
阅读量:0
我从csdn上一路找原文章找到了这一篇
它使用distilbert-base-uncased这个模型给表格数据做文本embedding,并且期望这个LLM已经蕴含了合理的房产相关信息,因此对于没见过的异常房产信息,一定会产生一个与大多数信息embedding都不一样的embedding。
具体来说,对于以下图中的表格房产数据,先转成自然语言。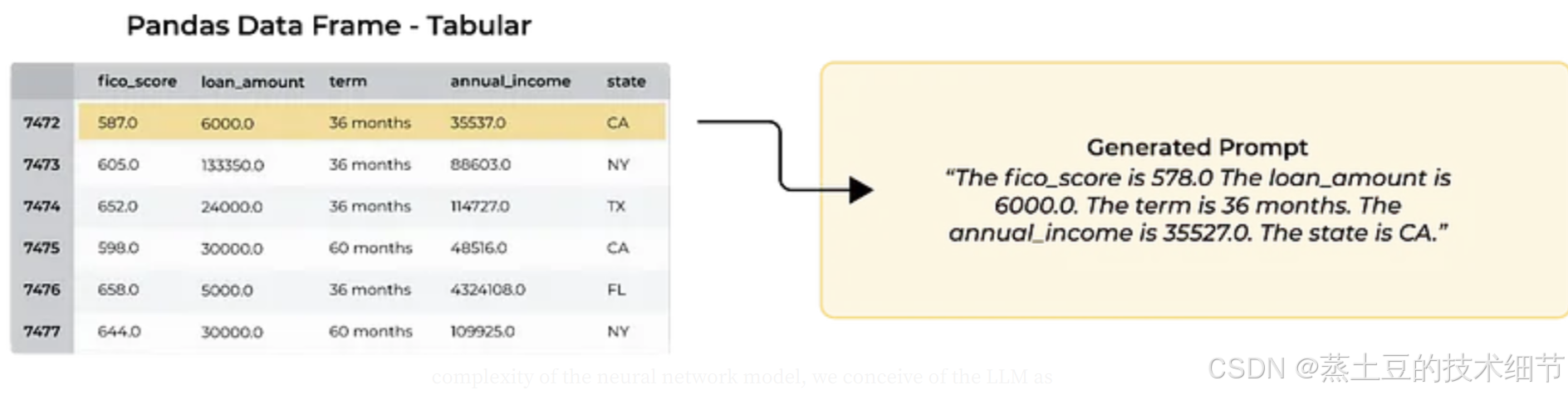
然后扔进前面提到的大模型,distilbert-base-uncased,从名字也能看出来是bert的蒸馏模型。
收集一堆embedding后,假设我们已经有了一批好数据,则在UMAP降维算法的帮助下,能够轻易地把好数据的分布可视化,而且聚类也很好做,就找到了一堆聚类中心。
如何检测异常呢?一条数据来了,它可能和所有聚类中心都距离很远,这就不对劲了。
这是他的实验结果
使用2%的异常数据,Anom Quantile置信度0.55,异常列大概意思是随机选4列变成异常值?总之最后性能极好。
