
阅读量:0
文章目录

Pre
OpenSource - Ip2region 离线IP地址定位库和IP定位数据管理框架
Ip2region - 基于xdb离线库的Java IP查询工具提供给脚本调用
IP源
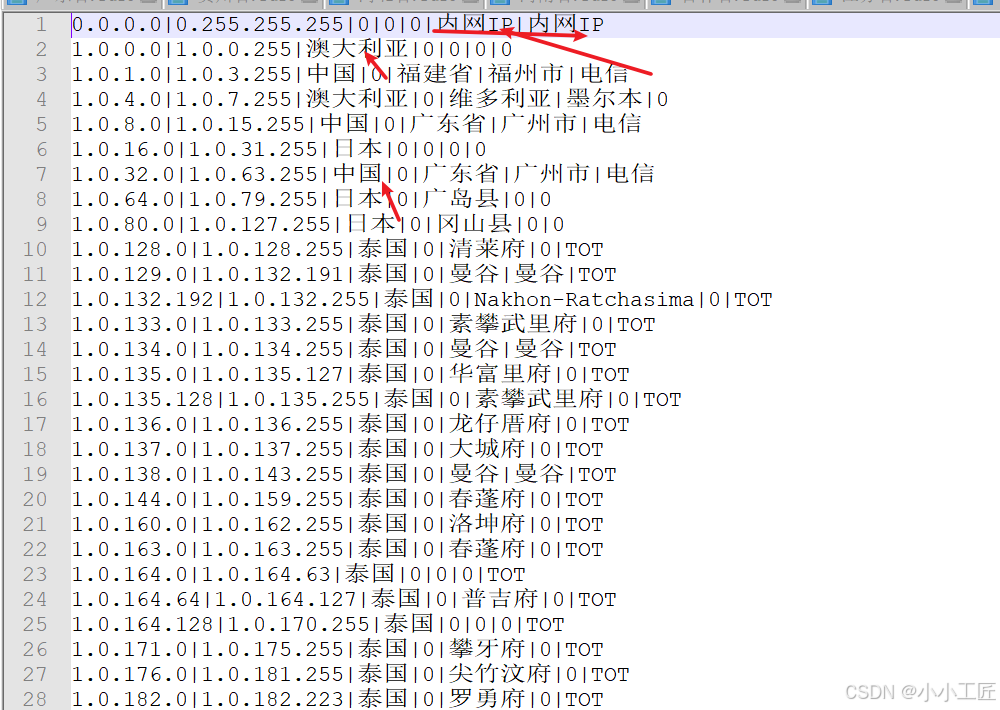
Code实现
package com.artisan.util; import cn.hutool.core.io.FileUtil; import java.io.File; import java.nio.charset.StandardCharsets; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.stream.Collectors; /** * @author 小工匠 * @version 1.0 * @date 2024/7/28 14:40 * @mark: show me the code , change the world */ public class IpDataAggregator { /** * 主函数,用于处理特定国家的IP数据。 * 具体步骤包括: * 1. 从指定文件中读取所有IP数据。 * 2. 过滤出包含“中国”关键字的IP数据。 * 3. 将这些数据聚合到各个城市。 * 4. 为每个城市的IP数据生成一个规则文件。 * * @param args 命令行参数,未使用。 */ public static void main(String[] args) { // 定义原始IP数据文件路径。 String filePath = "D:\\IdeaProjects\\ip2region-master\\data\\ip.merge.txt"; // 定义目标IP数据文件路径。 String chinaData = "D:\\IdeaProjects\\ip2region-master\\data\\china.txt"; String innerIpData = "D:\\IdeaProjects\\ip2region-master\\data\\inner.txt"; // 如果目标文件已存在,则删除之。 if (chinaData != null) { FileUtil.del(chinaData); } // 如果目标文件已存在,则删除之。 if (innerIpData != null) { FileUtil.del(innerIpData); } File chinaDataFile = null; File innerIpDataFile = null; // 读取原始IP数据文件,过滤出包含“中国”的行,并写入目标文件。 for (String line : FileUtil.readLines(filePath, StandardCharsets.UTF_8)) { if (line.contains("中国") ) { chinaDataFile = FileUtil.appendUtf8String(line + "\n", chinaData); } if (line.contains("内网")) { innerIpDataFile = FileUtil.appendUtf8String(line + "\n", innerIpData); } } // 读取目标文件中的中国IP数据。 // China IP 数据 List<String> chinaIpData = FileUtil.readLines(chinaDataFile, StandardCharsets.UTF_8); // 聚合中国IP数据到各个城市。 // 调用聚合函数并打印结果 Map<String, List<String>> aggregatedData = aggregateDataByCity(chinaIpData); // 为每个城市生成IP规则文件 extracted(aggregatedData , "city"); // 重新聚合数据到省份 aggregatedData = aggregateDataByProvince(chinaIpData); // 为每个省份生成IP规则文件 extracted(aggregatedData , "province"); // 处理内网数据 List<String> innerIpDataList = FileUtil.readLines(innerIpDataFile, StandardCharsets.UTF_8); // 203.0.113.0|203.0.113.255|0|0|0|内网IP|TPG电信 aggregatedData = aggregateDataByCity(innerIpDataList); extracted(aggregatedData, "inner"); } private static void extracted(Map<String, List<String>> aggregatedData,String type) { // 遍历聚合后的数据,为每个城市生成IP规则文件。 for (Map.Entry<String, List<String>> entry : aggregatedData.entrySet()) { // 如果城市规则文件已存在,则删除之。 if (FileUtil.exist("D:\\IdeaProjects\\ip2region-master\\data\\ips\\" + type + "\\" + entry.getKey() + ".rule")) { FileUtil.del("D:\\IdeaProjects\\ip2region-master\\data\\ips\\" + type + "\\" + entry.getKey() + ".rule"); } // 构建城市IP规则字符串。 StringBuilder sb = new StringBuilder(); for (String ipRange : entry.getValue()) { sb.append(ipRange); } //sb.append("deny all;"); // 将城市IP规则写入文件。 FileUtil.appendUtf8String(sb.toString(), "D:\\IdeaProjects\\ip2region-master\\data\\ips\\" + type + "\\" + entry.getKey() + ".rule"); } } /** * 根据省份聚合数据。 * 该方法通过遍历输入数据列表,将每个数据项根据其所属省份进行分组。 * 数据项被拆分为多个部分,其中倒数第三个部分代表了省份信息。 * 方法返回一个映射,其中键是省份,值是该省份下的数据项列表。 * * @param data 输入的数据列表,每个数据项以管道符("|")分隔。 * @return 返回一个映射,其中键是省份,值是该省份的数据项列表。 */ private static Map<String, List<String>> aggregateDataByProvince(List<String> data) { // 初始化一个映射,用于存储按省份聚合后的数据。 Map<String, List<String>> aggregatedData = new HashMap<>(); // 遍历输入数据列表。 data.stream().forEach(line -> { // 将每个数据项按管道符分割成多个部分。 // 分割字符串 String[] parts = line.split("\\|"); // 获取该数据项所属的省份信息。 // 获取倒数第三个分组 省份 String city = parts[parts.length - 3]; // 将数据项添加到对应省份的列表中。 // 如果该省份尚未存在于映射中,则先创建一个空列表。 // 将行数据添加到对应省份的列表中 aggregatedData.computeIfAbsent(city, k -> new ArrayList<>()).add(parts[0] + "|" + parts[1]); }); // 将聚合后的数据转换为指定格式后返回。 return getStringListMap(aggregatedData); } /** * 根据城市对数据进行聚合。 * 该方法通过遍历输入的数据列表,将每个数据项根据城市进行分组,最终返回一个映射表,其中键是城市名,值是该城市的数据项列表。 * 数据项是以管道符("|")分隔的字符串,本方法将每个数据项的第一个和第二个部分组合起来,作为聚合后的值。 * * @param data 数据列表,每个元素是一个以管道符分隔的字符串,代表一个数据项。 * @return 返回一个映射表,其中键是城市名,值是该城市的数据项列表。 */ private static Map<String, List<String>> aggregateDataByCity(List<String> data) { // 初始化一个哈希映射,用于存储聚合后的数据。 Map<String, List<String>> aggregatedData = new HashMap<>(); // 遍历数据列表中的每个元素。 data.stream().forEach(line -> { // 将每个数据项按管道符分割,以获取其组成部分。 // 分割字符串 String[] parts = line.split("\\|"); // 获取倒数第二个部分作为城市名。 // 获取倒数第二个分组 String city = parts[parts.length - 2]; // 如果映射中尚未存在该城市,则初始化一个列表,并将该数据项添加到列表中。 // 如果已存在,则直接将该数据项添加到列表中。 // 将行数据添加到对应城市的列表中 aggregatedData.computeIfAbsent(city, k -> new ArrayList<>()).add(parts[0] + "|" + parts[1]); }); // 调用getStringListMap方法对聚合后的数据进行处理,然后返回。 return getStringListMap(aggregatedData); } /** * 对给定的IP范围列表进行聚合,将每个城市的IP范围转换为CIDR格式的列表。 * * @param aggregatedData 包含城市和IP范围列表的映射。 * @return 返回转换后的映射,其中IP范围以CIDR格式列出。 */ private static Map<String, List<String>> getStringListMap(Map<String, List<String>> aggregatedData) { // 遍历映射中的每个条目,对每个城市的IP范围进行处理 aggregatedData.forEach((city, ranges) -> { // 初始化一个列表,用于存储聚合后的CIDR表达式 // 对每个城市进行IP范围聚合 List<String> aggregatedRanges = new ArrayList<>(); // 遍历城市的每个IP范围 for (String range : ranges) { // 使用竖线字符分割起始IP和结束IP String[] ips = range.split("\\|"); // 将起始IP和结束IP转换为CIDR列表 List<String> cidrList = IPCidrConverter.rangeToCIDR(ips[0], ips[1]); // 将CIDR列表转换为"allow"规则的字符串列表 List<String> targetList = cidrList.stream().map(cidr -> "allow " + cidr + ";\n").collect(Collectors.toList()); // 将转换后的规则列表添加到聚合后的列表中 aggregatedRanges.addAll(targetList); } // 更新映射,将城市的IP范围列表替换为聚合后的CIDR规则列表 aggregatedData.put(city, aggregatedRanges); }); // 返回处理后的映射 return aggregatedData; } } package com.artisan.util; import java.util.ArrayList; import java.util.List; public class IPCidrConverter { public static void main(String[] args) { String[] ipRanges = { "1.204.0.0|1.204.255.255", "1.207.96.0|1.207.127.255", "11.191.39.128|11.191.39.255", "11.192.60.0|11.192.63.255", "11.208.171.0|11.208.171.255", "11.208.184.0|11.208.203.255", "36.111.160.0|36.111.191.255", "36.114.0.0|36.114.255.255", "42.123.96.0|42.123.127.255", "42.247.2.200|42.247.2.207", "42.247.9.120|42.247.9.127", "42.247.14.48|42.247.14.63", "42.247.20.64|42.247.20.79", "42.247.33.160|42.247.33.175", "42.247.35.192|42.247.35.223", "42.247.45.64|42.247.45.79", "43.236.68.0|43.236.71.255", "43.250.116.0|43.250.119.255", "43.250.216.0|43.250.219.255", "43.254.100.0|43.254.103.255", "43.255.192.0|43.255.195.255", "45.248.88.0|45.248.91.255", "45.251.92.0|45.251.95.255", "45.251.100.0|45.251.103.255", "58.16.0.0|58.16.72.255", "58.16.75.0|58.16.99.255", "58.16.102.0|58.16.105.255", "58.16.129.0|58.16.135.255", "58.16.139.0|58.16.143.255", "58.16.181.0|58.16.181.255", "58.16.224.0|58.16.235.255", "58.16.240.0|58.16.240.255", "58.16.242.0|58.16.242.255", "58.16.244.0|58.16.255.255", "58.42.0.0|58.42.63.255", "58.42.112.0|58.42.127.255", "58.42.224.0|58.42.255.255", "59.51.128.0|59.51.191.255", "59.80.0.0|59.80.255.255", "61.159.128.0|61.159.135.255", "61.189.128.0|61.189.177.255", "61.189.254.0|61.189.255.255", "61.236.179.0|61.236.179.255", "61.236.182.0|61.236.182.127", "61.236.184.0|61.236.185.127", "61.236.189.0|61.236.193.255", "61.236.194.64|61.236.194.127", "61.237.2.28|61.237.2.31", "61.237.3.160|61.237.3.163", "61.237.15.32|61.237.15.63", "61.237.97.100|61.237.97.103", "61.237.122.142|61.237.122.143", "61.237.124.106|61.237.124.107", "61.237.124.110|61.237.124.111", "61.237.124.114|61.237.124.115", "61.243.0.0|61.243.6.255", "61.243.38.0|61.243.38.255", "61.243.40.0|61.243.41.255", "61.243.43.0|61.243.44.255", "101.238.0.0|101.238.255.255", "103.3.152.0|103.3.152.255" }; for (String range : ipRanges) { String[] ips = range.split("\\|"); List<String> cidrList = rangeToCIDR(ips[0], ips[1]); for (String cidr : cidrList) { System.out.println(cidr); } } } /** * 将IP地址范围转换为CIDR格式的IP段列表。 * * @param startIp 起始IP地址,包含在范围内。 * @param endIp 结束IP地址,包含在范围内。 * @return CIDR格式的IP段列表。 */ public static List<String> rangeToCIDR(String startIp, String endIp) { // 将起始和结束IP地址转换为长整型以便计算 long start = ipToLong(startIp); long end = ipToLong(endIp); List<String> result = new ArrayList<>(); // 遍历每个IP地址,直到达到结束IP while (end >= start) { // 初始化CIDR的掩码大小为32 byte maxSize = 32; // 逐渐减小掩码大小,寻找最合适的CIDR值 while (maxSize > 0) { // 计算对应掩码大小的掩码值 long mask = CIDRToMask(maxSize - 1); // 对起始IP应用掩码 long maskedBase = start & mask; // 如果应用掩码后的结果不是起始IP,则说明当前掩码大小不合适 if (maskedBase != start) { break; } // 尝试更小的掩码大小 maxSize--; } // 计算理论上的最大子网掩码大小 double x = Math.log(end - start + 1) / Math.log(2); byte maxDiff = (byte) (32 - Math.floor(x)); // 如果当前掩码大小小于理论上的最大子网掩码大小,则调整为理论上的最大值 if (maxSize < maxDiff) { maxSize = maxDiff; } // 构造CIDR格式的IP段,并添加到结果列表中 String cidr = longToIP(start) + "/" + maxSize; result.add(cidr); // 移动到下一个子网 start += Math.pow(2, (32 - maxSize)); } return result; } /** * 将IPv4地址转换为长整型数字。 * 这个方法将IPv4地址字符串形式转换为它的二进制表示,并将这个二进制数表示为一个长整型数值。 * IPv4地址由4个8位的字节组成,这些字节由点号(.)分隔。 * 例如,地址"192.168.1.1"会被转换为数值3232235521。 * * @param ipAddress 字符串形式的IPv4地址。 * @return 转换后的长整型数值。 */ public static long ipToLong(String ipAddress) { // 使用点号分割IP地址字符串,得到每个字节的字符串表示 String[] ipParts = ipAddress.split("\\."); long result = 0; // 遍历每个字节,将它们转换为整型,并按照IPv4的字节顺序组合成一个长整型数值 for (int i = 0; i < 4; i++) { // 将每个字节转换为整型,并根据其在IP地址中的位置进行位移 // 位移的目的是将每个字节正确地放置在长整型数值的相应位置上 result += Integer.parseInt(ipParts[i]) << (24 - (8 * i)); } return result; } /** * 将一个长整型数值转换为IPv4地址字符串。 * * @param ip 长整型数值表示的IP地址,每个字节占32位中的8位。 * @return 字符串表示的IPv4地址,形式为"xxx.xxx.xxx.xxx"。 */ public static String longToIP(long ip) { // 将ip的高8位转换为整型,并以字符串形式拼接 return ((ip >> 24) & 0xFF) + "." + // 将ip的次高8位转换为整型,并以字符串形式拼接 ((ip >> 16) & 0xFF) + "." + // 将ip的中间8位转换为整型,并以字符串形式拼接 ((ip >> 8) & 0xFF) + "." + // 将ip的最低8位转换为整型,并以字符串形式拼接 (ip & 0xFF); } /** * 根据CIDR值计算IPv4地址的子网掩码。 * <p> * CIDR(Classless Inter-Domain Routing)是一种用于IPv4地址分配和子网划分的方法,它通过一个斜线后面的数字(CIDR值)来表示子网掩码的位数。 * 该方法接受一个CIDR值作为参数,返回对应子网掩码的长整型表示。如果CIDR值为0,则返回全0的子网掩码。 * <p> * 计算子网掩码的原理是将32位的二进制数左移(32-CIDR)位,然后与全1的二进制数相与,得到子网掩码。 * 由于Java中没有直接处理二进制数的位运算操作符,因此使用按位左移和按位与操作来实现。 * * @param cidr CIDR值,表示子网掩码中1的位数。 * @return 对应于给定CIDR值的子网掩码的长整型表示。 */ public static long CIDRToMask(int cidr) { // 当CIDR值为0时,返回全0的子网掩码 return cidr == 0 ? 0 : (0xFFFFFFFF << (32 - cidr)); } } 输出
看看里面的格式
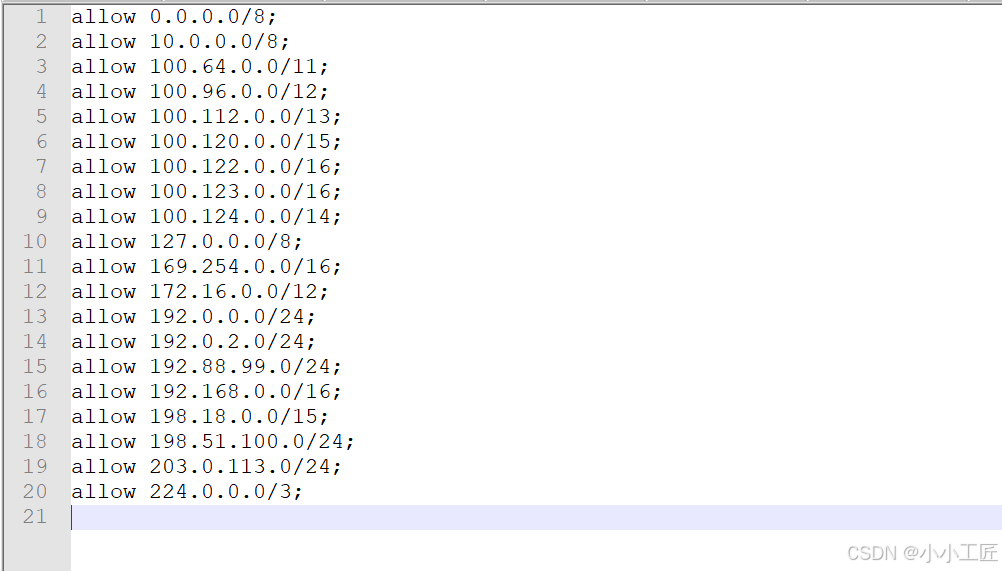
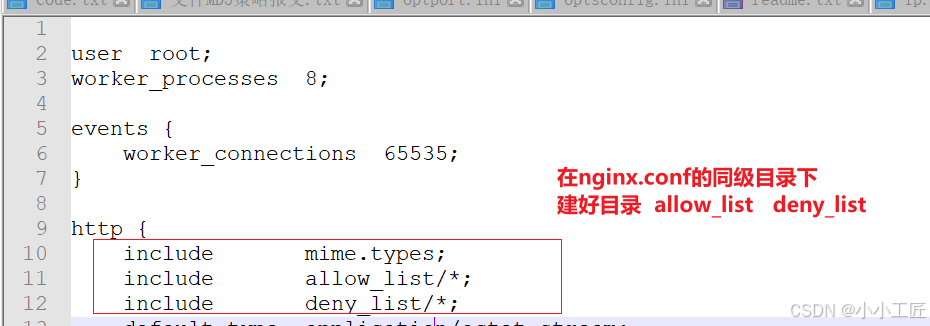
Nginx配置
Http
TCP
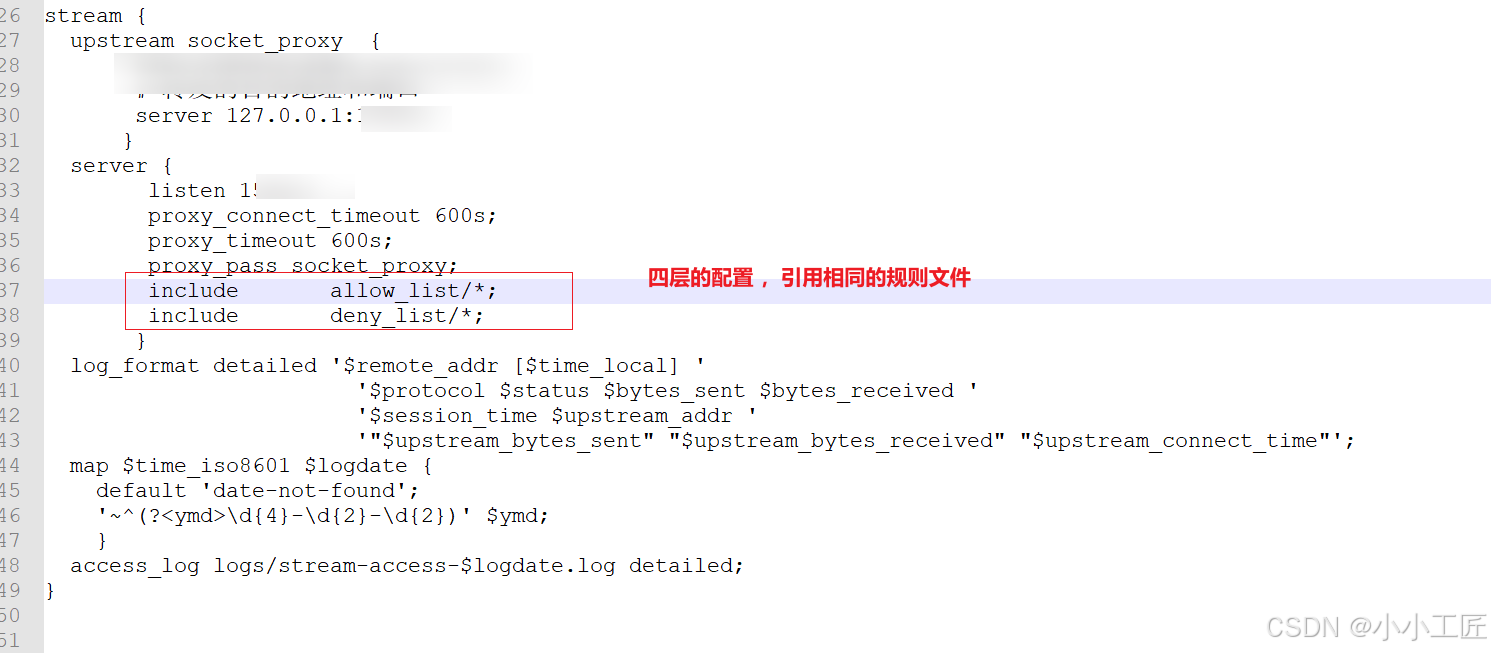
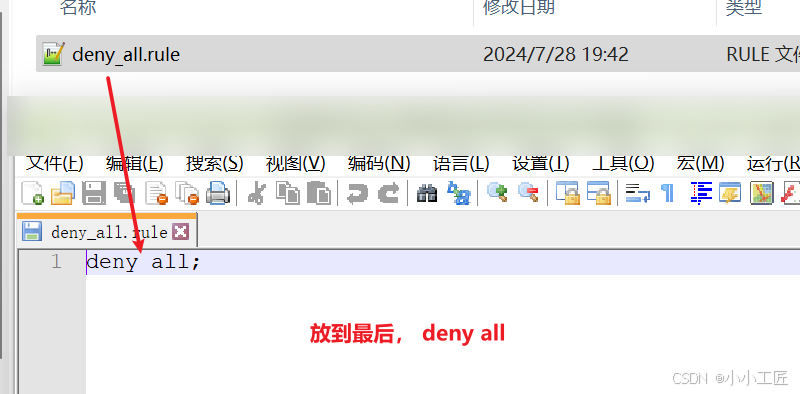
扩展
CIDR网段格式

