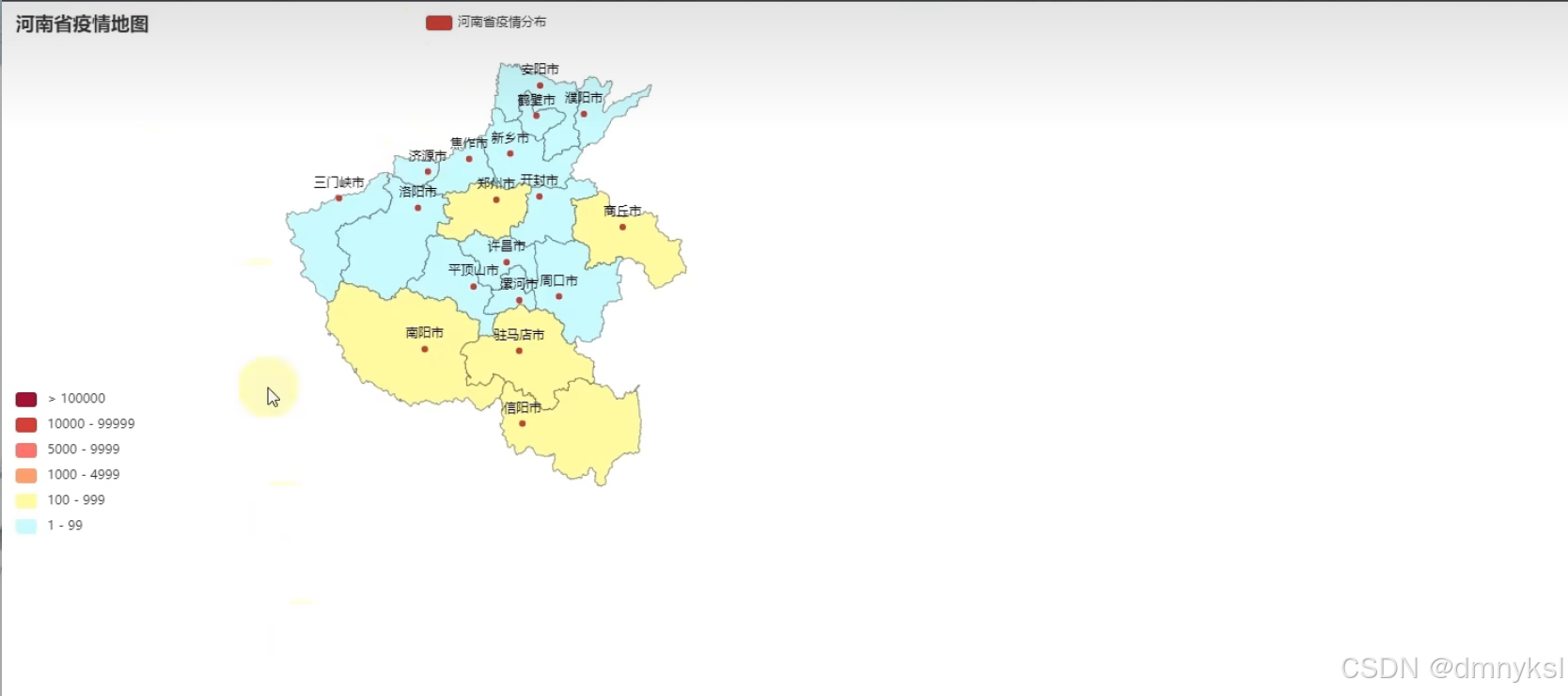
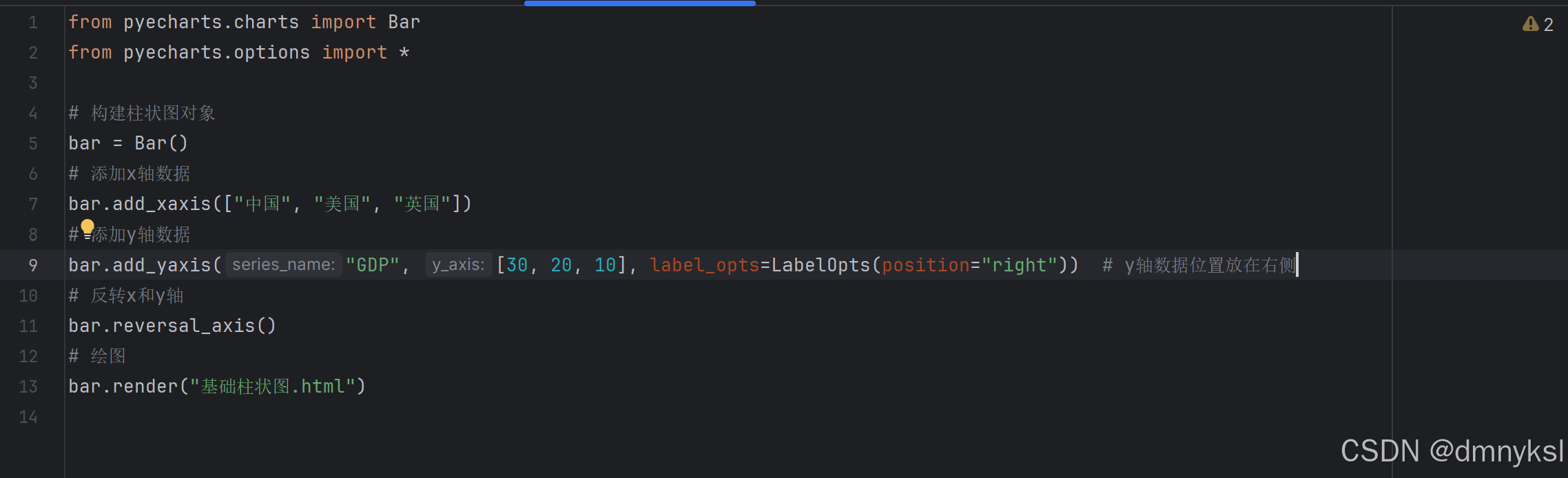
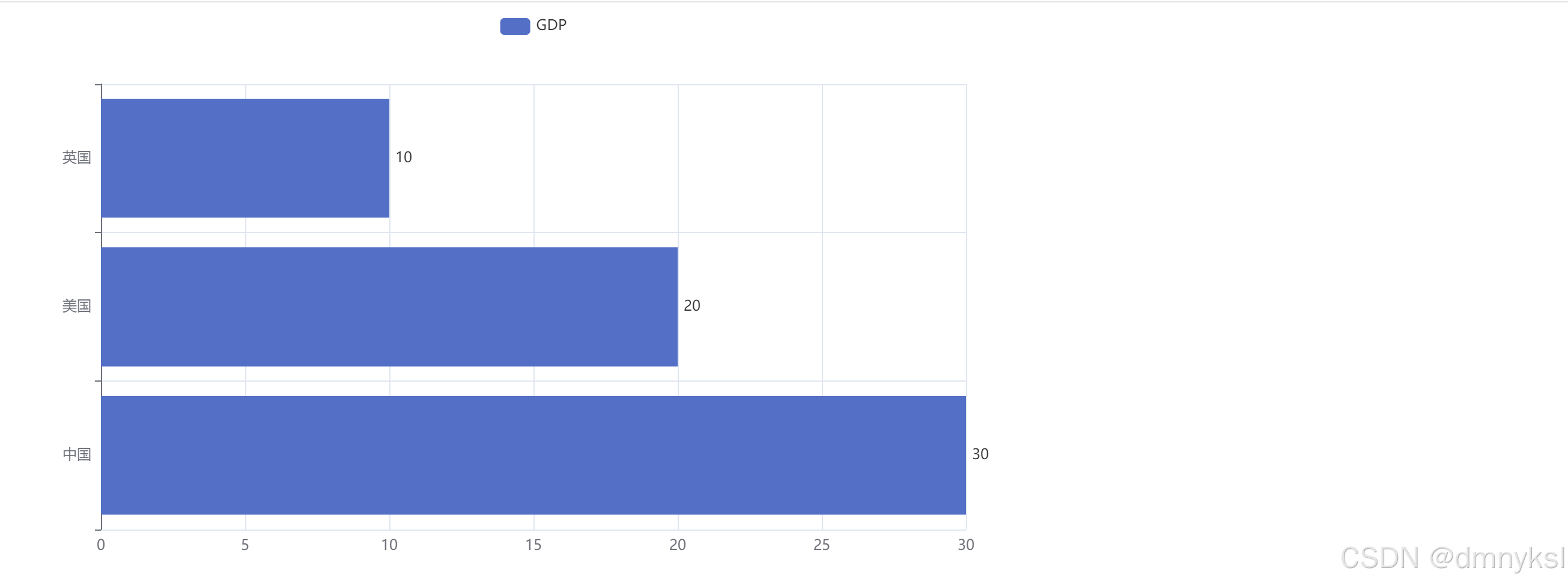
基础柱状图构建:

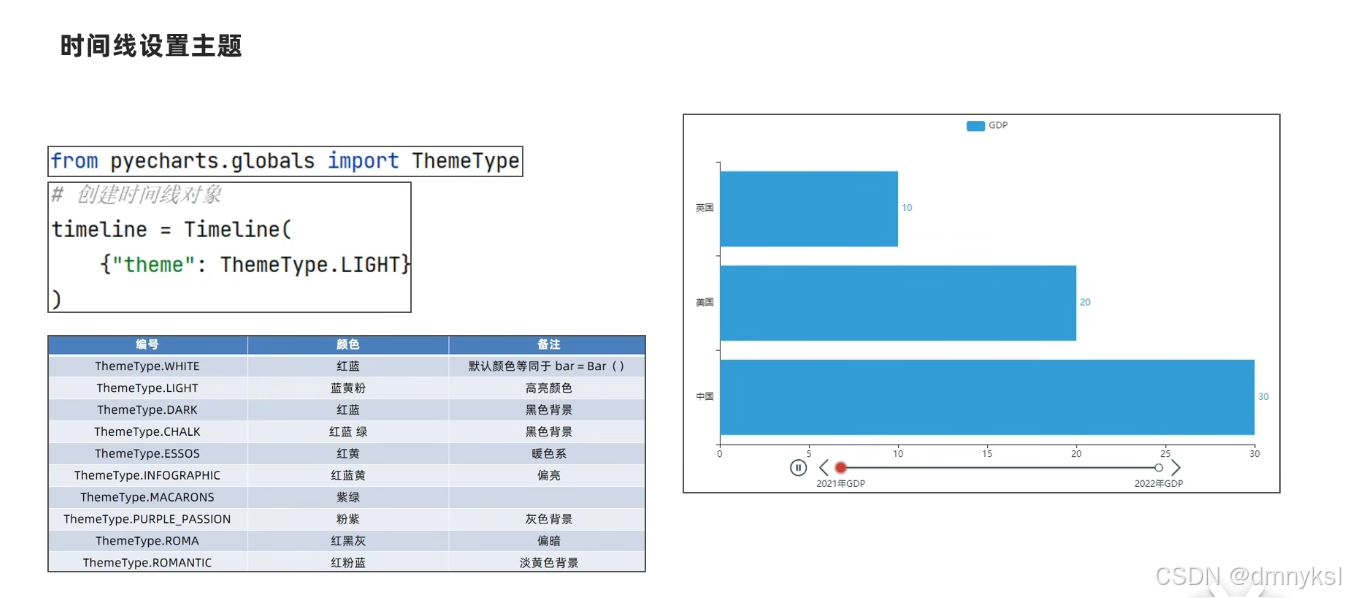
基础时间线柱状图绘制:


对象:
初识对象:

成员方法:



构造方法:

魔术方法:




"==" 是判断两个变量或实例是不是指向同一个内存空间
"equals" 是判断两个变量或实例所指向的内存空间的值是不是相同
封装:
面向对象三大特性:
封装、继承、多态


继承:

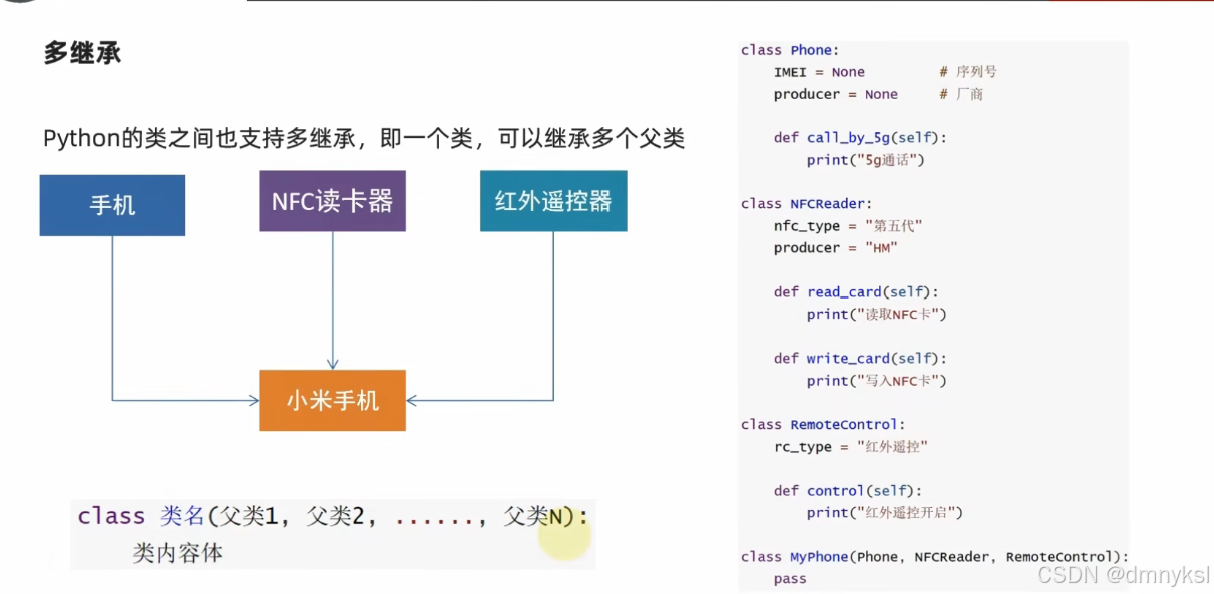
多继承中,如果父类有同名方法或属性,先继承的优先级高于后继承
pass关键字的作用:
pass是占位语句,用来保证函数(方法)或类定义的完整性,表示无内容,空的意思


类型注解:
Ctrl+p:弹出提示

变量的类型注解:



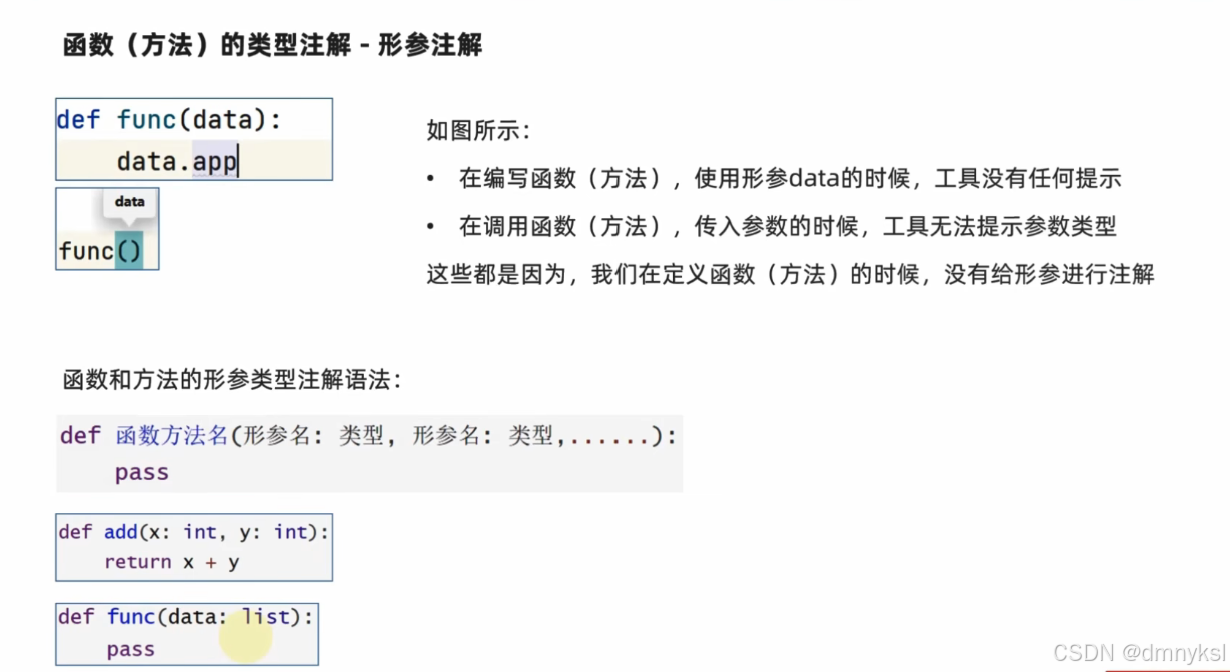
函数和方法的类型注解:

Union联合类型注解:
使用前需要导包


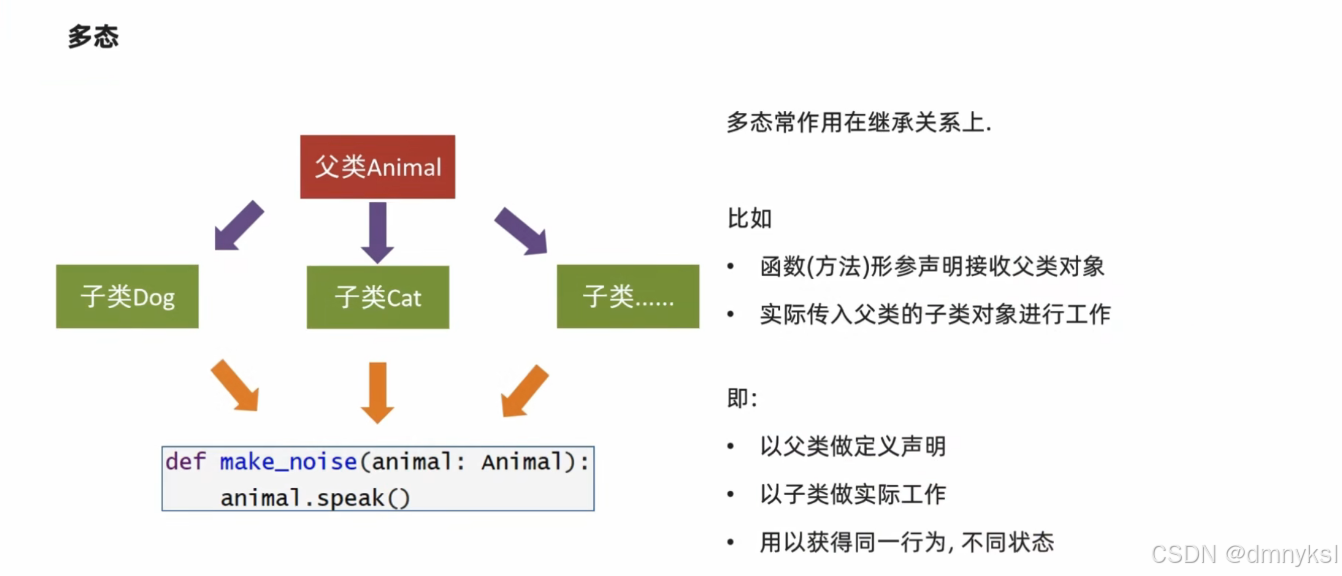
多态:


MySQL:
SQL基础和:DDL:



SQL支持注释:
单行注释:-- 注释内容(--后面一定要有一个空格)
单行注释:#注释内容(#后面可以不加空格,推荐加上)
多行注释:/*注释内容*/


SQL-DML:
DML是指数据操作语言,用来对数据库中表的数据记录进行更新